Getting started with the graph database Neo4j
The following task arose in our project - there is a base with a large number of goods, at the level of hundreds of thousands. Each product has hundreds of dynamically generated characteristics. It is necessary to provide fast filtering by goods for a set of different characteristics. Response generation time should be no more than 0.3 seconds, you need to maintain sophisticated logic in style.
A typical example of such a functional is hotline.ua/computer/myshi-klaviatury
')

Everything is implemented within MySQL + Symfony2 / Doctrine, the speed is unsatisfactory - the answers are formed within 1-10 seconds. My attempts to optimize all this economy - under cat.
The hotline has a more advanced version implemented - with a hint how many goods will remain after the activation of the criterion. For example, if you select the “Bluetooth” filter, then after loading the page next to the “Mouse Sensor Type - Optical” filter there will be the number 17. In fact, for such an implementation it is necessary not only to select the criteria, but also to count the number of items for each remaining filter beforehand. its activation.
To solve this problem, I decided to try out the graph database Neo4j . For superficial reference, I recommend reading this post .
For each product, create a separate node; in the node properties, store the product id in the MySQL database. For each criterion to create its own node, in the properties store the id of the criterion. Next, associate all the nodes of the goods with criteria nodes that are suitable for the product. When changing the characteristics of the product or the properties of the criteria to update the connection between the nodes.
Considering that I never worked with graph databases - I decided to deploy Neo4j locally, examine Cypher at a basic level and try to implement the required logic. If everything works out - test the speed of work for the base of 1 million products, each has 500 characteristics.
Deploying the system is quite simple - download the distribution and install it.
The Neo4j server has RestAPI, for php there is a neo4jphp library. There is also a bundle for integration with symfony2 - klaussilveira / neo4j-ogm-bundle .
The distribution kit includes a web server and an application for working with it, by default http: // localhost: 7474 /
There is also an old version of the client , with different functionality.
As documentation it is convenient to use short documentation . Code examples are in graphgist. In theory, they should be executed there online, but now it does not work. To view the code, follow the link from the graphgist (for example, here ) and click the Page Source button.
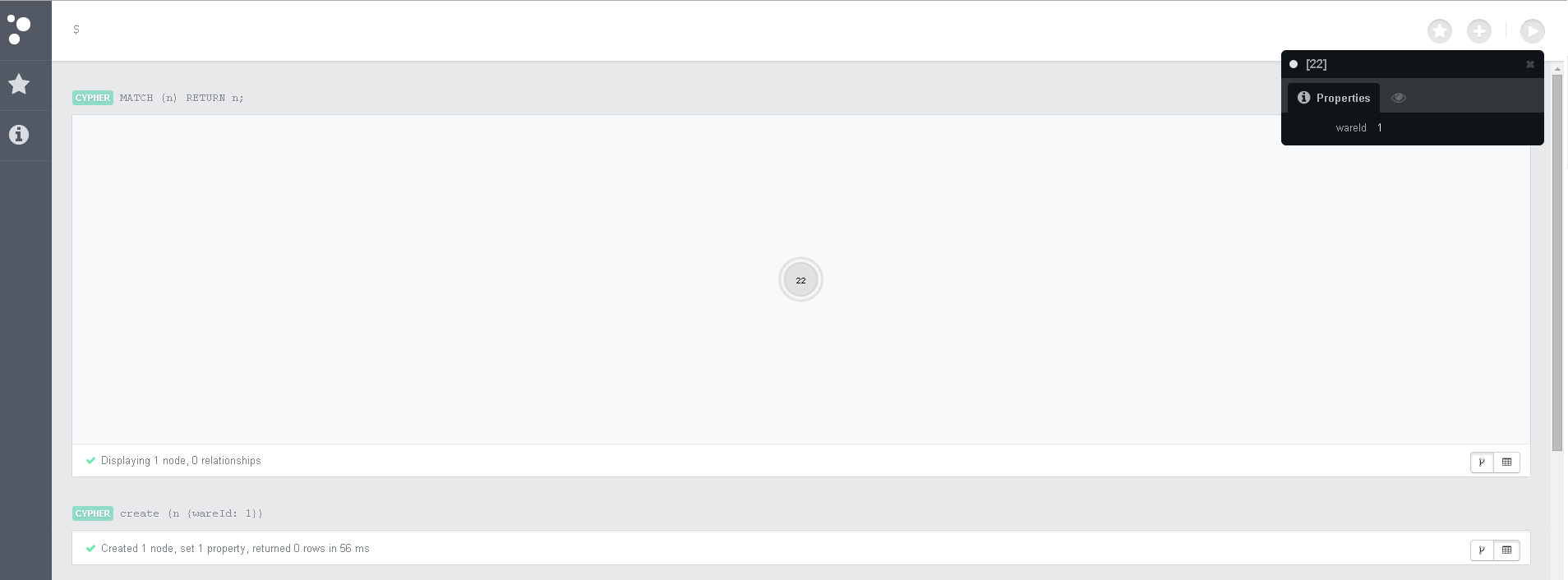
For experiments with Neo4j, it is very convenient to use the built-in web client. There you can perform Cypher requests and view the response to requests along with connections and characteristics of the nodes.
Simple Cypher Team
Creating a node with a label
Select all nodes
Counter
Create 2 related nodes
Link 2 existing nodes
Delete all related nodes
Delete all unbound nodes - if you try to run this command in the database where there are related nodes, it will not work. It is necessary to delete the connected nodes first.
Choose products suitable for criterion 3
Immediately several Cypher commands the web client can not perform. They say that the old client can do this, but I have not found such an opportunity. Therefore, you need to copy 1 line.
You can create a set of nodes with connections by one command, you need to give different names to the nodes, you can give names to the links
Get this structure. If you look less clear, you can rearrange the node with the mouse.

It's time to test the speed of filling the base and simple samples from a large base.
To do this, we clone neo4jphp
The basic description of this library is in this post , so I will immediately lay out the code to fill out the test database samples / test_fill_1.php
I left the base filling script for the night. After about 4 hours, the script stopped adding data and the Neo4j service started loading the server 100%. In the morning, as a result of the work, 78300 products from 8 categories of goods were inserted.
The results of the test fill database - about 20 products per second with 200-400 links. Not a very good result - Mysql and Cassandra gave out about 10-20 thousand inserts per second (10 fields, 1 primary index, 1 index). But the insertion speed is not critical for us - we can update the data graph in the background after editing the product. But the speed of data sampling is critical.
The size of the test database on the disk is 1781 megabytes. It holds 78300 products, 4000 criteria, 15660000-31320000 links. The total number of objects (nodes and connections) is less than 32 million - an average of 55 bytes per entity. Too much, as for me, but the main requirement is still the speed of the samples, and not the size of the base.
The first attempt to test the sampling rate failed - the Neo4j server again “went away” to the 100% processor load mode and in a few minutes it did not respond to the request.
To move on, you need to figure out how to optimize the query in Neo4j. At first, I wanted to limit the starter set of nodes in the sample using the START instruction.
For this, you need to have indexes in the database. In Neo4j, I did not find a command to view the list of current indexes, but in the Neo4j web application you can type a command
You can add indexes with the command
You can create a unique index with the command
Indices added by the commands above cannot be used in the START directive. They say that they can only be used in where
If I understand the documentation correctly, you can safely use WHERE instead of START.
Thus was born the first working request
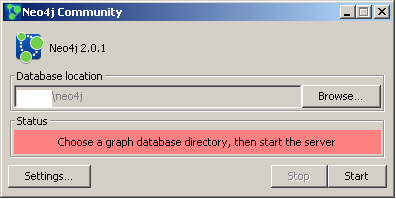
No indices were found in our test database, so we will create another database for the test in another way. I did not find the ability to create independent data sets (an analogue of the database in MySQL) in Neo4j. Therefore, for testing, I simply changed the path to the data storage in the Neo4j Community settings (Database location)
Attentive readers may have found a couple of comments in the test_fill_1.php code, namely
In batch mode in Neo4jphp, I could not add tags to the nodes, and for some reason the indices were not preserved. Considering that Cypher ceased to be a Chinese diploma for me, I decided to fill the base hardcore - on pure Cypher. So test_fill_2.php
The speed of adding data was predictably higher than in the first version.
A test script with the addition of 30,000 nodes and 500,000 - 1,000,000 connections on cypher worked in 140 seconds, the base took 62 megabytes on disk. When I tried to run the script with c $ waresCount = 1000 (not to mention 10000 products), I received the error “Stack overflow error”. I rewrote the script using.
This led to a catastrophic drop in the speed of work, the modified script worked for about an hour. I decided to test the sampling rate according to several criteria and return to the question of quick data insertion later.
The script above worked in 0.02 seconds. In general, this is quite acceptable, but the problem of how to quickly maintain a large number of connections between nodes while updating product properties remains.
I decided “to clear my conscience” to try out MySQL as a repository. Connections between nodes will be stored in a separate table without additional information.
Test script to fill the base below
Filling the base took 12 seconds. The size of the table is 37 megabytes. Search by 2 criteria takes 0.0007 seconds
Under mysql there is a full-fledged graph data storage - but I did not test it. Judging by the documentation, it is much more primitive than Neo4j.
Neo4j is a very cool thing . A query like “Selecting contacts of users who liked movie actors who starred in films that sounded soundtracks, which were written by musicians I put like” in Neo4j is trivial. Like that
For SQL, this is much more troublesome.
It is incorrect to compare a full graph database with a bare index table in MySQL, but in the context of solving my problem, the use of Neo4j did not give any advantages .
UPDATE . Changed url'y pictures, in theory should all be loaded.
UPDATE 2 . They offered several options - MongoDB, elasticsearch, solr, sphinx, OrientDB. I plan to test MongoDB, I'll post the test results right there.
(1 = true AND (2 < 100)) OR (1 = false AND (3 > 17)) ... AND\OR A typical example of such a functional is hotline.ua/computer/myshi-klaviatury
')
Everything is implemented within MySQL + Symfony2 / Doctrine, the speed is unsatisfactory - the answers are formed within 1-10 seconds. My attempts to optimize all this economy - under cat.
Terminology of the task of filtering goods (in simplified form)
- characteristic - a certain property of the goods. For example, the amount of memory.
- product template - a set of all possible characteristics of the same type of goods, for example - a list of possible characteristics of computer mice. When adding a new product, the administrator can select the characteristics within the template. It is impossible to add a new characteristic for one product - you need to add a characteristic to the template for this product. At the same time, this feature will be available for all products using this template.
- product group - products based on a single template. For example, computer mice. Filtering is done only for products from one group.
- criterion - a logical rule that consists of a set of formal requirements for the characteristics of the goods. For example, a “gaming mouse” is a set of performance requirements (size not miniature) AND (laser sensor) AND (sensor resolution not less than 1500)
- filter - a group of criteria for the same type of goods. Depending on the criteria, they can be combined via AND or OR
The hotline has a more advanced version implemented - with a hint how many goods will remain after the activation of the criterion. For example, if you select the “Bluetooth” filter, then after loading the page next to the “Mouse Sensor Type - Optical” filter there will be the number 17. In fact, for such an implementation it is necessary not only to select the criteria, but also to count the number of items for each remaining filter beforehand. its activation.
To solve this problem, I decided to try out the graph database Neo4j . For superficial reference, I recommend reading this post .
Terminology of Neo4j and graph databases in general.
- graph database , graph database - a database built on graphs - nodes and links between them
- Cypher is a language for writing queries to the Neo4j database (approximately, like SQL in MYSQL)
- node , node - an object in the database, a graph node. The number of nodes is limited to 2 to the extent of 35 ~ 34 billion
- node label , node label - is used as a conditional “node type”. For example, movie nodes can be associated with actor nodes. The node labels are case-sensitive , and Cypher produces no errors if you type the wrong name in the register.
- relation , a connection is a connection between two nodes, a graph edge. The number of links is limited to 2 to the extent of 35 ~ 34 billion
- relation identirfier , the type of connection is in Neo4j for connections. The maximum number of link types is 32767
- properties , node properties - a set of data that can be assigned to a node. For example, if a node is a product, then in the properties of the node, you can store the product id from the MySQL database.
- node ID , node ID - the node 's unique identifier. By default, it is this ID that is displayed when viewing the result. How to use it in Cypher queries I did not find
Problem Solving Scheme
For each product, create a separate node; in the node properties, store the product id in the MySQL database. For each criterion to create its own node, in the properties store the id of the criterion. Next, associate all the nodes of the goods with criteria nodes that are suitable for the product. When changing the characteristics of the product or the properties of the criteria to update the connection between the nodes.
The first solution is with Neo4j
Considering that I never worked with graph databases - I decided to deploy Neo4j locally, examine Cypher at a basic level and try to implement the required logic. If everything works out - test the speed of work for the base of 1 million products, each has 500 characteristics.
Deploying the system is quite simple - download the distribution and install it.
The Neo4j server has RestAPI, for php there is a neo4jphp library. There is also a bundle for integration with symfony2 - klaussilveira / neo4j-ogm-bundle .
The distribution kit includes a web server and an application for working with it, by default http: // localhost: 7474 /
There is also an old version of the client , with different functionality.
As documentation it is convenient to use short documentation . Code examples are in graphgist. In theory, they should be executed there online, but now it does not work. To view the code, follow the link from the graphgist (for example, here ) and click the Page Source button.
For experiments with Neo4j, it is very convenient to use the built-in web client. There you can perform Cypher requests and view the response to requests along with connections and characteristics of the nodes.
Simple Cypher Team
Creating a node with a label
create (n:Ware {wareId: 1}); Select all nodes
MATCH (n) RETURN n; Counter
MATCH (n:Ware {wareId:1}) RETURN "Our graph have "+count(*)+" Nodes with label Ware and wareId=1" as counter; Create 2 related nodes
CREATE (n{wareId:1})-[r:SUIT]->(m{criteriaId:1}) Link 2 existing nodes
MATCH (a {wareId: 1}), (b {criteriaId: 2}) MERGE (a)-[r:SUIT]->(b) Delete all related nodes
match (n)-[r]-() DELETE n,r; Delete all unbound nodes - if you try to run this command in the database where there are related nodes, it will not work. It is necessary to delete the connected nodes first.
match n DELETE n; Choose products suitable for criterion 3
MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}) RETURN a; Immediately several Cypher commands the web client can not perform. They say that the old client can do this, but I have not found such an opportunity. Therefore, you need to copy 1 line.
You can create a set of nodes with connections by one command, you need to give different names to the nodes, you can give names to the links
CREATE (w1:Ware{wareId:1})-[:SUIT]->(c1:Criteria{criteriaId:1}), (w2:Ware{wareId:2})-[:SUIT]->(c2:Criteria{criteriaId:2}), (w3:Ware{wareId:3})-[:SUIT]->(c3:Criteria{criteriaId:3}), (w4:Ware{wareId:4})-[:SUIT]->(c1), (w5:Ware{wareId:5})-[:SUIT]->(c1), (w4)-[:SUIT]->(c2), (w5)-[:SUIT]->(c3); Get this structure. If you look less clear, you can rearrange the node with the mouse.
Intermediate speed tests Neo4j
It's time to test the speed of filling the base and simple samples from a large base.
To do this, we clone neo4jphp
git clone https://github.com/jadell/neo4jphp.git The basic description of this library is in this post , so I will immediately lay out the code to fill out the test database samples / test_fill_1.php
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $neoWares = new NodeIndex($neoClient, 'Ware'); $neoCriterias = new NodeIndex($neoClient, 'Criteria'); $neoWareLabel = $neoClient->makeLabel('Ware'); $neoCriteriaLabel = $neoClient->makeLabel('Criteria'); $wareTemplatesCount = 200; // $criteriasCount = 500; // $waresCount = 10000; // $commitWares = 100; // , 1 batch $minRelations = 200; // $maxRelations = 400; // $time = time(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $neoClient->startBatch(); print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ..."; $criterias = array(); // for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { $c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() $criterias[] = $c; } // for($wareId = 1;$wareId <=$waresCount;$wareId++) { $w = $neoClient->makeNode()->setProperty('wareId', $wareTemplateId * $waresCount + $wareId)->save(); // ->addLabels(array($neoWareLabel)) - commitBatch $neoWares->add($c, 'wareId', $wareTemplateId * $waresCount + $criteriaId); // for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) { $w->relateTo($criterias[array_rand($criterias)], "SUIT")->save(); } if(($wareId % $commitWares) == 0) { // , Neo4j $neoClient->commitBatch(); print " [commit ".$commitWares." ".(time() - $time)." sec]"; $time = time(); $neoClient->startBatch(); } } $neoClient->commitBatch(); print " done in ".(time() - $time)." seconds\n"; $time = time(); } I left the base filling script for the night. After about 4 hours, the script stopped adding data and the Neo4j service started loading the server 100%. In the morning, as a result of the work, 78300 products from 8 categories of goods were inserted.
The results of the test fill database - about 20 products per second with 200-400 links. Not a very good result - Mysql and Cassandra gave out about 10-20 thousand inserts per second (10 fields, 1 primary index, 1 index). But the insertion speed is not critical for us - we can update the data graph in the background after editing the product. But the speed of data sampling is critical.
The size of the test database on the disk is 1781 megabytes. It holds 78300 products, 4000 criteria, 15660000-31320000 links. The total number of objects (nodes and connections) is less than 32 million - an average of 55 bytes per entity. Too much, as for me, but the main requirement is still the speed of the samples, and not the size of the base.
The first attempt to test the sampling rate failed - the Neo4j server again “went away” to the 100% processor load mode and in a few minutes it did not respond to the request.
MATCH (c {criteriaId: 1})<--(a)-->(b {criteriaId: 3}) RETURN a.wareId; To move on, you need to figure out how to optimize the query in Neo4j. At first, I wanted to limit the starter set of nodes in the sample using the START instruction.
START n=node:nodeIndexName(key={value}) MATCH (c)<--(a)-->(b) RETURN a.wareId; For this, you need to have indexes in the database. In Neo4j, I did not find a command to view the list of current indexes, but in the Neo4j web application you can type a command
:schema You can add indexes with the command
CREATE INDEX ON :Criteria(criteriaId) You can create a unique index with the command
CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE; Indices added by the commands above cannot be used in the START directive. They say that they can only be used in where
The STARTED START clause. The START clause index is a non-Cypher APIs.
In order to use the user index, you can do this:
match n: user
where n.name = "aapo"
return n;
If I understand the documentation correctly, you can safely use WHERE instead of START.
START is optional. If you’re trying to do so, you can’t give it a try. This is done. See Chapter 14, Schema for more information. In general, the START clause is only really needed when using legacy indexes.
Thus was born the first working request
MATCH (a:Ware)-->(c1:Criteria {criteriaId: 3}),(c2:Criteria {criteriaId: 1}),(c3:Criteria {criteriaId: 2}) WHERE (a)-->(c2) AND (a)-->(c3) RETURN a; No indices were found in our test database, so we will create another database for the test in another way. I did not find the ability to create independent data sets (an analogue of the database in MySQL) in Neo4j. Therefore, for testing, I simply changed the path to the data storage in the Neo4j Community settings (Database location)
Attentive readers may have found a couple of comments in the test_fill_1.php code, namely
$c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - commitBatch $neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() In batch mode in Neo4jphp, I could not add tags to the nodes, and for some reason the indices were not preserved. Considering that Cypher ceased to be a Chinese diploma for me, I decided to fill the base hardcore - on pure Cypher. So test_fill_2.php
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $wareTemplatesCount = 100; // $criteriasCount = 50; // $waresCount = 250; // $minRelations = 20; // $maxRelations = 40; // if($maxRelations > $criteriasCount) { throw new \Exception("maxRelations[".$maxRelations."] should be bigger, that criteriasCount[".$criteriasCount."]"); } $query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;", array()); $result = $query->getResultSet(); $query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Ware) ASSERT n.wareId IS UNIQUE;", array()); $result = $query->getResultSet(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $time = time(); $queryTemplate = "CREATE "; print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ..."; $criterias = array(); for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { // (w1:Ware{wareId:1}) $cId = $criteriaId + $criteriasCount*$wareTemplateId; $queryTemplate .= "(c".$cId.":Criteria{criteriaId:".$cId."}), "; $criterias[] = $cId; } for($wareId = 1;$wareId <=$waresCount;$wareId++) { $wId = $wareId + $waresCount*$wareTemplateId; // (w1:Ware{wareId:1}) $queryTemplate .= "(w".$wId.":Ware{wareId:".$wId."}), "; // (w1)-[:SUIT]->(c1) $possibleLinks = array_merge(array(), $criterias); // clone $criterias for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) { $linkId = $possibleLinks[array_rand($possibleLinks)]; unset($possibleLinks[$linkId]); $queryTemplate .= "w".$wId."-[:SUIT]->c".$linkId.", "; } } $queryTemplate = substr($queryTemplate,0,-2); // ", " $build = time(); $query = new Cypher\Query($neoClient, $queryTemplate, array()); // $queryTemplate 42 10000 , 500 , 200-400 - $result = $query->getResultSet(); print " Query build in ".($build - $time)." seconds, executed in ".(time() - $build)." seconds\n"; // die(); } The speed of adding data was predictably higher than in the first version.
A test script with the addition of 30,000 nodes and 500,000 - 1,000,000 connections on cypher worked in 140 seconds, the base took 62 megabytes on disk. When I tried to run the script with c $ waresCount = 1000 (not to mention 10000 products), I received the error “Stack overflow error”. I rewrote the script using.
MATCH (a {wareId: 1}), (b {criteriaId: 2}) MERGE (a)-[r:SUIT]->(b) This led to a catastrophic drop in the speed of work, the modified script worked for about an hour. I decided to test the sampling rate according to several criteria and return to the question of quick data insertion later.
<?php use Everyman\Neo4j\Client, Everyman\Neo4j\Index\NodeIndex, Everyman\Neo4j\Relationship, Everyman\Neo4j\Node, Everyman\Neo4j\Cypher; require_once 'example_bootstrap.php'; $neoClient = new Client(); $time = microtime(); $query = new Cypher\Query($neoClient, "MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}),(c:Criteria {criteriaId: 1}),(c2:Criteria {criteriaId: 2}) WHERE (a)-->(c) AND (a)-->(c2) RETURN a;", array()); $result = $query->getResultSet(); print "Done in ".(microtime() - $time)." seconds\n"; The script above worked in 0.02 seconds. In general, this is quite acceptable, but the problem of how to quickly maintain a large number of connections between nodes while updating product properties remains.
Alternative solution
I decided “to clear my conscience” to try out MySQL as a repository. Connections between nodes will be stored in a separate table without additional information.
CREATE TABLE IF NOT EXISTS `edges` ( `criteriaId` int(11) NOT NULL, `wareId` int(11) NOT NULL, UNIQUE KEY `criteriaId` (`criteriaId`,`wareId`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; Test script to fill the base below
<?php mysql_connect("localhost", "root", ""); mysql_select_db("test_nodes"); $wareTemplatesCount = 100; $criteriasCount = 50; $waresCount = 250; $minRelations = 20; $maxRelations = 40; $time = time(); for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) { $criterias = array(); for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) { $criterias[] = $wareTemplateId * $criteriasCount + $criteriaId; } for($wareId = 1;$wareId <=$waresCount;$wareId++) { $edges = array(); $wId = $wareTemplateId * $waresCount + $wareId; $links = array_rand($criterias,rand($minRelations,$maxRelations)); foreach($links as $linkId) { $edges[] = "(".$criterias[$linkId].",".$wareId.")"; } // mysql_query("INSERT INTO edges VALUES ".implode(",",$edges)); } print "."; } print " [added ".$wareTemplatesCount." templates in ".(time() - $time)." sec]"; $time = time(); Filling the base took 12 seconds. The size of the table is 37 megabytes. Search by 2 criteria takes 0.0007 seconds
SELECT e1.wareId FROM `edges` AS e1 JOIN edges AS e2 ON e1.wareId = e2.wareId WHERE e1.criteriaId =17 AND e2.criteriaId =31 Another option
Under mysql there is a full-fledged graph data storage - but I did not test it. Judging by the documentation, it is much more primitive than Neo4j.
findings
Neo4j is a very cool thing . A query like “Selecting contacts of users who liked movie actors who starred in films that sounded soundtracks, which were written by musicians I put like” in Neo4j is trivial. Like that
MATCH (me:User {userId:123})-[:Like]->(musicants:User)-[:Author]->(s:Soundtrack)-[:Used]->(f:Film)<-[:Starred]-(actor: User)<-[:Like]-(u:User) RETURN u For SQL, this is much more troublesome.
It is incorrect to compare a full graph database with a bare index table in MySQL, but in the context of solving my problem, the use of Neo4j did not give any advantages .
UPDATE . Changed url'y pictures, in theory should all be loaded.
UPDATE 2 . They offered several options - MongoDB, elasticsearch, solr, sphinx, OrientDB. I plan to test MongoDB, I'll post the test results right there.
Source: https://habr.com/ru/post/219441/
All Articles