What is a Tomita-parser, how Yandex understands natural language with its help, and how you can use it to extract facts from texts
The dream that the machine understands the human language, captured the minds even when the computers were large, and their performance - small. The main problem on the way to this is that the grammar and semantics of natural languages are poorly amenable to formalization. In addition, the presence of multiple meanings distinguishes them from programming languages.
Of course, the dream of full-fledged communication with a computer in a natural language is still far from a full-fledged implementation, about as much as the dream of artificial intelligence. However, some results are already there: the machine can be taught to find the necessary objects in the text in natural language, to find connections between them and to present the necessary data in a formalized form for further processing. In Yandex, this technology has been used for quite some time. For example, if you receive a letter with a proposal to meet in a certain place and at a certain time, a special algorithm will independently extract the necessary data and offer to add it to the calendar.
')
Soon we plan to give this technology to open source, so that anyone can use it and develop it, bringing with it the bright future of free communication between humans and computers. Preparations for the opening of source codes have already begun, but this process is not as fast as we would like, and most likely will last until the end of this year. During this time, we will try to tell as much as possible about our product, for which we launch a series of posts, within the framework of which we will tell about the device design and the principles of working with it.
Tomita-parser technology is called, and by and large, anyone can use it right now: binary files are available for download. However, before using the technology, you need to learn how to cook it properly.
The tool is named in honor of the Japanese scientist Masaru Tomita, the author of the GLR parsing algorithm (Generalized left-to-right algorithm), on the basis of which Tomita-parser was created. Back in 1984, he described the implementation of this algorithm, setting himself the task of efficiently and accurately performing analysis of texts in natural language. In some ways, the GLR algorithm is an extended version of the LR parsing algorithm. But the LR algorithm is intended for analyzing texts written in fairly strictly deterministic programming languages and cannot work with natural language. Tomita solved this problem by parallelizing the stacks, which made it possible to consider different interpretations of various sections of the text: as soon as the possibility of different interpretations arises, the stack forks. There can be several such sequential branches, but in the process of analysis, erroneous branches are discarded, and the result is the longest string. In this case, the algorithm gives the results of its work in real time, as it moves deeper into the text, other algorithms for processing natural language do not have this feature.
However, the algorithm alone is not enough to fully analyze the text and extract structured information from it. It is necessary to take into account the morphology and syntax of the language of the processed text, connect the necessary dictionaries that are understandable to the parser. All this was available only to linguists with programming experience. Tomita-parser was developed specifically with an eye to simplify the work with the algorithm. A simple syntax for creating dictionaries and grammars was compiled, and the work with the morphology of the Russian and Ukrainian languages was thought out. Now, with due perseverance and understanding of the structure of the Russian language, almost anyone can understand the syntax and prepare the parser for its own purposes. Of course, deeper knowledge of linguistics and the ability to work with regular expressions will be an absolute plus, but not a necessary condition.
Today, Tomita is used in four Yandex services:
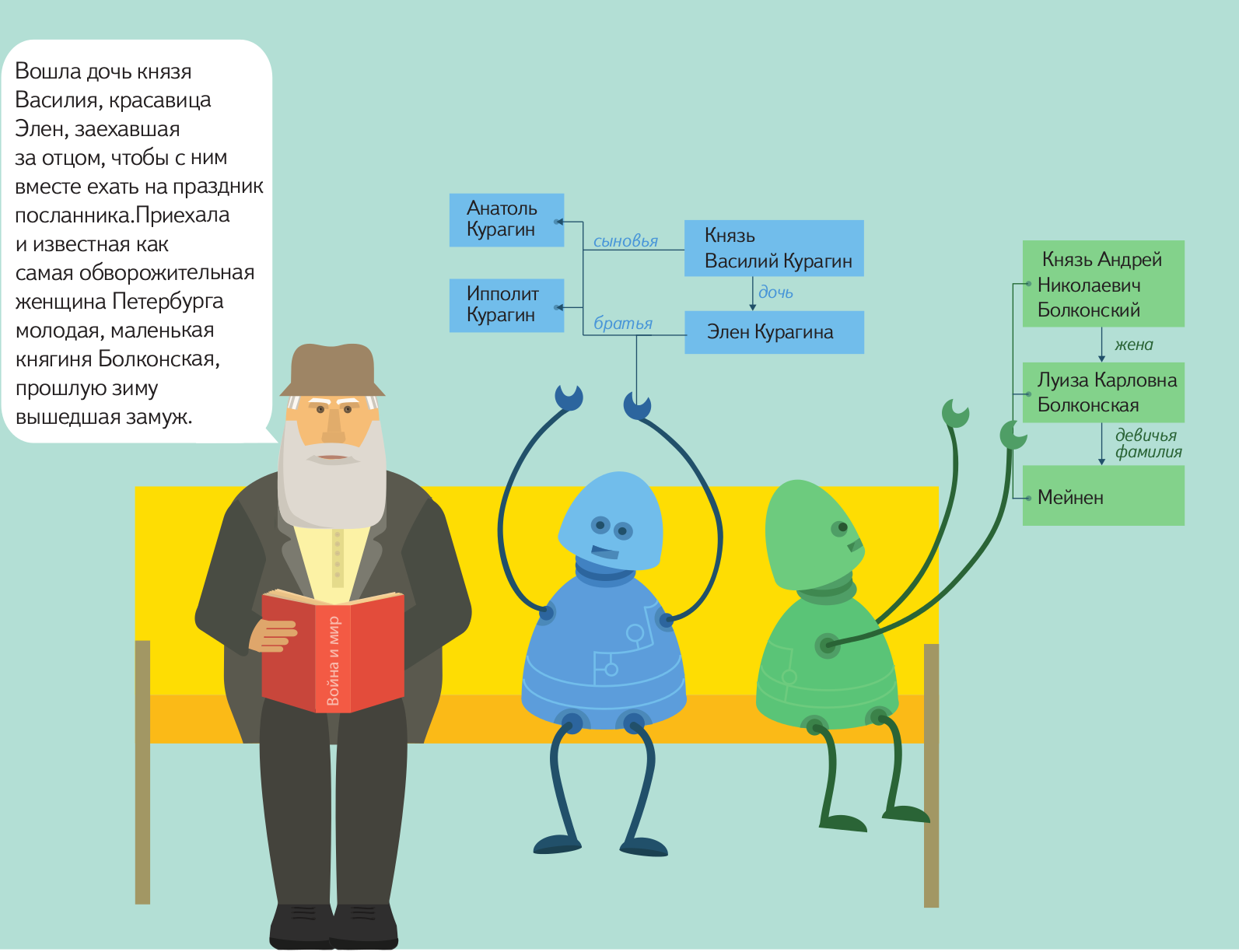
In the minimum configuration, the parser itself is given to the parser as well as the dictionary and grammar. The volume of the dictionary and the complexity of the grammar depend on the goals of the analysis: they can be both very small and huge. The grammar file consists of templates written in the internal language / formalism of Tomita-parser. These templates describe in generalized form a chain of words that may occur in the text. In addition, grammars determine how exactly the extracted facts should be presented in the final output.
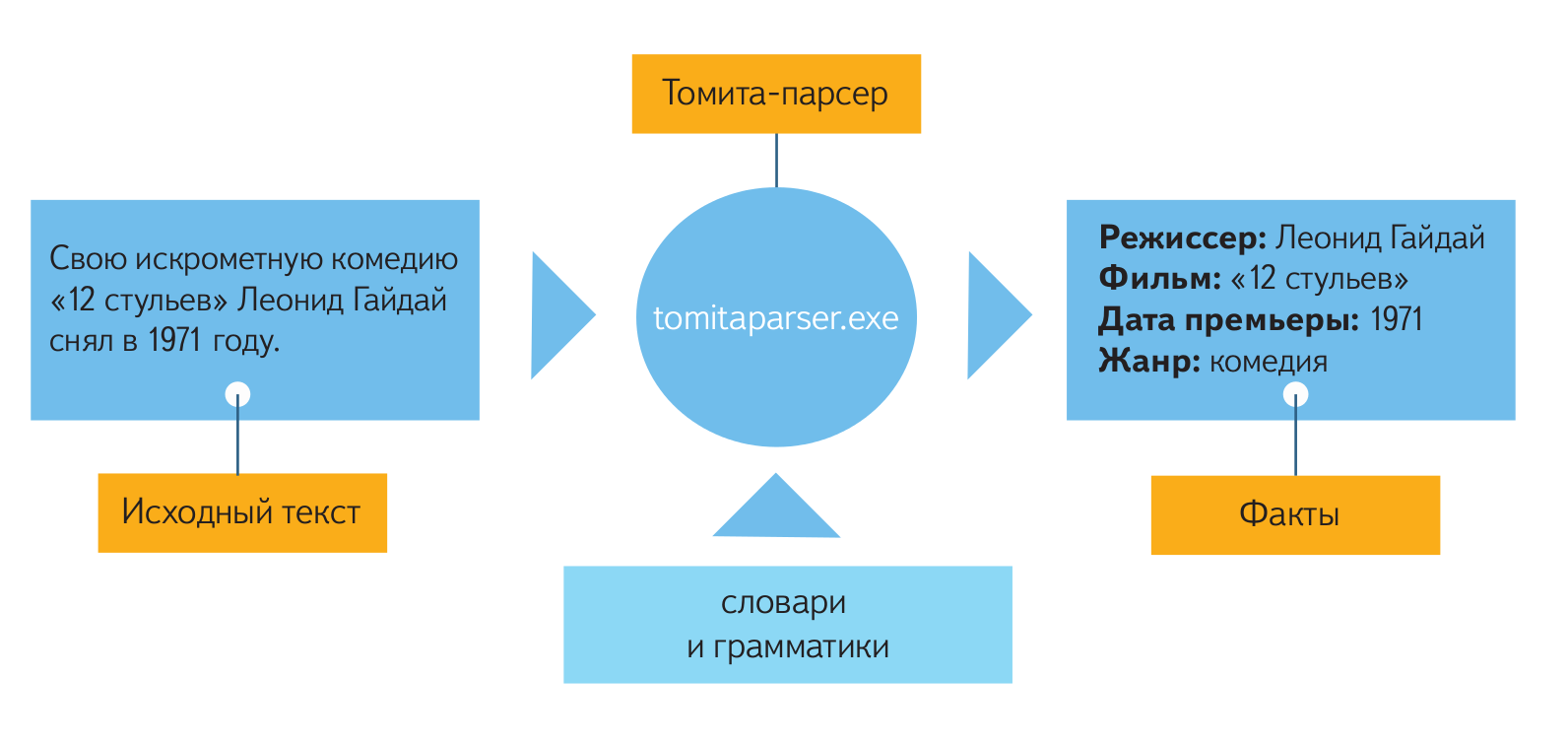
The dictionaries contain keywords that are used in the process of analysis by grammars. Each article of this dictionary defines a set of words and phrases united by a common property. For example, "all cities of Russia". Then in the grammar you can use the property "is the city of Russia". Words or phrases can be set explicitly as a list, or you can “functionally” by specifying a grammar that describes the necessary chains.
Below is a grammar that helps to extract from the text in a natural language and connect with each other the name of the director, the name and genre of the film, which he shot. Also provided is a dictionary that lists various genres and forms in which they can be used in the text.
As can be seen from the examples, in the grammar we first determine the name and surname of the director as a chain of words consisting of one or more capital letters, matched by number and case. Next, we indicate how to recognize the name of the film: it must be one or more words enclosed in quotation marks, the first word must begin with a capital letter. To determine the genre affiliation of films, we refer to a specially prepared dictionary with genres. The dictionary contains articles marked by the type to which the grammar refers. Each article consists of a title, keys, and a lemma. One or more keys reflect how a particular concept can be displayed in the text, and you can specify options for coordination between words in the key. The lemma is the form to which all keys will be cast during normalization, so everything will be displayed in the final table with facts.

You can try to independently conduct the same analysis of the text about the movie. The archive of the link contains all the necessary files for work and examples of proposals that are suitable for our templates.
In the form of binary packages under Windows, OS X and Linux, the Tomita-parser is available now, but it’s not so easy to figure out how to write your own grammars and dictionaries. Therefore, we have prepared a series of training videos. In the next post we will try to give a slightly more detailed description of the syntax and principles of working with Tomita based on these lessons. Well, the most impatient and stubborn now can get acquainted with the video and documentation .
Of course, the dream of full-fledged communication with a computer in a natural language is still far from a full-fledged implementation, about as much as the dream of artificial intelligence. However, some results are already there: the machine can be taught to find the necessary objects in the text in natural language, to find connections between them and to present the necessary data in a formalized form for further processing. In Yandex, this technology has been used for quite some time. For example, if you receive a letter with a proposal to meet in a certain place and at a certain time, a special algorithm will independently extract the necessary data and offer to add it to the calendar.
')
Soon we plan to give this technology to open source, so that anyone can use it and develop it, bringing with it the bright future of free communication between humans and computers. Preparations for the opening of source codes have already begun, but this process is not as fast as we would like, and most likely will last until the end of this year. During this time, we will try to tell as much as possible about our product, for which we launch a series of posts, within the framework of which we will tell about the device design and the principles of working with it.
Tomita-parser technology is called, and by and large, anyone can use it right now: binary files are available for download. However, before using the technology, you need to learn how to cook it properly.
GLR algorithm
The tool is named in honor of the Japanese scientist Masaru Tomita, the author of the GLR parsing algorithm (Generalized left-to-right algorithm), on the basis of which Tomita-parser was created. Back in 1984, he described the implementation of this algorithm, setting himself the task of efficiently and accurately performing analysis of texts in natural language. In some ways, the GLR algorithm is an extended version of the LR parsing algorithm. But the LR algorithm is intended for analyzing texts written in fairly strictly deterministic programming languages and cannot work with natural language. Tomita solved this problem by parallelizing the stacks, which made it possible to consider different interpretations of various sections of the text: as soon as the possibility of different interpretations arises, the stack forks. There can be several such sequential branches, but in the process of analysis, erroneous branches are discarded, and the result is the longest string. In this case, the algorithm gives the results of its work in real time, as it moves deeper into the text, other algorithms for processing natural language do not have this feature.
However, the algorithm alone is not enough to fully analyze the text and extract structured information from it. It is necessary to take into account the morphology and syntax of the language of the processed text, connect the necessary dictionaries that are understandable to the parser. All this was available only to linguists with programming experience. Tomita-parser was developed specifically with an eye to simplify the work with the algorithm. A simple syntax for creating dictionaries and grammars was compiled, and the work with the morphology of the Russian and Ukrainian languages was thought out. Now, with due perseverance and understanding of the structure of the Russian language, almost anyone can understand the syntax and prepare the parser for its own purposes. Of course, deeper knowledge of linguistics and the ability to work with regular expressions will be an absolute plus, but not a necessary condition.
Where is Tomita used?
Today, Tomita is used in four Yandex services:
- Post office. As mentioned above, if you receive a letter in which you are offered to meet in any way, Tomita will determine where and when this meeting will take place, and will offer to add it to the calendar. Approximately the same is the case with air tickets.
- News. In this service, Tomita helps to automatically carry out geo-referencing and grouping news stories. If the note mentions the name of the country, city, or the full address of the place where the described event occurred, Tomita will highlight this information and link the note to a point on the map.
- Auto.
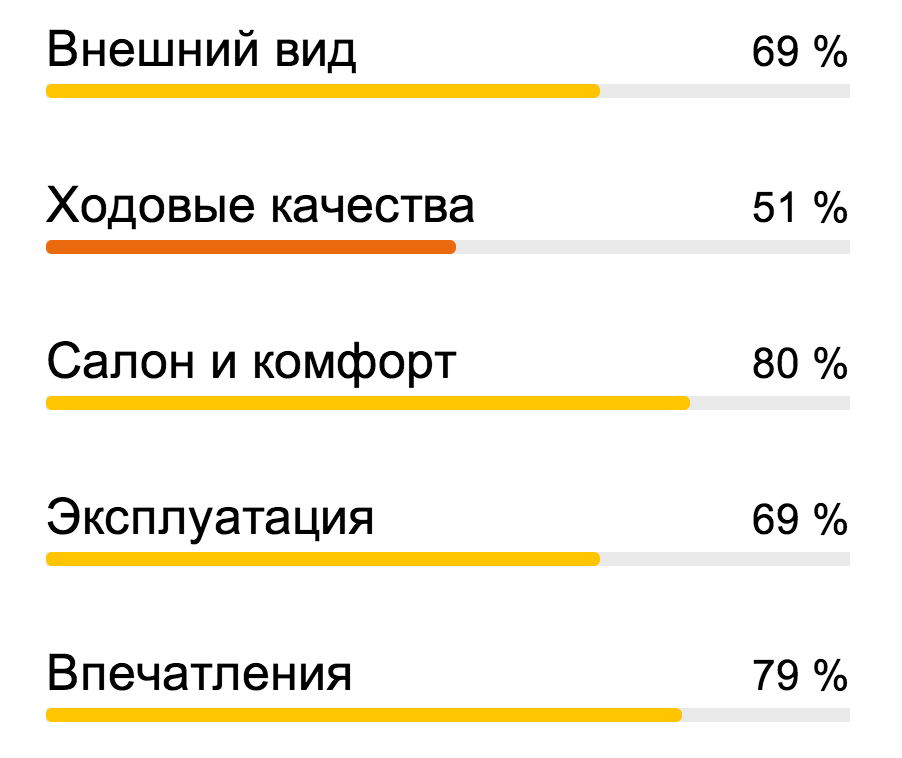 The Yandex.Avto service aggregates reviews about cars from various sites, you can also leave your feedback there. Tomita analyzes these reviews, evaluates the emotional color of statements about the various characteristics of cars. Based on these data, a rating of characteristics is compiled: appearance, ride quality, beauty and comfort, operation, and impressions.
The Yandex.Avto service aggregates reviews about cars from various sites, you can also leave your feedback there. Tomita analyzes these reviews, evaluates the emotional color of statements about the various characteristics of cars. Based on these data, a rating of characteristics is compiled: appearance, ride quality, beauty and comfort, operation, and impressions. - Job. Like Yandex.Avto Work collects ads from different sites about finding employees. They are also usually in arbitrary form. Tomita analyzes these texts and highlights the requirements for candidates and working conditions, formalizes them, so that users can filter job openings when searching for a job.
How it all works in practice
In the minimum configuration, the parser itself is given to the parser as well as the dictionary and grammar. The volume of the dictionary and the complexity of the grammar depend on the goals of the analysis: they can be both very small and huge. The grammar file consists of templates written in the internal language / formalism of Tomita-parser. These templates describe in generalized form a chain of words that may occur in the text. In addition, grammars determine how exactly the extracted facts should be presented in the final output.
The dictionaries contain keywords that are used in the process of analysis by grammars. Each article of this dictionary defines a set of words and phrases united by a common property. For example, "all cities of Russia". Then in the grammar you can use the property "is the city of Russia". Words or phrases can be set explicitly as a list, or you can “functionally” by specifying a grammar that describes the necessary chains.
Below is a grammar that helps to extract from the text in a natural language and connect with each other the name of the director, the name and genre of the film, which he shot. Also provided is a dictionary that lists various genres and forms in which they can be used in the text.
Grammar
#encoding "utf-8" #GRAMMAR_ROOT S PersonName -> Word<h-reg1, nc-agr[1]> Word<h-reg1, nc-agr[1]>*; // - , FilmName -> AnyWord<h-reg1, quoted>; // - FilmName -> AnyWord<h-reg1, l-quoted> AnyWord* AnyWord<r-quoted>; // , GenreChain -> Word<kwtype=genre_type> interp (Film.Genre); // - , genre Film -> ''; // Descr -> GenreChain | Film; // Director -> PersonName interp (Film.Director); // PersonName Director Film S -> Descr Director<gram=""> FilmName interp (Film.Name::not_norm); // - . , : " " Vocabulary
// ( genre), - genre_type "_1" { key = { " " agr=gnc_agr } // key = { " " agr=gnc_agr } // key = { " " agr=gnc_agr } mainword = 2 // lemma = "" //, } genre_type "_2" // { key = "" lemma = "" // } genre_type "_" { key = { " " gram={",", word=2} } key = "" | "" lemma = " " } genre_type "" { key = "" lemma = "" } As can be seen from the examples, in the grammar we first determine the name and surname of the director as a chain of words consisting of one or more capital letters, matched by number and case. Next, we indicate how to recognize the name of the film: it must be one or more words enclosed in quotation marks, the first word must begin with a capital letter. To determine the genre affiliation of films, we refer to a specially prepared dictionary with genres. The dictionary contains articles marked by the type to which the grammar refers. Each article consists of a title, keys, and a lemma. One or more keys reflect how a particular concept can be displayed in the text, and you can specify options for coordination between words in the key. The lemma is the form to which all keys will be cast during normalization, so everything will be displayed in the final table with facts.
You can try to independently conduct the same analysis of the text about the movie. The archive of the link contains all the necessary files for work and examples of proposals that are suitable for our templates.
How to use Tomita in your projects?
In the form of binary packages under Windows, OS X and Linux, the Tomita-parser is available now, but it’s not so easy to figure out how to write your own grammars and dictionaries. Therefore, we have prepared a series of training videos. In the next post we will try to give a slightly more detailed description of the syntax and principles of working with Tomita based on these lessons. Well, the most impatient and stubborn now can get acquainted with the video and documentation .
Source: https://habr.com/ru/post/219311/
All Articles