Using MongoDB instead of memcached: to be or not to be?
 On the topic of "using MongoDB instead of memcached" there are a lot of success stories. It seems that there is a wide class of tasks for which the idea works well: first of all, these are projects where cache tagging is used extensively . But if you try, you will notice that MongoDB lacks the function of deleting entries from the cache that are the least readable (LRU - Least Recently Used). How to keep cache size within reasonable limits? LRU is, by the way, memcached "horse"; You can write to memcached without worrying about the overflow of your cache; but what about MongoDB?
On the topic of "using MongoDB instead of memcached" there are a lot of success stories. It seems that there is a wide class of tasks for which the idea works well: first of all, these are projects where cache tagging is used extensively . But if you try, you will notice that MongoDB lacks the function of deleting entries from the cache that are the least readable (LRU - Least Recently Used). How to keep cache size within reasonable limits? LRU is, by the way, memcached "horse"; You can write to memcached without worrying about the overflow of your cache; but what about MongoDB?Thinking over this, I wrote in Python a small utility called CacheLRUd (laid out on GitHub). This is a daemon to support LRU-delete records in various DBMS (first of all, of course, in MongoDB). A farm of such demons (one for each MongoDB replica) monitors the size of the collection, periodically deleting the records that are most rarely readable. Tracking the facts of reading a cache entry is decentralized (without a single point of failure) using a UDP-based protocol (why is that so? Because the “naive” option is to write from the application to the MongoDB master database with every read operation is a bad idea, especially if the master database will be in another data center). Read the details below.
But why?
Why might I need to replace memcached with MongoDB? Let's try to figure it out. The concept of "cache" has two different types of use.
')
- The cache is used to reduce the load on the failing database (or other subsystems). For example, suppose we have 100 requests per second to read a certain resource. Turning on caching and setting a small cache expiration time (for example, 1 second), we thereby reduce the load on the database by 100 times: now, only one query out of a hundred reaches the DBMS. And we almost do not need to fear that the user will see outdated data: after all, the time of obsolescence is very short.
- There is another type of cache: this is a cache of more or less static pieces of a page (or even the entire page), and it is used to reduce the time it takes to form a page (including those rarely visited). It differs from the first in that the cached entries have a long lifetime (hours or even days), which means that the question arises: how to ensure that the cache contains relevant data, how to clean it? For this purpose tags are used: each piece of data in the cache that is related to a certain large resource X is tagged with one or another tag. When the resource X is changed, the command “clear tag X” is given.
For the first use of the cache, nothing better than memcached seems to be invented. But for the second, memcached is stalling, and here the idea of “MongoDB instead of memcached” can come to the rescue. Perhaps this is your case if your cache:
- Relatively small (upper limit - hundreds of gigabytes).
- Contains many “long-lived” records that become obsolete in hours and days (or never become obsolete at all).
- You essentially use tags and rely on the fact that the tag cleaning operation should work reliably.
- I would like to make the cache common and equally easily accessible (that is, replicable) on all the cluster machines, including several data centers.
- You don’t want to worry when one of the cache machines stops being available for a while.
MongoDB and its replication with an automatic failover wizard (turning a replica into a master at the “death” of the latter) guarantee the reliability of the clearing of one or another tag. In memcached, this is a problem: memcached servers are independent of each other, and to remove a tag you need to “go” to each of them with the cleanup command. But what if at this moment any of the memcached servers is unavailable? It will “lose” the cleaning command and will start sending out old data; MongoDB solves this problem.
And finally, MongoDB is very fast in reading operations, because it uses an event-oriented mechanism for working with connections and memory mapped files, i.e. reading is done directly from the RAM with enough of it, and not from the disk. (Many people write that MongoDB is as fast as memcached, but I don't think so: just the difference between them is sinking with a huge margin against the background of network delays.)
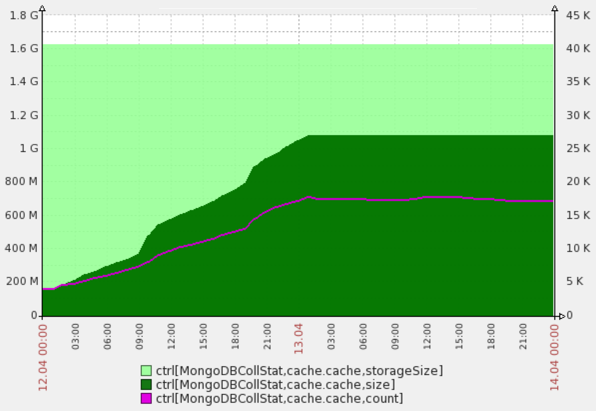
Here is the result of CacheLRUd on one not very loaded project. It can be seen that the size of the collection with the cache is indeed kept constant at the 1G level specified in the config.
Install CacheLRUd
## Install the service on EACH MongoDB NODE:
cd / opt
git clone git@github.com: DmitryKoterov / cachelrud.git
ln -s /opt/cachelrud/bin/cachelrud.init /etc/init.d/cachelrud
## Configure:
cp /opt/cachelrud/cachelrud.conf /etc/cachelrud.conf # and then edit
## For RHEL (RedHat, CentOS):
chkconfig --add cachelrud
chkconfig cachelrud on
## ... or for Debian / Ubuntu:
update-rc.d cachelrud defaults
How the demon works
There are no miracles, and your application must tell the CacheLRUd daemon (daemon farm) what cache entries it reads. The application obviously cannot do this in synchronous mode (for example, updating the last_read_at field in the cache document in the MongoDB master database), because a) the master database may be in another data center relative to the current web application muzzle, b) MongoDB uses the TCP protocol, which threatens timeouts and client “hangs” in case of communication instability, c) it is unsuitable to write at each reading, this does not work in distributed systems.
To solve the problem, the UDP protocol is used: the application sends UDP packets with a list of recently read keys to one or another CacheLRUd daemon. Which one - you can decide on your own, depending on the load:
- If the load is relatively low, send UDP packets to the CacheLRUd daemon that is “sitting” on the current MongoDB master node (the rest will simply stand idle and wait for their turn). Determining who is currently the master on the application side is very easy: for example, in PHP, MongoClient :: getConnections is used for this.
- If one daemon fails, then you can send UDP messages, for example, to the CacheLRUd daemons in the current data center.
Details are described in the documentation .
What else is useful
CacheLRUdWrapper : this is a simple class for communicating with CacheLRUd from the application code in PHP, wrapping the standard Zend_Cache_Backend (although this class is for Zend Framework 1; if you rewrite it for ZF2 or for other languages in general, I will be glad to pull-request).
Zend_Cache_Backend_Mongo : this is the implementation of Zend_Cache_Bachend for MongoDB from the neighboring GitHub repository. Wrap an object of this class in CacheLRUdWrapper, and get an interface for working with LRU cache in MongoDB in ZF1 style:
$ collection = $ mongoClient-> yourDatabase-> cacheCollection;
$ collection-> w = 0;
$ collection-> setReadPreference (MongoClient :: RP_NEAREST); // allows reading from the master as well
$ primaryHost = null;
foreach ($ mongoClient-> getConnections () as $ info) {
if (in_array ($ info ['connection'] ['connection_type_desc'], array ("STANDALONE", "PRIMARY"))) {
$ primaryHost = $ info ['server'] ['host'];
}
}
$ backend = new Zend_Cache_Backend_Mongo (array ('collection' => $ collection));
if ($ primaryHost) {
// We have a primary (no failover in progress etc.) - use it.
$ backend = new Zend_Cache_Backend_CacheLRUdWrapper (
$ backend,
$ collection-> getName (),
$ primaryHost,
null
array ($ yourLoggerClass, 'yourLoggerFunctionName')
);
}
// You may use the $ backend below this line.
Share in the comments: what do you think about all this?
Source: https://habr.com/ru/post/219481/
All Articles