Automation of test infrastructure in the Search
It’s no secret that testing tasks, both manual and automated, constantly require the creation of new test benches.
In order for Mail.Ru Search AutoTests to run quickly and in all the necessary environments, we needed to learn how to quickly deploy new virtual machines with a specific configuration.
A large number of virtual machines in our cloud is used by WebDriver browser farm, by scaling it, we speed up the execution of tests of the web-based Search interface.
In addition, we run virtualka on tools for collecting code quality metrics and coverage measurement, as well as Search testing tools developed by us.

It all started with a single server with the KVM hypervisor installed and libvirt management installed. At the same time, each virtualka was created manually by admins each time via Task in Jira. Such a process imposed some restrictions on the efficiency and controllability of the testing department infrastructure.
Over time, when the number of virtual machines with Windows increased, the reliability of the solution decreased: from time to time VM with guest Windows hung up, consumed the entire CPU on the host machine, or suddenly rolled up updates and installed new browsers. The environment went out of control, and it became impossible to continue to manage it manually. After analyzing the tasks, we have compiled the following list of requirements that must be met by our future virtualization platform:
')
Expressing the requirements of buzzwords, we were looking for an IaaS solution for organizing a private cloud. At present, there are quite a few platforms that meet these requirements. We also focused on the following OpenSource solutions:
Assessing these projects on the prospects, lack of vendor lock'ov and activity of the community, we decided in favor of OpenStack.
OpenStack is a set of services, each of which is responsible for some important part of its functionality. Individual services include authorization, block device management, hypervisor management, and a virtual machine creation scheduler, with virtually any component of OpenStack being a service with a RESTful API. It makes no sense to describe the setting of each service: it depends on the tasks assigned to the infrastructure. I will focus on the key components used by us.
- Hypervisor: we preferred KVM. The reasons were commonplace - it is included in the core. In the future, this will save us from problems with updating the kernel.
“As a backend of block devices and a repository of virtual images, we chose Ceph. At the time of the decision, the developers stated that it was not production ready, so we took it very seriously, but we didn’t identify any problems with performance / reliability, and we decided to leave it. In general, the use of Ceph at that time was a rather exotic configuration for OpenStack, but to raise a Swift cluster for us seemed like an empty task.
- We chose OpenVSwitch as a network virtualization backend, since at that time (the Grizzli release), OVS was the only solution that ran on top of the existing VLAN.
At the deployment stage, we encountered some difficulties: at the end of 2012, OpenStack was still not so smoothly deployed on CentOS, and in general, OpenStack is a rather complex engineering-intensive product, so we and the administrators spent a lot of effort to deploy and configure it.
If you are engaged in the implementation of such a decision, it is better if you have a dedicated person who can understand all its nuances and, if necessary, delve into the details of the implementation of certain services.
The interaction scheme of the component, we have this:

After deploying and performing load tests of all subsystems, we were faced with the question of how to manage the configuration of our guest systems. Configuration management tools have recently been heard, so there’s no point in describing each of them in detail, in my opinion.
However, the following systems were on the list of candidates:
One of the important selection criteria for us was the ability to work with Windows XP, since, according to our statistics, it firmly holds the second place among desktop systems on the Russian market. By this criterion, Puppet immediately disappeared - at that time, XP did not appear in the official documentation.
SaltStack, despite its prospects and my personal sympathy (the project was written in Python), turned out to be quite raw, and many things would have to be implemented independently (bootstrap new nodes, integration with cloud-init, web api, etc.) or wait until the project evolutionarily reaches them.
In the end, the choice fell on Chef: it best matched ours
requirements, as well as the dynamics of its development and the activity of the community significantly ahead of its competitor (Salt).
Our work with Chef is no different from the classical approach described on Habré many times: we use knife and the knife-openstack plugin to integrate with the OpenStack API, knife-windows for the bootstrap of Windows-node and knife-spork for notifications and organization of work with Chef (static analysis, working with versions, uploading kukbuk / roles / dateabags to the Chef server).
We should also talk about how we test and debug the workbooks. Without testing the kukbook, we do not push to the repository and do not upload the kukbook in Chef. For these purposes, we use vagrant www.vagrantup.com
- it allows you to automate the process of creating a virtual machine and applying to it the Kukbuk Chef. By the way, vagrant integrates not only with Chef; It is also possible to integrate it with other CMS salt / puppet / cfengine / ansible.
It so happens that in the general access there are no vagrant boxes necessary for us (it often concerns Windows - due to the peculiarities of the licensing policy), or the boxes need to be pre-assembled. In such cases, we use veewee. Veewee is a tool for preparing vagrant boxes, it automates the procedure for assembling vagrant box files for target operating systems. We actively use veewee for testing the preparation of the Windows box, as well as for testing unattended Windows installations.
So how does this bundle work? I will try to describe the final usage scenario to make it clearer. Push away from any “live” task. For example, for testing purposes, we need to roll out the Amigo browser to several target platforms - let it be Windows 7 / Windows XP / Windows Vista / Windows 8.
After a few minutes, we have at our disposal configured virtual machines on which we can perform further testing activities (both manual and automated).
The transition to this infrastructure allowed us to accumulate knowledge in the code. Now we don’t need to write detailed documentation on how to deploy our application projects and transfer this knowledge to the operations department. Everything is described by code (we try to follow the ideology Infrastructure as a Code). We are able to debug our deploy-procedures (Vagrant) and create new vagrant boxes using Veewee. The transition to the infrastructure documented by the code has allowed us to reduce the costs of updating, scaling and recovering from failures of our environment. And besides:
You can add to the list of undoubted advantages that this solution is based on OpenSource components (with the exception of Windows virtual machines, licenses for which we receive by MSDN subscription).
Future plans include making our Chef cookbooks and veewee templates for building Windows open (they are somewhat different from the standard ones). If this topic is of interest to the community, we also plan to write an article about the features of preparing Windows images for OpenStack (rackspace / hpcloud).
In order for Mail.Ru Search AutoTests to run quickly and in all the necessary environments, we needed to learn how to quickly deploy new virtual machines with a specific configuration.
A large number of virtual machines in our cloud is used by WebDriver browser farm, by scaling it, we speed up the execution of tests of the web-based Search interface.
In addition, we run virtualka on tools for collecting code quality metrics and coverage measurement, as well as Search testing tools developed by us.
Prehistory
It all started with a single server with the KVM hypervisor installed and libvirt management installed. At the same time, each virtualka was created manually by admins each time via Task in Jira. Such a process imposed some restrictions on the efficiency and controllability of the testing department infrastructure.
Over time, when the number of virtual machines with Windows increased, the reliability of the solution decreased: from time to time VM with guest Windows hung up, consumed the entire CPU on the host machine, or suddenly rolled up updates and installed new browsers. The environment went out of control, and it became impossible to continue to manage it manually. After analyzing the tasks, we have compiled the following list of requirements that must be met by our future virtualization platform:
')
- Availability of management APIs and libraries implementing it.
- Virtual machine status management
- Virtual Machine Profile Management (Memory / CPU / Disk)
- Managing quotas for different users (we really did not want to get a situation where one user could affect the performance of other virtual environments)
- Management of disk subsystems (backups / snapshots)
- Network management
- Horizontal scaling capabilities and providing the required level of fault tolerance
- Live community
- Development prospects
Decision making
Expressing the requirements of buzzwords, we were looking for an IaaS solution for organizing a private cloud. At present, there are quite a few platforms that meet these requirements. We also focused on the following OpenSource solutions:
- Proxmox VE www.proxmox.com/proxmox-ve
- Xen www.xenproject.org
- OpenStack www.openstack.org
- Eucalyptus www.eucalyptus.com
- Opennebula opennebula.org
Assessing these projects on the prospects, lack of vendor lock'ov and activity of the community, we decided in favor of OpenStack.
OpenStack is a set of services, each of which is responsible for some important part of its functionality. Individual services include authorization, block device management, hypervisor management, and a virtual machine creation scheduler, with virtually any component of OpenStack being a service with a RESTful API. It makes no sense to describe the setting of each service: it depends on the tasks assigned to the infrastructure. I will focus on the key components used by us.
- Hypervisor: we preferred KVM. The reasons were commonplace - it is included in the core. In the future, this will save us from problems with updating the kernel.
“As a backend of block devices and a repository of virtual images, we chose Ceph. At the time of the decision, the developers stated that it was not production ready, so we took it very seriously, but we didn’t identify any problems with performance / reliability, and we decided to leave it. In general, the use of Ceph at that time was a rather exotic configuration for OpenStack, but to raise a Swift cluster for us seemed like an empty task.
- We chose OpenVSwitch as a network virtualization backend, since at that time (the Grizzli release), OVS was the only solution that ran on top of the existing VLAN.
At the deployment stage, we encountered some difficulties: at the end of 2012, OpenStack was still not so smoothly deployed on CentOS, and in general, OpenStack is a rather complex engineering-intensive product, so we and the administrators spent a lot of effort to deploy and configure it.
If you are engaged in the implementation of such a decision, it is better if you have a dedicated person who can understand all its nuances and, if necessary, delve into the details of the implementation of certain services.
The interaction scheme of the component, we have this:
Configuration management
After deploying and performing load tests of all subsystems, we were faced with the question of how to manage the configuration of our guest systems. Configuration management tools have recently been heard, so there’s no point in describing each of them in detail, in my opinion.
However, the following systems were on the list of candidates:
- SaltStack saltstack.org
- Opscode Chef www.getchef.com
- Puppet puppetlabs.com
One of the important selection criteria for us was the ability to work with Windows XP, since, according to our statistics, it firmly holds the second place among desktop systems on the Russian market. By this criterion, Puppet immediately disappeared - at that time, XP did not appear in the official documentation.
SaltStack, despite its prospects and my personal sympathy (the project was written in Python), turned out to be quite raw, and many things would have to be implemented independently (bootstrap new nodes, integration with cloud-init, web api, etc.) or wait until the project evolutionarily reaches them.
In the end, the choice fell on Chef: it best matched ours
requirements, as well as the dynamics of its development and the activity of the community significantly ahead of its competitor (Salt).
Our work with Chef is no different from the classical approach described on Habré many times: we use knife and the knife-openstack plugin to integrate with the OpenStack API, knife-windows for the bootstrap of Windows-node and knife-spork for notifications and organization of work with Chef (static analysis, working with versions, uploading kukbuk / roles / dateabags to the Chef server).
Testing
We should also talk about how we test and debug the workbooks. Without testing the kukbook, we do not push to the repository and do not upload the kukbook in Chef. For these purposes, we use vagrant www.vagrantup.com
- it allows you to automate the process of creating a virtual machine and applying to it the Kukbuk Chef. By the way, vagrant integrates not only with Chef; It is also possible to integrate it with other CMS salt / puppet / cfengine / ansible.
It so happens that in the general access there are no vagrant boxes necessary for us (it often concerns Windows - due to the peculiarities of the licensing policy), or the boxes need to be pre-assembled. In such cases, we use veewee. Veewee is a tool for preparing vagrant boxes, it automates the procedure for assembling vagrant box files for target operating systems. We actively use veewee for testing the preparation of the Windows box, as well as for testing unattended Windows installations.
Usage scenarios
So how does this bundle work? I will try to describe the final usage scenario to make it clearer. Push away from any “live” task. For example, for testing purposes, we need to roll out the Amigo browser to several target platforms - let it be Windows 7 / Windows XP / Windows Vista / Windows 8.
- For a start, we prepare the vagrant boxes of these systems (if they are not already available).
- Then we create kukbuki (knife cookbook create ...) describing the installation of Amigo on each of these systems (in some cases the procedure will be unified, in some it will be necessary to add prerequisites and dependencies on operating systems).
- The next step will be to check whether the doll we created on each of the target operating systems (vagrant up) is correctly rolled out to simplify perception:
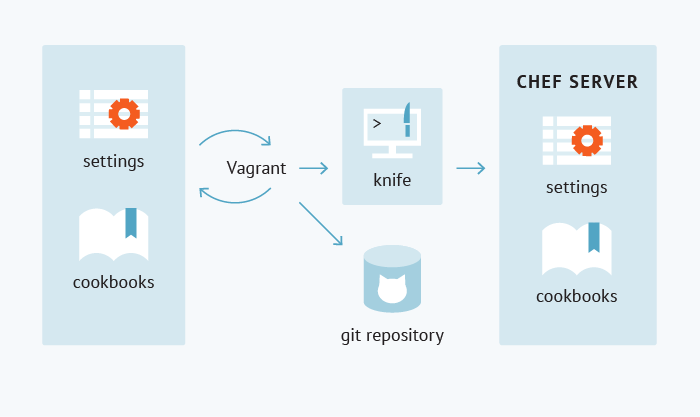
- After testing, we upload the kookbook and its dependencies to the Chef server (knife spork upload ...).
- Create, describe and load roles (knife role from file ...).
- And the last step is to create virtual machines with target OS, assign roles to them (knife openstack server create ...). another explanatory drawing:
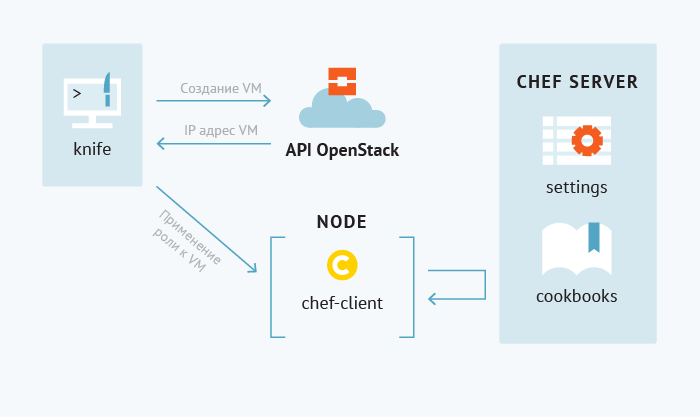
After a few minutes, we have at our disposal configured virtual machines on which we can perform further testing activities (both manual and automated).
What we got
The transition to this infrastructure allowed us to accumulate knowledge in the code. Now we don’t need to write detailed documentation on how to deploy our application projects and transfer this knowledge to the operations department. Everything is described by code (we try to follow the ideology Infrastructure as a Code). We are able to debug our deploy-procedures (Vagrant) and create new vagrant boxes using Veewee. The transition to the infrastructure documented by the code has allowed us to reduce the costs of updating, scaling and recovering from failures of our environment. And besides:
- speed testing of our desktop products
- Automate the layout of our custom reporting / test monitoring tools (we actively use continuous delivery practices)
- Accelerate the setting / display of infrastructure solutions required by the testing department (nexus / sonar, etc.)
- remove from the chain an idea-solution the manual labor of system administrators in creating and setting up environments
You can add to the list of undoubted advantages that this solution is based on OpenSource components (with the exception of Windows virtual machines, licenses for which we receive by MSDN subscription).
Future plans include making our Chef cookbooks and veewee templates for building Windows open (they are somewhat different from the standard ones). If this topic is of interest to the community, we also plan to write an article about the features of preparing Windows images for OpenStack (rackspace / hpcloud).
Source: https://habr.com/ru/post/215691/
All Articles