New version of ABBYY FineReader for Mac: without leaving the jungle of complex features
 A new FineReader for Mac has been released recently - and it's time to write a few words about it. I confess that I was the first person in the company who decided to switch completely to the Mac in his work back in 2006 already now. ABBYY has done mostly Windows-only products before, and only a little for other platforms. I then regularly went to the department of FineReader and screamed that we did not have a normal FineReader for Mac (there was only an outdated version for PowerPC), but then stopped nagging, and sat down to program. Since then, much water has flowed, but my effort was not wasted, and launched the process of creating updated versions of FineReader for Mac. That is why I breathe very unevenly to this product.
A new FineReader for Mac has been released recently - and it's time to write a few words about it. I confess that I was the first person in the company who decided to switch completely to the Mac in his work back in 2006 already now. ABBYY has done mostly Windows-only products before, and only a little for other platforms. I then regularly went to the department of FineReader and screamed that we did not have a normal FineReader for Mac (there was only an outdated version for PowerPC), but then stopped nagging, and sat down to program. Since then, much water has flowed, but my effort was not wasted, and launched the process of creating updated versions of FineReader for Mac. That is why I breathe very unevenly to this product.Fortunately, FineReader for Mac, which has just been released, has little to do with what I then programmed. He is stylish, fast and comfortable. It is much more functional than FineReader Express for Mac, which was until now. I will not make a detailed review of the product, because good programs do not benefit from breaking into pieces, as is customary in the genre of the traditional review. I will only write what, from my point of view, this product differs from its namesake for Windows.
It differs from the fact that it is simpler (and, for my taste, more elegant). FineReader for Windows is literally packed with features. In the aggregate, they are needed only by advanced users, whom we greatly appreciate and love. But among people who need to sometimes get the text of the document for editing, these advanced users make up only a small part. This is the fate of most mature products: they grow over the years, are filled with features that are no longer available, and which may not be used very often, but there are dedicated users who need them, and we have to maintain these features.
')
In the Mac version, we had the opportunity to look at the problem with a fresh look, and concentrate on the functionality that most users need, without going too far into the jungle of complex features. It turned out a light product with a minimum set of convenient and intuitively simple controls. He looks very Makovsky, and not much like his brother for the Windows platform.
The initial idea was as follows. In itself, the quality of OCR on modern documents is such that errors in recognizing the flow of the text itself occur very rarely, except if the original image is completely bad. However, with complex layout, in the case of all sorts of tricky tables, pictures with a complex contour, there are errors in the analysis of the document, which lead to difficult-to-correct defects at the output. Therefore, first of all, the user needs tools to improve the image itself, if there are problems with it, as well as correcting the results of analyzing the location of information on the page.
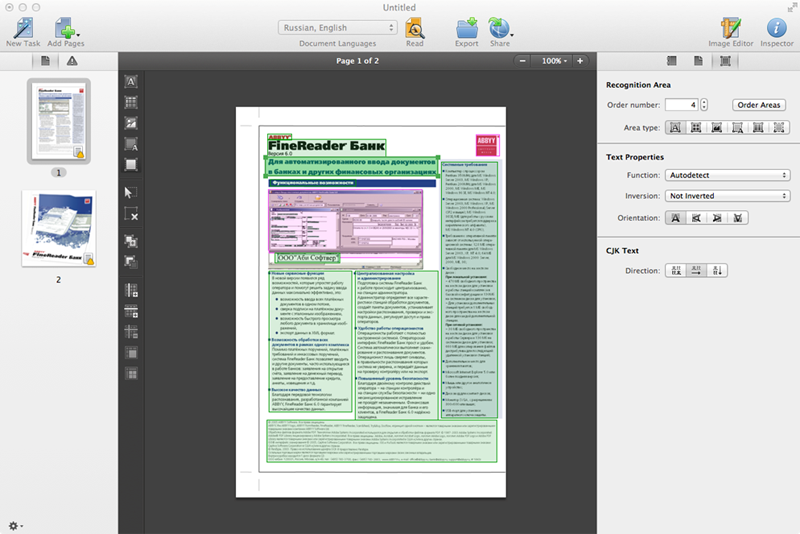
These two components are added first of all to FineReader. Well, there is a handy tool for working with a document: delete and add pages, rearrange pages, etc.
As a result, even if the system has not guessed how the text is located in your complex document, with little effort you can help it to get a quality result at the output.
However, I still lack one important function in a new product. And not only me, judging by the user reviews. There is not enough opportunity to work with the received text inside the product. True, in the question of how this function should be implemented, opinions are divided. There is a traditional implementation, as is done in the Windows version of FineReader, using the built-in editor. This approach has existed since time immemorial. I don’t like this idea very much, and I will try to give my reasons.
The fact is that the built-in editor, however perfect it may be, is not able to compete with the same Microsoft Word or LibreOffice in terms of completeness of text display. And this means that by making more or less complex edits in the text, you risk completely “breaking it down” when, when loaded into an external editor, it floats, becoming completely different from the original, and it may take considerable effort to restore the formatting. And why on earth, generally speaking, do you need to make such complex edits in FineReader itself? The only reason to edit the text inside the OCR product is that it is possible to quickly verify specific words with their images in the source text to make sure that there are no errors. Any complex formatting edits are best done where you will prepare the final document.
Therefore, from my point of view, no full-fledged editor is needed in FineReader for Mac. All that is needed is a handy speller, showing the user dubious and non-word words along with an image of the neighborhood of the word being checked in the original image. But this is my point of view. If it prevails, such a function may appear relatively quickly in FineReader for Mac.
I would like to hear your opinions in the comments.
Aram Pakhchanyan,
director of data entry products
Source: https://habr.com/ru/post/215439/
All Articles