New JIT available: now with SIMD support
From translator
Personally, I just incredibly happy new opportunity. Just recently, I defeated Pro .Net Perfomance , in which one of the chapters was devoted to parallelism, and vectorization in particular. The conclusion made by the authors: “Unfortunately, the use of vectorization is possible exclusively on C ++, the execution of code on the video card is possible using .Net tools, however C ++ AMP leaves any managed GPGPU libraries far behind, therefore, unfortunately, in these tasks we recommend using plug C + + assemblies. "Therefore, I am happy to announce that at least one problem has been solved. Well, let's get started!
Introduction
')
The speed of the processors no longer obeys Moore's law . Therefore, to increase application performance, it is increasingly important to use parallelization. Or, as Sutter's Coat of Arms said, “there will be no more soup”
One might think that using task-oriented programming ( for example, in the case of .Net - TPL, approx. Lane ) or ordinary threads already solves this problem. While multithreading is certainly an important task, you need to understand that it is still important to optimize the code that runs on each individual core. SIMD is a technology that uses data parallelism at the processor level. Multi-threading and SIMD complement each other: multi-threading allows you to parallelize work on several processor cores, while SIMD allows you to parallelize work within one core.
Today, we are pleased to announce a new preview version of RyuJIT, which provides SIMD functionality. The SIMD API is available through the new NuGet package, Microsoft.Bcl.Simd , which is also released as a preview.
Here is an example of how you can use it:
// Initalize some vectors Vector<float> values = GetValues(); Vector<float> increment = GetIncrement(); // The next line will leverage SIMD to perform the // addition of multiple elements in parallel: Vector<float> result = values + increment; What is SIMD and why is it for me?
SIMD is currently the most requested feature that is being asked to add to the platform ( about 2,000 user votes )

It is so popular because, with the exception of certain types of applications, SIMD greatly speeds up code performance. For example, the rendering performance of the Mandelbrot set can be significantly improved using SIMD: 2-3 times (if the processor supports SSE2 ), and 4-5 times (if the processor supports AVX ).
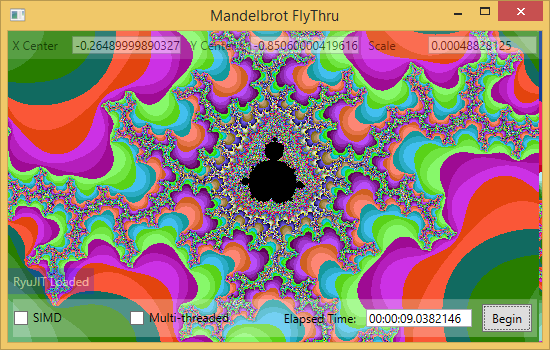
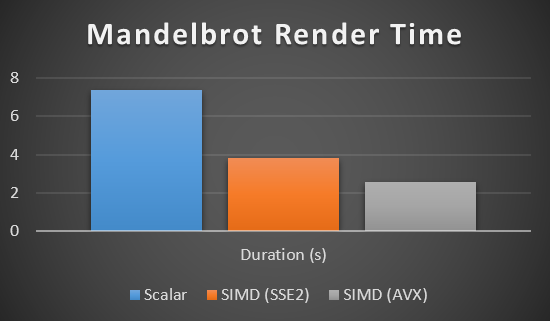
Introduction to SIMD
SIMD stands for “one team, a lot of data” ( Russian version - OKMD, approx. Lane ). This is a set of processor instructions that allow you to work on vectors instead of scalars. Due to this, parallel execution of mathematical operations on a data set is possible.
SIMD allows you to parallelize data at the processor level, using high-level tools. For example, imagine that you have a set of numbers, and to each you need to add some value. Usually, to solve this problem, a cycle is written that performs this operation sequentially for each element:
float[] values = GetValues(); float increment = GetIncrement(); // Perform increment operation as manual loop: for (int i = 0; i < values.Length; i++) { values[i] += increment; } SIMD, on the other hand, allows you to add multiple values at the same time using specific CPU instructions. This usually looks like a vector operation:
Vector<float> values = GetValues(); Vector<float> increment = GetIncrement(); // Perform addition as a vector operation: Vector<float> result = values + increment; It is interesting to note that there is more than one SIMD specification. Rather, each processor has its own implementation of SIMD. They differ in the number of elements on which an operation can be performed simultaneously, as well as in the set of instructions available. The most common implementation of SIMD on Intel / AMD processors is SSE2.
Here is a simplified model of how SIMD works at the processor level:
- The processor has special SIMD registers. They have a fixed size. For example, for SSE2, the size is 128 bits.
- The processor also has special SIMD instructions depending on the size of the operand. From the point of view of the processor, the data in the SIMD register is simply a set of bits. However, the developer wants to interpret these bits as, let's say, a set of 32-bit integers. For this purpose, the processor has instructions specific to the operation being performed (for example, addition), and the type of operand (for example, a 32-bit integer)
One of the many areas where SIMD is very useful is graphics and games, because:
- These applications do a lot of computation.
- Most data structures are already represented as vectors.
However, SIMD is applicable to any type of application that performs numeric operations on a large set of values. This also includes scientific calculations and finance.
Designing SIMD for. NET
Most .NET developers should not write CPU dependent code. Instead, CLR abstracts the hardware by providing a virtual machine that translates its code into machine commands either at run time (JIT) or during installation (NGEN). Leaving the CLR code generation, you can use the same MSIL code on different computers with different processors, without abandoning optimizations specific to this particular CPU.
This separation is what allows the library ecosystem to be used because it makes it extremely easy to reuse code. We believe that the library ecosystem is the main reason why .NET is such a productive environment.
In order to preserve this separation, we had to come up with such a programming model for SIMD, which would allow to express vector operations without reference to a specific processor implementation, for example, SSE2. We have come up with a model that provides two categories of vector types:

These two categories we call JIT- "built-in types." This means that JIT knows about these types and treats them in a special way when generating machine code. However, all types are also designed to work flawlessly in cases where equipment does not support SIMD (which is quite rare today) or the application does not use this version of RyuJIT. Our goal is to provide acceptable performance even in cases where it is about the same as for sequential written code. Unfortunately, in this preview, we have not yet achieved this.
Vectors with fixed size
Let's first talk about fixed-size vectors. There are many applications that already define their own vector types, especially graphic applications such as games or ray tracer. In most cases, these applications use floating-point and single-precision values.
The key aspect is that these vectors have a certain number of elements, usually two, three or four. Dual element vectors are often used to represent points or similar objects, such as complex numbers. Vectors with three and four elements are usually used for 3D (the 4th element is used to do the math work [ Obviously, it’s about the fact that four-dimensional
XYZ1 matrices are used in 3D modeling of the transformation ]). The bottom line is that these tasks use vectors with a certain number of elements.To get an idea of how these types look, let's look at a simplified version of
Vector3f : public struct Vector3f { public Vector3f(float value); public Vector3f(float x, float y, float z); public float X { get; } public float Y { get; } public float Z { get; } public static bool operator ==(Vector3f left, Vector3f right); public static bool operator !=(Vector3f left, Vector3f right); // With SIMD, these element wise operations are done in parallel: public static Vector3f operator +(Vector3f left, Vector3f right); public static Vector3f operator -(Vector3f left, Vector3f right); public static Vector3f operator -(Vector3f value); public static Vector3f operator *(Vector3f left, Vector3f right); public static Vector3f operator *(Vector3f left, float right); public static Vector3f operator *(float left, Vector3f right); public static Vector3f operator /(Vector3f left, Vector3f right); } I would like to emphasize the following aspects:
- We have developed fixed-size vectors so that they can easily replace those defined in the applications.
- For performance reasons, we have defined these types as immutable value types.
- The idea is that after replacing your vector with ours, your application will behave the same, except that it will work faster. For more information, see our sample ray tracing application .
Machine-dependent size vectors
At that time, fixed-size vector types are convenient to use, their maximum degree of parallelization is limited by the number of components. For example, an application that uses Vector2f will get at most double the acceleration, even if the CPU is able to perform operations on eight elements at the same time.
In order for the application to scale with the hardware capabilities, the developer must vectorize the algorithm. The vectorization of the algorithm means that the developer must divide the input parameters into a set of vectors, the size of which depends on the equipment. On a machine with SSE2, this means that the application can work on vectors of four 32-bit floating point numbers. On an AVX machine, the same application can work on vectors of eight such numbers.
To understand for the difference, below is a simplified version.
Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - , Vector. , . int , long , float double . , .
. , , Length. sizeof(SIMD-register) / sizeof(T) . , Vector Vector , T1 T2 . , .
- , , . , , . . , , . , .
SIMD, , Vector2f . ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :
@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet- Microsoft.Bcl.Simd . , Manage NuGet References . Online . , Include Prelease . Microsoft.Bcl.Simd . Install .
, , , :
SIMD 64- . , x64, Any CPU, 32- Vector int, long, float double. Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - , Vector. , . int , long , float double . , .
. , , Length. sizeof(SIMD-register) / sizeof(T) . , Vector Vector , T1 T2 . , .
- , , . , , . . , , . , .
SIMD, , Vector2f . ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :
@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet- Microsoft.Bcl.Simd . , Manage NuGet References . Online . , Include Prelease . Microsoft.Bcl.Simd . Install .
, , , :
SIMD 64- . , x64, Any CPU, 32- Vector int, long, float double. Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.
Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :
@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.
Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.Vector:
public struct Vector<T> where T : struct { public Vector(T value); public Vector(T[] values); public Vector(T[] values, int index); public static int Length { get; } public T this[int index] { get; } public static bool operator ==(Vector<T> left, Vector<T> right); public static bool operator !=(Vector<T> left, Vector<T> right); // With SIMD, these element wise operations are done in parallel: public static Vector<T> operator +(Vector<T> left, Vector<T> right); public static Vector<T> operator &(Vector<T> left, Vector<T> right); public static Vector<T> operator |(Vector<T> left, Vector<T> right); public static Vector<T> operator /(Vector<T> left, Vector<T> right); public static Vector<T> operator ^(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, Vector<T> right); public static Vector<T> operator *(Vector<T> left, T right); public static Vector<T> operator *(T left, Vector<T> right); public static Vector<T> operator ~(Vector<T> value); public static Vector<T> operator -(Vector<T> left, Vector<T> right); public static Vector<T> operator -(Vector<T> value); }
:
. , - ,Vector. ,.int,long,floatdouble. , .
. , , Length.sizeof(SIMD-register) / sizeof(T). ,Vector Vector , T1T2. , .
- , , . , , . . , , . , .
SIMD, ,Vector2f. ( ) ( ). , . , .
, . , .
- SIMD
:
RyuJIT, SIMD NuGet, SIMD
NuGet SIMD / JIT. IL. ,, RyuJIT.
SIMD, :
RyuJIT aka.ms/RyuJIT JIT SIMD . , :@echo off set COMPLUS_AltJit=* set COMPLUS_FeatureSIMD=1 start myapp.exe
NuGet-Microsoft.Bcl.Simd. ,Manage NuGet References.Online. ,Include Prelease.Microsoft.Bcl.Simd.Install.
, , , :
SIMD 64- . , x64, Any CPU, 32-Vectorint, long, float double.Vector .
SIMD SSE2. , RyuJIT CTP . AVX .NET, RyuJIT. , () CTP.
.
. ? ? ? , ryujit(at)microsoft.com.
Source: https://habr.com/ru/post/219841/
All Articles