Chinese video cameras and TCP: a bug or feature?
 In connection with the usurpation of the position of the house manager of our MKD, and the need to “brush” public disorder, we are slowly constructing a video surveillance system.
In connection with the usurpation of the position of the house manager of our MKD, and the need to “brush” public disorder, we are slowly constructing a video surveillance system.Of course, funding is minimal, the plans are ambitious, so everything is collected from pasture.
Details a little later, but one of the interesting bugs, which forced to sort out a lot of things.
So, everything started from a small one — a simple dome camera; the lousy one was taken on the principle “ only IP and dome ”. After the process of busting the software started (the topic of a separate post, will be, again, later) ... At the end, I fixed onto Macroscop in one channel. It was a couple of months, I did not ask for a drink, I did not help addicts to drive.
And it works like everything, but somehow podlagivaet periodically. He sinned on everything: on percents, on the network, on the software, on the weather on Mars ... The support for the logs says that the camera periodically falls off.
')
Upd
Yes, more cameras were purchased, the quality and price are much higher. Having overcome laziness in three beautiful days in different weeks, it was all mounted on the 1st floor, set up in a computer, connected. And the second iteration of software brute forceing went, so that the cameras are bigger, more humane, the interface is more convenient ... After the second brute force round, there is AxxonNext for now. Yes, only the lags have reached a new level: the cameras fall off almost non-synchronously every 5-10 minutes if you enable TCP; and if you keep UDP, then the artifacts climb like I do not know what.
I complained about this topic on the topic, and take maxlapshin and say that it is a stable bug of the Chinese cameras, where the firmware was created by their own efforts: if the client does not have time to rake out, then garbage climbs into the stream. Since it was sold on ali, it was decided to try to solve the problem thoroughly. Several times I tried to describe the bug with different words, but I understood that the English of us both leaves much to be desired, so you just need to “show code”.
The first stage of the excavation: to find the cause
So, first we take tcpdump, and wait for the clipping situation. Wait for long, in 5 minutes I caught as many as 3 pieces. How to understand what happened? A stream in one and a half million packages ... For a start we filter, leaving only one camera. Then Ctrl + F => tcp.flags.syn == 1 => find the beginning of the reconnect, from where we scroll up to see what happened ...
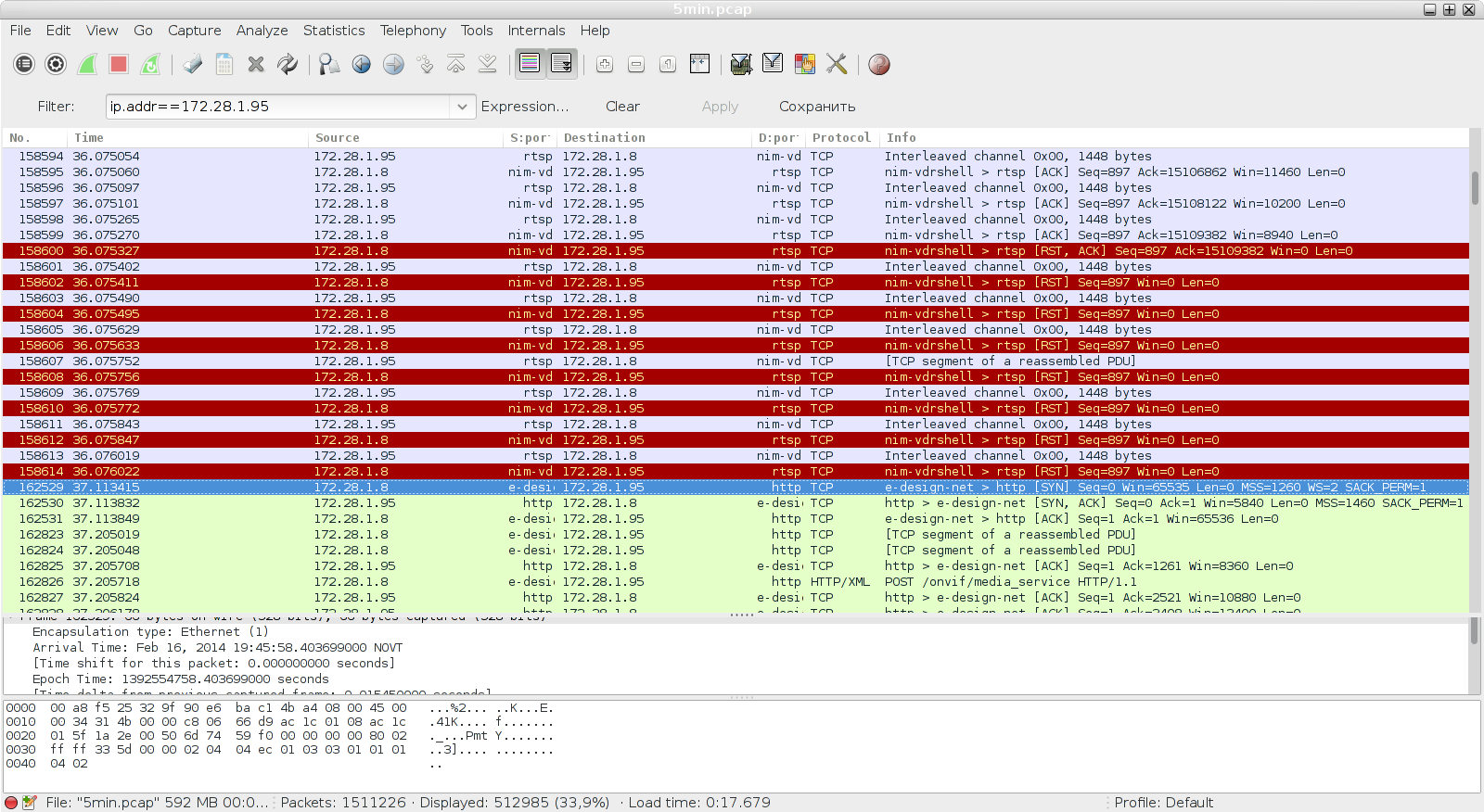
We observe that the connection was closed from the side of the computer ... But it’s just embarrassing that before that Win = 11460, Win = 10200, Win = 8940 - that is, it seems that the client doesn’t have time. Stop stop stop. How does it not have time? AMD Phenom II X6 1100T? Not weird. Io? So writing to a separate disk, and did not rest on the shelf. Yes, and then there would be a dependence on viewing, for example - but it is not there ... In general, we leaf through even higher slightly:
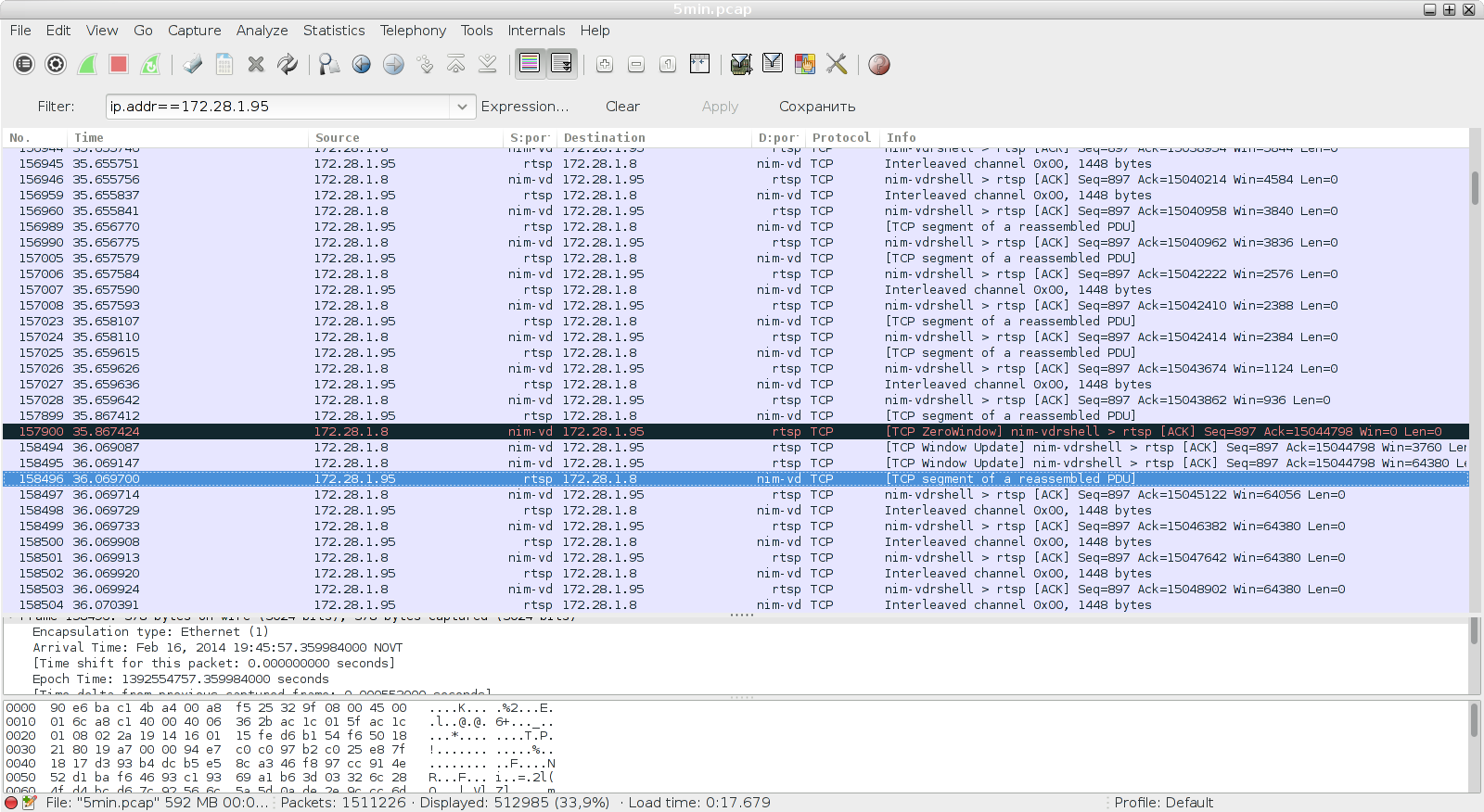
So literally a second ago, everything went away in ZeroWindow. Not exactly in time. But why break something ?! Scroll below, look at another cliff ...

So, we observe ZeroWindow for as much as 2.5 seconds - it does not climb at all into any gate. Scroll below, and it seems, we begin to understand:
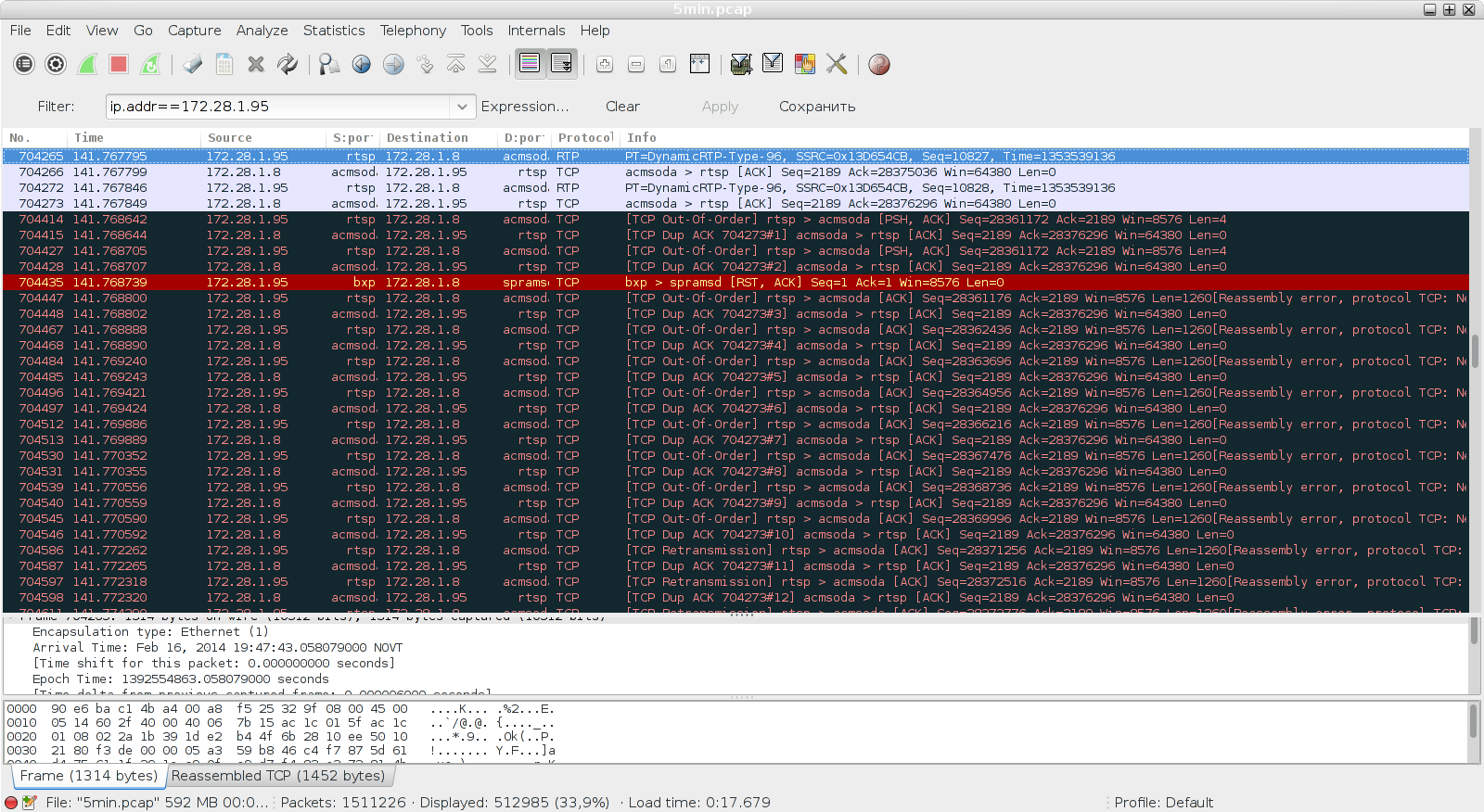
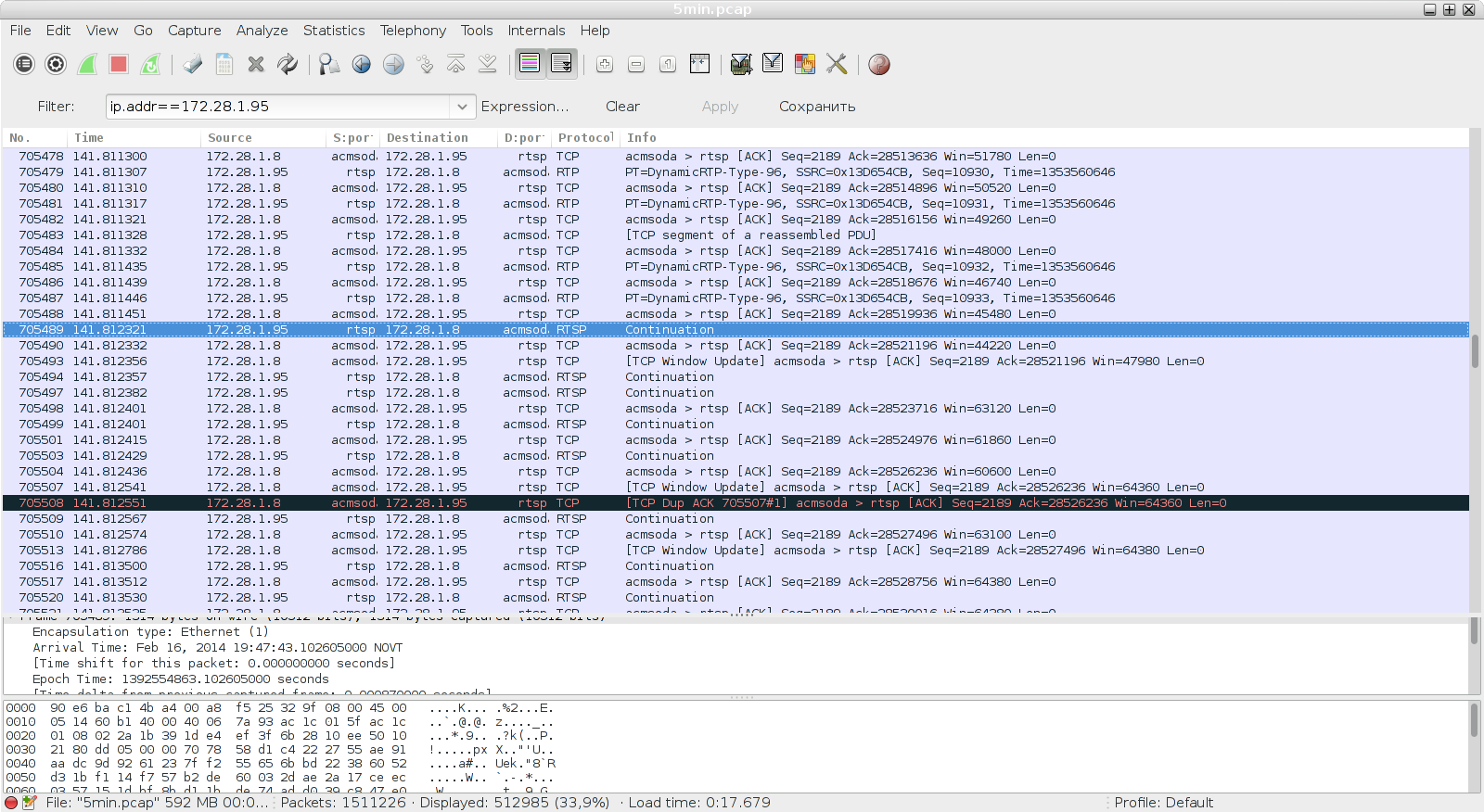
We look at the TCP stack (the cameras? Probably ...) did not behave very well, after which the RTP stream lost its way - at one point instead of DynamicRTP-Type-96, RTSP Continuation went.
So, we conclude: all that is needed for the simulation is to request the RTP stream, pull it out a little, and then do sleep (), and see if the stream breaks.
Search parts for Frankenstein
What to do when you need to quickly throw a test piece? Take a scripting language, a set of ready-made libraries, make it all together, rejoice. We climb to google. Python + ONVIF. Rotten Ruby + ONVIF. Oh, there is a ruby-onvif-client . OK, we take. Stream URL caught. Great, but if: protocol to twist? .. UDP, HTTP, TCP ... the result is one - excellent, I learned to catch the URL by onvif, now I’d like to merge it.
Curl? Does not chew. Okay, Ruby + RTSP ... Hooray, there is lib. We eat him url, and bummer. Attempts to log in exclusively through Basic. A little more google. Bummer. Then there is one method - a file. We solder with a hot iron , using the way of swearing at the volumes of the magic of Ruby (who will tell me how to do an "honest" recursion correctly, so that both return and yield work correctly, and how to guess from the function description, what it may be needed? her - and cleaner code, and silky hair).
And once again we exult, rtsp_client works. Open in the second window tcpdump ... Damn! I requested from ONVIF: protocol => "TCP". What the hell, why UDP?
A soldering iron in hand ... Ha! UDP is nailed at lib/rtsp/client.rb@request_transport. So, solder there with the same nails / TCP. Run - falls. Why? Where? Yeah, he requires client_port ... What client_port, if it is TCP? Hardcode rtp_port if it is not in 554. So, the IP is necessary server - hardcode. Oops, can not, he says, at 'bind ()' it doesn’t root on port 554. Is logical. So, why? Well ... This is in RTP :: Receiver ... We look at the init_socket in the mode: TCP and wonder - why does he need a TCPServer for Receiver? Something wrong. Obviously, no one debugged it explicitly on TCP.
After a couple of minutes of attempts to understand the logic, it turned out to the Sharp-Sighted Eyes that there was no wall:
transport: RTP / AVP / TCP; unicast; destination = 172.28.1.199; source = 172.28.1.95; interleaved = 0-1
Well, well ... what interleaved? Google: rtp interleaved => Wikipedia => Find on page “interleaved” => Aha! So RTP and RTSP fall in the same connection!
We throw out the rtsp libu, since for my task to edit either I don’t want to be frank - here it is obviously necessary to redo the architecture in an amicable way.
We grow amoeba
So, we are again at zero: we have a rtsp: // url of the camera, there is a need to merge it and play around while merging with the connection ... Stop! At first. There is an url. I have a camera. There is a task to reproduce a bug on it. Why do I need ONVIF? Why RTSP? You just need to request and download the answer.
No sooner said than done. DESCRIBE? And why do we need it ... We only need to first SETUP, from where to pick up the Session: then PLAY with it.
The very first experience showed that he doesn’t even need authorization here.
Fine! The first pancake was fired right away: a simple script perfectly reproduced the bug - after sleep (), and the stream broke with a bang.
But in order to play around with the TCP Window, you would have to be able to set TCP_WINDOW_CLAMP. And for this you need to do setsockopt to connect but after creating a socket.
And how to do it in Ruby? Um ... Looking at Google ... Empty. Looking at the source - init_inetsock_internal ... FIG there! we first create rsock_socket (), and then immediately rsock_connect (). Pancake.
Okay, I still do not really love chopping. In 2 minutes we rewrite to python , add setsockopt. We add the analysis of the RTP packet number.
The result of the analysis: from the size of the initial window, the amount of information changes, how much does the camera manage to transmit normal, before it breaks. However, it does not matter, he commits the result, and wrote a bug report to the seller, so that they give the developers the firmware.
It would have calmed down, but maxlapshin asked whether it was possible to somehow live with this bug. And this required additional excavations.
Basically, how to live with it?
1) You can monitor the failure and reconnect yourself
2) You can track your own lag (I do not know how, but you can) and join immediately, without waiting for the flow to break
3) You can try to restore synchronization with the stream.
So, we stick instead of the call of the raise - call reconnect, and analyze the losses by the difference of the RTP packet numbers. If we act on point 1, then the losses amount to about 1,500–1,800 RTP packets (approximately 600 packets per second sleep ()).
We stick reconnect right after sleep (). The result is exactly the same.
We stick the resynchronization with the search method "$ \ x00" - it works disgustingly. We stick the resynchronization with the search method "$ \ x00 [LEN] {len bytes} $ \ x00" - it works stably, the loss is one and a half times less than with reconnect. But the most important thing is that the TCP connection does not fall off, which means that the TCP Window adaptation algorithm and receive buffers continue to work. As a result, after 1-2 failures at the beginning of the connection, the flow simply stops breaking - sleep () continues to put the client to sleep regularly, and the flow does not fall.
The resulting test script quality code does not shine , but perfectly performs the function of proof-of-concept.
And now, finally, we come to the question asked in the title.
Is it a bug or a feature?
My personal opinion is really better than breaking the connection entirely: there are connection numbers for RTP packets, so you can measure the lost volume without problems.
If the channel is thinner than the network bandwidth, then losses will grow, thus finding losses for more than 5 seconds - you can safely complain about the channel thickness (reconnect with lower quality, ask for a cable change, blow up nuclear power plants, or any other way of reacting to this problem); if the problem is that the receiver simply does not have time for some reason to rake - resync behavior = our luck. We get a combination of the advantages of both UDP and TCP approaches: if something is bad at all, a piece is lost; in other cases, retransmitters are automatic and do not cause problems.
Well, for a snack, let's talk about that for a bug in the firmware ... And the bug is simple: send (somedata, somelen) returns <0 in case of an error, the number of bytes if it worked. And any mistake of all novice network developers: send (somedata, somelen) can return something LESS than somelen - it did not fit into the buffer.
If this is not processed, the tail from somedata is simply lost - it was not sent and thrown away.
How to fix?
To fix it this way: you have to memorize the unfinished piece, and stop sending anything, until the send () of this remainder sends the whole thing. After that, you need to start sending _next_ packets (discarding those that were all the time that the buffer was busy). Then we get the very behavior of the TCP-UDP mix, but without the need for the client to engage in magic resynchronization with packet boundaries.
Hopefully, the manufacturers will correct this bug, and after a while, all the Chinese firmware for Chinese cameras will delight you to work correctly without a single break & tm;
Source of joy: LIVE555 Jurassic
The support macroscop drew my stupid inattention to the fact that LIVE555 is being announced in 2011 ... So through binwalk + dd + mount I looked into the giblets of the firmware. rtsp_streamer and true from 2011.
Looked into the diff between the two versions of live.2013.10.10.09.tar.gz and live.2014.02.19.tar.gz:
diff --git a/liveMedia/RTPInterface.cpp b/liveMedia/RTPInterface.cpp index d45e5a8..3d88d55 100644 --- a/liveMedia/RTPInterface.cpp +++ b/liveMedia/RTPInterface.cpp @@ -324,19 +325,23 @@ Boolean RTPInterface::sendRTPorRTCPPacketOverTCP(u_int8_t* packet, unsigned p } Boolean RTPInterface::sendDataOverTCP(int socketNum, u_int8_t const* data, unsigned dataSize, Bool - if (send(socketNum, (char const*)data, dataSize, 0/*flags*/) != (int)dataSize) { - // The TCP send() failed. - - if (forceSendToSucceed && envir().getErrno() == EAGAIN) { - // The OS's TCP send buffer has filled up (because the stream's bitrate has exceeded the cap + int sendResult = send(socketNum, (char const*)data, dataSize, 0/*flags*/); + if (sendResult < (int)dataSize) { + // The TCP send() failed - at least partially. + + unsigned numBytesSentSoFar = sendResult < 0 ? 0 : (unsigned)sendResult; + if (numBytesSentSoFar > 0 || (forceSendToSucceed && envir().getErrno() == EAGAIN)) { + // The OS's TCP send buffer has filled up (because the stream's bitrate has exceeded + // the capacity of the TCP connection!). // Force this data write to succeed, by blocking if necessary until it does: + unsigned numBytesRemainingToSend = dataSize - numBytesSentSoFar; #ifdef DEBUG_SEND - fprintf(stderr, "sendDataOverTCP: resending %d-byte send (blocking)\n", dataSize); fflush(st + fprintf(stderr, "sendDataOverTCP: resending %d-byte send (blocking)\n", numBytesRemainingToS #endif makeSocketBlocking(socketNum); - Boolean sendSuccess = send(socketNum, (char const*)data, dataSize, 0/*flags*/) == (int)dataS + sendResult = send(socketNum, (char const*)(&data[numBytesSentSoFar]), numBytesRemainingToSen makeSocketNonBlocking(socketNum); - return sendSuccess; + return sendResult == (int)numBytesRemainingToSend; } return False; } And here is a clipping from changelog.txt:
2013.12.04:
- Updated the "sendDataOverTCP()" function (in "RTPInterface.cpp") to allow for the possibility of
one of the "send()" calls partially succeeding - ie, writing some, but not all, of its data.
- Fixed a couple of minor bugs. (Thanks to "maksqwe1ukr.net".)
? . , LIVE555 .
, -- topsee; MontaVista. , .Source: https://habr.com/ru/post/213063/
All Articles