Break open the library from "GEOTAR-Media"
Recently, the topic of copyright is gaining increasing popularity in society. The screws are tightened, new laws are being adopted, and the copywriters continue to cry out about their mythical lost profits. Let's see how some of them care about the safety of their own products.
Slowly surfing the Internet, I, by the will of fate, found myself on the site "Student Consultant", which gave life to LLC "Polytechresource" - a company affiliated to the publishing group "GEOTAR-Media". Let's get to know our future patient.
Well, let's check how this bold statement is true. Head over to the site and choose some random book, such as Internet analytics. Search and evaluation of information in web-resources . Having poked into the "Table of Contents", you will notice that the site provides us with several pages for review, and then offers to register:

The demo pages of the book are presented in the form of a picture, which is not very interesting for us, but at the bottom of each demo page you can see the following link:
')

We use the opportunity provided by the developers and poke at it, and then examine the resulting page:
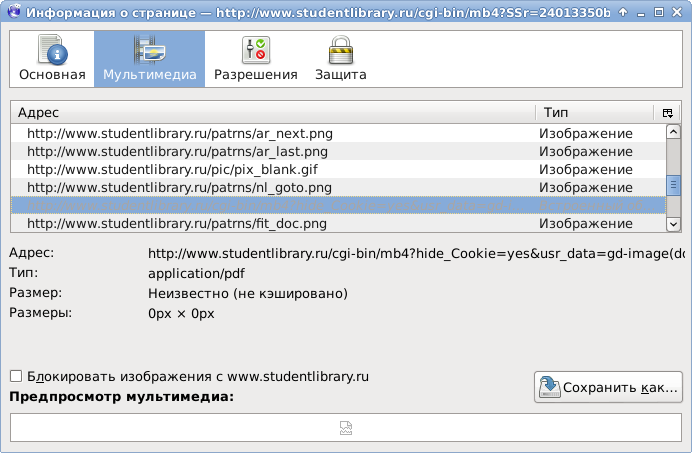
You may notice that instead of a picture, a new object appeared on the page with a very interesting address:
Doing the same with the next page from the table of contents, we get another link:
Obviously, the parameter ISBN9785804105694-SCN0000 is the book's ISBN and chapter number, and 0002.pdf and 0003.pdf, the parameter responsible for the page.
Thus, substituting the chapter number and page number, we, even without registering on the site, without any restrictions, can receive any page of the book directly in pdf. The only inconvenience is that each chapter corresponds to certain page numbers. And if in the book this chapter does not correspond to this page, then we are redirected to the main page of the site. Therefore, it is necessary to determine this correspondence exclusively empirically.
To heighten convenience, let's write a small script that saves the book as separate pages:
The principle of operation is extremely clumsy:
Since we don’t know how many pages are in each chapter, we go through everything and if there is an html tag in the resulting file, then this is clearly not a pdf page and this file is to be deleted. Of course, it would be possible to immediately glue the pages into a single pdf, but experience has shown that the pages are not completely consistent and have to be compiled manually (and indeed, one must know the measure of cynicism at the end).
In conclusion, I would like to refrain from any specific conclusions. Let everyone make them for himself. One has only to recall that this study is for informational purposes only and does not constitute a call for piracy and copyright infringement.
Slowly surfing the Internet, I, by the will of fate, found myself on the site "Student Consultant", which gave life to LLC "Polytechresource" - a company affiliated to the publishing group "GEOTAR-Media". Let's get to know our future patient.
The multidisciplinary educational resource “Student Consultant” (www.studentlibrary.ru) is an electronic library system (ELS), which provides access via the Internet to educational literature and additional materials acquired under direct contracts with rightholders. The site is intended for corporate users - universities, colleges, and other educational institutions, which, when they purchase a subscription to a paid service, then provide their students and employees with access to the full texts of electronic versions of books. Access to the resource for individuals is currently not offered.
Well, let's check how this bold statement is true. Head over to the site and choose some random book, such as Internet analytics. Search and evaluation of information in web-resources . Having poked into the "Table of Contents", you will notice that the site provides us with several pages for review, and then offers to register:
The demo pages of the book are presented in the form of a picture, which is not very interesting for us, but at the bottom of each demo page you can see the following link:
')
We use the opportunity provided by the developers and poke at it, and then examine the resulting page:
You may notice that instead of a picture, a new object appeared on the page with a very interesting address:
www.studentlibrary.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,ISBN9785804105694-SCN0000,0002.pdf,-1,,00000000)
Doing the same with the next page from the table of contents, we get another link:
www.studentlibrary.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,ISBN9785804105694-SCN0000,0003.pdf,-1,,00000000)
Obviously, the parameter ISBN9785804105694-SCN0000 is the book's ISBN and chapter number, and 0002.pdf and 0003.pdf, the parameter responsible for the page.
Thus, substituting the chapter number and page number, we, even without registering on the site, without any restrictions, can receive any page of the book directly in pdf. The only inconvenience is that each chapter corresponds to certain page numbers. And if in the book this chapter does not correspond to this page, then we are redirected to the main page of the site. Therefore, it is necessary to determine this correspondence exclusively empirically.
To heighten convenience, let's write a small script that saves the book as separate pages:
# -*- coding: utf-8 -*- import urllib import os def main(*argv): isbn = 'ISBN9785804105694' scn_amount = 3 page_amount = 78 for scn in range(0, scn_amount + 1): for current_page in range(0, page_amount + 1): current_page_formated = (4 - len(str(current_page))) * '0' + str(current_page) scn_formatted = (4 - len(str(scn))) * '0' + str(scn) url = 'http://www.studmedlib.ru/cgi-bin/mb4?hide_Cookie=yes&usr_data=gd-image(doc,' + isbn + '-' + 'SCN' + scn_formatted + ',' + current_page_formated + '.pdf,-1,,00000000)' print 'getting ', url urllib.urlretrieve(url, 'pages/' + str(scn) + '_' + str(current_page) + '.pdf') f1 = open('pages/' + str(scn) + '_' + str(current_page) + '.pdf', 'r') if '<HTML>' in f1.read(): os.remove('pages/' + str(scn) + '_' + str(current_page) + '.pdf') if __name__ == "__main__": main() The principle of operation is extremely clumsy:
- isbn - ISBN books,
- scn_amount - the number of chapters
- page_amount - the number of pages.
Since we don’t know how many pages are in each chapter, we go through everything and if there is an html tag in the resulting file, then this is clearly not a pdf page and this file is to be deleted. Of course, it would be possible to immediately glue the pages into a single pdf, but experience has shown that the pages are not completely consistent and have to be compiled manually (and indeed, one must know the measure of cynicism at the end).
In conclusion, I would like to refrain from any specific conclusions. Let everyone make them for himself. One has only to recall that this study is for informational purposes only and does not constitute a call for piracy and copyright infringement.
Source: https://habr.com/ru/post/212589/
All Articles