ZooKeeper as a guaranteed delivery system for Yandex.Mail
Yandex processes the incoming stream of millions of letters and files daily. Their number is constantly and continuously increasing. The level of incoming load is uneven, it strongly depends on the time of day and day of the week. In addition, botnet attacks occur periodically.
The task is complicated by the fact that each letter and each file requires additional processing: we classify them, save, retrieve text, recognize images, create indexes. Thanks to this, it is much easier for the user to find the necessary letters or files.

')
Processing can take different times: from the milliseconds required to save a letter to several tens of seconds, such as extracting text from photos.
No matter how much we calculate the power of the system for receiving and processing letters and files, we are never immune to situations where the input flow significantly exceeds our expectations.
In these cases, help us turn. They allow you to smooth out bursts of input load: buy time and wait until the letter processing cluster becomes available.
The queue for processing documents is not much different from the live queue in the store or by mail. There they also arise for the same reason: it is impossible to serve customers instantly. However, an important advantage of the queue for processing documents in Yandex Personal Services is that there are only letters and files in it, the user does not have to wait. In fact, this is a buffer into which you can quickly write files and letters, and when the load on the processing system drops, quickly read it all.
As a rule, two programs work with the queue: one writes data to it, the other reads it out and sends it to the consumer.
The program for writing to the queue should be as simple as possible so as not to introduce any additional delays in accepting the task, but we do not want to make another queue for the placement in the main one. And the reader from the queue already interacts with various functional elements of the services: Mail / Disk or other products.
There can be several data reading programs, each of which serves for specialized data processing. A reading program can run significantly longer than a writing program, since it has additional functionality. Therefore, the queue should be able to store data for a period of time sufficient for processing of letters / files by its sources.
Mostly queues are used where there is an uneven input load and you want to perform operations on data. In particular, at the reception of letters to the mail and files to disk.
When using queues, it is important to consider the following rules:
Letters fly into the mail and fall into the Mx-Front cluster, whose programs process the letters and save them to mail storages.
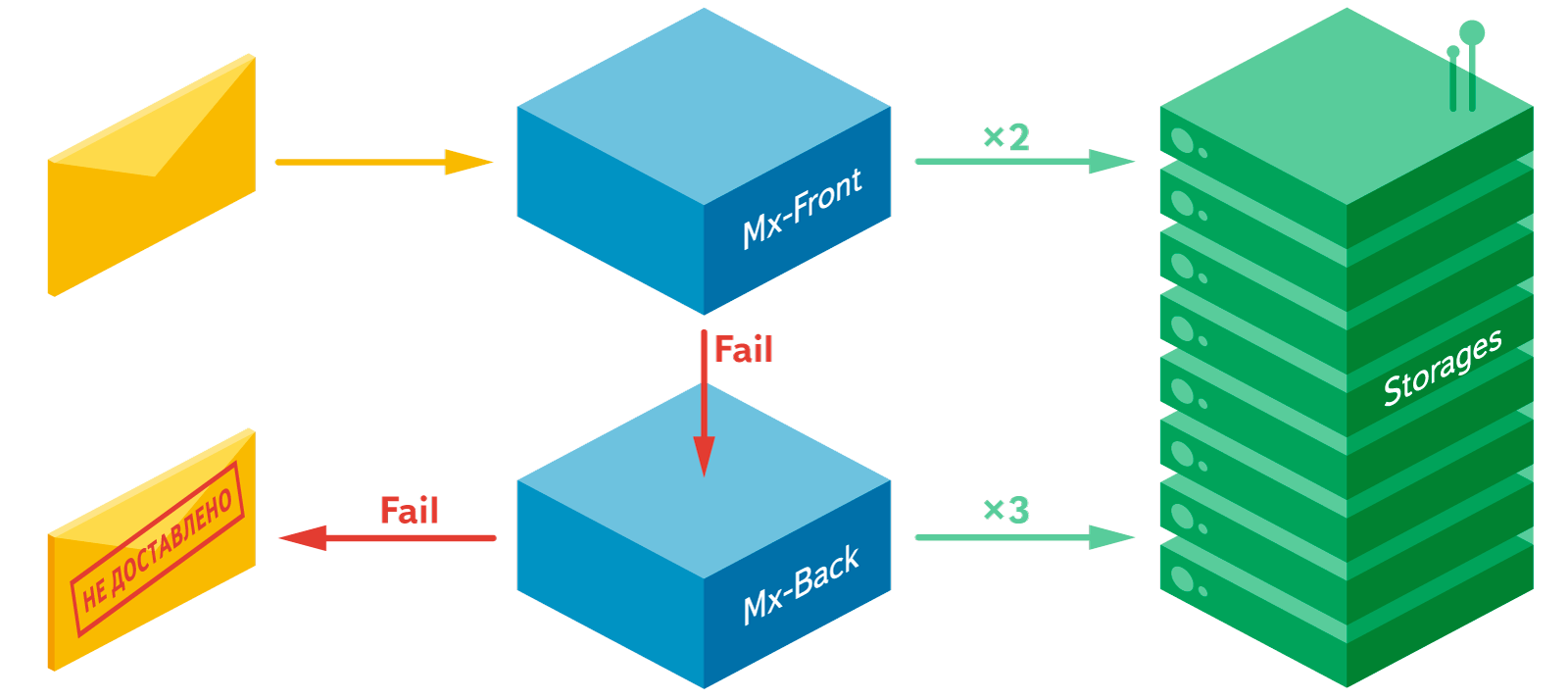
If the lettering fails, the letter goes to the Mx-Back cluster, which consists of a queue on PostFix and a number of letter-laying and analysis programs. Mx-Back cluster programs make many attempts to put a letter in storage for a long time, but if it fails, the letter is considered undeliverable. If the lettering succeeds, the letter is sent to the Services cluster, from which it is already delivered to the search.
Since the Post Office service is part of the mail, the tab system is also built into the post office. The only difference is that the service itself should not store the letters themselves. The service requires only meta-information from the letters. And Postofis allows you to look at the mail from the sender, and not from the recipient. Therefore, as a queue, we decided to try other solutions other than PostFix.
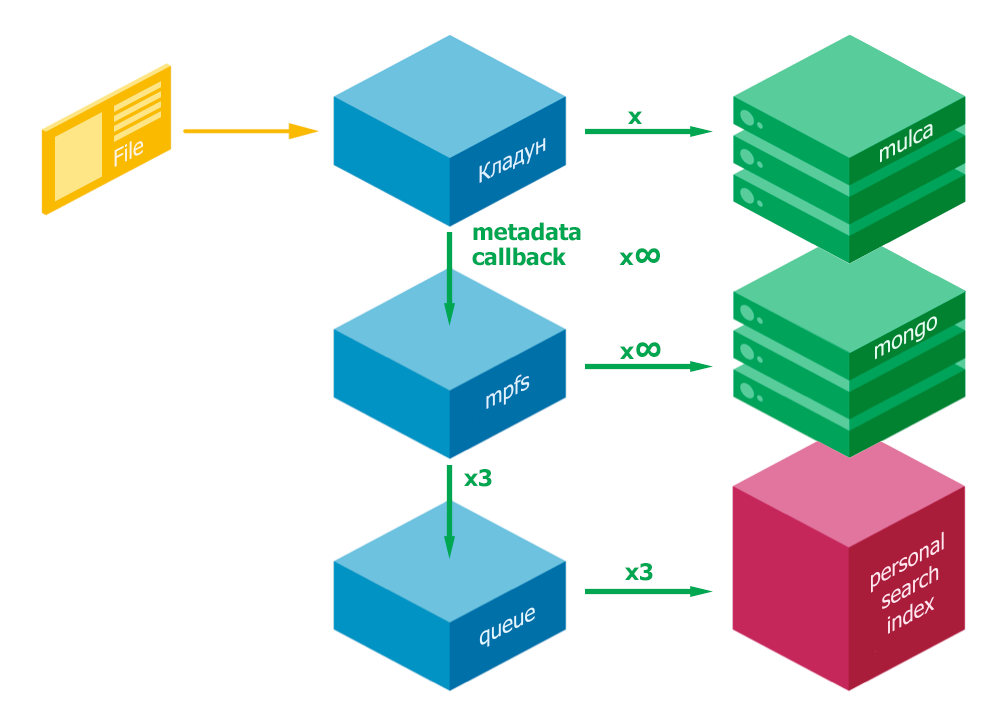
Files fly into a treasure chamber that puts files in storage (mulca) and sends them to the mpfs cluster. MPFS stores meta-information about files in the metadata store (mongo DB) and queues for the delivery of files in the search. Further files from the queue fall into the search.
PostFix - queue at the entrance to the Mail in three places: mxfront, mxback, services
The advantage of this queue is only one, it is very easy to use.
The disadvantages are much more:
RabbitMQ - used to inform Mail Search about deleting emails from a mailbox. The main advantage of this queue is the ability to randomly read data. The disadvantages include all the disadvantages of a non-network queue listed above.
Queue in Mongo DB - is used in Disk for all operations with metadata: copying, moving files on Disk and indexing files for search.
Advantages - the network queue. If a single server drops out, the data is saved.
The main disadvantage is that the queue is cleared by different handlers that are not synchronized with each other, so the ordering of tasks is not performed.
Existing solutions are limited by the tasks to be solved or do not provide guarantees of delivery to the recipient. Therefore, we decided to test Apache ZooKeeper - a queue with guaranteed delivery. In addition to guaranteed delivery, it has two other important advantages:
Of course, there are drawbacks, but they are not so significant:
We placed three servers in the minimum configuration in different data centers in order to be insured against disconnecting one of them entirely. Moreover, the unavailability of one of the data centers for the company is a typical operating mode. So-called exercises are held weekly to ensure that Yandex services will continue to operate if one of the data centers fails.
Considering the rich experience of using queues in personal services of Yandex, the declared technical characteristics of the above listed queues, as well as our internal requirements for the reliability of data delivery, we decided to take a chance and try Zookeeper in a new personal service of Yandex Post Office.
We conducted many experiments, here are some of them:
What we did, it was necessary to test it functionally and under load. This is how we did it ...
In order to qualitatively carry out functional and load testing of the delivery system, we first described the cases in which the queue should “deliver”. All possible situations arise from the product requirements for the reliability of the delivery system and the architectural features of building systems in our company.
First, the guaranteed delivery protocol requires an odd number of operating instances of the guaranteed delivery system - these are at least three simultaneously running programs, and preferably five.
Secondly, in Yandex, a standard is the simultaneous placement of any systems in different data centers - this allows the service to be maintained in the event of a power outage in a DC or other abnormal phenomena in a given DC.
Third, we deliberately complicated our lives and decided to combine the delivery system requirement and the Yandex requirements, as a result, we placed the delivery system program on three different servers located in three different data centers.
On the one hand, the solution we have chosen complicates the overall architecture and leads to various undesirable effects in the form of long inter-center pings, on the other hand, we get a system protected from atomic war.
The result was the following architecture: a proxy that receives data, a queue, a storage.
Proxies are located in five data centers on ten servers. The queue is located in three data centers on three servers. Any SQL and noSQL storage can be selected as storage, and any number can be any storage. In our case, we chose noSQL storage based on Lucene as storage, and placed it on two servers in 2 different data centers.
Before commissioning, we conducted functional and load testing of the guaranteed delivery system.
Testing was carried out sequentially in four modes:
According to the test results, we closed our eyes and, taking responsibility on our head, we decided to run the whole system in production. As expected, testing is testing, and real life creates situations that you never predict in advance. Sometimes we end up with a pool of connections, sometimes we take a long time to deliver data to one of the backends, and for some reason, one of the backends is up to date, and the second is behind.
In a word, in the course of operation, more and more new situations arise that we successfully fix, and our turn, launched back in November, is gradually turning from experimental technology into a good stand-alone product.
The task is complicated by the fact that each letter and each file requires additional processing: we classify them, save, retrieve text, recognize images, create indexes. Thanks to this, it is much easier for the user to find the necessary letters or files.
')
Processing can take different times: from the milliseconds required to save a letter to several tens of seconds, such as extracting text from photos.
No matter how much we calculate the power of the system for receiving and processing letters and files, we are never immune to situations where the input flow significantly exceeds our expectations.
In these cases, help us turn. They allow you to smooth out bursts of input load: buy time and wait until the letter processing cluster becomes available.
What is a queue
The queue for processing documents is not much different from the live queue in the store or by mail. There they also arise for the same reason: it is impossible to serve customers instantly. However, an important advantage of the queue for processing documents in Yandex Personal Services is that there are only letters and files in it, the user does not have to wait. In fact, this is a buffer into which you can quickly write files and letters, and when the load on the processing system drops, quickly read it all.
As a rule, two programs work with the queue: one writes data to it, the other reads it out and sends it to the consumer.
The program for writing to the queue should be as simple as possible so as not to introduce any additional delays in accepting the task, but we do not want to make another queue for the placement in the main one. And the reader from the queue already interacts with various functional elements of the services: Mail / Disk or other products.
There can be several data reading programs, each of which serves for specialized data processing. A reading program can run significantly longer than a writing program, since it has additional functionality. Therefore, the queue should be able to store data for a period of time sufficient for processing of letters / files by its sources.
Mostly queues are used where there is an uneven input load and you want to perform operations on data. In particular, at the reception of letters to the mail and files to disk.
When using queues, it is important to consider the following rules:
- The queue is needed where there is an uneven load on the processing system.
- The queue helps smooth out unevenness and serves as some kind of buffer between the input and the processing system.
- The processing system must cope with the entire input load at a certain limited time interval, otherwise no queues will help.
The architecture of the system of receiving letters to the Post:
Letters fly into the mail and fall into the Mx-Front cluster, whose programs process the letters and save them to mail storages.
If the lettering fails, the letter goes to the Mx-Back cluster, which consists of a queue on PostFix and a number of letter-laying and analysis programs. Mx-Back cluster programs make many attempts to put a letter in storage for a long time, but if it fails, the letter is considered undeliverable. If the lettering succeeds, the letter is sent to the Services cluster, from which it is already delivered to the search.
The architecture of the data reception system in the Post Office:
Since the Post Office service is part of the mail, the tab system is also built into the post office. The only difference is that the service itself should not store the letters themselves. The service requires only meta-information from the letters. And Postofis allows you to look at the mail from the sender, and not from the recipient. Therefore, as a queue, we decided to try other solutions other than PostFix.
The architecture of the file receiving system in the Disk:
Files fly into a treasure chamber that puts files in storage (mulca) and sends them to the mpfs cluster. MPFS stores meta-information about files in the metadata store (mongo DB) and queues for the delivery of files in the search. Further files from the queue fall into the search.
What are the queues
PostFix - queue at the entrance to the Mail in three places: mxfront, mxback, services
The advantage of this queue is only one, it is very easy to use.
The disadvantages are much more:
- calculated only for mail tasks and works using the smtp protocol;
- it works only within one server, so in case of a server crash, all data disappears and there is no synchronization of the sequence between different servers;
- cannot be read from any place in the queue, only sequential reading is possible;
- Returning the task to the queue is possible only through the start.
RabbitMQ - used to inform Mail Search about deleting emails from a mailbox. The main advantage of this queue is the ability to randomly read data. The disadvantages include all the disadvantages of a non-network queue listed above.
Queue in Mongo DB - is used in Disk for all operations with metadata: copying, moving files on Disk and indexing files for search.
Advantages - the network queue. If a single server drops out, the data is saved.
The main disadvantage is that the queue is cleared by different handlers that are not synchronized with each other, so the ordering of tasks is not performed.
ZooKeeper
Existing solutions are limited by the tasks to be solved or do not provide guarantees of delivery to the recipient. Therefore, we decided to test Apache ZooKeeper - a queue with guaranteed delivery. In addition to guaranteed delivery, it has two other important advantages:
- data safety and operation when one of the servers in the queue is unavailable;
- ability to distribute heads queue at different data centers.
Of course, there are drawbacks, but they are not so significant:
- an excess number of servers is required - at least three, and preferably five;
- it takes time to synchronize data in all heads of the queue.
We placed three servers in the minimum configuration in different data centers in order to be insured against disconnecting one of them entirely. Moreover, the unavailability of one of the data centers for the company is a typical operating mode. So-called exercises are held weekly to ensure that Yandex services will continue to operate if one of the data centers fails.
Considering the rich experience of using queues in personal services of Yandex, the declared technical characteristics of the above listed queues, as well as our internal requirements for the reliability of data delivery, we decided to take a chance and try Zookeeper in a new personal service of Yandex Post Office.
Zookeeper does not start the first time
We conducted many experiments, here are some of them:
- We tried through ZooKeeper to transfer data in an amount equal to the number of storages. The default is two backends. Received 8 thousand RPS (requests per second) for data transmission in one copy. And 2.5 thousand RPS for data transmission in duplicate.
We realized that we need to have at least three backends - two searches + logstore, eventually transferred data three times through ZooKeeper and received 500 RPS - this is very poor performance, since there may be much more than three services that want to get the same data, and this means that each time we will lose performance on data copying and negotiation protocols between queue servers. - Having carefully considered all the problems from the first stage of the experiments, we decided to use ZooKeeper as a ring buffer. In this case, in ZooKeeper, the data is always added up only once, and each backend contains its position in the queue, to which he read the data from the queue. In this case, if the backend falls, it rises and subtracts data from the queue from the position it has saved. This solution has two important advantages: firstly, high performance (8 thousand RPS) due to the fact that the data is stored in one copy only. Secondly, an unlimited number of backends that use the same data. Thus, problems with queue performance were solved.
- But here we learned that this is not all. Since ZooKeeper can only work with data in memory, and the inaccessibility of one of the storage servers (backend) can reach several days, then ZooKeeper itself requires storage. Apache Lucene was used as this storage .
What we did, it was necessary to test it functionally and under load. This is how we did it ...
Test bench architecture
In order to qualitatively carry out functional and load testing of the delivery system, we first described the cases in which the queue should “deliver”. All possible situations arise from the product requirements for the reliability of the delivery system and the architectural features of building systems in our company.
First, the guaranteed delivery protocol requires an odd number of operating instances of the guaranteed delivery system - these are at least three simultaneously running programs, and preferably five.
Secondly, in Yandex, a standard is the simultaneous placement of any systems in different data centers - this allows the service to be maintained in the event of a power outage in a DC or other abnormal phenomena in a given DC.
Third, we deliberately complicated our lives and decided to combine the delivery system requirement and the Yandex requirements, as a result, we placed the delivery system program on three different servers located in three different data centers.
On the one hand, the solution we have chosen complicates the overall architecture and leads to various undesirable effects in the form of long inter-center pings, on the other hand, we get a system protected from atomic war.
The result was the following architecture: a proxy that receives data, a queue, a storage.
Proxies are located in five data centers on ten servers. The queue is located in three data centers on three servers. Any SQL and noSQL storage can be selected as storage, and any number can be any storage. In our case, we chose noSQL storage based on Lucene as storage, and placed it on two servers in 2 different data centers.
Functional and load testing
Before commissioning, we conducted functional and load testing of the guaranteed delivery system.
Testing was carried out sequentially in four modes:
- Normal operation: all servers are available. We send data through a queue with a load of 500 RPS during the day, we check that all data is delivered to the backend.
- One of the queue servers is not available. We start sending data through the queue. Disable one of the heads of the queue for an hour. We continue to send letters and check that the data is delivered to the backends.
- One of the backend servers is not available. We start sending data through the queue. We disconnect one of the backends for an hour, then we turn it on and after a certain period of time we check that the data reached the backend.
- One of the queue servers and one of the backend servers are not available. We start sending data through the queue. Disable one of the heads of the queue and one of the heads of the backend for one hour. Sending data does not stop. We check that the data is delivered to the working backend. An hour later, turn on the disabled heads of the queue and backend. We check that after switching on the data fall into both backends and that the data in each of them is the same.
Implementation
According to the test results, we closed our eyes and, taking responsibility on our head, we decided to run the whole system in production. As expected, testing is testing, and real life creates situations that you never predict in advance. Sometimes we end up with a pool of connections, sometimes we take a long time to deliver data to one of the backends, and for some reason, one of the backends is up to date, and the second is behind.
In a word, in the course of operation, more and more new situations arise that we successfully fix, and our turn, launched back in November, is gradually turning from experimental technology into a good stand-alone product.
Source: https://habr.com/ru/post/219617/
All Articles