Features of memory allocation in OpenCL
Introduction
Hello dear readers.
In this post I will try to consider the features of memory allocation for OpenCL objects.
OpenCL is a cross-platform standard for heterogeneous computing. It is no secret that programs are written on it when they require speed of execution. As a rule, such code needs to be fully optimized. Every GPGPU developer knows that memory operations are often the weakest link in the speed of the program. Since in nature there are a great many hardware platforms supporting OpenCL, the issue of organizing memory objects often becomes a headache. What works well on Nvidia Tesla, equipped with local memory and connected by a wide bus to the global one, refuses to show acceptable performance on SoCs that have a completely different architecture.
')
The peculiarities of memory allocation for systems with shared memory CPU and GPU will be discussed in this post. The use of image memory types will be set aside and we will focus on the most commonly used type of Buffer. As a standard, we will consider version 1.1 as the most common. At the beginning we will conduct a short theoretical course, and then we will consider several examples.
Theory
Memory is allocated by calling the clCreateBuffer API function. The syntax is as follows:
cl_mem clCreateBuffer ( cl_context context, cl_mem_flags flags, size_t size, void *host_ptr, cl_int *errcode_ret) We are primarily interested in flags that are responsible for how memory will be allocated. The following values are valid:
CL_MEM_READ_WRITE CL_MEM_WRITE_ONLY, CL_MEM_READ_ONLY The easiest option. Memory will be allocated on the side of the OpenCL Device in read-write / read-only / read only mode. CL_MEM_ALLOC_HOST_PTR The memory for the object will be allocated from the Host's memory — that is, from the RAM. This flag is of interest for systems with shared CPU and GPU memory. CL_MEM_USE_HOST_PTR The object will use the already allocated (and used by the program) Host's memory at the specified address. The standard allows for the possibility of allocating memory on the Device side as an intermediate buffer. This flag and CL_MEM_ALLOC_HOST_PTR are mutually exclusive. This flag is interesting in that if you add support for OpenCL to a ready-made application, and you want to use the existing memory to work with it on the Device side. CL_MEM_COPY_HOST_PTR This flag means that when creating an object, an analog memcpy will be produced from the specified address.Practice
Let us try in practice to find out which version of memory allocation is better suited for the traditional case of a discrete video card with its own memory “on board” and the one in which the GPU uses memory from RAM. The following computers will appear as test systems:
- System with discrete video chip: Intel Core i5 4200U, 4Gb DDR31600Mhz, Radeon 8670M 128bit GDDR3 1800Mhz
- System with integrated video chip: AMD A6700, 8Gb DDR31800Mhx, Radeon 7660D 128bit
The operating system in both cases is Windows7 SP1, the development environment is Visual Studio 2013 Express + AMD APP SDK 2.9.
As a test load, we will read / write and mapping / unmapping memory objects of various sizes - from 65 KB to 65 MB.
Without thinking twice, move on to the charts. In all cases, the abscissa axis shows the amount of memory in bytes, the ordinate axis shows the operation time in microseconds. The video card with discrete memory is marked in the title of the graphic as “discrete GPU”, the video card with shared memory with CPU is marked as “Integrated GPU”
Discrete graphics card

This graph shows the linear dependence of the data transfer time on the volume. The adapter uses its own memory, so the results are stable.
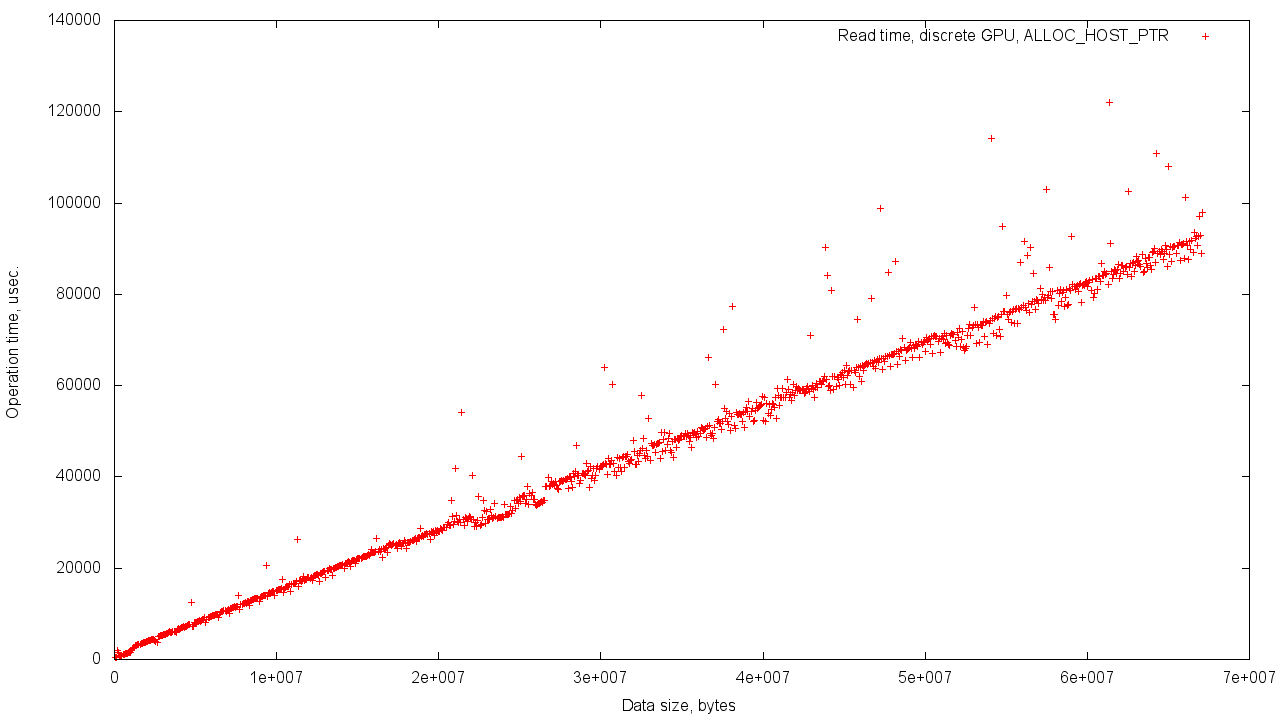
In this case, the memory for the object was allocated from the operational one, so we have a slightly larger scatter of values.
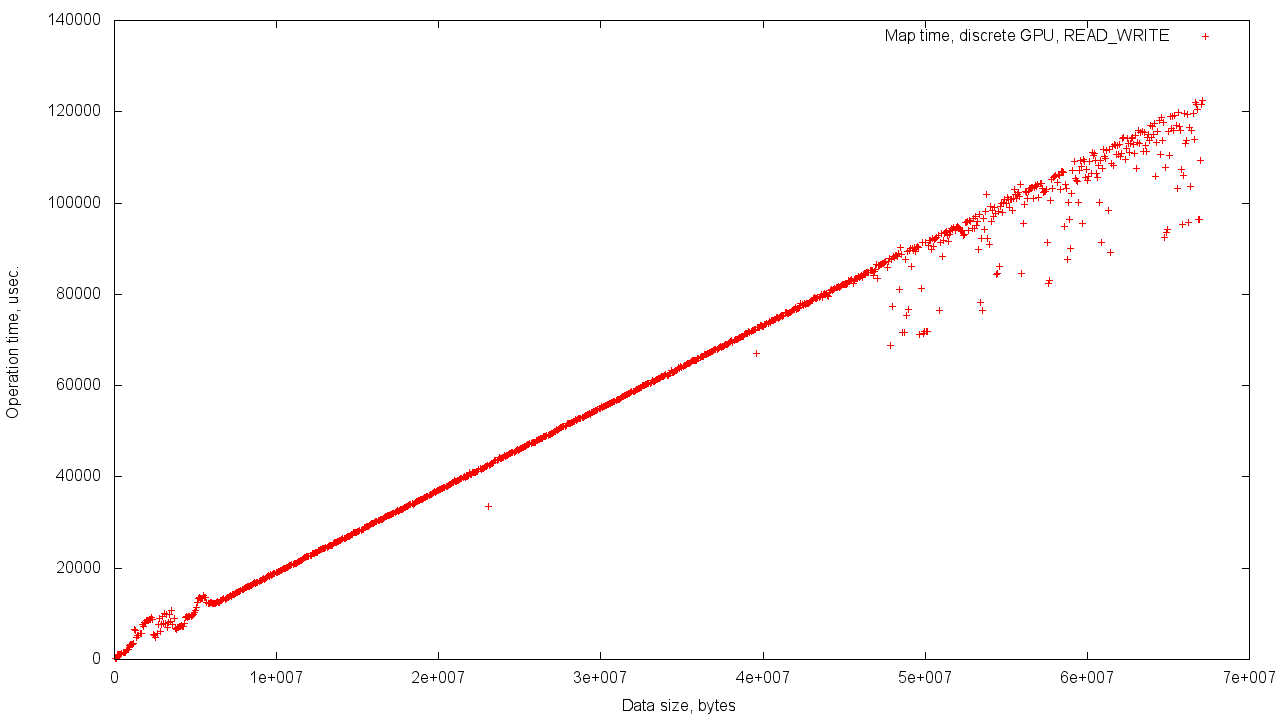

The graphs illustrate the mapping / unmapping of the buffer allocated from the GPU memory. Mapping is the procedure for mapping a section of memory from the Device’s address space to the Host space. Unmapping is the reverse process. Since for a GPU with its own memory, these address spaces are physically different, that reading / writing to temporary buffers takes place for the display.
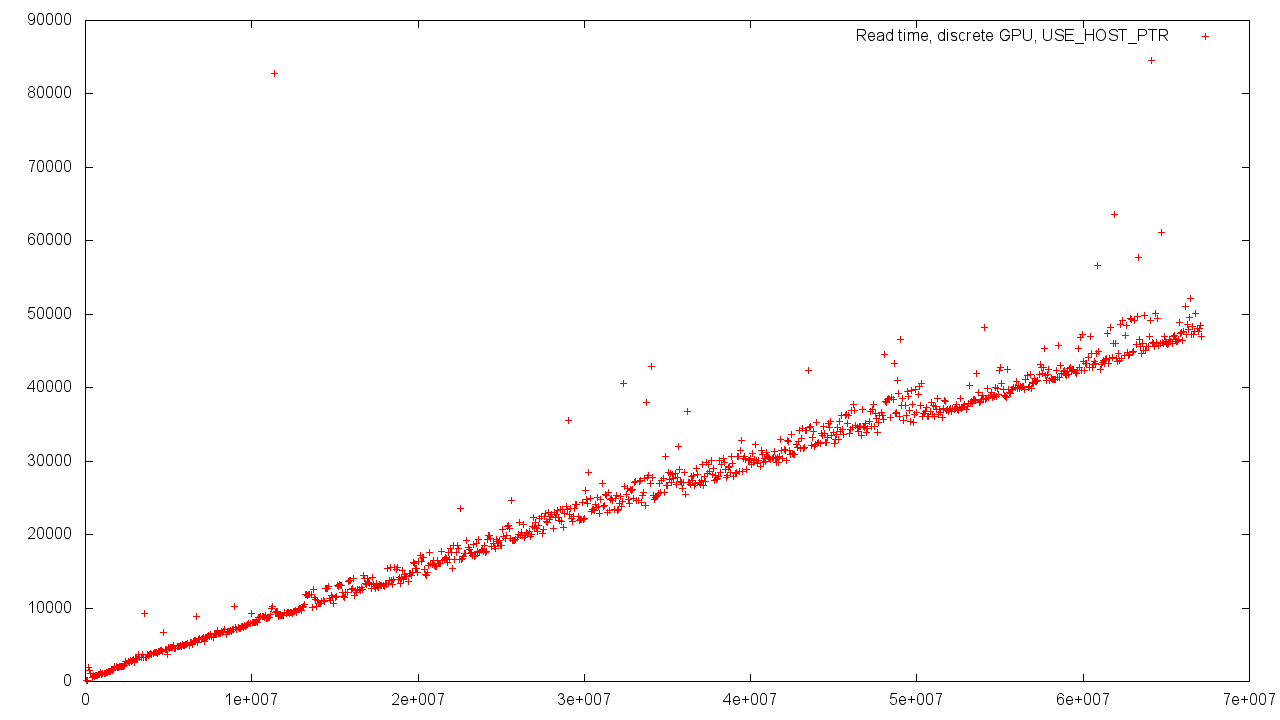

When using the existing memory allocated on the side of the Host'a, the variation in time is more significant. There may be many reasons for this - alignment of memory with different basic values, competitive load on the memory controller, and much more.
Integrated graphics card
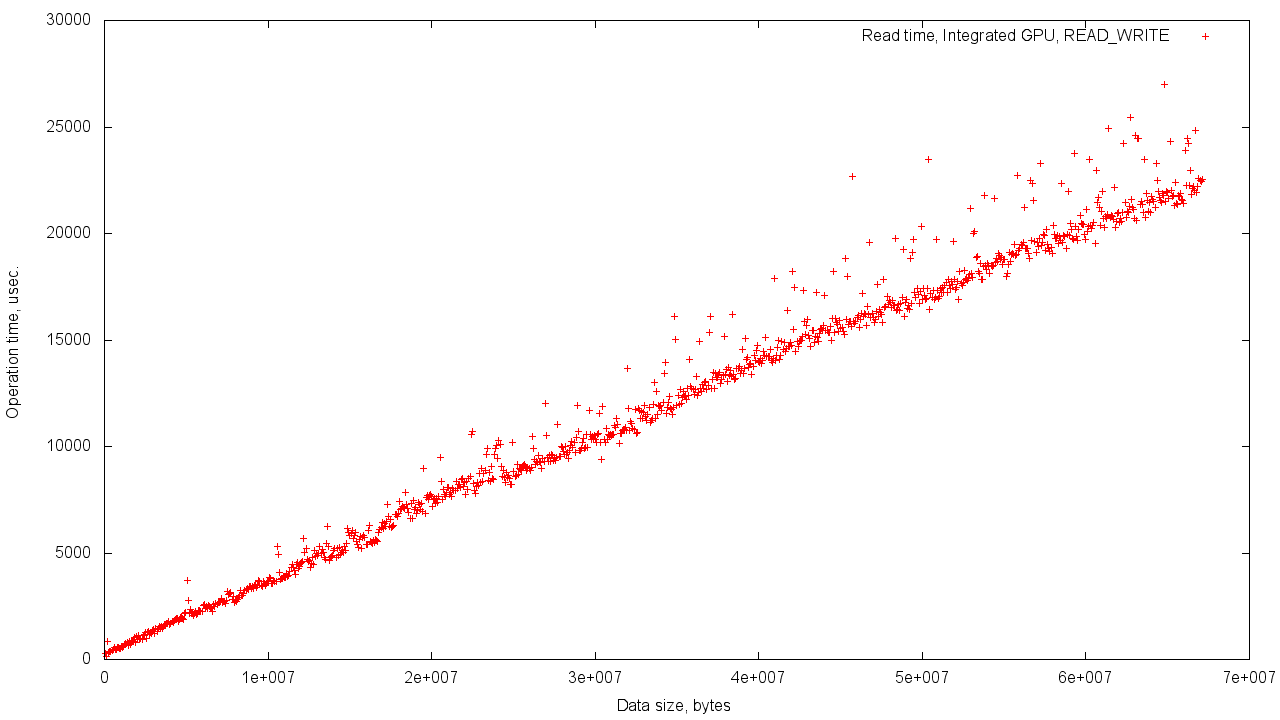
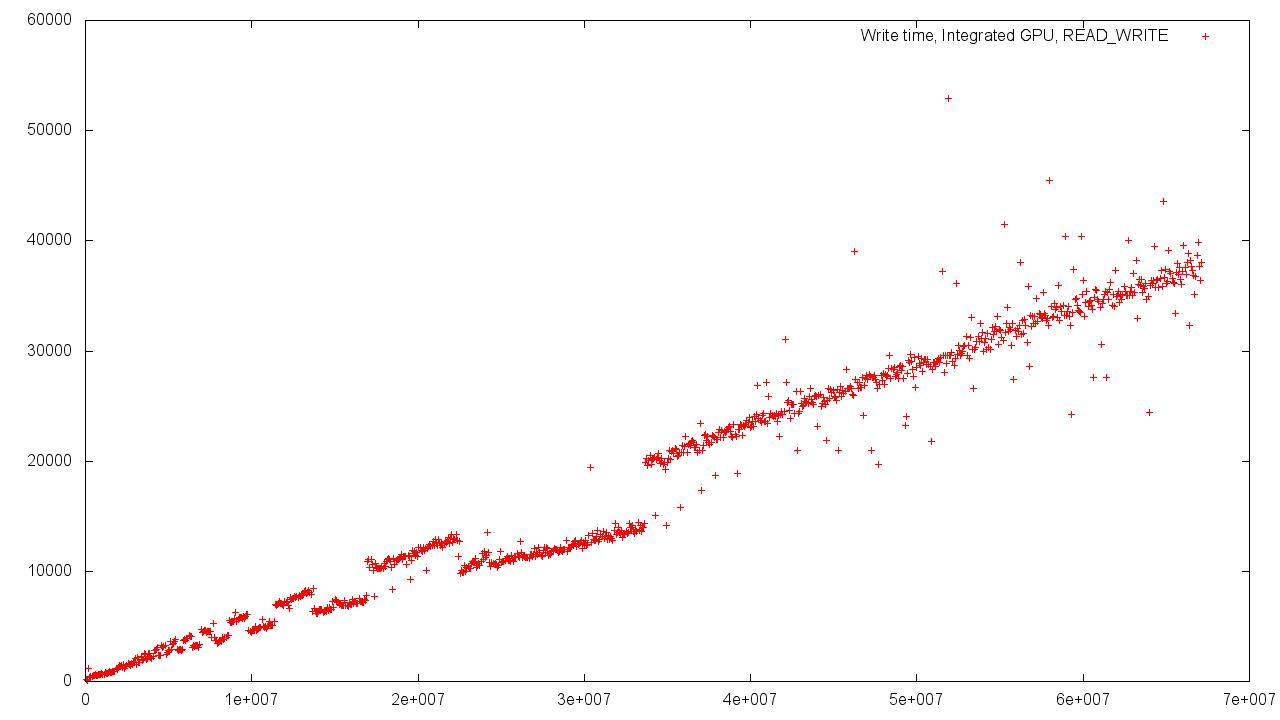
In the case of shared memory Host'a and Device'a dispersion of results is stronger. This is easily explained by the need to use shared memory and the increased load on the controller.


When allocating memory from RAM, the memory objects of the Device and Host are in the same physical address space and different virtual ones. Therefore, the time to convert the address is constant and does not depend on the size of the object.
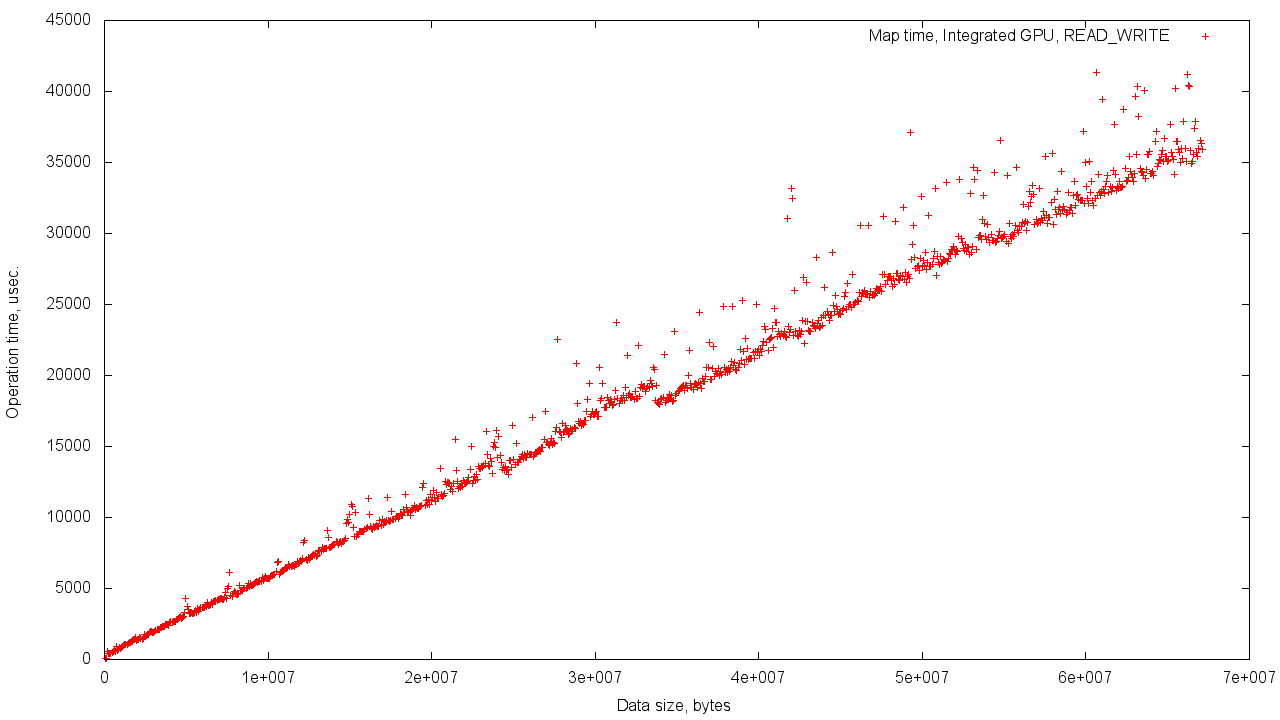
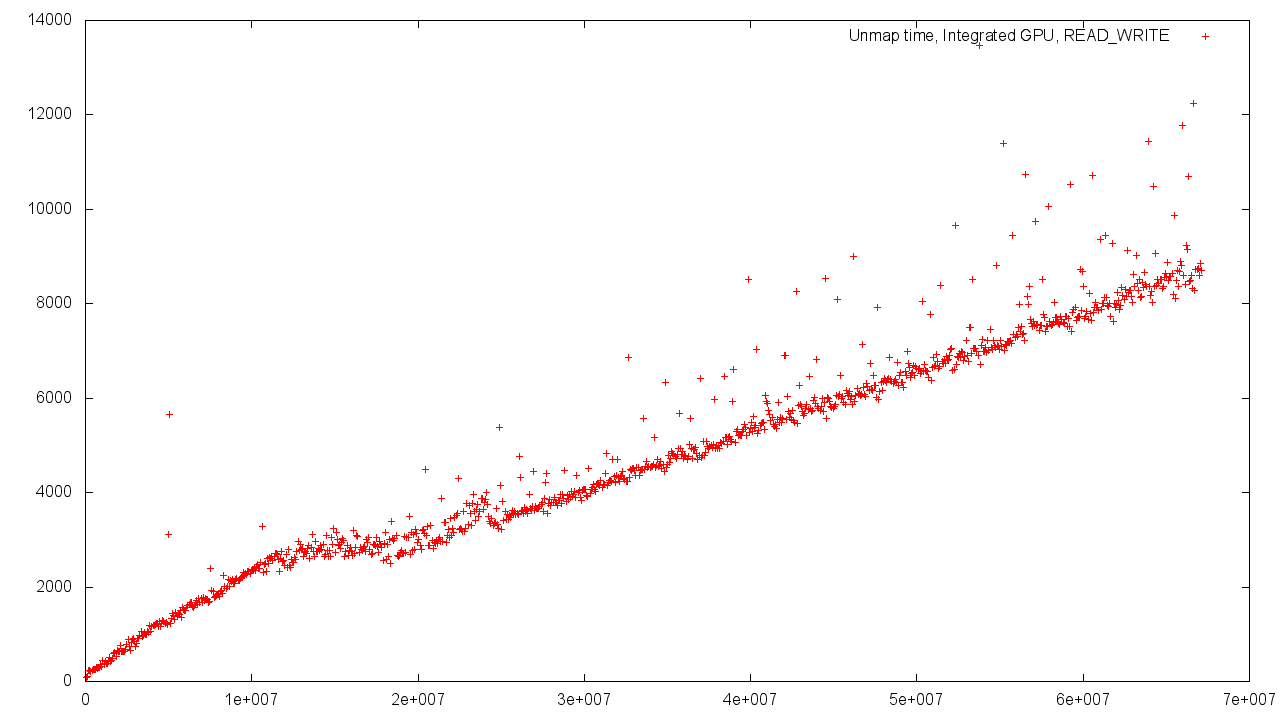
However, if you allocate memory for an object from the GPU memory, then the dependence of the execution time on the volume of the object will be similar to that observed when using a discrete video card adjusted for an increased scatter of results.
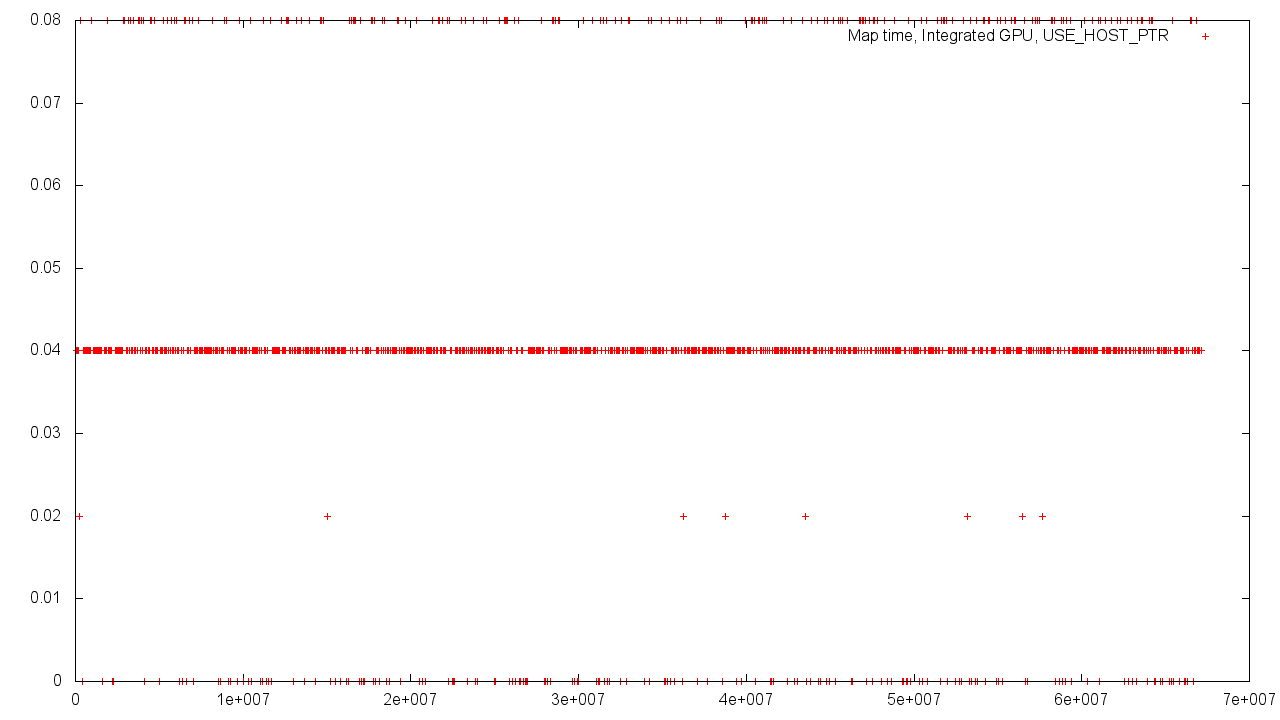
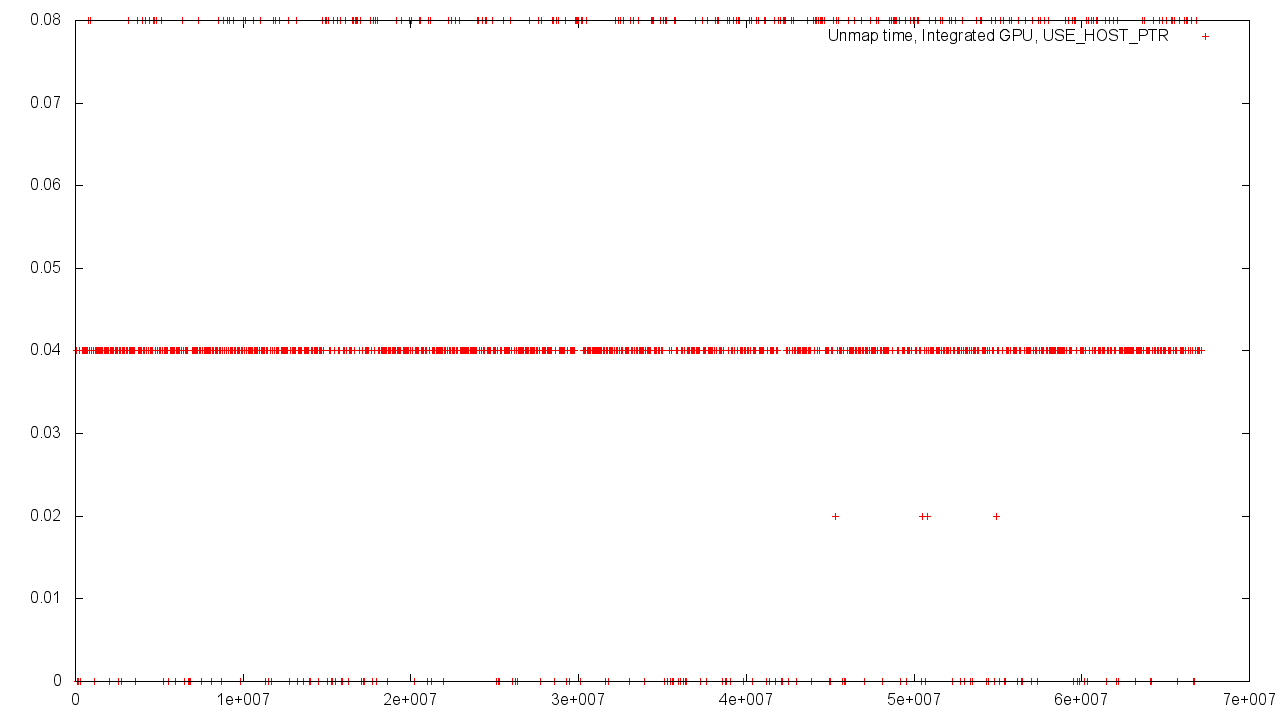
Again, if the memory allocated by the Host is used, then we get a near-zero operation time, independent of the size of the buffer.
findings
It is worth noting the following patterns identified during the experiment:
- Using a video card with discrete memory gives results with less variation. This is due to the use of separate memory. The use of shared memory, on the contrary, leads to a greater variation in performance.
- In both cases, using the USE_HOST_PTR flag results in unevenness in the results obtained.
Despite the fact that the local memory of a discrete video card is preferable for the operation of OpenCL cores in the intensive access mode, the use of shared memory makes it possible in some cases to perform mapping / unmapping for near zero time, independent of the buffer size.
The mapping technique can be used in both cases considered. On a system with shared memory, it gives the advantages described above, on a system with a discrete video card, it just works in the same linear time as the classic read / write scheme.
Source: https://habr.com/ru/post/215359/
All Articles