Enhance visual quality for photographs of documents
 Recently, users are increasingly receiving images of documents using cameras or mobile devices, resorting to using a scanner occasionally, in special cases. At the same time, the following drawbacks are characteristic of images taken by cameras: geometric distortions (we talked about them in the article about automatic document highlighting ), uneven illumination (you can often see shadows or highlights when using a flash), a drop in contrast, defocusing, blurring , digital noise in low light. We will try to get rid of these shortcomings by applying some transformations to the original image in order to bring its look closer to the scanned one.
Recently, users are increasingly receiving images of documents using cameras or mobile devices, resorting to using a scanner occasionally, in special cases. At the same time, the following drawbacks are characteristic of images taken by cameras: geometric distortions (we talked about them in the article about automatic document highlighting ), uneven illumination (you can often see shadows or highlights when using a flash), a drop in contrast, defocusing, blurring , digital noise in low light. We will try to get rid of these shortcomings by applying some transformations to the original image in order to bring its look closer to the scanned one.First of all, we note that a simple increase in contrast relative to the average signal level does not work in most cases, as can be seen in the figure:


On the left - the original image, on the right - the result of increasing the contrast.
')
It can be seen that a more complex algorithm is needed, taking into account the unevenness of illumination. Let's try to make an adaptive increase in contrast relative to the local average. The local average is calculated for each pixel within a square neighborhood, the center of which it is. The size of the neighborhood should be selected based on the expected size of the letters and the thickness of the stroke. There are algorithms for quickly calculating local averages, for example, an integral matrix ( summed area table ). If before increasing the contrast from the local average, subtract a constant corresponding to an estimate of the noise level in the image, then for simple documents the result can be quite satisfactory:


On the left is a map of “thresholds” (brightness levels), relative to which an increase in contrast occurs. Right - the result of the application.
It is also possible to increase the contrast with respect to the average value between the local minimum and maximum.
Everything becomes much worse if the document contains flat areas, reversals , or inverted text, the size of the letters may differ several times, and there may be photographs next to the text. This is what the result looks like on a complex layout:


On the left - the original image, on the right - the result of increasing the contrast.
It can be seen that in the photographs a significant part of the images is lost, the inverted parts of the text, the inversion look differently than in the original document, the capital letters have a contour view without a fill. All this creates additional difficulties for the subsequent analysis and recognition of such documents.
The task is to somehow build such a map of “thresholds”, in relation to which an increase in contrast would lead to an increase in visual quality, and which would take into account the features of documents with complex layout. Such a threshold map will also be useful for obtaining a binarized (black and white) image of a document. The process of binarization can be considered as a special case when the increase in contrasts in the image tends to infinity.
The proposed algorithm allows us to build an acceptable threshold map for complex documents. To take into account objects of different sizes in the image, the pyramidal decomposition of the image is used. Schematically, this process is shown in the figure:
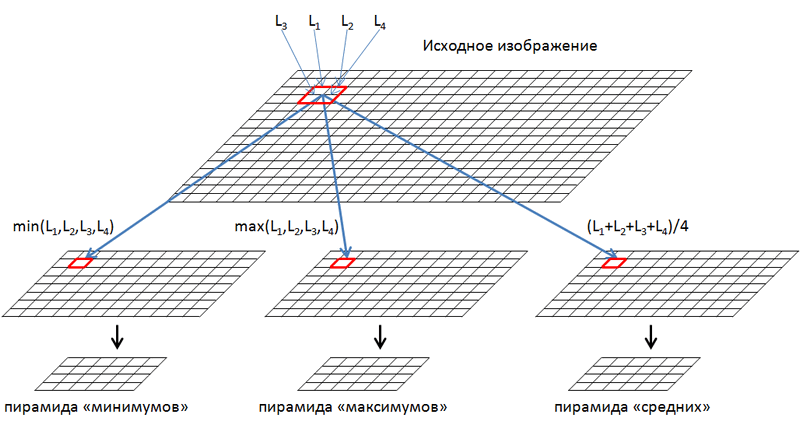
Decomposition begins with the scale of the original image. It is divided into non-intersecting squares with a size of 2x2 pixels, in each of which we get the values of the minimum, maximum and average of the 4 pixels that make it up. Further, from these values we form three images: minima, maxima and averages, which are reduced by 2 times horizontally and vertically relative to the original. Repeat the procedure and decompose the resulting images in the pyramids to a level where the size is still at least 2 pixels horizontally and vertically.
Using the pyramidal decomposition, we obtain the values of the minima, maxima and averages for the original parts of the image corresponding to the different scales of its representation. Typical images of documents contain 9-12 levels of decomposition.
The algorithm for constructing a map of thresholds based on pyramidal decomposition is as follows:
- At the bottom level of the pyramid decomposition, where the image consists of only a few pixels, we initialize the threshold map using either of the two hypotheses:
- the local average of this part of the image (i.e., the brightness of the pixel from the pyramid of medium)
- the average between the local minimum and maximum (the average of the brightness of 2 pixels taken from the pyramids of the minima and maxima).
- We move to the next level of decomposition, increasing the map of thresholds by 2 times horizontally and vertically using interpolation with convolutions [1 3], [3 1].
- In each pixel at the new level of the pyramid expansion, we calculate the difference between the pixel value from the pyramid of maxima and the value from the pyramid of minima. If this difference does not exceed the noise threshold, we believe that there is no useful signal in this area of the image, and both at this and at subsequent levels of pyramidal decomposition. Consequently, the threshold value obtained at the previous decomposition level can be left unchanged. Otherwise, we calculate a new, refined threshold value, based on a mixture of two hypotheses, 1a and 1b.
- Steps 2 and 3 are repeated until we reach a level of decomposition in which the image areas corresponding to the pixels in the pyramid still have a size larger than the smallest letters visible in the image. Typically, these letters have a size of about 6-10 pixels, this corresponds to the 3rd or 4th level of the pyramid.
As a result, we get a map of thresholds, in relation to which the increase in contrast does not lead to the loss of objects of different sizes, in addition, the flat homogeneous areas in the image do not contain noise:


On the left is a map of thresholds, on the right is the result of an increase in contrast relative to it.
It remains to be decided how to deal with color images, since an increase in contrast often leads to a loss in color. You can increase the contrast for the brightness component (gray image), taking into account the areas with saturated color, reducing their contrast ratio.
We use our own color space similar to HSL , but instead of the brightness L we will work with the Y component in the YCbCr color space.
For a gray image, the contrast increases as follows:
Y '= k (Y - T) + T, where T is the brightness value for the same pixel from the threshold map, Y and Y' is the initial and obtained brightness value of the pixel, k is the contrast increase factor, usually its value lies in the range from 3 to 6.
For pixels whose saturation is high, we will often get the wrong color, since the range of acceptable values for the color components is limited. Therefore, for a color image, the coefficient k in this formula must be made inversely proportional to the color saturation. Additional normalization factors are easy to find empirically.
For areas with low saturation, you can, on the contrary, reduce the color saturation down to 0, suppressing the color noise in the image. This is easy to do by mixing the values from the color channels with the brightness in various proportions. It is also useful to increase the white balance in the image by histograms of the R, G, B channels before increasing the contrast.


On the left - the original image, on the right - the result of increasing the contrast, taking into account the color saturation.
Source: https://habr.com/ru/post/218285/
All Articles