Platform for video service for a quarter
Today we will tell how we managed to build our platform for video service on Odnoklassniki in Java for 3 months.
To begin with, what is a video service on Odnoklassniki. It is available both on the web and in versions for mobile devices. One of the differences between Odnoklassniki and other social networks is the presence of video displays, where videos are collected in the TOP of the Week, Novinki and Channels sections. For these sections, the video is automatically selected by a sly algorithm based on the number of views, classes and the rate of growth of the video's popularity. And of course, the showcase shows channels with content from partners: - TV shows, TV shows, cartoons and movies.
Basically, this is a standard video service. The user uploads the video, then it passes moderation, after which other users can watch it.
')
Over 10 million unique users a day use video service on Odnoklassniki, who watch over 70 million videos and download 50,000 videos per day.
Videobase Odnoklassniki has over 28 million videos. Outgoing traffic in the evenings reaches 80 gigabits per second. Daily downloaded 5 terabytes of new video per day are converted to our internal format and the output is 2 terabytes. The resulting files are stored in three copies, which, in total, totals 6 terabytes of new video per day. Inbound traffic load reaches 2 gigabits at peak hours.

What does all this work? Now the video service park has about 200 servers, and soon there will be much more. The storage occupies 70 servers, the total volume is 5 Petabytes. 30 servers are engaged in the storage of metadata, this is the database and caches in front of them. Another 60 servers are engaged in the transformation of custom video into our formats. Another 30 servers - for download and distribution.

We started developing video service on Odnoklassniki back in 2010. At first, we didn’t have our own platform and we only allowed users to share links to content that was located on other resources: Rutube, YouTube, Mail.Ru Video. In 2011, we launched the video download through the Odnoklassniki portal, but it all worked on the basis of the Mail.Ru Video platform. The service began to grow, new requirements began to be made, and in January 2013 we realized that without creating our video platform, our service could not develop further.
New platform - new requirements. The first inherent requirement that applies to all Odnoklassniki servers is reliability, fault tolerance and full functionality retention in case of loss of the server or data center. Next comes the resuming download. It is necessary, otherwise we will lose user content. In third place is video playback from any moment without pre-buffering the entire video. We wanted to see all this on mobile devices. We also love and know how to exploit Java services, so it was also added to the list of requirements.

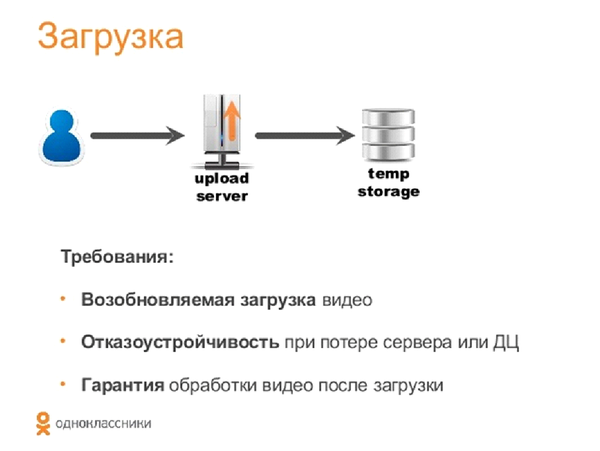
Let's see what the whole video pipeline looks like from the inside. The user uploads the video to the upload server (we will denote it in the pictures with the up arrow). Then the video goes to the server storage, and then to the transformation server. On it, we convert the video into our internal format, save it to a temporary storage, after which the download server (down arrow) distributes this content to users.

Let us consider in more detail the implementation of each stage.
Once again I will remind the requirements. We wanted to implement a renewable load and provide fault tolerance in case of server loss. That is, if a user uploads content to a specific server, and that one fails or network access disappears, then all download should continue on another server. We set as our goal to ensure that we will process all the uploaded video in any case. Of course, there is nginx for reloading, but we decided that its use is not quite convenient for our own storage, and therefore we implemented our solution in Java.
What does our video load balancing system look like? We have 6 servers, 2 in each data center. For load balancing inside data centers, we use LVS (Linux Virtual Server). This allows you to store multiple servers behind a single IP address and transfer requests to them, depending on their workload.


To ensure fault tolerance in data centers, we use DNS-GSLB. The user clicks the "Add Video" button, gets a link to download, then the domain name is authorized into the IP address of one of the data centers. DNS-GSLB is Global Server Load Balancing, its main function is to provide fault tolerance at the level of data centers. In case of a data center failure, our DNS will not resolve (resolve, resolve) the domain name to this data center.
Once again: if the server fails, the user is transferred to another one, and in the event of the entire data center failure, a new query via DNS resumes downloading via another data center. What is convenient? By the fact that we, first of all, do not write code, but use ready-made solutions, and secondly, this allows us to balance the load for any stateless services.

Now how we have implemented stateless-service. The user starts downloading to a specific server, and that, in turn, in units of the order of a megabyte, sends data to the distributed storage (we will talk about it later), necessarily via several data centers. Upload server is implemented in Java, Apache Tomcat is used.

What happens when we lose a server, a data center, or, for example, a user simply reestablished a connection some time after the connection was broken? Our new upload server, which does not have any session with this user, according to the state of the distributed storage, detects the last successfully loaded bytes, and resumes downloading from the disconnect point. Fault tolerance is almost 100%. Even if the data center is lost during the download process, the process resumes from the point where the gap occurred.

After the video is in temporary storage, it is converted to our internal unified format. The basic format requirements are the ability to play it in different browsers and on different platforms. Also, he should be able to store video in both high and low quality, be fault tolerant and scalable.

When choosing a format, we analyzed the following data: the current prevalence of browsers and operating systems, including Android and iOS, the ability to play video in them through HTML5 and Flash. Since the current Odnoklassniki player is implemented in Flash, we decided to support both HTML5 video and Flash.

Having considered the formats supported by Flash and HTML5, we chose the MP4, as the media container - the H264 codec, the audio codec - AAC.

So, after the video is successfully uploaded, it should go on conversion to our internal format. This is done on the transformation servers, where we use the native FFMpeg library. We now have about 60 transformation servers. What happens to the video? The upload server uploads the video to the temporary storage and at the end of the upload adds the transformation task to the queue.

Tasks are distributed to the servers, but the fact is that FFMpeg is a rather unstable thing, it sometimes freezes, eats up all the system resources, and there are cases when the video is not converted the first time. Therefore, we have added a permanent tracking of the status of tasks performed. That is, the process looks like this: the upload server uploaded the video to the queue, the transformation server took over the task and, at some intervals, checks the status of its execution. In the event of a server failure, the task is restarted, or it is returned to the queue and transferred to another server.
Everything is fine, but after all, the previous server could simply have lost the connection. And we do not need the server to do extra work when restoring a connection, which another server is already doing. To do this, each time checking the queue, we return the possibility of continuing work. That is, the algorithm is as follows: the server woke up, turned to the queue and said that it would continue to perform the task. The queue responds that the task is no longer relevant, and the server takes on a new task.
This scheme works great, but we have a Single Point of Failure, it is our turn. If we lose the data center, where we store the queue, or the server itself, then we will have serious problems. Here we would need to implement some kind of distributed queue solution, but we did not exploit such things and did not want to complicate the infrastructure. We simply used Zookeeper, which Odnoklassniki is very actively using in his other services.
What is a zookeeper? This is a server of distributed locks, it has ready-made solutions in the form of a choice of a leader. The choice of a leader is such a process in a distributed system, when in case of loss of a server, the whole system will come to a stable state due to the appointment of a “leader”. He knows that he is the "leader", and all the servers know this too.

In fact, in this system, “candidate1” and “candidate2” do nothing, they are just backup servers located in other data centers. The queue is fully executed on the "leader". In the event of the loss of the “leader”, a new one is selected, and the whole system learns that the first candidate has become the new “leader”.

Upload servers start adding tasks to it, transformation servers ping, everything is fine. However, the state of the queue at the time of the fall of the old leader is unknown on the new leader. Since we have all the videos and time stamps uploaded by users in the temporary storage, we can restore the queue using them. After receiving some responses from the queue after a while, all the transformation servers will inform us in a short while about the tasks that they are performing, and we will get the same state that the leader had.
This delay period is dozens of seconds and does not noticeably affect the users.
For video transformation, we use FFMpeg, and for extracting any interesting information we use MP4 parser . The entire transformation server is written in Java and works quite simply - takes the task from the queue, runs FFMpeg through the Java wrapper, cuts the video into four qualities, extracts the images for the splash screen and metadata, and finally saves all the received information to the permanent storage.
In the process of creating different versions of the quality, we are faced with such a problem. It turned out that 15% of the loaded video in the title have the wrong length. That is, for example, the title of the video shows the duration of 2 hours, and in fact there is a video stream there for a couple of minutes. Faced with this, we had to calculate the length of frames, this parameter we use both in calculating the output parameters of the video, and for cutting thumbnails.

After cutting the video, it is sent to the repository. Now it consists of about 70 servers, each of which has 36 double-byte drives. Total 5 petabytes. The storage is distributed, fault tolerant, it is called One Blob Storage (OBS). To store the state of the clusters, we use Zookeeper. Videos are stored on disks in blocks of 64 megabytes. Hard disk failure is not a problem for this storage. There are additional drives on the servers. In case of failure of one of them, on the other, his condition is automatically restored. Each video we store in triplicate. Thus, from each video there are four new ones, each of which is stored in triplicate, one in each DC.

Probably the most interesting part. Requirements:

In principle, for the implementation of pseudo-streaming, that is, the return of the video from any moment, nginx has suitable modules. But nginx works with files, and we wanted to cache only what the user actually looks at. For example, we have a two-hour movie, and the user watched about 5 minutes. Then we cache only this piece. I had to write my solution again in Java.
Let's see, for a start, what pseudo-streaming is. When playing a video, there is some buffered part in it. If the user goes to the unbuffered part, then we must start playback from this point without buffering. How does it work? During the transformation of the video into our internal format, we alternate between video and audio samples, and also insert a so-called sync sample every few seconds. The resulting result is as follows: we have a header and there are blocks. Accordingly, when the user selects a place, then we understand from which block one can begin to give data. The title indicates the beginning of each block.

On the one hand, it is advantageous to use a lot of such blocks. But then the volume of the title grows, and this is the volume that the user is forced to download before the first frame of the video appears. Trying to optimize the title, we came up with this solution: the maximum size of the video file header should not exceed 6 megabytes. At the same time in one video 500-700 blocks are obtained.
In the process of cutting, besides the choice of the synchronization frequency of video and audio, there was another problem. Standard video converters usually put a caption at the end of the file. This is much more convenient for them, because all the displacements of all blocks are already known. And in the case of streaming video, the main thing is not to forget to move the title to the beginning.
Consider the implementation of pseudo-streaming in HTML5. The player has a moov atom, when selecting a place, it calculates the upset, it requests the byte-range-request-data itself and provides the native search. The Flash player has a slightly worse situation, he simply makes a request to the server at the start (the URL has the start time in seconds), and then the server has to prepare a full-fledged video file for him from this place, that is, recalculate the title, as if the video was started since the request of the user.


When pseudo-streaming files can only be viewed from the beginning, from the middle and from the end, only the viewed part of the video is cached on the distribution server. We decided that we would be caching video blocks of 256 kilobytes. And all this will do in Java.

Consider the architecture of our distributor. This is such a caching layer between our permanent storage, it has several levels of caches. Historically, about 96 GB of RAM are allocated to us on servers. Here we put another SSD-drives.

The algorithm works as follows: the user has requested the video from the server; if it is cached in memory, then we give it, if not, then check the disk; if it is not, then go to our store. We immediately put the video from the storage into RAM and distribute it to users. In RAM, we use only the LRU cache and, when preempting, we check the counter, how many views we have of this segment. If a segment is watched more than a certain number of times, then we force it onto a disk; if the segment was viewed a little, then we throw it away.
96 gigabyte cache requirements:
Requirements for the second level of caching on disks are lower. It is enough to use FIFO caching, the internal OBS solution is also applied, only locally.

Large volumes of 100 gigabytes and a ban on the impact on the GC lead us to offheap-caching. Offheap caching options, in principle, a lot. There are Direct-ByteBuffer, memory-mapped files, but they have problems. For example, the native code is not portable, and in these solutions the limitation of the maximum amount of allocated files is about 2 gigabytes. Of course, you can assemble them from blocks, but this will not be very convenient. Solution: use shared-memory, use Unsafe to access it. All this is implemented on our open source one-nio library, it can be viewed on github .

For distribution we use selectors. Our distribution HTTP server is part of the one-nio library. The server is equipped with two gigabit fiber-optic cards. He has 10 gigabit Ethernet cards to access the storage.

According to the results of testing, we successfully cope with the distribution of 20 Gigabits. That is, as much as we can provide external network cards. At the same time, the processor load is about 30%. Now our engineers are working to reconfigure the system and start distributing more. The main limitation is 6 slots on one server and the effectiveness of our cache. We got it somewhere 80/20: 80% of block requests are taken from the cache, 20% of requests come from OBS. Probably, this is not bad, but for 20 Gigabit, we almost completely select the 4 Gigabit Ethernet access resource to our permanent storage.
Everything is great, but 20 gigabits is not enough for our users. We use clusters from all servers for video distribution, as well as the standard balancing algorithm, which was previously considered when downloading videos. But we have a problem: if users watch the same video, and we will distribute it from different nodes, then the effectiveness of our super cache will be greatly reduced.

We needed to make sure that on 10 servers the total cache size was about a terabyte. To do this, they wrote their balancer. Its main idea is that we split all videos into a certain number of partitions (the main thing is that there are a lot of them), and we assign some partitions to each server. Actually, each server distributes only its own video content. To ensure fault tolerance (even load distribution across other servers in the cluster), we add replicas to each partition.

If the Server is dropped, respectively, the distribution takes place with this partition from one server, and the other partition from the other. The load is evenly distributed across all servers, and everything would be great, but the content of these servers is not cached. Thus, we will form a large number of requests to our permanent storage. It can not stand this, especially during peak hours. To do this, we “warm up” the partitions for the future, that is, sometimes we send the user with some probability to the replicas — to the replica1 or the replica2. Thus, we kill two birds with one stone: we warm up this cache and balance the load on the storage, but on the other hand, we effectively use the cache within the cluster.
Also, do not forget that the byte range is easy to implement on this HTTP server, but rebuilding a moov atom from a place is not an easy task. The rebuild itself takes place on the distributing servers. For this, we tried to use the MP4 parser, but it generated a lot of garbage, had a great impact on the GC and was extremely inefficient. We have the number of requests for rewind - a hundred per second. We abandoned the MP4 parser and implemented our Java solution to rebuild the moov atom from time to time. It turned out to be extremely effective, the title is rebuilt from 6 megabytes to 3 in time to ten milliseconds.
There is such an interesting fact: in August 2012, when the rover landed on Mars, NASA decided to organize an online video broadcast. For this, they invited nginx. Nginx had a platform that distributes, caches, deployed on 40 Amazon-EC2 servers. These are, of course, not super-efficient servers, but 40 of them are serious enough. A testing company was invited, which tested the load on this video service, and they tested a load of about 25 gigabits per second. I think that one of our server after some modifications will withstand 25 gigabits per second. They carried out shutdown of servers. First, we deduced 10 servers, the traffic sank a little, rebalanced and returned to normal. They disconnected 10 more servers, the traffic sat down and did not return to 25 gigabits, but remained at the level of 12 gigabits per second. It turned out that the distribution to nginx, this, of course, was the distribution of streaming video, but they had only one video script. 20 servers provided a performance of about 12 gigabits.

Below are the main milestones of our project. It is worth noting that we started development in January 2013, and in May 2013, the entire Java platform was launched on 100% of the portals.

We tried to make the most of the technologies that we worked out. I understand that, perhaps, startups usually try to minimize coding and integrate existing solutions as much as possible. We decided to save on integration and launch.
On the other hand, we used very little technology, this is our internal One-nio library, which is available in open source. Of all this, only our storage is proprietary, OBS, but this is due to some problems, the need to untie it from our internal configuration architecture. The only alternative solution was FFMpeg, which was used for cutting video.

Actually, this is how all these technologies are distributed across our servers. Everything except FFMpeg is Java.

We ensured that the service is fully operational in case of loss of data centers and servers. We gave users the opportunity to resume downloading videos within 12 hours after disconnecting. That is, if you downloaded the video, and you lost the network (this is especially true for mobile devices), if you continue downloading within 12 hours, we will fully load the file.
We also provided video viewing from any point in time in Flash and HTML5. The latter is very important for mobile devices. We achieved interesting results in terms of traffic from one server.

The main plans for the near future are to try add-ons on the HTML5 player. You can also improve the work of FFMpeg with codecs. We get all sorts of interesting metadata from a user-uploaded video, such as GPS, but we still don’t use GPS coordinates.

We allow Odnoklassniki users to upload videos up to 8 gigabytes to us, which is four times the maximum size of a video on VKontakte that can be downloaded. And the length of the downloaded video is not limited by anything (YouTube, for example, has a 15-minute limit for some accounts). The maximum video resolution, however, is lower than we would like - only 720p, which, incidentally, corresponds to the HD standard. Nevertheless, we will soon acquire new capacities, which will increase the quality to the desired 1080p.
In addition, unlike other video resources, the Odnoklassniki service supports an expanded range of video formats - there are more than 20 of them, including .evo and .asf. This is the highest figure among competitors, although they support all major formats, including MP4.
Downloading content is available not only in the form of files: you can add a video by link from other video resources.
A powerful backend in the face of the video platform we developed allowed us to implement a full-fledged online cinema on Odnoklassniki. Licensed content that we receive from our partners is available to users of the social network for free. , , «», , — «», «» . , — .
To begin with, what is a video service on Odnoklassniki. It is available both on the web and in versions for mobile devices. One of the differences between Odnoklassniki and other social networks is the presence of video displays, where videos are collected in the TOP of the Week, Novinki and Channels sections. For these sections, the video is automatically selected by a sly algorithm based on the number of views, classes and the rate of growth of the video's popularity. And of course, the showcase shows channels with content from partners: - TV shows, TV shows, cartoons and movies.
Basically, this is a standard video service. The user uploads the video, then it passes moderation, after which other users can watch it.
')
Over 10 million unique users a day use video service on Odnoklassniki, who watch over 70 million videos and download 50,000 videos per day.
Videobase Odnoklassniki has over 28 million videos. Outgoing traffic in the evenings reaches 80 gigabits per second. Daily downloaded 5 terabytes of new video per day are converted to our internal format and the output is 2 terabytes. The resulting files are stored in three copies, which, in total, totals 6 terabytes of new video per day. Inbound traffic load reaches 2 gigabits at peak hours.
What does all this work? Now the video service park has about 200 servers, and soon there will be much more. The storage occupies 70 servers, the total volume is 5 Petabytes. 30 servers are engaged in the storage of metadata, this is the database and caches in front of them. Another 60 servers are engaged in the transformation of custom video into our formats. Another 30 servers - for download and distribution.
We started developing video service on Odnoklassniki back in 2010. At first, we didn’t have our own platform and we only allowed users to share links to content that was located on other resources: Rutube, YouTube, Mail.Ru Video. In 2011, we launched the video download through the Odnoklassniki portal, but it all worked on the basis of the Mail.Ru Video platform. The service began to grow, new requirements began to be made, and in January 2013 we realized that without creating our video platform, our service could not develop further.
New platform - new requirements. The first inherent requirement that applies to all Odnoklassniki servers is reliability, fault tolerance and full functionality retention in case of loss of the server or data center. Next comes the resuming download. It is necessary, otherwise we will lose user content. In third place is video playback from any moment without pre-buffering the entire video. We wanted to see all this on mobile devices. We also love and know how to exploit Java services, so it was also added to the list of requirements.
Let's see what the whole video pipeline looks like from the inside. The user uploads the video to the upload server (we will denote it in the pictures with the up arrow). Then the video goes to the server storage, and then to the transformation server. On it, we convert the video into our internal format, save it to a temporary storage, after which the download server (down arrow) distributes this content to users.
Let us consider in more detail the implementation of each stage.
Loading
Once again I will remind the requirements. We wanted to implement a renewable load and provide fault tolerance in case of server loss. That is, if a user uploads content to a specific server, and that one fails or network access disappears, then all download should continue on another server. We set as our goal to ensure that we will process all the uploaded video in any case. Of course, there is nginx for reloading, but we decided that its use is not quite convenient for our own storage, and therefore we implemented our solution in Java.
What does our video load balancing system look like? We have 6 servers, 2 in each data center. For load balancing inside data centers, we use LVS (Linux Virtual Server). This allows you to store multiple servers behind a single IP address and transfer requests to them, depending on their workload.
To ensure fault tolerance in data centers, we use DNS-GSLB. The user clicks the "Add Video" button, gets a link to download, then the domain name is authorized into the IP address of one of the data centers. DNS-GSLB is Global Server Load Balancing, its main function is to provide fault tolerance at the level of data centers. In case of a data center failure, our DNS will not resolve (resolve, resolve) the domain name to this data center.
Once again: if the server fails, the user is transferred to another one, and in the event of the entire data center failure, a new query via DNS resumes downloading via another data center. What is convenient? By the fact that we, first of all, do not write code, but use ready-made solutions, and secondly, this allows us to balance the load for any stateless services.
Now how we have implemented stateless-service. The user starts downloading to a specific server, and that, in turn, in units of the order of a megabyte, sends data to the distributed storage (we will talk about it later), necessarily via several data centers. Upload server is implemented in Java, Apache Tomcat is used.
What happens when we lose a server, a data center, or, for example, a user simply reestablished a connection some time after the connection was broken? Our new upload server, which does not have any session with this user, according to the state of the distributed storage, detects the last successfully loaded bytes, and resumes downloading from the disconnect point. Fault tolerance is almost 100%. Even if the data center is lost during the download process, the process resumes from the point where the gap occurred.
Transformation (recoding)
After the video is in temporary storage, it is converted to our internal unified format. The basic format requirements are the ability to play it in different browsers and on different platforms. Also, he should be able to store video in both high and low quality, be fault tolerant and scalable.
When choosing a format, we analyzed the following data: the current prevalence of browsers and operating systems, including Android and iOS, the ability to play video in them through HTML5 and Flash. Since the current Odnoklassniki player is implemented in Flash, we decided to support both HTML5 video and Flash.
Having considered the formats supported by Flash and HTML5, we chose the MP4, as the media container - the H264 codec, the audio codec - AAC.
So, after the video is successfully uploaded, it should go on conversion to our internal format. This is done on the transformation servers, where we use the native FFMpeg library. We now have about 60 transformation servers. What happens to the video? The upload server uploads the video to the temporary storage and at the end of the upload adds the transformation task to the queue.
Tasks are distributed to the servers, but the fact is that FFMpeg is a rather unstable thing, it sometimes freezes, eats up all the system resources, and there are cases when the video is not converted the first time. Therefore, we have added a permanent tracking of the status of tasks performed. That is, the process looks like this: the upload server uploaded the video to the queue, the transformation server took over the task and, at some intervals, checks the status of its execution. In the event of a server failure, the task is restarted, or it is returned to the queue and transferred to another server.
Everything is fine, but after all, the previous server could simply have lost the connection. And we do not need the server to do extra work when restoring a connection, which another server is already doing. To do this, each time checking the queue, we return the possibility of continuing work. That is, the algorithm is as follows: the server woke up, turned to the queue and said that it would continue to perform the task. The queue responds that the task is no longer relevant, and the server takes on a new task.
This scheme works great, but we have a Single Point of Failure, it is our turn. If we lose the data center, where we store the queue, or the server itself, then we will have serious problems. Here we would need to implement some kind of distributed queue solution, but we did not exploit such things and did not want to complicate the infrastructure. We simply used Zookeeper, which Odnoklassniki is very actively using in his other services.
What is a zookeeper? This is a server of distributed locks, it has ready-made solutions in the form of a choice of a leader. The choice of a leader is such a process in a distributed system, when in case of loss of a server, the whole system will come to a stable state due to the appointment of a “leader”. He knows that he is the "leader", and all the servers know this too.
In fact, in this system, “candidate1” and “candidate2” do nothing, they are just backup servers located in other data centers. The queue is fully executed on the "leader". In the event of the loss of the “leader”, a new one is selected, and the whole system learns that the first candidate has become the new “leader”.
Upload servers start adding tasks to it, transformation servers ping, everything is fine. However, the state of the queue at the time of the fall of the old leader is unknown on the new leader. Since we have all the videos and time stamps uploaded by users in the temporary storage, we can restore the queue using them. After receiving some responses from the queue after a while, all the transformation servers will inform us in a short while about the tasks that they are performing, and we will get the same state that the leader had.
This delay period is dozens of seconds and does not noticeably affect the users.
For video transformation, we use FFMpeg, and for extracting any interesting information we use MP4 parser . The entire transformation server is written in Java and works quite simply - takes the task from the queue, runs FFMpeg through the Java wrapper, cuts the video into four qualities, extracts the images for the splash screen and metadata, and finally saves all the received information to the permanent storage.
In the process of creating different versions of the quality, we are faced with such a problem. It turned out that 15% of the loaded video in the title have the wrong length. That is, for example, the title of the video shows the duration of 2 hours, and in fact there is a video stream there for a couple of minutes. Faced with this, we had to calculate the length of frames, this parameter we use both in calculating the output parameters of the video, and for cutting thumbnails.
Storage
After cutting the video, it is sent to the repository. Now it consists of about 70 servers, each of which has 36 double-byte drives. Total 5 petabytes. The storage is distributed, fault tolerant, it is called One Blob Storage (OBS). To store the state of the clusters, we use Zookeeper. Videos are stored on disks in blocks of 64 megabytes. Hard disk failure is not a problem for this storage. There are additional drives on the servers. In case of failure of one of them, on the other, his condition is automatically restored. Each video we store in triplicate. Thus, from each video there are four new ones, each of which is stored in triplicate, one in each DC.
Distribution of content
Probably the most interesting part. Requirements:
- Return of video from any moment without preliminary buffering.
- High performance, we expected about 150 gigabits per second.
- Fault tolerance.
In principle, for the implementation of pseudo-streaming, that is, the return of the video from any moment, nginx has suitable modules. But nginx works with files, and we wanted to cache only what the user actually looks at. For example, we have a two-hour movie, and the user watched about 5 minutes. Then we cache only this piece. I had to write my solution again in Java.
Let's see, for a start, what pseudo-streaming is. When playing a video, there is some buffered part in it. If the user goes to the unbuffered part, then we must start playback from this point without buffering. How does it work? During the transformation of the video into our internal format, we alternate between video and audio samples, and also insert a so-called sync sample every few seconds. The resulting result is as follows: we have a header and there are blocks. Accordingly, when the user selects a place, then we understand from which block one can begin to give data. The title indicates the beginning of each block.
On the one hand, it is advantageous to use a lot of such blocks. But then the volume of the title grows, and this is the volume that the user is forced to download before the first frame of the video appears. Trying to optimize the title, we came up with this solution: the maximum size of the video file header should not exceed 6 megabytes. At the same time in one video 500-700 blocks are obtained.
In the process of cutting, besides the choice of the synchronization frequency of video and audio, there was another problem. Standard video converters usually put a caption at the end of the file. This is much more convenient for them, because all the displacements of all blocks are already known. And in the case of streaming video, the main thing is not to forget to move the title to the beginning.
Pseudo-streaming
Consider the implementation of pseudo-streaming in HTML5. The player has a moov atom, when selecting a place, it calculates the upset, it requests the byte-range-request-data itself and provides the native search. The Flash player has a slightly worse situation, he simply makes a request to the server at the start (the URL has the start time in seconds), and then the server has to prepare a full-fledged video file for him from this place, that is, recalculate the title, as if the video was started since the request of the user.
When pseudo-streaming files can only be viewed from the beginning, from the middle and from the end, only the viewed part of the video is cached on the distribution server. We decided that we would be caching video blocks of 256 kilobytes. And all this will do in Java.
Consider the architecture of our distributor. This is such a caching layer between our permanent storage, it has several levels of caches. Historically, about 96 GB of RAM are allocated to us on servers. Here we put another SSD-drives.
The algorithm works as follows: the user has requested the video from the server; if it is cached in memory, then we give it, if not, then check the disk; if it is not, then go to our store. We immediately put the video from the storage into RAM and distribute it to users. In RAM, we use only the LRU cache and, when preempting, we check the counter, how many views we have of this segment. If a segment is watched more than a certain number of times, then we force it onto a disk; if the segment was viewed a little, then we throw it away.
96 gigabyte cache requirements:
- The cache should not affect the GC, it should be LRU. Now we have about 20 thousand requests per second processed on the server, that is, it should be high-performance.
- The cache must be persistent, that is, persist after a restart or update of the distribution service.
Requirements for the second level of caching on disks are lower. It is enough to use FIFO caching, the internal OBS solution is also applied, only locally.
Large volumes of 100 gigabytes and a ban on the impact on the GC lead us to offheap-caching. Offheap caching options, in principle, a lot. There are Direct-ByteBuffer, memory-mapped files, but they have problems. For example, the native code is not portable, and in these solutions the limitation of the maximum amount of allocated files is about 2 gigabytes. Of course, you can assemble them from blocks, but this will not be very convenient. Solution: use shared-memory, use Unsafe to access it. All this is implemented on our open source one-nio library, it can be viewed on github .
For distribution we use selectors. Our distribution HTTP server is part of the one-nio library. The server is equipped with two gigabit fiber-optic cards. He has 10 gigabit Ethernet cards to access the storage.
According to the results of testing, we successfully cope with the distribution of 20 Gigabits. That is, as much as we can provide external network cards. At the same time, the processor load is about 30%. Now our engineers are working to reconfigure the system and start distributing more. The main limitation is 6 slots on one server and the effectiveness of our cache. We got it somewhere 80/20: 80% of block requests are taken from the cache, 20% of requests come from OBS. Probably, this is not bad, but for 20 Gigabit, we almost completely select the 4 Gigabit Ethernet access resource to our permanent storage.
Balancing
Everything is great, but 20 gigabits is not enough for our users. We use clusters from all servers for video distribution, as well as the standard balancing algorithm, which was previously considered when downloading videos. But we have a problem: if users watch the same video, and we will distribute it from different nodes, then the effectiveness of our super cache will be greatly reduced.
We needed to make sure that on 10 servers the total cache size was about a terabyte. To do this, they wrote their balancer. Its main idea is that we split all videos into a certain number of partitions (the main thing is that there are a lot of them), and we assign some partitions to each server. Actually, each server distributes only its own video content. To ensure fault tolerance (even load distribution across other servers in the cluster), we add replicas to each partition.
If the Server is dropped, respectively, the distribution takes place with this partition from one server, and the other partition from the other. The load is evenly distributed across all servers, and everything would be great, but the content of these servers is not cached. Thus, we will form a large number of requests to our permanent storage. It can not stand this, especially during peak hours. To do this, we “warm up” the partitions for the future, that is, sometimes we send the user with some probability to the replicas — to the replica1 or the replica2. Thus, we kill two birds with one stone: we warm up this cache and balance the load on the storage, but on the other hand, we effectively use the cache within the cluster.
Also, do not forget that the byte range is easy to implement on this HTTP server, but rebuilding a moov atom from a place is not an easy task. The rebuild itself takes place on the distributing servers. For this, we tried to use the MP4 parser, but it generated a lot of garbage, had a great impact on the GC and was extremely inefficient. We have the number of requests for rewind - a hundred per second. We abandoned the MP4 parser and implemented our Java solution to rebuild the moov atom from time to time. It turned out to be extremely effective, the title is rebuilt from 6 megabytes to 3 in time to ten milliseconds.
There is such an interesting fact: in August 2012, when the rover landed on Mars, NASA decided to organize an online video broadcast. For this, they invited nginx. Nginx had a platform that distributes, caches, deployed on 40 Amazon-EC2 servers. These are, of course, not super-efficient servers, but 40 of them are serious enough. A testing company was invited, which tested the load on this video service, and they tested a load of about 25 gigabits per second. I think that one of our server after some modifications will withstand 25 gigabits per second. They carried out shutdown of servers. First, we deduced 10 servers, the traffic sank a little, rebalanced and returned to normal. They disconnected 10 more servers, the traffic sat down and did not return to 25 gigabits, but remained at the level of 12 gigabits per second. It turned out that the distribution to nginx, this, of course, was the distribution of streaming video, but they had only one video script. 20 servers provided a performance of about 12 gigabits.
Below are the main milestones of our project. It is worth noting that we started development in January 2013, and in May 2013, the entire Java platform was launched on 100% of the portals.
Technology
We tried to make the most of the technologies that we worked out. I understand that, perhaps, startups usually try to minimize coding and integrate existing solutions as much as possible. We decided to save on integration and launch.
On the other hand, we used very little technology, this is our internal One-nio library, which is available in open source. Of all this, only our storage is proprietary, OBS, but this is due to some problems, the need to untie it from our internal configuration architecture. The only alternative solution was FFMpeg, which was used for cutting video.
Actually, this is how all these technologies are distributed across our servers. Everything except FFMpeg is Java.
results
We ensured that the service is fully operational in case of loss of data centers and servers. We gave users the opportunity to resume downloading videos within 12 hours after disconnecting. That is, if you downloaded the video, and you lost the network (this is especially true for mobile devices), if you continue downloading within 12 hours, we will fully load the file.
We also provided video viewing from any point in time in Flash and HTML5. The latter is very important for mobile devices. We achieved interesting results in terms of traffic from one server.
The main plans for the near future are to try add-ons on the HTML5 player. You can also improve the work of FFMpeg with codecs. We get all sorts of interesting metadata from a user-uploaded video, such as GPS, but we still don’t use GPS coordinates.
And a few more words about the video platform
We allow Odnoklassniki users to upload videos up to 8 gigabytes to us, which is four times the maximum size of a video on VKontakte that can be downloaded. And the length of the downloaded video is not limited by anything (YouTube, for example, has a 15-minute limit for some accounts). The maximum video resolution, however, is lower than we would like - only 720p, which, incidentally, corresponds to the HD standard. Nevertheless, we will soon acquire new capacities, which will increase the quality to the desired 1080p.
In addition, unlike other video resources, the Odnoklassniki service supports an expanded range of video formats - there are more than 20 of them, including .evo and .asf. This is the highest figure among competitors, although they support all major formats, including MP4.
Downloading content is available not only in the form of files: you can add a video by link from other video resources.
A powerful backend in the face of the video platform we developed allowed us to implement a full-fledged online cinema on Odnoklassniki. Licensed content that we receive from our partners is available to users of the social network for free. , , «», , — «», «» . , — .
Source: https://habr.com/ru/post/219429/
All Articles