Task management: some options for implementing repetitive tasks
One of the motives for creating our "bicycle", i.e. the task management system betasked.ru was the need to maximize the convenient accounting of repetitive tasks, as we did not give suitable solutions to Google. The specificity of our tasks is that there are many of them and for the most part they are repeated with varying degrees of periodicity.
Web-based task management services on the Internet a great many. Probably every second programmer who wants something special for his needs is looking for something suitable on the Internet and, not finding an ideal, writes his own version. The "mortality" of task management systems that claim to the mass market is also very high. I think there are two factors - big competition and big segmentation - someone needs an emphasis on group work, someone needs to keep notes. As a result, those who want to please everyone realize everything that is possible and it turns out that the resulting monster is difficult to use.
This post was written to show those who, sooner or later, will take on the implementation of repetitive tasks, possible difficulties (at least those we have encountered) and options. A brief (and quite obvious, often forgotten) conclusion of the post: it is not always necessary to solve the problem head-on while developing, stop often and analyze what you are doing and whether you are going there.
')

Looking ahead, I will say that the implementation of repetitive tasks took a lot of time and effort, but ultimately allowed us to come to a completely usable option, simultaneously solving many other difficult issues.
Those systems that we looked at, which supported repetitive tasks, had certain drawbacks, for someone unimportant, but critical for us:
MyLifeOrganized was the most advanced system for repeating tasks, but this is not a web application. C LeaderTask also did not grow together, although many approaches to the interface are not bad there.
So, the task was to make the tasks repetitive. It would seem that difficult? From the point of view of database design, there was a question of choosing one of the options:
We considered the second option as the most logical and optimal, but it is optimal only if there are few fields (or parameters) for the task, if logic is required to maintain logic normally, then the amount of code, for example, database triggers is very large. They wrote, wrote, stopped in time. Stayed first option.
Its disadvantages were as follows:
In addition, she was not satisfied with the complexity of servicing the “chain” of repetitive tasks for both the user and the programmer. Here, for example, are small, but time-consuming questions:
Separately, there was a question of usability - how to identify different instances of the problem, except by date? Those. in the task list we had a bunch of identical tasks, differing only in date. You can clearly see it in the title picture of the post.
It became clear that it is necessary to allow the user to edit the name of each instance of the task. Previously it was banned, because as you rename - then the devil will figure out where his repetition is. Dopili such possibility (separate change) for the majority of the main fields of the task. But it also did not particularly improve usability.
It was decided that the best solution would be to make the tasks more visible with the option of automatic substitution. That is, specifying in the title of the task, for example, “%% this.date.month %%”, this expression would be replaced with the name of the month when displayed. If you call the task "Reporting of ATP Ltd. to the tax for %% this.date.quarter.prev %% q %% this.date.month.prev.year %% g", you get the following picture:
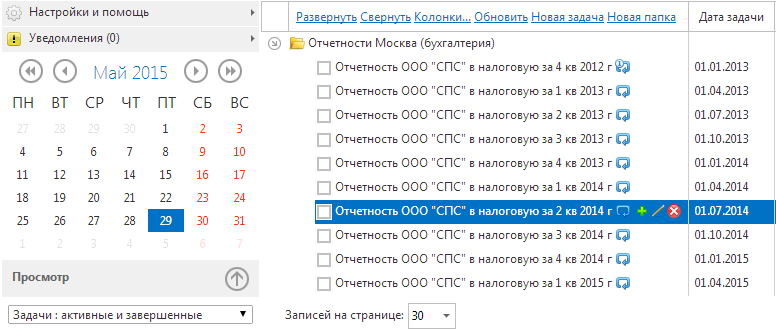
This was already quite the solution. Having blocked a lot of options for possible expressions, we realized that this was just the beginning. Auto substitution should work everywhere, when displayed on the screen, in notifications sent, so they killed for the implementation of this “hack” for more than a month. We took it into account almost everywhere. But still the number of settings for the task repetition function was too large. Too many manipulations were required to simply repeat the “Workout” task every week.
In short, it turned out to be some kind of monstrous mechanism, which was difficult to maintain and could not be understood by the user without the help.
Therefore, we decided to leave this mechanism, and try to implement the repetition of tasks through triggers, since it was more interesting. There was nothing revolutionary in this, since the triggers in relational and not only databases have existed for a long time, but I wanted to see what came of it.
We decided to make such an implementation - let each time a certain user operation with the task be automatically performed a certain action. That is, for each:
we can customize
To implement exactly the repetitions, it was necessary to make a custom delay in the execution of the action, for example, after completing the task after 10 days, re-do it again.
Now it turned out to implement the repetition of the task after certain periods, counted from the moment of the previous execution. It became clear that the option with triggers is much more flexible, so the following features were added:
As a result, we got a fairly flexible and customizable system, but returned again to the same problem - the user had to configure it for too long. To install a simple weekly repetition it was necessary to do too many manipulations.
To solve this problem, we added the ability to install triggers directly to:
And it was precisely the ability to install triggers on tasks with a certain label that made life much easier for us. Now the setting for repeating a specific task was reduced to:
Everything. Setting for yourself once and for all the necessary principles of repetition (“Monthly 20th”, “Annually March 8th”, “Monday”), then you could simply mark the necessary tasks with these labels and all the rules of repetition applied to them.
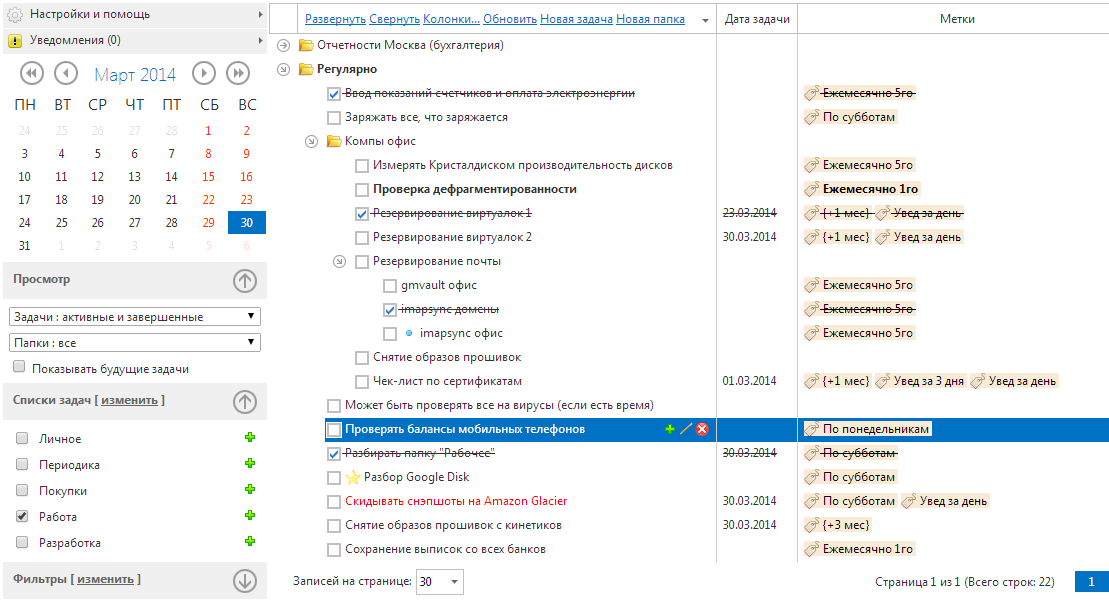
There were, of course, a few unresolved issues, something was not fully implemented (for example, flexible adjustment of repetition periods), but for most practical tasks this was already enough, at the same time the very presentation of the tasks became much more visual. Yes, for the initial setup you need to understand a little bit, editing the triggers of the tags is available through the Settings menu - Global Triggers, or by the Triggers context menu item for any task with this tag. In the future, we will slightly facilitate the life of new users already configured labels for periodic tasks.
For those 1-2 users who are interested in practical information about the implementation of triggers and setting up periodic repetition (and the need for it can be not only in task management, but also in scheduling, for example), I will describe the technical side schematically.
Web-based task management services on the Internet a great many. Probably every second programmer who wants something special for his needs is looking for something suitable on the Internet and, not finding an ideal, writes his own version. The "mortality" of task management systems that claim to the mass market is also very high. I think there are two factors - big competition and big segmentation - someone needs an emphasis on group work, someone needs to keep notes. As a result, those who want to please everyone realize everything that is possible and it turns out that the resulting monster is difficult to use.
This post was written to show those who, sooner or later, will take on the implementation of repetitive tasks, possible difficulties (at least those we have encountered) and options. A brief (and quite obvious, often forgotten) conclusion of the post: it is not always necessary to solve the problem head-on while developing, stop often and analyze what you are doing and whether you are going there.
')
Looking ahead, I will say that the implementation of repetitive tasks took a lot of time and effort, but ultimately allowed us to come to a completely usable option, simultaneously solving many other difficult issues.
Those systems that we looked at, which supported repetitive tasks, had certain drawbacks, for someone unimportant, but critical for us:
- either it was impossible to look at future tasks
- or the mechanism of their configuration and use was too cumbersome
MyLifeOrganized was the most advanced system for repeating tasks, but this is not a web application. C LeaderTask also did not grow together, although many approaches to the interface are not bad there.
So, the task was to make the tasks repetitive. It would seem that difficult? From the point of view of database design, there was a question of choosing one of the options:
- Each instance of a recurring task is a separate task and a separate entry in the task table.
- The recurring task pattern is stored separately, and tasks whose fields have been modified are stored separately. A similar storage mechanism is implemented in the Google Calendar - there, for example, when changing the event fields, a question is issued - to change the entire chain, only subsequent events or only one.
We considered the second option as the most logical and optimal, but it is optimal only if there are few fields (or parameters) for the task, if logic is required to maintain logic normally, then the amount of code, for example, database triggers is very large. They wrote, wrote, stopped in time. Stayed first option.
Its disadvantages were as follows:
- a large amount of entries in the task table. For example, there is a task, it needs to be repeated every week, so there is a separate task for every Sunday. The default restrictions for the user on the end date of repetitions are not set. Those. when creating a “task schedule”, its instances were created a year in advance. But also a variant of the curve - someone doesn’t need to plan so far at all, but someone is not enough years. Ok, added the ability for the user to set for how long ahead the tasks will be created.
- The approach itself, which consists in the fact that a separate instance of the task was created for each necessary date, was sometimes inappropriate. For example, why bother to keep and force the user to take into account a bunch of the same type of "Training" tasks with different dates?
In addition, she was not satisfied with the complexity of servicing the “chain” of repetitive tasks for both the user and the programmer. Here, for example, are small, but time-consuming questions:
- when deleting tasks, it was necessary that when the chain was rebuilt (for example, if the user changed the repetition parameters), the remote task was not recreated. After going through all the possible options, it turned out that the most suitable one is to store information about deleted tasks in a separate table. But experience suggested that the allocation of a separate table for this information is a sign of an incorrect approach and this will come around in the future. As a result, we made a parameter for a user who saves schedule changes - to recreate deleted tasks or not.
- the task chain should have a template, i.e. a task, the repetition of which is configured by the user and which, in fact, is copied into all created new instances. Given that the date of the task is optional, it would be logical to make it possible to repeat a task that does not have a date, i.e. there will be a task template (no date) and its repetition (they already have their own dates). But the practical use of this is rather inconvenient, since all this while working looks somehow cumbersome - a template, task instances. Without a help you will not understand.
- given the tree of task lists, I did not want to restrict the user and allow me to post different instances of repetitive tasks to different parent folders / tasks. But then another problem appeared - how the user will see the whole chain, or rather the problem was not exactly that, but the fact that these future instances of the task appeared in my opinion, not where the user expects it.
Separately, there was a question of usability - how to identify different instances of the problem, except by date? Those. in the task list we had a bunch of identical tasks, differing only in date. You can clearly see it in the title picture of the post.
It became clear that it is necessary to allow the user to edit the name of each instance of the task. Previously it was banned, because as you rename - then the devil will figure out where his repetition is. Dopili such possibility (separate change) for the majority of the main fields of the task. But it also did not particularly improve usability.
It was decided that the best solution would be to make the tasks more visible with the option of automatic substitution. That is, specifying in the title of the task, for example, “%% this.date.month %%”, this expression would be replaced with the name of the month when displayed. If you call the task "Reporting of ATP Ltd. to the tax for %% this.date.quarter.prev %% q %% this.date.month.prev.year %% g", you get the following picture:
This was already quite the solution. Having blocked a lot of options for possible expressions, we realized that this was just the beginning. Auto substitution should work everywhere, when displayed on the screen, in notifications sent, so they killed for the implementation of this “hack” for more than a month. We took it into account almost everywhere. But still the number of settings for the task repetition function was too large. Too many manipulations were required to simply repeat the “Workout” task every week.
In short, it turned out to be some kind of monstrous mechanism, which was difficult to maintain and could not be understood by the user without the help.
Therefore, we decided to leave this mechanism, and try to implement the repetition of tasks through triggers, since it was more interesting. There was nothing revolutionary in this, since the triggers in relational and not only databases have existed for a long time, but I wanted to see what came of it.
We decided to make such an implementation - let each time a certain user operation with the task be automatically performed a certain action. That is, for each:
- creating a task
- performing the task
- deleting a task
we can customize
- task creation (temporarily disabled this feature)
- setting a task as completed
- setting task mark as unfulfilled
- delete task
To implement exactly the repetitions, it was necessary to make a custom delay in the execution of the action, for example, after completing the task after 10 days, re-do it again.
Now it turned out to implement the repetition of the task after certain periods, counted from the moment of the previous execution. It became clear that the option with triggers is much more flexible, so the following features were added:
- trigger on a specific schedule. Those. triggered at regular intervals. The direct purpose is to “restore” tasks with a certain frequency. For example, every Saturday, make the task “Purchase for a picnic” unfulfilled.
- trigger that is triggered when the task date or deadline (task completion date) is reached. Its main purpose was found for notifications (by that time we didn’t undertake the implementation of notifications, and it was very helpful), together with a configurable delay, this made it possible for each task to have multiple notifications, for example, about the approach time by e-mail with different degree of periodicity
- for each trigger made possible the action "Move the date of the task." This allowed for those tasks for which the date is important, with each repetition to shift it. Similarly, the field “Task deadline” was received.
As a result, we got a fairly flexible and customizable system, but returned again to the same problem - the user had to configure it for too long. To install a simple weekly repetition it was necessary to do too many manipulations.
To solve this problem, we added the ability to install triggers directly to:
- all user tasks
- all tasks from a specific list
- all tasks with a specific label
And it was precisely the ability to install triggers on tasks with a certain label that made life much easier for us. Now the setting for repeating a specific task was reduced to:
- setting triggers on a particular tag. Those. a “weekly on saturday” label was created; it had a trigger set up, which marked all tasks with this tag that were unfulfilled on saturdays. This can be done once and more in the settings never climb.
- Set this label to the desired tasks.
Everything. Setting for yourself once and for all the necessary principles of repetition (“Monthly 20th”, “Annually March 8th”, “Monday”), then you could simply mark the necessary tasks with these labels and all the rules of repetition applied to them.
There were, of course, a few unresolved issues, something was not fully implemented (for example, flexible adjustment of repetition periods), but for most practical tasks this was already enough, at the same time the very presentation of the tasks became much more visual. Yes, for the initial setup you need to understand a little bit, editing the triggers of the tags is available through the Settings menu - Global Triggers, or by the Triggers context menu item for any task with this tag. In the future, we will slightly facilitate the life of new users already configured labels for periodic tasks.
For those 1-2 users who are interested in practical information about the implementation of triggers and setting up periodic repetition (and the need for it can be not only in task management, but also in scheduling, for example), I will describe the technical side schematically.
Briefly about implementation
Surprisingly, the implementation of triggers in our system is based on PostgreSQL DB triggers. Putting out the source codes of the triggers and PostgreSQL procedures probably does not make sense (plus there are too many of them), since the main value is the database structure, at least for me, sitting down from scratch to write this business would be the most important and save a lot of time.
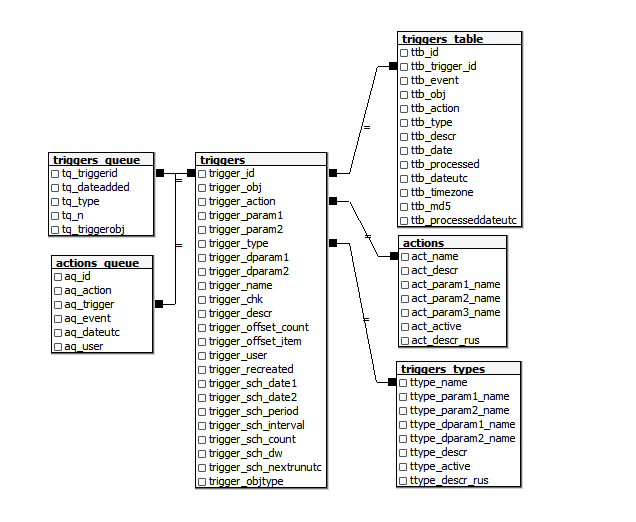
Table triggers_types . It simply stores information about the possible types of triggers (“When a task is completed,” “When the date of the task arrives,” “When the task is due,” ...).
Table actions . Stores information about possible types of actions when a trigger is triggered (“Delete task”, “Mark as done”, “Shift task completion date”, ...).
Table triggers . It contains descriptions of configured triggers, i.e .:
- trigger_id uuid - identifier
- trigger_obj uuid - object reference (task, list, user, ...)
- trigger_action varchar - type of action
- trigger_param1, trigger_param2 - fields for additional parameters (for example, the subject and text of the message upon notification)
- trigger_type varchar - the trigger type, i.e. what works
- trigger_dparam1, trigger_dparam2 - integer fields for dop parameters
- trigger_name - user name
- trigger_chk integer - checksum of parameters
- trigger_descr - custom description
- trigger_offset_count integer, trigger_offset_item - execution delay parameters
- trigger_user uuid - user ID
- trigger_recreated timestamp (3) —the date of the last check
- trigger_sch_date1, trigger_sch_date2 - start and end dates of repetition (for “Scheduled” triggers)
- trigger_sch_period, trigger_sch_interval, trigger_sch_count - repetition frequency settings (for “Scheduled” triggers)
To implement simple triggers (without execution delays), just the triggers table will suffice. That is, intercepting certain events (creating a task, approaching a time, executing a task) simply look through the table for suitable triggers and perform actions.
To use delayed triggers, i.e. performing actions with a delay; you need a separate actions_queue table, which contains the time, a reference to the object (task, list, ...) and the action to be performed. Every 5 minutes, the cronʻom processes the actions taken.
But with the triggers "When the date of the task arrives" and "When the date of the task arrives," especially with the set delays, the task is already more complicated. To solve it, a separate table is also required (we have triggers_table ), where records of all such dates will be stored, i.e. for each task there will be a separate entry for the task date and a separate entry for the task date. It was necessary, because Triggers can be installed on many tasks at once, so in order not to load the system regularly by calculating those tasks for which the trigger should work (and taking into account deferred triggers, that is, an additional time shift, plus accounting for the time zone that the user can change at any time this is a resource-intensive task), it is easier to put this information into a separate task. Well, do not forget to configure its auto-update when changing some parameters - the settings of the trigger itself, the dates of tasks, time zones.
Regarding time zones. Each user has his own time zone (in which all tasks are recalculated when displayed on the screen), and each task list can also have its own time zone. In the main task table (events, in our case), it is better to store time without specifying the time zone, this will significantly save the output of the task tree. But in all other tables, especially those related to triggers, it is better to store time in UTC.
Table triggers_types . It simply stores information about the possible types of triggers (“When a task is completed,” “When the date of the task arrives,” “When the task is due,” ...).
Table actions . Stores information about possible types of actions when a trigger is triggered (“Delete task”, “Mark as done”, “Shift task completion date”, ...).
Table triggers . It contains descriptions of configured triggers, i.e .:
- trigger_id uuid - identifier
- trigger_obj uuid - object reference (task, list, user, ...)
- trigger_action varchar - type of action
- trigger_param1, trigger_param2 - fields for additional parameters (for example, the subject and text of the message upon notification)
- trigger_type varchar - the trigger type, i.e. what works
- trigger_dparam1, trigger_dparam2 - integer fields for dop parameters
- trigger_name - user name
- trigger_chk integer - checksum of parameters
- trigger_descr - custom description
- trigger_offset_count integer, trigger_offset_item - execution delay parameters
- trigger_user uuid - user ID
- trigger_recreated timestamp (3) —the date of the last check
- trigger_sch_date1, trigger_sch_date2 - start and end dates of repetition (for “Scheduled” triggers)
- trigger_sch_period, trigger_sch_interval, trigger_sch_count - repetition frequency settings (for “Scheduled” triggers)
To implement simple triggers (without execution delays), just the triggers table will suffice. That is, intercepting certain events (creating a task, approaching a time, executing a task) simply look through the table for suitable triggers and perform actions.
To use delayed triggers, i.e. performing actions with a delay; you need a separate actions_queue table, which contains the time, a reference to the object (task, list, ...) and the action to be performed. Every 5 minutes, the cronʻom processes the actions taken.
But with the triggers "When the date of the task arrives" and "When the date of the task arrives," especially with the set delays, the task is already more complicated. To solve it, a separate table is also required (we have triggers_table ), where records of all such dates will be stored, i.e. for each task there will be a separate entry for the task date and a separate entry for the task date. It was necessary, because Triggers can be installed on many tasks at once, so in order not to load the system regularly by calculating those tasks for which the trigger should work (and taking into account deferred triggers, that is, an additional time shift, plus accounting for the time zone that the user can change at any time this is a resource-intensive task), it is easier to put this information into a separate task. Well, do not forget to configure its auto-update when changing some parameters - the settings of the trigger itself, the dates of tasks, time zones.
Regarding time zones. Each user has his own time zone (in which all tasks are recalculated when displayed on the screen), and each task list can also have its own time zone. In the main task table (events, in our case), it is better to store time without specifying the time zone, this will significantly save the output of the task tree. But in all other tables, especially those related to triggers, it is better to store time in UTC.
Source: https://habr.com/ru/post/217579/
All Articles