DDOS of any site using Google Spreadsheet
Google uses its "spider" FeedFetcher to cache any content in Google Spreadsheet, inserted through the formula = image ("link") .
For example, if you insert the formula
However, if you add a random parameter to the image URL, FeedFetcher will download it again each time. Let's say, for example, on the victim's website there is a PDF file of 10 MB in size. Inserting such a list into a table will cause the Google spider to download the same file 1000 times!
All this can lead to the exhaustion of the limit of traffic for some site owners. Anyone using only a browser with one open tab can launch a massive HTTP GET FLOOD attack on any web server.
')
The attacker doesn't even have to have a fast channel. Since the formula uses a link to a PDF file (that is, not a picture that could be displayed in the table), the attacker receives only N / A from the Google server in response. This allows you to quite simply multiply the attack [Analog DNS and NTP Amplification - approx. translator] that represents a serious threat.
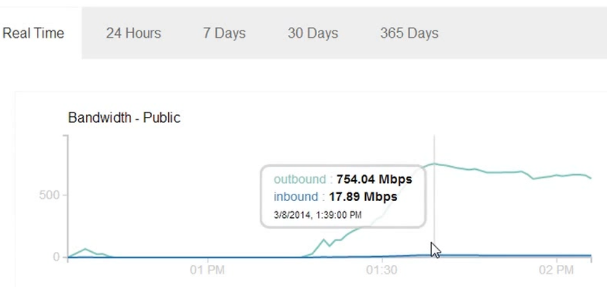
Using a single laptop with several open tabs, simply copying and pasting lists of links to files of 10 MB each, Google Spider can download this file at a speed of more than 700 Mbps. In my case, it lasted for 30-45 minutes, until I cut down the server. If I calculated everything correctly, it took about 240GB of traffic in 45 minutes.
I was surprised when I saw the amount of outgoing traffic. A little more, and I think outgoing traffic would have reached 1 Gb / s, and incoming 50-100 Mbit / s. I can only imagine what will happen if several attackers use this method. Google Spider uses more than one IP address, and although the User-Agent is always the same, it may be too late to edit the web server configuration if the attack takes the victim by surprise. Due to its ease of use, an attack can easily go on for hours.
When this bug was discovered, I started to google incidents using it, and found two:
• An article in which a blogger describes how he accidentally attacked himself and got a huge traffic bill. [ Translation to Habré - approx. translator] .
• Another article describes a similar attack using Google Spreadsheet, but first, the author suggests parsing links to all site files and launching an attack on this list using multiple accounts.
I find it somewhat strange that no one had guessed trying to add a random parameter to the request. Even if the site has only one file, adding a random parameter allows you to make thousands of requests to this site. In fact, it is a bit scary. Simply inserting multiple links into an open browser tab should not lead to this.
Yesterday I sent a description of this bug to Google and received a reply that this is not a vulnerability, and does not pass through the Bug Bounty program. Perhaps they knew about it beforehand, and really do not consider it a bug?
However, I hope they fix this problem. Just a little annoying that anyone can get a Google spider to deliver so many problems. A simple fix is to download files skipping additional parameters in the URL [In my opinion, this is a very bad fix. It may be worth limiting the bandwidth or limiting the number of requests and traffic per unit of time and not downloading files larger than a certain size - approx. translator] .
For example, if you insert the formula
=image("http://example.com/image.jpg") However, if you add a random parameter to the image URL, FeedFetcher will download it again each time. Let's say, for example, on the victim's website there is a PDF file of 10 MB in size. Inserting such a list into a table will cause the Google spider to download the same file 1000 times!
=image("http://targetname/file.pdf?r=1") =image("http://targetname/file.pdf?r=2") =image("http://targetname/file.pdf?r=3") =image("http://targetname/file.pdf?r=4") ... =image("http://targetname/file.pdf?r=1000") All this can lead to the exhaustion of the limit of traffic for some site owners. Anyone using only a browser with one open tab can launch a massive HTTP GET FLOOD attack on any web server.
')
The attacker doesn't even have to have a fast channel. Since the formula uses a link to a PDF file (that is, not a picture that could be displayed in the table), the attacker receives only N / A from the Google server in response. This allows you to quite simply multiply the attack [Analog DNS and NTP Amplification - approx. translator] that represents a serious threat.
Using a single laptop with several open tabs, simply copying and pasting lists of links to files of 10 MB each, Google Spider can download this file at a speed of more than 700 Mbps. In my case, it lasted for 30-45 minutes, until I cut down the server. If I calculated everything correctly, it took about 240GB of traffic in 45 minutes.
I was surprised when I saw the amount of outgoing traffic. A little more, and I think outgoing traffic would have reached 1 Gb / s, and incoming 50-100 Mbit / s. I can only imagine what will happen if several attackers use this method. Google Spider uses more than one IP address, and although the User-Agent is always the same, it may be too late to edit the web server configuration if the attack takes the victim by surprise. Due to its ease of use, an attack can easily go on for hours.
When this bug was discovered, I started to google incidents using it, and found two:
• An article in which a blogger describes how he accidentally attacked himself and got a huge traffic bill. [ Translation to Habré - approx. translator] .
• Another article describes a similar attack using Google Spreadsheet, but first, the author suggests parsing links to all site files and launching an attack on this list using multiple accounts.
I find it somewhat strange that no one had guessed trying to add a random parameter to the request. Even if the site has only one file, adding a random parameter allows you to make thousands of requests to this site. In fact, it is a bit scary. Simply inserting multiple links into an open browser tab should not lead to this.
Yesterday I sent a description of this bug to Google and received a reply that this is not a vulnerability, and does not pass through the Bug Bounty program. Perhaps they knew about it beforehand, and really do not consider it a bug?
However, I hope they fix this problem. Just a little annoying that anyone can get a Google spider to deliver so many problems. A simple fix is to download files skipping additional parameters in the URL [In my opinion, this is a very bad fix. It may be worth limiting the bandwidth or limiting the number of requests and traffic per unit of time and not downloading files larger than a certain size - approx. translator] .
Source: https://habr.com/ru/post/215233/
All Articles