Mark read: Twitter, VK, LiveJournal, Facebook ...
I. What is the problem.
Mailboxes, "Inbox" personal messages, RSS - all this combines one convenience: a clear separation of read and unread messages. However, in blogs and social networks, at least the most common, such an opportunity is often not provided. And by coincidence, these resources do not provide users with RSS feeds.
It seems to be not so difficult to remember what you read and what you don’t yet. But if you follow a very dynamic tape or an active discussion of one topic, it is sometimes not so easy to figure it out right away. Yes, and constantly reading one or two of the first sentences to idle, just to understand that you already read this, is not such a pleasant and harmless task.
Previously, I used this method: I assigned custom styles on top of the site, which would more clearly highlight the viewed links; at the end of the next reading, he opened the last (he is usually the top) post separately, so that the link to it got into the history of the browser; subsequently, the first such reference to the read post and served as a watershed of old and new messages. However, this is still not a very clear way.
')
Of course, you can write a whole extension for your favorite browser or a cunning user script for one of the common extensions, but I wanted to find a simple and cross-browser way. So the next idea was born. I am not a programmer, so I don’t set myself the task of offering a ready-made elegant solution, and I understand that my method is clumsy in principle and is certainly ugly in implementation. Therefore, the description of the problem will most likely be:
1. Discuss the problem itself. Perhaps, fundamentally different ways have long been known, simpler, more reliable and more beautiful. That is, I pound through the open door and reinvent the wheel. Share them, please.
2. To think together about the features of the current implementation. Perhaps the method can be improved in large and small. However, it’s really quite small, maybe not necessary, we’re not developing the engine and not the library.
That is, all this as a very rough idea.
Ii. The solution in general terms.
A relatively perfect "overlay" method would look like this: the tape consists of homogeneous coordinated elements with constant unique identifiers; create a bookmarklet that will take instructions to the last post read, visually mark both it and all older posts following it, memorize the identifier of the last post read and subsequently restore the border on it.
But here we come across a number of problems:
1. Not always the structure of tapes for all users has the same structure.
2. Not always posts are homogeneous subordinate elements.
3. Not always they have classic identifiers.
4. Not always on the current page from the very beginning of reading is already once read post.
5. Some sites are aggressively tuned to the most convenient cross-browser information storage tool.
Examples of these problems will be given in the course of the further description. But first, let's imagine in the first approximation the implementation of the most optimistic option.
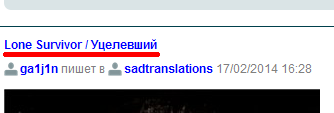
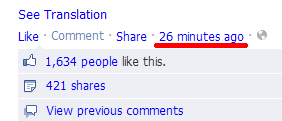
Evaluation of the four networks mentioned in the header (listed in the order of complication of diagnosis) shows that the absence of message identifiers can be completed by referring to these messages within the messages themselves: these links are by definition unique and permanent. Here is where they hide in the networks taken as a model (underlined in red):
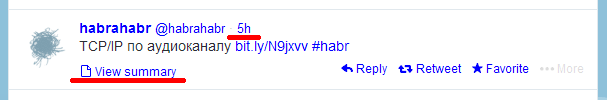
VK

Livejournal
To point the script in the bookmarklet to the desired link, we just select the part of the link right before launching the script (so that the cursor / focus remain inside the link). The script remembers the address of the link in localStorage for the future, climbs the chain of elements to the main container of the post and assigns it a special class. The script creates a style for this class and all subsequent subordinate elements so that the entire read segment is highlighted, for example, with a special color.
If nothing is selected on the page, the script assumes that we are only starting to read after the break, so it immediately contacts localStorage, extracts a link to the previously read post from it, tries to find it, and then repeats the way to the top container and all operations with styles .
The script will need to perform at least three checks with a message about possible unsuccessful results: is the open page a site for which the script is designed and to which the necessary department is assigned to localStorage; whether the user selected the correct link (or did the selection not accidentally go beyond its borders); is there a previously read post on the page if the user didn’t select anything.
In the near future, if we have a parent selector , it will not be possible to deal with localStorage at all, but creating styles along the chain for the great-grandfathers of the browsed links (unless, of course, the style restrictions for the browsed links become even more stringent for their parent and ancestors ). True, then you will have to open the last post separately, so that it will go down in history.
Iii. Private features of the sites analyzed
Here we were lucky with the ribbon structure (tweets are homogeneous and subordinate). But the principle of small dosing of tweets with endless scrolling leads to the fact that we may have to scroll down several times until the post reads before the break physically appears on it. However, a few keystrokes of the “End” key alternately with a bookmarklet are not such a tedious task. The same problem will persist for VK and Facebook: if the read segment has gone deep into the tape, the script will report several times that the last post was not found before it can mark the border.
VK
Here, the structure is also okay, but there is a slight warning: when rushing, it is easy to confuse the link to the original post of another person with reference to its repost in our wall (we need the second type of links) - both versions are inside the post and are very similar. Links to the post itself and comments on it are also similar. The script is trying to check if the user has confused all these links. Currently, the script is designed for wall posts and news.
Livejournal
Here we are faced with a variety of the structure of the tapes of friends from different users. In order to unify everything somehow, we will take the mobile tape as a base, because it has the same structure for everyone (in the screenshot above, you can see the title link to the post of such tape). At the same time the need for multiple scrolls will be replaced by the need for multiple downloads of the previous pages. But this is not the end of the features: not all posts in the feed are equally coordinated, because groups of posts of the same day are in a separate container, which we will not allow for by special CSS3 rules. Therefore, the script can mark not all the read segment to the end, but only posts that are simultaneously the day with the last read.
The most problematic option. Posts have a very complex system of subordination, are distributed in several dynamic containers, have a complex system of unreadable classes. Therefore, the homogeneity of the color of the read can not always be achieved, except that we read the tape for a long time, without closing and reloading the tab. In addition, the site has a strange handling of localStorage: periodically our script records disappear from there, as if the scripts of the site itself from time to time clean the entire segment of the site in the repository, considering themselves to be the exclusive owner in this area (maybe this is right?). Moreover, with the most meticulous tracking of friends and journals to which the user is subscribed, messages about the comments of friends in other posts get into the tape, and these messages can constantly move up the tapes, while maintaining a single key link, which destroys the sequence of posts and mechanism tracking. Therefore, in such posts it is better to highlight the link to the last comment (fortunately, all XPath work, as well as with links to the post itself) so that there is no confusion during repeated comments and shifts of such posts up the tape, including before unread posts.
Another minor general warning: the displayed text of the links we need in most networks is automatically updated about once a minute, adjusting to the past time, so sometimes our selection has time to fly before clicking on the bookmarklet - because after the update, the link already becomes a new element of the interface; this failure does not do any harm, the script simply re-marks the old read post according to the data in localStorage (as if we didn’t select anything), and just need to select the link again and click the bookmark again.
Iv. Implementation.
In theory, it should work in all recent browsers, because standard, albeit relatively new tools are used. I apologize for the awkward amateurish code.
Readable option:
javascript:(function(xpaths, doc, hst, stl, sel, lnks, i, a_lnk, the_lnk, post) { xpaths = { 'twitter.com': { 'lnk': './ancestor-or-self::a[contains(@class, "tweet-timestamp") or contains(@class, "details")]', 'post': './ancestor::li[contains(@class, "stream-item")]' }, 'vk.com': { 'lnk': './ancestor-or-self::a[descendant::span[contains(@class, "rel_date")] and not(contains(@class, "wd_lnk"))]', 'post': './ancestor::div[contains(@class, "feed_row") or contains(@class, "post") and not(@id="page_wall_posts")]' }, 'm.livejournal.com': { 'lnk': './ancestor-or-self::a[ancestor::h3[contains(@class, "item-header")]]', 'post': './ancestor::li[contains(@class, "post-list-item")]' }, 'www.facebook.com': { 'lnk': './ancestor-or-self::a[descendant::abbr[@data-utime]]', 'post': './ancestor::div[contains(@class, "_5jmm") and contains(@class, "_5pat") and contains(@class, "_5uch")]' } }; doc = document; hst = doc.location.hostname; if(xpaths[hst]) { if(!doc.querySelector('style#usernameReadPost')) { stl = doc.querySelector('head').appendChild(doc.createElement('style')); stl.id = 'usernameReadPost'; stl.innerHTML = '.usernameReadPost, .usernameReadPost ~ * {background-color: silver !important;}'; } sel = doc.getSelection(); if(sel.isCollapsed) { lnks = doc.querySelectorAll('a[href$="' + localStorage.getItem('usernameReadPost') + '"]'); for (i = 0, a_lnk; a_lnk = lnks[i]; i++) { the_lnk = doc.evaluate(xpaths[hst].lnk, a_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue; if(the_lnk) { post = doc.evaluate(xpaths[hst].post, the_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue; break; } } if(post) { post.className += ' usernameReadPost'; } else { alert('Read post not found.'); } } else { the_lnk = doc.evaluate(xpaths[hst].lnk, sel.focusNode, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue; if(the_lnk) { post = doc.evaluate(xpaths[hst].post, the_lnk, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue; post.className += ' usernameReadPost'; localStorage.setItem('usernameReadPost', the_lnk.getAttribute('href')); } else { alert('Wrong link.'); } } } else { alert('Wrong hostname.'); } })() Abridged version:
A version with remote formatting spaces and line breaks (in Firefox, you can simply drag the bookmarks and then replace the name with something readable; this code fits into two kilobytes, in case this restriction still applies to the latest versions of IE).
javascript:(function(xpaths,doc,hst,stl,sel,lnks,i,a_lnk,the_lnk,post){xpaths={'twitter.com':{'lnk':'./ancestor-or-self::a[contains(@class,"tweet-timestamp")or contains(@class,"details")]','post':'./ancestor::li[contains(@class,"stream-item")]'},'vk.com':{'lnk':'./ancestor-or-self::a[descendant::span[contains(@class,"rel_date")]and not(contains(@class,"wd_lnk"))]','post':'./ancestor::div[contains(@class,"feed_row")or contains(@class,"post")and not(@id="page_wall_posts")]'},'m.livejournal.com':{'lnk':'./ancestor-or-self::a[ancestor::h3[contains(@class,"item-header")]]','post':'./ancestor::li[contains(@class,"post-list-item")]'},'www.facebook.com':{'lnk':'./ancestor-or-self::a[descendant::abbr[@data-utime]]','post':'./ancestor::div[contains(@class,"_5jmm")and contains(@class,"_5pat")and contains(@class,"_5uch")]'}};doc=document;hst=doc.location.hostname;if(xpaths[hst]){if(!doc.querySelector('style#usernameReadPost')){stl=doc.querySelector('head').appendChild(doc.createElement('style'));stl.id='usernameReadPost';stl.innerHTML='.usernameReadPost,.usernameReadPost~*{background-color:silver !important;}';}sel=doc.getSelection();if(sel.isCollapsed){lnks=doc.querySelectorAll('a[href$="'+localStorage.getItem('usernameReadPost')+'"]');for(i=0,a_lnk;a_lnk=lnks[i];i++){the_lnk=doc.evaluate(xpaths[hst].lnk,a_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;if(the_lnk){post=doc.evaluate(xpaths[hst].post,the_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;break;}}if(post){post.className+=' usernameReadPost';}else{alert('Read post not found.');}}else{the_lnk=doc.evaluate(xpaths[hst].lnk,sel.focusNode,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;if(the_lnk){post=doc.evaluate(xpaths[hst].post,the_lnk,null,XPathResult.FIRST_ORDERED_NODE_TYPE,null).singleNodeValue;post.className+=' usernameReadPost';localStorage.setItem('usernameReadPost',the_lnk.getAttribute('href'));}else{alert('Wrong link.');}}}else{alert('Wrong hostname.');}})() You can also drag a ready link from here (it’s there the same name for this post).
A brief explanation of the code
In order to be able to use one bookmarklet to all relevant sites, we first create an XPath path database for two necessary elements: links to the post and the top post container. The particular complexity and strangeness of the paths is due to at least two reasons: when a link is selected, the focus element is often the link itself, then the subordinate element, then the final text node; links and containers are not always have a unique combination of tag name and class, you have to connect the parameters of containing or subordinate elements.
First of all, the script checks the page for belonging to the desired site. If there is a coincidence, the desired style is created (if it has not already been created by running the script on the same page): for now, everything is simple, we just mark the read with gray.
Next, the script checks if there is a user-selected site on the page. If not, then this is the first reading of the page after the break, so you need to start with restoring the old border: the script goes through all the links that match the specified XPath and matches them with the saved address from localStorage. If the desired link is found, it becomes the starting point for searching the entire container's XPath for the entire post. If both the link and the post are found, the class is added and the style is applied. Otherwise, the user is notified of the need to scroll the page or load other pages into the tape.
If there is a segment selection on the page, the script checks the element in the middle of which the selection ends. If it is the desired link, the operations with search and tagging of posts are repeated, and then the link address is placed in localStorage. If this is not the link (or the user missed the end of the selection), a message is displayed.
Those who wish can further reduce the names of variables, replace the blank name of the key class of read posts and the identifier of an additional style according to their nicknames for greater uniqueness, refuse to use a mobile tape in LiveJournal and adjust the parameters to their tape structure, not to mention more significant improvements ( you can, for example, attach a link selection event handler to the page so that you do not have to click on the bookmarklet every time during uninterrupted reading to automatically update tapes).
If someone finds a way to at least a little worthy of improvement, ideas and code can be shared in the comments. I would be grateful for additions, fixes and information about support in browsers (he tested only on the latest nightly builds of Firefox).
Source: https://habr.com/ru/post/213283/
All Articles