One year in the life of the project. Answers@Mail.ru
In this article I will try to remember and describe all the difficulties and pitfalls that were encountered on the way of implementing the tasks related to the project. I will also tell you about the architecture of the project.
It all started when my contract came to an end (during the year I participated in the work on Mail.ru mail). “Adventures are waiting for me again,” flashed through my thoughts, “a new country, a new job.” I went to my superiors and in the course of the discussions I nevertheless received a portion of adventures in the form of an interesting task - to work on the project Answers.
')
As of October 15, 2012, the project was visited by an average of 3.5 million unique visitors per day.
The calculation was carried out on a unique "Cooks" (Cookie), which are issued to each visitor. If cookies are disabled in the visitor's browser, the visitor is not counted.The business card of the project could be called a screen, which, I am sure, is very well known to everyone.

The set of technologies used was as follows:
- CentOS 5 i386
- mod_perl under Apache
- Nginx
- SQL - database
- code layout to battle with rsync
Architecture:

| name | purpose | cpu | ram, gb | hdd | note |
| primus | front | 2xE5504 | eight | 2 x sata | entry point balancer |
| alpha | bek | 2xXeon old | 2 | 2 x scsi | on it we let all the crown scripts |
| argon | bek | 2xE5504 | eight | 2 x sata | |
| butan | bek | 2x E5506 | four | 2 x sata | |
| luna | bek | 2xE5405 | eight | 2 x sata | here wap and m version was spinning |
| oktan | bek | 2xE5405 | eight | 2 x sata | |
| metan | bek | 2xE5506 | four | 2 x sata | |
| propan | bek | 2xE5405 | four | 2 x sata | |
| radon | bek | 2xE5504 | eight | 2 x sata | |
| neon | bek | 2xE5-2620 | sixteen | 2 x sata | new |
| nitrogen | bek | 2xE5-2620 | sixteen | 2 x sata | new |
| plasma | bek | 2xE5-2620 | sixteen | 2 x sata | new |
| titan | base | 2 x E5620 | 96 | 4sata + 20sas | master |
| buran | base | 2 x E5620 | 64 | 2 sata + 4 ssd | main replica |
| maximus | base | 2 x 5110 | 32 | 2 sata + 4 scsi | replica for admin |
| minimus | base | 2 x 5110 | sixteen | 2 sata + 4 scsi | replica for admin |
| coloss | base | 2 x 5130 | eight | 6 scsi | comment base |
- project instability
- there are few specialists in the operational department for this SQL database, when the base drops, the only specialist who can understand what and why is not always available
- the eternal problem of the backlog of replicas, there is no one to solve it
- development of new functionality is difficult, since 90% of the logic inside the database
Task from management
To ensure the stable operation of the service and the possibility of its further development, in particular, to launch the mobile version.Migrating to Mysql and carrying out the logic of processes in the cloud will solve most of our problems.
The first thing raised monitoring. He wrote about him in the article (by the way,
rewrote it on AnyEvent, performance increased from 50 to 240 thousand lines per second).
He opened his eyes to the following things:
- Fall every day!
- A huge background of errors 504, about 50 thousand per day.
What are the reasons for 504?
- Slow HTML parser, it does its job when displaying the question page, that is, on the fly.
- Bots that download content.
- Yandex and Google index.
I received a letter from Yandex:
For otvet.mail.ru we began to increase the load, but to produce more than 200 requests per minute is notAnother problem has surfaced: on the balancer, we have a limit of 1 request per second from one IP, if we increase it, we cannot cope with the load.
it turns out, since we are starting to receive HTTP 503 regardless of the time of day. Is it possible to
eliminate it on your side?
Since search traffic is the most important thing for the Answers project, you need to act quickly. Everyone is nervous, the situation is heating up =).
From the simplest, easiest and cheapest - they bought 3 backends: neon, plasma and nitrogen. Added RAM to the primus balancer), included in nginx caching html for all unauthorized users, which are about 40%. Restriction on the balancer increased to 15 requests per second.
Every day they stopped falling, Yandex no longer complained about us. Critical problems solved, now you can think about the problem.
Looking ahead, I will say that in the new API, problems with slow HTML have been resolved. We used samny samopisny (Perl XS) parser and parsili only when saved to the database. For mail, this solution is not suitable, because if someone finds XSS, then it would take a lot of time (5 petabytes of data) to re-parse all the letters, so it’s easier and faster to add protection and parsing on the fly to the parser.
Migration and mobile version
Migration must meet two conditions: preserving the integrity of data and the performance of the project 24/7. Therefore, turn off the project and transfer data - will not work.
We will create an API, based on which everything will work, both the mobile version and the future “big” one. The API will only read from muscle, and write in both databases: old and new.
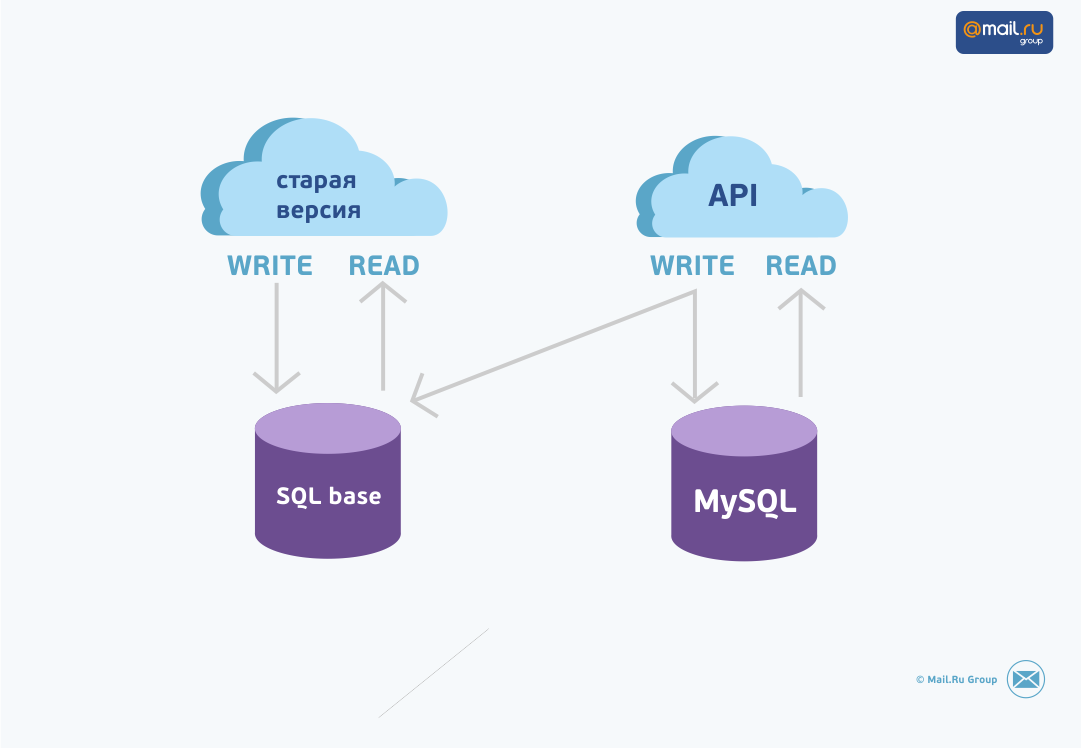
In order for MySQL to reach the changes from the old database, we will create a queue in which we will write which entities need to be synchronized (take from the old one and add or replace them in the new one).

To do this, the entire database must be divided into entities. For example, a task to resynchronize a response, a question, a user, all user responses, etc.
It should also be noted that the processors of this queue will work in parallel, since the flow of synchronization tasks is huge. We finally managed to handle 12 forks.
This is all necessary so that at any time you can add tasks to the queue and completely re-synchronize the necessary entities.
So rushed. On January 10, Alex Q , Perlovik came out. The queue is realized in the muscle. We bought two servers for muskul (called “birch” and “pine”) and two fronts (“baron” and “bourbon”). Muscle master and replica. They taught the old version to write tasks in the queue for resynchronization. It was a very routine and painfully long process. It was necessary to find each place in the pearl that writes in the old database, and back it up with the corresponding task for resynchronization.
At this point, the main thing to remember about the following things:
- Cron-jobs inside the database. Here we had to implement an analogue in the new version, because they did not want to interfere with the package code inside the database.
- Ordinary cron scripts. For them, we wrote similar in the new version.
- Well, the most insidious, it is - triggers. In our case, it turned out that the combat version of the database was different from the dev version. Therefore, carefully and meticulously check this.
Each of the above errors cost 14 days. Why so much? Learn more about it.
So, the old version can write to the queue, check the load. We roll out the old version, first on 2 Becks, then on 4 more, we look at the muskul, everything is OK, rolled on all the Beks, holds the load. Go to the next step.
They wrote a queue handler that knows how to forge and monitor children: if they fall, then it produces new ones. It takes a portion of the tasks and resynchronizes them, turning them into the necessary structure. In the future, we noticed that from two strategies — to launch 12 forks, each of which rakes all types of tasks — slower than launching 4 forks that perform tasks A, 4 forks that perform task B, etc.
This is explained by the fact that the queue handler remembers the entities that it has resynchronized during the current pass, and skips them if it encounters again, and if the types of entities are limited, the probability to get into the already processed task is much higher.
As a result, they taught the old version to write to the queue, the queue handlers are ready. In the battle launched the old version. The queue is accumulating, but so far not raked.
Now we need to transfer the already accumulated data from one database to another. Their order of 500 gigabytes. How to do it? Thank you Alex Q =)
Task:
Migrating large tables (up to 1500 million records) from the old SQL database to MySQL. In this case, the structure may (slightly) change, for example, in the old SQL database, the boolean fields were CHAR (1) (hidden may have values '' or 'H'), and in MySQL they would become TINYINT (hidden may be 0 or 1).Simultaneously with the transfer of data, data can be added and changed in the old database. The problem is resolved by creating a queue in which information is written about which data in the old database has changed or been added. While the table is migrating, tasks for “desynchronization” accumulate in the queue; the queue is then parsed by a separate script.
Migration:
- Import into MySQL via LOAD DATA INFILE in batches of 1000 (by default, redefined by startup keys) strings, because it is much faster than through INSERT.
- As a data transfer file, use the FIFO pipe, because then all data is run through the memory without writing to disk. It should be significantly faster than through files.
- The script reads N lines from the old SQL database (10,000, for example).
- The script forts the child process. In this process, the FIFO is opened for reading, and from it in MySQL it makes LOAD DATA INFILE.
- the parent writes K lines (1000, for example) to fifo. After each pack, closes the filehandle of the pipe, waits for the output of the child process and repeats from point 2 until the data taken in point 1 is finished.
February 26, 2013 - the first commit. By March 6, 2013 the working version is ready. They made a function that accepts the description of the incoming table (the old SQL database) and the output table (MySQL) old_to_MySQL (), and then everything is done through it. To avoid starting from scratch in case of a sudden facup, store the id of the last migrated row for each table in the MySQL table old_migrate.
We use LOAD INFILE REPLACE, not LOAD INFILE IGNORE, so that when recovering from a facac, you do not lose data changes in the old SQL database.
On March 15, the problem with default-values was temporarily solved: if from the old SQL-base comes NULL, and in MySQL the column is NOT NULL DEFAULT 0, then when we try to insert NULL we fall. The description of the scheme now has a set of key columns that are required to be; we insert DEFAULT into all the others if NULL arrives.
March 20, the war began against SIGPIPE.
Stages of war:
- Added $ SIG {PIPE}, which tries to repeat the call to old_to_MySQL () with old parameters from a saved position. For a long time, everything worked.
- November 13-14 SIGPIPE strikes back. I fixed the order of work with the pipe: first open the fifo for reading, then for writing. During the fight against sigpipe, croak / carp was added as a replacement for die / warn, and stumbled upon bug 72467 in Carp (attempt to copy freed scalar), and changed everything back.
- Did not help. Sleep did not help even after a second after opening the pipe for reading. Climbed to temporary files. It became noticeably faster due to unscrewing all the sleep, which served as crutches in the fight against sigpipe. It became good.
The war with sigpipe lasted two days, November 13 and 14. It was a very busy two days.
In total, it took us 14 days to transfer these 500 gigabytes.
While there was a transfer, the alpha version of the new API (Perl, fast_cgi) was ready.
Transferred the data, launched a test mobile version to corporate users. We look, we test. Accidentally in the logs of the old version, they noticed an error that on one of the beeches the pearl swears at the absence of the DBD module. This means that tasks do not leave the queue from this front, and the bases are not consistent. Oh, shit. I had to re-transfer everything. 14 days have passed =).
Now, after transferring data, you can begin to rake the queue, and it has accumulated a huge, about 300 million jobs.
Run handlers too slow. Looking for the cause of the brakes, it turned out that we need an index on the plate in which we have a queue. I did not want to wait again for 14 days. Created one more such label, but already with an index. Rolled out the old version, so she wrote in a new tablet with an index. It was InnoDB. Added an index. Scatter and kill the tablet. Renamed everything back.
It seems to work. Go ahead.
The new API should be able to write in both databases. We write asynchronously, so as not to wait extra time. To do this, in the tables of the new database, we make a margin by id using the initial position of the auto increment. For example, in the old database, the maximum id of the question is 1000, then in the analogous table of the new base we set the initial position of autoincrement 2000.
We add a new question through the API, it has an ID 2001, it adds it to the old database, there it has an ID 1001, we update in the new database with an ID 2001 turn into an record with ID 1001, so the ID for the entities will match in our databases .
Then we learned that after restarting the muscle or alter of the table, the auto-increment is reset to the maximum value of the primary key. Therefore, to avoid this, we added an entity base with a large ID equal to the starting number of auto-increment in MySQL.All further tasks were solved by adding to the queue of tasks for resynchronization of the necessary entities.
I remembered one more thing: somehow, from the operations department, news reached us that one of the data centers might have to be redeemed, and considering that the mobile version is already launched into battle and the fact that the servers with the old database are in this data center, and the new MySQL databases are different in the other. But, fortunately, the predictions did not come true.
Imagine that it happened.
We extinguished the datacenter with the old databases - then quickly curled the front in another datacenter (we did it right away, as we learned about this news), switch the mobile version to read-only mode and redirect all to the mobile version.
We extinguished the datacenter with the new databases - disable recording to the queue for synchronization. After the data center is working, we throw into the queue all the entities created after the start of the problems, and quietly resynchronize.
In March, launched a mobile version of the battle. There came about 500 thousand unique per day. We hold the load, everything works well.
The architecture of the project took the following form:

| name | purpose | cpu | ram, gb | hdd | note |
| baron | front | 2xE5-2620 | 32 | 2 x sata | httpd + mod_fcgid, large power margin |
| burbon | front | 2xE5-2620 | 32 | 2 x sata | httpd + mod_fcgid, large power margin |
| bereza | base | 2xE5-2609 | 96 | 2 x sata + 10 x ssd | mysql master |
| sosna | base | 2xE5-2609 | 96 | 2 x sata + 10 x ssd | mysql replica |
| pihta | base | 2xE5-2609 | 96 | 2 x sata + 10 x ssd | mysql replica |
| vagon | memkes | 2xE5-2620 | 64 | 2 x sata | two memcached instances |
Made, rolled it to the region of Moscow. We saw that with a load of 800 requests per second Apache is being torn down. At first, suspicions fell on mod_fcgid, but it turned out that the culprit was mod_rpaf. Thank you Mons , he skillfully removed the Apache's crust.
Abandoned mod_rpaf, threw an ip through the X-Real-IP header with nginx.
Rolled all over Russia, we hold the load. Made a new "big" version, started all redirect. November 19 closed the old version.
The limit on the primus balancer was removed to hell (15 requests per second from one IP). Load keep the flight normal. Approximately 950 requests per second from the API.
Attendance is on average 6.5 million per day.
On all servers we use CentOS 64bit, rollout into battle occurs through RPM packages. At the moment, the pearl is still spinning under apache2 (mod_fcgid). After yum rolled the bag, we restart the backups in turn.
At the front we use this kind of thing:
proxy_next_upstream timeout error http_502 http_504;That is, if the user comes 502 or 504, then he will be let out to another back, thus minimizing the discomfort due to the restart of the Apache.
Charts for the load can be found here .
I hope that this article will help you not to step on the rake we walked through! Remember, it is better to learn from the mistakes of others than from your own! :)
Source: https://habr.com/ru/post/214919/
All Articles