Useful techniques for working with Apache Camel
If you had to create integration solutions in Java, you probably know the wonderful Java framework called Apache Camel . It will easily connect between several services, import data from files, databases and other sources, notify you of various events in a Jabber client or via E-mail, and become the basis for a composite application based on a large number of other applications.
The Apache Camel model is based on the notion of routes ( routes ), which can be configured both statically (for example, in the Spring-context file) and during application running. Along the routes, caravans of messages travel along the way to various processors, converters, aggregators and other transformers, which ultimately allows processing data from many different sources in a single application and transferring this data to other services or saving it to any storage.
In general, Camel is a completely self-contained framework. Using it, often, you don’t even have to write your own code - you just need to type the correct route that will allow you to solve the problem. However, all the same, to build your own data processing model, you may need to write code.
So it was with us. We use Camel to implement pipelines to handle multiple messages from various sources. Such an approach allows, for example, to monitor the status of services, promptly notify about problems, receive aggregated analytical sections, prepare data for sending to other systems, and so on. The flow of processed and “digestible” messages to the system can be quite large (thousands of messages per minute), so we try to use horizontally scalable solutions where possible. For example, we have a system for tracking the status of tests performed and monitoring services. Millions of such tests are performed daily, and we receive many times more messages to monitor their execution.
In order to “assimilate” a similar volume of messages, it is necessary to clearly define an aggregation strategy — from more parallelism to less. In addition, it is necessary to have at least basic horizontal scalability and fault tolerance of the service.
We use ActiveMQ as the message queue, and Hazelcast as the online storage.
')
For the organization of parallel processing is organized a cluster of several peer servers. Each of them has an ActiveMQ broker, whose queues are composed of messages arriving via the HTTP protocol. HTTP handles are behind the balancer, distributing messages on live servers.
An incoming message queue on each server parses a Camel application that uses a Hazelcast cluster to store states and, if necessary, synchronize processing. ActiveMQ is also clustered using NetworkConnectors, and can “share” messages with each other.
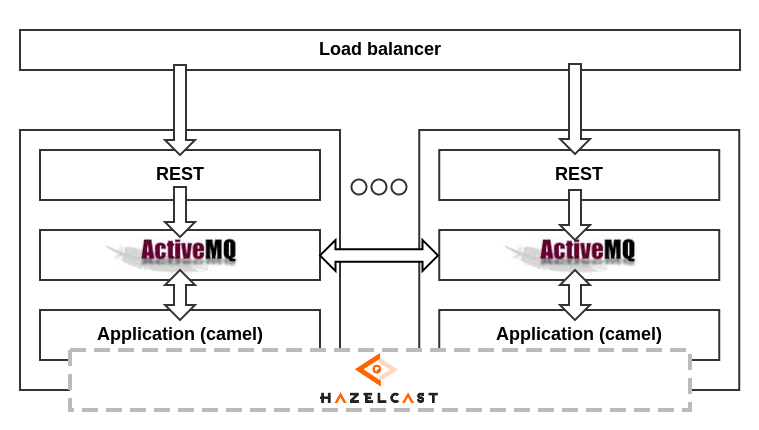
In general, the scheme is as follows:
As can be seen from the diagram, the failure of one of the components of the system does not violate its performance, taking into account the equality of the elements. For example, if a message handler fails on one of the servers, ActiveMQ starts to send messages from its queues to others. If one of the ActiveMQ brokers falls, then the handler hooks to the next one. Well, finally, if the entire server fails, the other servers continue to work hard, as if nothing had happened. To increase data safety, Hazelcast nodes store backup copies of their neighbors' data (copies are made asynchronously, their number on each node is configured additionally).
This scheme also allows you to scale out the service cost-effectively, adding additional servers, and thereby increasing the computing resource.
When using aggregation, Apache Camel includes the concepts of " aggregation repository " and " correlation key ". The first is the repository where the aggregated states are stored (for example, the number of dropped tests per day). The second is the key used to distribute the message flow by state. In other words, a correlation key is a key in the aggregation repository (for example, the current date).
For aggregators in such a scheme, we needed to implement our own aggregation repository, which can store states in Hazelcast and synchronize the processing of identical keys within the cluster. Unfortunately, in the standard delivery of Camel, we did not find such a possibility. It turned out to be quite easy to create it - just implement the AggregationRepository interface:
To use such a repository, now you just need to connect to the Hazelcast project and declare it in context, and then add a set of repositories with an indication to the Hazelcast instance. It is important to remember that each aggregator must have its own key space, and therefore it must also transfer the name of the repository. In the Hazelcast settings you need to register all the servers that are included in the cluster.
Thus, we get the opportunity to use aggregators in a distributed environment without thinking about which server will aggregate on.
The number of states stored in the cluster is quite large. But not all of them are needed all the time. In addition, some states (for example, the status of tests that have not been used for a long time, and therefore there have not been any messages for them for a long time) are generally not necessary to be stored. I want to get rid of such states and additionally notify other systems about this. To do this, it is necessary to check the state of aggregators for obsolescence at a specified frequency and to delete them.
The simple way to do this is to add a periodic task, for example, using Quartz. In addition, Camel allows you to do this. However, it must be remembered that execution takes place in a cluster with multiple peer servers. And I don’t really want the Quartz periodic tasks to work at all at the same time. To avoid this, it is enough to make synchronization again with the help of Hazelcast locks. But how to get Quartz to initialize only on one server, or rather at what point in time to synchronize?
To initialize the Camel context and all other components of the system, we use Spring, and to get Quartz to start the scheduler on only one server from the cluster, first, it is necessary to disable its automatic launch by explicitly declaring the context:
Secondly, you need to synchronize somewhere and start the scheduler only if you managed to capture the lock, and then wait for the next moment of its capture (in case the previous server that captured the lock failed or for some reason released it). This can be implemented in Spring in several ways, for example, through ApplicationListener, which allows you to handle context launch events:
We get the following implementation of the class scheduler initialization:
Thus, we will be able to use periodic tasks recommended by Camel in the way and taking into account the distributed runtime environment. For example:
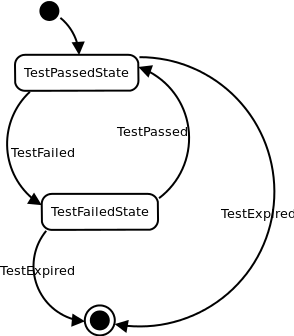
In addition to simple methods of aggregation (for example, counting amounts), we also often needed to switch the states of aggregators depending on incoming messages, for example, to always remember the current state of the test performed. Finite automata are well suited for this feature. Imagine that we have some test status. For example, TestPassedState. When we receive a TestFailed message for this test, we must switch the state of the aggregator to TestFailedState, and when we receive the TestPassed, we will again switch to TestPassedState. And so on to infinity. On the basis of these transitions, you can draw some conclusions, for example, if a transition occurs TestPassed -> TestFailed, it is necessary to notify all interested parties that the test has broken. And if the reverse transition occurs, then, on the contrary, tell them that everything has become good.
Selecting options for the implementation of such an aggregation strategy, we came to the conclusion that we need some kind of state machine model adapted to the realities of message processing. First, the messages arriving at the input of aggregators are a certain set of objects. Each event has its own type, and therefore easily falls on classes in Java. To describe the types of events, we use the xsd scheme, according to which we generate a set of classes using xjc. These classes are easily serialized and deserialized into xml and json, using jaxb. The states stored in Hazelcast are also represented by a set of classes generated by xsd. Thus, we needed to find an implementation of finite automata, which makes it easy to operate with state transitions based on the message type and the current state type. And I also wanted these transitions to be specified declaratively, and not imperatively, as in many similar libraries. We did not find such a lightweight implementation of such functionality, and therefore we decided to write our own, taking into account our needs and well forming the basis for processing messages coming along the route to Camel.
A small library that implements our needs is called Yatomata (from the words Yet Another auTomata) and is available on github .
It was decided to simplify the FSM model somewhat - for example, the context is set by the current state object, the message also stores some data. However, the transitions are determined only by the types of states and messages. A state machine is defined for a class that is used as an aggregator. For this, the class is annotated with @FSM . An initial state (start) and a set of transitions are defined for it, some of which stop the aggregation (stop = true), automatically sending the accumulated state further along the route.
A set of transitions is declared by the @Transitions annotation and an array of @Transit annotations, each of which can be given a set of initial states (from), an end state (to), a set of events for which this transition is activated (on), and whether this state is the end of the machine (stop). For conversion processing, annotations are provided for @OnTransit , @BeforeTransit , and also @AfterTransit , which can be used to mark public methods inside a class. These methods will be invoked if a matching transition is found that satisfies its signature.
Work with the state machine is as follows:
By implementing the AggregationStrategy interface, we created the FSMAggregationStrategy, which is declared in Spring context like this:
The simplest implementation of an aggregation strategy when using this state machine may look like this:
These techniques allowed us to implement several horizontally scalable services for various purposes. Apache Camel showed its best and met its expectations. It combines declarativity with high flexibility, which in total provides excellent scaling of integration applications with minimal effort to support and add new functionality.
Introduction
The Apache Camel model is based on the notion of routes ( routes ), which can be configured both statically (for example, in the Spring-context file) and during application running. Along the routes, caravans of messages travel along the way to various processors, converters, aggregators and other transformers, which ultimately allows processing data from many different sources in a single application and transferring this data to other services or saving it to any storage.
In general, Camel is a completely self-contained framework. Using it, often, you don’t even have to write your own code - you just need to type the correct route that will allow you to solve the problem. However, all the same, to build your own data processing model, you may need to write code.
So it was with us. We use Camel to implement pipelines to handle multiple messages from various sources. Such an approach allows, for example, to monitor the status of services, promptly notify about problems, receive aggregated analytical sections, prepare data for sending to other systems, and so on. The flow of processed and “digestible” messages to the system can be quite large (thousands of messages per minute), so we try to use horizontally scalable solutions where possible. For example, we have a system for tracking the status of tests performed and monitoring services. Millions of such tests are performed daily, and we receive many times more messages to monitor their execution.
In order to “assimilate” a similar volume of messages, it is necessary to clearly define an aggregation strategy — from more parallelism to less. In addition, it is necessary to have at least basic horizontal scalability and fault tolerance of the service.
We use ActiveMQ as the message queue, and Hazelcast as the online storage.
')
Scaling
For the organization of parallel processing is organized a cluster of several peer servers. Each of them has an ActiveMQ broker, whose queues are composed of messages arriving via the HTTP protocol. HTTP handles are behind the balancer, distributing messages on live servers.
An incoming message queue on each server parses a Camel application that uses a Hazelcast cluster to store states and, if necessary, synchronize processing. ActiveMQ is also clustered using NetworkConnectors, and can “share” messages with each other.
In general, the scheme is as follows:
As can be seen from the diagram, the failure of one of the components of the system does not violate its performance, taking into account the equality of the elements. For example, if a message handler fails on one of the servers, ActiveMQ starts to send messages from its queues to others. If one of the ActiveMQ brokers falls, then the handler hooks to the next one. Well, finally, if the entire server fails, the other servers continue to work hard, as if nothing had happened. To increase data safety, Hazelcast nodes store backup copies of their neighbors' data (copies are made asynchronously, their number on each node is configured additionally).
This scheme also allows you to scale out the service cost-effectively, adding additional servers, and thereby increasing the computing resource.
Distributed aggregators
When using aggregation, Apache Camel includes the concepts of " aggregation repository " and " correlation key ". The first is the repository where the aggregated states are stored (for example, the number of dropped tests per day). The second is the key used to distribute the message flow by state. In other words, a correlation key is a key in the aggregation repository (for example, the current date).
For aggregators in such a scheme, we needed to implement our own aggregation repository, which can store states in Hazelcast and synchronize the processing of identical keys within the cluster. Unfortunately, in the standard delivery of Camel, we did not find such a possibility. It turned out to be quite easy to create it - just implement the AggregationRepository interface:
Hidden text
public class HazelcastAggregatorRepository implements AggregationRepository { private final Logger logger = LoggerFactory.getLogger(getClass()); // maximum time of waiting for the lock from hz public static final long WAIT_FOR_LOCK_SEC = 20; private final HazelcastInstance hazelcastInstance; private final String repositoryName; private IMap<String, DefaultExchangeHolder> map; public HazelcastAggregatorRepository(HazelcastInstance hazelcastInstance, String repositoryName){ this.hazelcastInstance = hazelcastInstance; this.repositoryName = repositoryName; } @Override protected void doStart() throws Exception { map = hazelcastInstance.getMap(repositoryName); } @Override protected void doStop() throws Exception { /* Nothing to do */ } @Override public Exchange add(CamelContext camelContext, String key, Exchange exchange) { try { DefaultExchangeHolder holder = DefaultExchangeHolder.marshal(exchange); map.tryPut(key, holder, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS); return toExchange(camelContext, holder); } catch (Exception e) { logger.error("Failed to add new exchange", e); } finally { map.unlock(key); } return null; } @Override public Exchange get(CamelContext camelContext, String key) { try { map.tryLock(key, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS); return toExchange(camelContext, map.get(key)); } catch (Exception e) { logger.error("Failed to get the exchange", e); } return null; } @Override public void remove(CamelContext camelContext, String key, Exchange exchange) { try { logger.debug("Removing '" + key + "' tryRemove..."); map.tryRemove(key, WAIT_FOR_LOCK_SEC, TimeUnit.SECONDS); } catch (Exception e) { logger.error("Failed to remove the exchange", e); } finally { map.unlock(key); } } @Override public void confirm(CamelContext camelContext, String exchangeId) { /* Nothing to do */ } @Override public Set<String> getKeys() { return Collections.unmodifiableSet(map.keySet()); } private Exchange toExchange(CamelContext camelContext, DefaultExchangeHolder holder) { Exchange exchange = null; if (holder != null) { exchange = new DefaultExchange(camelContext); DefaultExchangeHolder.unmarshal(exchange, holder); } return exchange; } } To use such a repository, now you just need to connect to the Hazelcast project and declare it in context, and then add a set of repositories with an indication to the Hazelcast instance. It is important to remember that each aggregator must have its own key space, and therefore it must also transfer the name of the repository. In the Hazelcast settings you need to register all the servers that are included in the cluster.
Thus, we get the opportunity to use aggregators in a distributed environment without thinking about which server will aggregate on.
Distributed timers
The number of states stored in the cluster is quite large. But not all of them are needed all the time. In addition, some states (for example, the status of tests that have not been used for a long time, and therefore there have not been any messages for them for a long time) are generally not necessary to be stored. I want to get rid of such states and additionally notify other systems about this. To do this, it is necessary to check the state of aggregators for obsolescence at a specified frequency and to delete them.
The simple way to do this is to add a periodic task, for example, using Quartz. In addition, Camel allows you to do this. However, it must be remembered that execution takes place in a cluster with multiple peer servers. And I don’t really want the Quartz periodic tasks to work at all at the same time. To avoid this, it is enough to make synchronization again with the help of Hazelcast locks. But how to get Quartz to initialize only on one server, or rather at what point in time to synchronize?
To initialize the Camel context and all other components of the system, we use Spring, and to get Quartz to start the scheduler on only one server from the cluster, first, it is necessary to disable its automatic launch by explicitly declaring the context:
<bean id="quartz" class="org.apache.camel.component.quartz.QuartzComponent"> <property name="autoStartScheduler" value="false"/> </bean> Secondly, you need to synchronize somewhere and start the scheduler only if you managed to capture the lock, and then wait for the next moment of its capture (in case the previous server that captured the lock failed or for some reason released it). This can be implemented in Spring in several ways, for example, through ApplicationListener, which allows you to handle context launch events:
<bean class="com.my.hazelcast.HazelcastQuartzSchedulerStartupListener"> <property name="hazelcastInstance" ref="hazelcastInstance"/> <property name="quartzComponent" ref="quartz"/> </bean> We get the following implementation of the class scheduler initialization:
Hidden text
public class HazelcastQuartzSchedulerStartupListener implements ShutdownPrepared, ApplicationListener { public static final String DEFAULT_QUARTZ_LOCK = "defaultQuartzLock"; protected volatile boolean initialized = false; Logger log = LoggerFactory.getLogger(getClass()); Lock lock; protected volatile boolean initialized = false; protected String lockName; protected HazelcastInstance hazelcastInstance; protected QuartzComponent quartzComponent; public HazelcastQuartzSchedulerStartupListener() { super(); log.info("HazelcastQuartzSchedulerStartupListener created"); } public void setLockName(final String lockName) { this.lockName = lockName; } public synchronized Lock getLock() { if (lock == null) { lock = hazelcastInstance.getLock(lockName != null ? lockName : DEFAULT_QUARTZ_LOCK); } return lock; } @Override public void prepareShutdown(boolean forced) { unlock(); } @Required public void setQuartzComponent(QuartzComponent quartzComponent) { this.quartzComponent = quartzComponent; } @Required public void setHazelcastInstance(HazelcastInstance hazelcastInstance) { this.hazelcastInstance = hazelcastInstance; } @Override public synchronized void onApplicationEvent(ApplicationEvent event) { if (initialized) { return; } try { while (true) { try { getLock().lock(); log.warn("This node is now the master Quartz!"); try { quartzComponent.startScheduler(); } catch (Exception e) { unlock(); throw new RuntimeException(e); } return; } catch (OperationTimeoutException e) { log.warn("This node is not the master Quartz and failed to wait for the lock!"); } } } catch (Exception e) { log.error("Error while trying to wait for the lock from Hazelcast!", e); } } private synchronized void unlock() { try { getLock().unlock(); } catch (IllegalStateException e) { log.warn("Exception while trying to unlock quartz lock: Hazelcast instance is already inactive!"); } catch (Exception e) { log.warn("Exception during the unlock of the master Quartz!", e); } } } Thus, we will be able to use periodic tasks recommended by Camel in the way and taking into account the distributed runtime environment. For example:
<route id="quartz-route"> <from uri="quartz://quartz-test/test?cron=*+*+*+*+*+?"/> <log message="Quartz each second message caught ${in.body.class}!"/> <to uri="direct:queue:done-quartz"/> </route> Finite state machine
In addition to simple methods of aggregation (for example, counting amounts), we also often needed to switch the states of aggregators depending on incoming messages, for example, to always remember the current state of the test performed. Finite automata are well suited for this feature. Imagine that we have some test status. For example, TestPassedState. When we receive a TestFailed message for this test, we must switch the state of the aggregator to TestFailedState, and when we receive the TestPassed, we will again switch to TestPassedState. And so on to infinity. On the basis of these transitions, you can draw some conclusions, for example, if a transition occurs TestPassed -> TestFailed, it is necessary to notify all interested parties that the test has broken. And if the reverse transition occurs, then, on the contrary, tell them that everything has become good.
Selecting options for the implementation of such an aggregation strategy, we came to the conclusion that we need some kind of state machine model adapted to the realities of message processing. First, the messages arriving at the input of aggregators are a certain set of objects. Each event has its own type, and therefore easily falls on classes in Java. To describe the types of events, we use the xsd scheme, according to which we generate a set of classes using xjc. These classes are easily serialized and deserialized into xml and json, using jaxb. The states stored in Hazelcast are also represented by a set of classes generated by xsd. Thus, we needed to find an implementation of finite automata, which makes it easy to operate with state transitions based on the message type and the current state type. And I also wanted these transitions to be specified declaratively, and not imperatively, as in many similar libraries. We did not find such a lightweight implementation of such functionality, and therefore we decided to write our own, taking into account our needs and well forming the basis for processing messages coming along the route to Camel.
A small library that implements our needs is called Yatomata (from the words Yet Another auTomata) and is available on github .
It was decided to simplify the FSM model somewhat - for example, the context is set by the current state object, the message also stores some data. However, the transitions are determined only by the types of states and messages. A state machine is defined for a class that is used as an aggregator. For this, the class is annotated with @FSM . An initial state (start) and a set of transitions are defined for it, some of which stop the aggregation (stop = true), automatically sending the accumulated state further along the route.
A set of transitions is declared by the @Transitions annotation and an array of @Transit annotations, each of which can be given a set of initial states (from), an end state (to), a set of events for which this transition is activated (on), and whether this state is the end of the machine (stop). For conversion processing, annotations are provided for @OnTransit , @BeforeTransit , and also @AfterTransit , which can be used to mark public methods inside a class. These methods will be invoked if a matching transition is found that satisfies its signature.
@FSM(start = Undefined.class) @Transitions({ @Transit(on = TestPassed.class, to = TestPassedState.class), @Transit(on = TestFailed.class, to = TestFailedState.class), @Transit(stop = true, on = TestExpired.class), }) public class TestStateFSM { @OnTransit public void onTestFailed(State oldState, TestFailedState newState, TestFailed event){} @OnTransit public void onTestPassed(State oldState, TestPassedState newState, TestPassed event){} } Work with the state machine is as follows:
Yatomata<TestStateFSM> fsm = new FSMBuilder(TestStateFSM.class).build(); fsm.getCurrentState(); // returns instance of Undefined fsm.isStopped(); // returns false fsm.getFSM(); // returns instance of TestStateFSM fsm.fire(new TestPassed()); // returns instance of TestPassedState fsm.fire(new TestFailed()); // returns instance of TestFailedState fsm.fire(new TestExpired()); // returns instance of TestFailedState fsm.isStopped(); // returns true By implementing the AggregationStrategy interface, we created the FSMAggregationStrategy, which is declared in Spring context like this:
<bean id="runnableAggregator" class="com.my.FSMAggregationStrategy"> <constructor-arg value="com.my.TestStateFSM"/> </bean> The simplest implementation of an aggregation strategy when using this state machine may look like this:
Hidden text
public class FSMAggregationStrategy<T> implements AggregationStrategy { private final Yatomata<T> fsmEngine; public FSMAggregationStrategy(Class fsmClass) { this.fsmEngine = new FSMBuilder(fsmClass).build(); } @Override public Exchange aggregate(Exchange state, Exchange message) { Object result = state == null ? null : state.getIn().getBody(); try { Object event = message.getIn().getBody(); Object fsm = fsmEngine.getFSM(); result = fsmEngine.fire(event); } catch (Exception e) { logger.error(fsm + " error", e); } if (result != null) { message.getIn().setBody(result); } return message; } public boolean isCompleted() { return fsmEngine.isCompleted(); } } findings
These techniques allowed us to implement several horizontally scalable services for various purposes. Apache Camel showed its best and met its expectations. It combines declarativity with high flexibility, which in total provides excellent scaling of integration applications with minimal effort to support and add new functionality.
Source: https://habr.com/ru/post/219629/
All Articles