How dies technology? Elements of Reliability Theory
Some people who are interested in our services ask the question: “Servers that you provide are new or used?” It was this question that prompted us to delve a little into the theory of reliability and tell us what a new server is not better than a completely new one, as well as the meaning of the inscription "Lifetime" in the documentation for your refrigerator, why and for what reasons you need to think in advance about replacing the working laptop and some other interesting things.

In the case of servers, experiencing first causes the state of hard drives. Many are convinced that if they are put into the server new discs, just brought from the factory, they will serve happily. But not everyone knows that there is a certain section on the life cycle curve, on which a new device can die as quickly as a spawned species. To this we will return a little later, but for now ...
The theory of reliability (also sometimes called the theory of failures) is a scientific area that studies the principles, patterns, and the compilation of statistical models of technical device failures. It arose as a branch of statistics and probability theory as early as the 19th century and was originally used by maritime insurance and life insurance companies to estimate which tariffs would be profitable in the realities of those times. In the 30s-40s of the 20th century, principles for calculating the reliability of power systems were laid. Since then, the science of technology failures has evolved in parallel with the technology itself.
')
All technical objects according to the theory of reliability are divided into recoverable and non-recoverable . At the same time, attribution to non-recoverable does not necessarily mean the complete impossibility of repair, but also includes cases when such repair is not economically feasible. For example, if in your 3-year-old laptop your battery finally died with the controller, and the replacement will cost as much as a third of a new and more modern laptop, it is better to classify your old one as unrecoverable and write it off for scrap. This may seem obvious, but in practice, not all produce an appropriate assessment and make the right conclusions. This is especially true for the owners of domestic automobiles produced in the 1970s and 1980s, who sometimes manage to invest in them for the cost of used foreign cars of the early 1990s during several years of operation.
The technical state is divided into 5 types: health / malfunction , operability / non-operability and limit state . The first two states characterize the conformity of the device to technical documentation, the second two - the ability of the device to perform its functions. Some people confuse these concepts, although in practice, failure does not always mean inoperability. An example from the personal life: I handed over a tablet for repair, for some reason it replaced the system board. The new board was from another series, and the RAM instead of 512 MB was 384 MB. The tablet, of course, works quite well. But the technical documentation is no longer consistent, because it cannot be taken from repair as serviceable.
A limit state is a state where further exploitation or repair is unacceptable, impossible or impractical. It is also worthwhile to introduce the concept of a resource - the total operating time (duration / volume of work) of a device before going to the limit state. In everyday life resource work can often be found on the light-housekeepers. In this case, naturally, the average resource is indicated - the expectation based on product testing.
Similar to the resource, but containing more hypotheses, the concept of service life . In essence, it is an attempt to translate the actual resource of a device at some calendar time, i.e. indicates the time over which the resource will be exhausted on average. When calculating, information is used about how much time the average person spends in front of the TV or how many times a week he erases things.
There are several parameters that quantitatively describe the reliability of a device. They are usually determined experimentally on a test batch, sometimes using extrapolation, if it is not possible to wait for the failure of the entire experimental batch (for example, in the case of long-lived, highly reliable devices).
The probability of failure-free operation P (t) is the probability that in the time interval t no device in the sample will fail. Also called the law of distribution of reliability.
The probability of failure F (t) is the characteristic opposite of P (t) and showing the probability of at least one failure before the time t. Graphically, both functions look like this:

The following expression is always true: P (t) + F (t) = 1.
The distribution density of failure-free operation is called the failure rate and is calculated as the time derivative of the probability of failure:
a (t) = d F (t) / dt,
and the failure rate per unit time (or just the failure rate ) λ (t) is defined as the ratio of the failure rate to the probability of failure-free operation:
λ (t) = a (t) / P (t)
The failure rate graph is as follows:
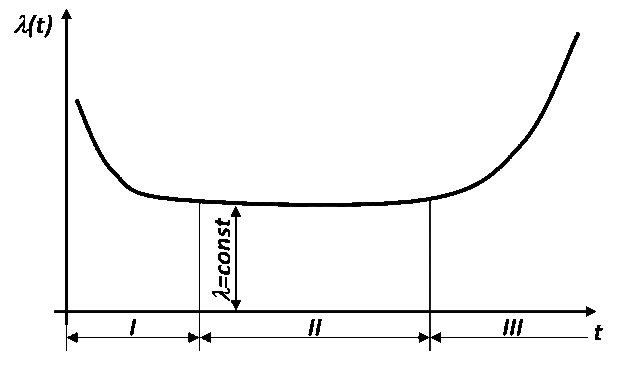
The curve is divided into 3 zones: I - the stage of running-in , II - normal operation , III - aging (wear) . At the stage of running-in, mostly defective products die. And if there are a lot of defects in a batch of devices, the consequences of mass exploitation of such a batch can vary from unpredictable to catastrophic. In the comments to the article about how people lost their data , a person told about the experience of using hard drives from one defective batch in a server, when 24 drives died one by one.
And here we smoothly get to the fact that the new discs, and any other equipment that just came off the assembly line, are not at all a synonym for reliability. And at the same time to the fact that the equipment that has successfully worked for 2-3-5 months, most likely, will serve for many more years (or how much it has been allocated there).
We should also consider the aging stage. It is believed that for some devices and parts wear is practically not characteristic. In particular, they include semiconductor devices. It is believed that under the operating conditions stipulated by the standards, the life of such devices is almost eternal. In computer technology, processors and volatile (operational) memory can be referred to as such. Practice shows that they are more likely to go to the best of worlds because of a power failure (power surge or something like that). But all the storage devices known to me, unfortunately, are subject to aging. In HDD, the mechanics wear out and the pancakes fall off, memory cells wear out in the SSD (however, only the recording wears them out, which makes the situation much easier if you rarely need to write and store for a long time), magnetic media are demagnetized, the reflective layer fades on the optical.
By the way, an amusing fact: the life cycle of living organisms is somewhat similar to the life cycle of technical devices. Below is a graph of the probability of death versus age based on real US statistics for 2003.

Sad as it may seem, it may even sound cruel, but people also have a stage of extra earnings, during which weak kids leave for the best of worlds.
But in practice, we all should remember that everything has its own resource and its service life. And we will save ourselves from a multitude of problems if we monitor the operating time of devices both in industry and in everyday life. Even more it concerns life, because on an industrial scale, this is often followed by experts.
I hope this article will help someone decide to buy a new car or laptop, putting aside the thought "I still have not crumbled the old." Or, it will force you to install on your servers a monitoring system of the “health” of hard disks and, seeing the increasing frequency of errors, make a replacement before the failure or the limit state occurs.
In the case of servers, experiencing first causes the state of hard drives. Many are convinced that if they are put into the server new discs, just brought from the factory, they will serve happily. But not everyone knows that there is a certain section on the life cycle curve, on which a new device can die as quickly as a spawned species. To this we will return a little later, but for now ...
Some theory
The theory of reliability (also sometimes called the theory of failures) is a scientific area that studies the principles, patterns, and the compilation of statistical models of technical device failures. It arose as a branch of statistics and probability theory as early as the 19th century and was originally used by maritime insurance and life insurance companies to estimate which tariffs would be profitable in the realities of those times. In the 30s-40s of the 20th century, principles for calculating the reliability of power systems were laid. Since then, the science of technology failures has evolved in parallel with the technology itself.
')
All technical objects according to the theory of reliability are divided into recoverable and non-recoverable . At the same time, attribution to non-recoverable does not necessarily mean the complete impossibility of repair, but also includes cases when such repair is not economically feasible. For example, if in your 3-year-old laptop your battery finally died with the controller, and the replacement will cost as much as a third of a new and more modern laptop, it is better to classify your old one as unrecoverable and write it off for scrap. This may seem obvious, but in practice, not all produce an appropriate assessment and make the right conclusions. This is especially true for the owners of domestic automobiles produced in the 1970s and 1980s, who sometimes manage to invest in them for the cost of used foreign cars of the early 1990s during several years of operation.
The technical state is divided into 5 types: health / malfunction , operability / non-operability and limit state . The first two states characterize the conformity of the device to technical documentation, the second two - the ability of the device to perform its functions. Some people confuse these concepts, although in practice, failure does not always mean inoperability. An example from the personal life: I handed over a tablet for repair, for some reason it replaced the system board. The new board was from another series, and the RAM instead of 512 MB was 384 MB. The tablet, of course, works quite well. But the technical documentation is no longer consistent, because it cannot be taken from repair as serviceable.
A limit state is a state where further exploitation or repair is unacceptable, impossible or impractical. It is also worthwhile to introduce the concept of a resource - the total operating time (duration / volume of work) of a device before going to the limit state. In everyday life resource work can often be found on the light-housekeepers. In this case, naturally, the average resource is indicated - the expectation based on product testing.
Similar to the resource, but containing more hypotheses, the concept of service life . In essence, it is an attempt to translate the actual resource of a device at some calendar time, i.e. indicates the time over which the resource will be exhausted on average. When calculating, information is used about how much time the average person spends in front of the TV or how many times a week he erases things.
There are several parameters that quantitatively describe the reliability of a device. They are usually determined experimentally on a test batch, sometimes using extrapolation, if it is not possible to wait for the failure of the entire experimental batch (for example, in the case of long-lived, highly reliable devices).
The probability of failure-free operation P (t) is the probability that in the time interval t no device in the sample will fail. Also called the law of distribution of reliability.
The probability of failure F (t) is the characteristic opposite of P (t) and showing the probability of at least one failure before the time t. Graphically, both functions look like this:
The following expression is always true: P (t) + F (t) = 1.
The distribution density of failure-free operation is called the failure rate and is calculated as the time derivative of the probability of failure:
a (t) = d F (t) / dt,
and the failure rate per unit time (or just the failure rate ) λ (t) is defined as the ratio of the failure rate to the probability of failure-free operation:
λ (t) = a (t) / P (t)
The failure rate graph is as follows:
The curve is divided into 3 zones: I - the stage of running-in , II - normal operation , III - aging (wear) . At the stage of running-in, mostly defective products die. And if there are a lot of defects in a batch of devices, the consequences of mass exploitation of such a batch can vary from unpredictable to catastrophic. In the comments to the article about how people lost their data , a person told about the experience of using hard drives from one defective batch in a server, when 24 drives died one by one.
And here we smoothly get to the fact that the new discs, and any other equipment that just came off the assembly line, are not at all a synonym for reliability. And at the same time to the fact that the equipment that has successfully worked for 2-3-5 months, most likely, will serve for many more years (or how much it has been allocated there).
We should also consider the aging stage. It is believed that for some devices and parts wear is practically not characteristic. In particular, they include semiconductor devices. It is believed that under the operating conditions stipulated by the standards, the life of such devices is almost eternal. In computer technology, processors and volatile (operational) memory can be referred to as such. Practice shows that they are more likely to go to the best of worlds because of a power failure (power surge or something like that). But all the storage devices known to me, unfortunately, are subject to aging. In HDD, the mechanics wear out and the pancakes fall off, memory cells wear out in the SSD (however, only the recording wears them out, which makes the situation much easier if you rarely need to write and store for a long time), magnetic media are demagnetized, the reflective layer fades on the optical.
By the way, an amusing fact: the life cycle of living organisms is somewhat similar to the life cycle of technical devices. Below is a graph of the probability of death versus age based on real US statistics for 2003.
Sad as it may seem, it may even sound cruel, but people also have a stage of extra earnings, during which weak kids leave for the best of worlds.
And what in practice?
But in practice, we all should remember that everything has its own resource and its service life. And we will save ourselves from a multitude of problems if we monitor the operating time of devices both in industry and in everyday life. Even more it concerns life, because on an industrial scale, this is often followed by experts.
I hope this article will help someone decide to buy a new car or laptop, putting aside the thought "I still have not crumbled the old." Or, it will force you to install on your servers a monitoring system of the “health” of hard disks and, seeing the increasing frequency of errors, make a replacement before the failure or the limit state occurs.
Source: https://habr.com/ru/post/219189/
All Articles