About customization of information systems

The main activity of our company is the development of corporate information systems. In addition to custom systems, we make two replicable products. Of course, we try to ensure that our products are as comfortable and functional as possible. However, in real life, each business has its own characteristics and is not always ready to put up with the standard features of the system. There is a task of finalizing the solution for a specific client and his further support. What are the approaches to the organization of the scalable product architecture? What problems may arise during development? What did we do? All of this below.
Possible approaches
To begin with, let us clarify that we call a “project-extension” or simply “extension” a product with modifications made for a specific customer. Now consider some of the possible approaches to product expansion:
Separate brunch in the repository for each expansion project
Perhaps this thought is the first one that comes to mind, because branching off from the main product and making changes to the new brunch is the fastest way to achieve the desired result. The only question is the price that will have to be paid for this speed.
After the development and implementation of an information system, the longest and often the most painful phase of the life cycle begins - support. In the case of an expansion project, this phase can become doubly unpleasant, because the customer will have to supply not only new features, which are implemented specifically for him, but also new versions of the product on which the extension is based. In order for the project to have changes from the new version of the product, one way is seen - merge changes from the main branch to the expansion brunch. But imagine how hard it will be, and how many potential errors can occur if the same code segment has changed a lot in both branches.
')
You can, of course, immediately think about future transfers to the new version of the product and organize the code in such a way that all specific changes will be located as far as possible from the code of the main product. In an ideal world, this would have worked, but you and I live in a harsh reality, where the deadline for completing a task can often be announced as “yesterday”, and the project is not a compact team of class professionals, but a battalion of yesterday’s students. In such situations, people rarely think about architecture and follow the path of least resistance - I found a place to be corrected, deleted the old, wrote a new one. This, by the way, leads to another big problem - the logic of expansion is mixed with the logic of the product.
Bottom line: this approach is the most flexible, as it allows you to change absolutely any part of the product, but only the first couple of updates will have to rejoice at flexibility. Subsequently, the enormous difficulties will be delivered by the support of the extension and its translation to new versions of the product. Moreover, the longer the information system lives, the more time-consuming support will become.
After the development and implementation of an information system, the longest and often the most painful phase of the life cycle begins - support. In the case of an expansion project, this phase can become doubly unpleasant, because the customer will have to supply not only new features, which are implemented specifically for him, but also new versions of the product on which the extension is based. In order for the project to have changes from the new version of the product, one way is seen - merge changes from the main branch to the expansion brunch. But imagine how hard it will be, and how many potential errors can occur if the same code segment has changed a lot in both branches.
')
You can, of course, immediately think about future transfers to the new version of the product and organize the code in such a way that all specific changes will be located as far as possible from the code of the main product. In an ideal world, this would have worked, but you and I live in a harsh reality, where the deadline for completing a task can often be announced as “yesterday”, and the project is not a compact team of class professionals, but a battalion of yesterday’s students. In such situations, people rarely think about architecture and follow the path of least resistance - I found a place to be corrected, deleted the old, wrote a new one. This, by the way, leads to another big problem - the logic of expansion is mixed with the logic of the product.
Bottom line: this approach is the most flexible, as it allows you to change absolutely any part of the product, but only the first couple of updates will have to rejoice at flexibility. Subsequently, the enormous difficulties will be delivered by the support of the extension and its translation to new versions of the product. Moreover, the longer the information system lives, the more time-consuming support will become.
Using dynamic attributes (Entity-Attribute-Value model)
The Entity-Attribute-Value (or Open Schema) model can be used with the standard relational model to dynamically define and store the values of new entity attributes. When using the EAV model, attribute values are usually written in one table of three columns. As you can guess, their names are Entity, Attribute and Value:
A mandatory component of the schema is also a table that stores the description of the metadata for the attributes:
To use this model in a product, you need to do 2 things:
The most important advantage of the approach is the absence of the need to create an expansion project. The basic product is delivered to the customer and at the stage of setting up or even operating, any number of dynamic attributes in the entities are established.
Further on the disadvantages. First, it is the limited application. The EAV model will only add attributes to the entity and display them in a predetermined location on the screen. No more. About changing the functionality, tricky UI-components are out of the question.
Secondly, the EAV model creates a large additional load on the database server. To load a single instance of an entity without links, you need to read instead of one or several rows of a table. To load a list of instances, for example, into a table on a UI, you generally need N + 1 queries, or joins by the number of columns of the table. Considering that the database in corporate systems is often the slowest and most poorly scalable element, such additional load can simply kill the system.
Third, again, because of the structure of the database, it will be quite difficult to sample data for reports — instead of writing ordinary SQL, relational data will require much more complex queries.
- Entity - stores the link to the object, the field of which we describe. This is usually an entity identifier;
- Attribute - link to attribute definition (about it below);
- Value - the actual value of the attribute.
A mandatory component of the schema is also a table that stores the description of the metadata for the attributes:
- attribute type;
- restrictions (field length, regular expression to which the value must correspond, etc.);
- component to display in the UI;
- The order of the component in the UI
To use this model in a product, you need to do 2 things:
- Implement the metadata task mechanism, with which we can, for example, specify that a new attribute “Date of termination” is added to entities of the “Contract” type, the field type is “Date”, the component to be displayed is DateField.
- Implement mechanisms for displaying and entering dynamic attribute values on the required product screens. The mechanism should find a possible set of attributes for a given entity in a table with a description of metadata, display components for editing them, and then search for and display their values in the data table, saving them when the screen is closed.
The most important advantage of the approach is the absence of the need to create an expansion project. The basic product is delivered to the customer and at the stage of setting up or even operating, any number of dynamic attributes in the entities are established.
Further on the disadvantages. First, it is the limited application. The EAV model will only add attributes to the entity and display them in a predetermined location on the screen. No more. About changing the functionality, tricky UI-components are out of the question.
Secondly, the EAV model creates a large additional load on the database server. To load a single instance of an entity without links, you need to read instead of one or several rows of a table. To load a list of instances, for example, into a table on a UI, you generally need N + 1 queries, or joins by the number of columns of the table. Considering that the database in corporate systems is often the slowest and most poorly scalable element, such additional load can simply kill the system.
Third, again, because of the structure of the database, it will be quite difficult to sample data for reports — instead of writing ordinary SQL, relational data will require much more complex queries.
Plug-in architecture
This architecture allows you to store additional functionality in separate artifacts - plug-ins. If your customer wants some new specifics, then you give him a base product, write a plug-in, plug it in and be done. To use plug-ins in the product must be declared extension points. What it is? If it is simple, then these are certain places in the code. In these places, loaded plug-ins are sorted out, it is analyzed whether there is logic in the plug-ins intended for this extension point, and if such logic is found, it is executed. Examples of extension points: menu item, command command, button on toolbar, new screen.
Such a frequently used option of extending the functionality, such as the description of logic and event handlers in external scripts, can also be attributed to variations of plug-ins, since Scripts are called and executed by certain points of the program.
Plug-in architecture allows you to store all the new functionality separately from the product, which is an important advantage of it. The complete physical separation of the product and the plug-ins makes the process of updating the product version or the plug-in very simple - just replace the updated component.
But here, unfortunately, there are drawbacks. For some products, they will be insignificant, for some may cause the impossibility of using the plug-in architecture. The fact is that the plugin can expand the system only in the place where the extension point is defined. Undoubtedly, there is a class of products, where in principle there are few such places and all of them are predetermined, but there is also a huge group for which it is almost impossible to predict what will need to be expanded tomorrow. An analysis of potential expandable sites can be a very resource-intensive exercise, and as a result, it still turns out to be not entirely accurate. In addition, extension points are a complication of the main code, which is always fraught with errors and maintenance complexity. Approach to the definition of expansion points in the main product must be very thoughtful.
Such a frequently used option of extending the functionality, such as the description of logic and event handlers in external scripts, can also be attributed to variations of plug-ins, since Scripts are called and executed by certain points of the program.
Plug-in architecture allows you to store all the new functionality separately from the product, which is an important advantage of it. The complete physical separation of the product and the plug-ins makes the process of updating the product version or the plug-in very simple - just replace the updated component.
But here, unfortunately, there are drawbacks. For some products, they will be insignificant, for some may cause the impossibility of using the plug-in architecture. The fact is that the plugin can expand the system only in the place where the extension point is defined. Undoubtedly, there is a class of products, where in principle there are few such places and all of them are predetermined, but there is also a huge group for which it is almost impossible to predict what will need to be expanded tomorrow. An analysis of potential expandable sites can be a very resource-intensive exercise, and as a result, it still turns out to be not entirely accurate. In addition, extension points are a complication of the main code, which is always fraught with errors and maintenance complexity. Approach to the definition of expansion points in the main product must be very thoughtful.
How we do it
We have launched two replicable products on the market: ECM (or in more usual terms, electronic document management system, EDMS) THESIS and the system for automating the Sherlock taxi business. From the very beginning it was obvious: in order to provide a specific client with the most convenient system, product refinements will be required, and therefore the product should be based on an easily extensible architecture.
Starting work on a new extension, we often did not even anticipate into which “monster” (in a good sense of the word) this project could escalate. A common occurrence is when what began as a small customization ends with almost completely rewritten business processes and additional logic on a good half of the screens. In addition, the product can be expanded with new functionality, quite sufficient for an independent system. As an example - in the project expansion TEZIS for a large distributed company, automation of the treasury activity, evaluation of the performance of employees and some more difficult modules appeared.
The variety of requirements, their volume and unpredictability did not allow using any of the methods described above. On top of that, product versions are coming out fairly regularly. This makes it imperative that you maximize the transfer of an expansion project to a new version of the product.
How do we solve the problem of creating and maintaining extensions?
Our expansion project
Most of our company's projects were created using the CUBA platform. We have already written about it in one of the past articles . In order to understand how the expansion projects are organized, you first need to deal with the device of the platform itself.
In short, CUBA is a set of modules, each of which provides a specific functionality:
- cuba - the core of the application, contains all the infrastructure, tools for organizing business logic, a library of visual components, a security subsystem, etc.
- reports - report generation subsystem
- fts - full-text search subsystem
- charts - chart output subsystem
- workflow - business process management subsystem
- ccpayments - credit card subsystem
Each subsystem can contain persistent entities, screens and services with business logic.
When creating a new project, in its build script, the dependencies of those basic modules of the platform, the functionality of which is necessary, are written. After that, using entities, screens and services of the connected modules, we begin to implement the project. Physically, platform modules are jar files, and the project installed on the server is a regular Java web application.
When you need to expand an existing product on the platform, we do this: we create a new project, but in its build script we indicate the dependence not on the platform modules, but on the product being expanded. The product itself actually acts as a platform for development.

Now inside the project-extension you can create new objects of the domain model, describe the new user interface as in the most ordinary project on the CUBA platform. All the functionality of the underlying modules to the developer is still available.
The most obvious advantage is that all new logic is stored in a separate expansion project. You can always see exactly what and when you wrote in the current extension. The approach does not limit the developer in any way in the type of new functionality, as the plug-in architecture and EAV do.
The process of upgrading the extension to a new version of the product is as follows:
- you specify a new version of the product in the build scripts and reassemble the extension;
- if only a stable product API was used in the extension, then that's it - launch your advanced product and go ahead;
- If there are significant changes in the product at those points that you have expanded, then you may need to change the extension code. As a rule, this happens infrequently, and it is easy to localize the problem. Bugfix product releases always maintain compatibility with extensions.
It is clear that in the expansion it is easy to create new entities, business logic and screens for them. But how to change what is already in the product? For example, add a field to a product entity and display it in existing screens?
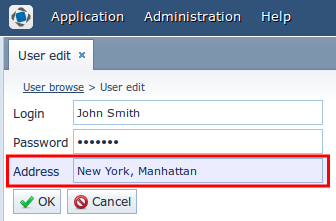
Adding a new attribute to the base product essence
We define a task for ourselves: in the
User entity of the base product, we need to add a field for storing the address. Such requirements are perhaps the most common among our customers. At once we say that the platform supports the model of dynamic attributes about which it was written above, but in practice this option is rarely used - the speed of data sampling and the ease of generating reports are almost always an important requirement.Actually about the alternative method of adding an attribute. OpenJPA is used as the ORM platform. The entity declaration in the product is as follows:
@Entity(name = "product$User") @Table(name = "PRODUCT_USER") public class User extends StandardEntity { @Column(name = "LOGIN") protected String login; @Column(name = "PASSWORD") protected String password; //getters and setters } As you can see, this is a standard description for JPA of the entity and mapping for the table and database columns.
Create an entity heir in an extension project:
@Entity(name = "ext$User") @Extends(User.class) public class ExtUser extends User { @Column(name = "ADDRESS", length = 100) private String address; public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } } The inheritance mechanism is standard for OpenJPA with the exception of the
@Extends annotation, which is of most interest. It is she who declares that the ExtUser class will be universally used instead of the User class.Now all operations for creating a
User entity will create an instance of an extended entity: User user = metadata.create(User.class); // ExtUser The operations of extracting data from the database will also return instances of the new entity. For example, in the base product, a user search service is declared by name, which returns the result of the following JPQL query:
select u from product$User u where u.name = :name Without the
@Extends annotation @Extends we would have a collection of User objects as output, and in order to get the address from ExtUser would have to re-read the result of the previous query from the database. But using the override information provided by the @Extends annotation, the platform mechanisms will pre-transform the query and return us the collection of objects of the ExtUser extended entity. Moreover, if some other entities had references to User , then when the extension is connected, these links will return objects of the ExtUser type, without any change in the source code.Entity redefined. Now it would be nice to display the new field to the user.
The platform screen is a bundle of XML + Java. XML declaratively describes the UI, the Java controller determines the response to events. It is clear that there will be no special problems with the redefinition of the Java controller, but with the XML extension a bit more complicated. Returning to the previous example, adding the
address field to the User entity.The description of the simplest screen layout looks like this:
<window datasource="userDs" caption="msg://caption" class="com.haulmont.cuba.gui.app.security.user.edit.UserEditor" messagesPack="com.haulmont.cuba.gui.app.security.user.edit" > <dsContext> <datasource id="userDs" class="com.haulmont.cuba.security.entity.User" view="user.edit"> </datasource> </dsContext> <layout spacing="true"> <fieldGroup id="fieldGroup" datasource="userDs"> <column width="250px"> <field id="login"/> <field id="password"/> </column> </fieldGroup> <iframe id="windowActions" screen="editWindowActions"/> </layout> </window> We see a link to the UserEditor screen controller, the data source declaration (datasource), the fieldGroup component displaying the entity fields, and the frame with the standard actions “OK” and “Cancel” (windowActions).
I don’t want to duplicate the base screen code in the extension project, so we added the ability to inherit screen XML descriptors to the platform. This is how the screen heir from the base project looks like:
<window extends="/com/haulmont/cuba/gui/app/security/user/edit/user-edit.xml"> <layout> <fieldGroup id="fieldGroup"> <column> <field id="address"/> </column> </fieldGroup> </layout> </window> In the successor screen, the ancestor is specified (the extends attribute) and only those components are described that should be added to or redefined in the base screen. It remains only to declare the screen in the configuration file with the identifier of the basic screen:
<screen id="sec$User.edit" template="com/sample/sales/gui/extuser/extuser-edit.xml"/> Result:
Redefine business logic
As for the redefinition of functionality, everything is quite trivial. The platform infrastructure is implemented on Spring. Accordingly, the business logic layer of services is spring-driven beans. The expansion capabilities provided by the framework are more than enough to override the desired business logic. To demonstrate this clearly, again a small example. Suppose there is a component on the middle layer in the base product that performs the price calculation:
@ManagedBean("product_PriceCalculator") public class PriceCalculator { public void BigDecimal calculatePrice() { //price calculation } } In order to replace the pricing algorithm in the expansion project, we take 2 simple steps:
Create a descendant of the component to be redefined:
public class ExtPriceCalculator extends PriceCalcuator { @Override public void BigDecimal calculatePrice() { //modified logic goes here } } Register the class in the Spring configuration file with the ID of the bean from the base product:
<bean id="product_PriceCalculator" class="com.sample.extension.core.ExtPriceCalculator"/> Now the Spring container will always return an ExtPriceCalculator instance.
Topic Override
We have dealt with the modification of entities, screen components and business logic. Next in line is the visual theme.
Screens created using the platform work in web and desktop clients. At the moment, the use of web clients prevails in our country; therefore, speaking of customization of the topic, we will consider them.
To implement the web UI, we have chosen the popular framework Vaadin. Vaadin allows you to describe threads on SCSS. The description of styles for a new theme on SCSS is in itself much more pleasant than on pure CSS. We have made the process of creating a topic even less time consuming, taking out a lot of parameters to variables.
Procurement for a new theme is created in 2 clicks with the help of our development studio. The new theme imports the styles of the base theme of the platform, the developer only needs to redefine the necessary styles and variables. Many customers want to see the information system in the corporate colors of their company. Our approach to expanding themes allows them to easily achieve this.
In the expansion project, the developer is able to connect new visual components. A large number of components are available in the Vaadin addon repository. If the necessary component was not found there, then you can write it yourself.
Examples of various visual topics:

Conclusion
If you found our approach interesting, you can try the CUBA platform yourself. Creating a product on the platform, you automatically get the opportunity to customize it in the manner described. Always welcome feedback and comments!
PS The author of the title photo - Ilya Varlamov. You can find even more luxury Pakistani trucks on his blog .
Source: https://habr.com/ru/post/214787/
All Articles