About the prospects of using auto-change while typing
In the previous article I considered the creation of alternative keyboard layouts, incl. problems that arise when building optimization models for these layouts.

Here we will go in a slightly different way and consider the possibility of reducing the total number of keystrokes (except for using chord set methods and stenotypes , because this is another big topic).
At once I will make a reservation that the use of a stenotype together with the knowledge of shorthand, of course, will have a much greater effect in terms of productivity gains. But the method discussed below is easy to implement (there is no need for special equipment, complex software) and takes less time to study (remembering a few dozen abbreviations is usually easy).
')
AutoCorrect (AZ) will be called a way of printing a combination of letters / words / phrases, in which the source text is programmatically reassigned to other shortcuts. For performance reasons, the typed key combination (let's call it a key or abbreviation) should have a minimum length relative to the original sequence of letters. The difference in the number of keystrokes when typing a combination in its original form and when typing with abbreviations will be a gain on this combination due to AZ.
For example, you need to type in such a frequently used word as “because.” If the abbreviation looks like "n", then the gain when typing only one word will be 5 characters.
Note that in the world this practice has long existed. Even competitions are held in various offsets - using the system of reductions and without it. In the first case, the world record in the 30-minute interval is 955 beats / min , in the second - 821 beats / min . Both records set the infamous Helena Matushkova.
The most developed system of abbreviations for the Czech language, called Zavisie (ZAVpis). There is even a training site , and there is information that mastering the system of cuts begins only after acquiring a sufficiently high level of blind typing skill.
As we see from the ratio of numbers 955 and 821, the gain when using AZ is not that high (~ 16%). However, in this case, the system AZ is adapted to the average structure of the language, and does not take into account the specific words, features characteristic of different areas of knowledge. The user’s lexicon used in communication and everyday correspondence are also not taken into account. In everyday life or a narrow practical field, the vocabulary is much smaller in volume, and the effectiveness of the AZ system, tailored to specific needs, can increase significantly.
First, you need to decide for what purposes the autochange system is created. If the AZ system is required to reduce the time for recruiting an average sentence in Russian, then it is necessary to take into account the structure of the language as a whole. Here you can go two ways.
One of them is to personally collect a large sample of texts that adequately represent a language (usually the size of such a sample is from several hundred megabytes) and analyze them statistically to highlight the most frequent words, combinations of letters, symbols. Then, based on the analysis, build statistical tables.
Note that this method is more suitable for the case when the AZ system is created for itself, under its most frequently used words - in articles, in business correspondence, when communicating in a chat, on a forum, etc.
The second is to use ready-made tables. Of course, such tables are already in a usable form. This implies the use of the National Corpus of the Russian language and frequency dictionaries of the Russian language (one of the most famous is the Sharov frequency dictionary: [1] ; [2] ).
A list of the 100 most frequent word forms can be viewed here .
It seems logical that the most frequent words should be subjected to autocaps first, and the longest among them. In general, all language statistics are subject to Zipf's law . This is a generalized hyperbolic distribution of ranked statisticians, no matter at what level - whether it is the level of individual letters or symbols; letter combinations (n-grams); word level; phraseological level.
Such statistics, along with Gaussian, very often appear in the world around us, and were found in various fields of knowledge. For example, the distribution of people by income (Pareto), the distribution of scientists by productivity (Lotka), the distribution of articles by journals (Bradford), the distribution of settlements by population, the distribution of earthquakes by intensity, etc. In general, such statistics arise from the strong interdependence of events in the system (analogue of positive feedback), a type of chain reaction, as a result of which both extreme amplification and strong weakening can occur.
For us, it is important that the peaks, positive deviations from the hyperbolic trend will just indicate the words that must first enter the AZ system. In this case, the greatest contribution to the final effectiveness of the system will be made by the first few hundred most frequent words.
Consider other features of the construction of the system AZ:
1. Keys must be unique (do not coincide with words and other keys), minimal in length, easily remembered. Such keys should consist either of the first few letters of the word, or of the first and last.
2. The purpose of the keys (their length, letters, symbols used) will depend on the size of the AZ system itself. Consider the simplest example. Suppose we want to create a system for a single word “later”, it is obvious that the best option is the abbreviation “n”. If the system consists of two more words (the real version), then the occurrences should be taken into account, as well as claim 1. Let the word “later” be met 10,000 times, and the word “because” - 100,000 times. Obviously, the word with the maximum occurrence must be assigned a reduction in the minimum length “n”, and the word “later” - an abbreviation “pm”. Of course, in the case of only two abbreviations, a single letter can also be attributed to the second word. But this case is still far from practical application, and therefore we have applied the abbreviation “PM”, which is more likely.
It is also necessary to take into account that single-letter keys are maximum 33 (without using numbers and symbols as keys), two-letter 33 2 = 1089. And then, with an overestimation. It is unlikely that there will be keys like “” or “yu”.
3. Some keys may be in a hierarchical form. For example, “h” -> “what” -> “something”. In this case, the key can “unfold” both immediately after dialing and after pressing the activator key.
4. The size of the AZ system should be a compromise between the theoretical gain and the time needed to study the system. I did not use AZ widely, but for a deployed system I estimate a decent ceiling of about 1000 cuts. For the system used in everyday life - 100 cuts will be enough for the most frequently used words, phrases, turns.
AutoCorrect reduces the number of characters typed. Those. word length is reduced by L cl- L AZ . Suppose if we replace the word “what” with “h”, then on one word the gain will be L (what) -L (h) = 3-1 = 2 characters. Further, each word has its own specific frequency, expressed as a percentage. Or, if we use a corpus , then it usually provides data on the occurrence of a word - i.e. In general, the number of such words in the body.
For example, the word “what” occurs in the corpus 2210373 times. Then the total gain from a set of all the words "what" in the body will be
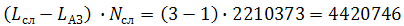
characters.
To calculate the relative gain as a percentage of the total number of characters typed, we need to know the characteristics of the Russian language on average. The total volume of the body is 1.93 8 10 8 words. It would be logical to divide the number of words “what” by the total number of words, but the words have different lengths, which must also be taken into account. The average length of words in Russian, according to the body, is 5.28 characters.
Now we can now calculate the volume of the body in characters. But the body is not the whole text. In fact, there are many service signs in the text, such as a space, a period, a comma, a semicolon, quotes, various signs, numbers, etc. And in order to find the volume of all the text in the corpus we need to multiply the number of characters found by a certain coefficient, which reflects the share of service marks in the Russian-language text. According to his own calculations, approximately, the share of service marks is ~ 20%, with small deviations in one direction or another.
Then the expression for calculating the relative gain in the constant autocorrect of one word takes the form:
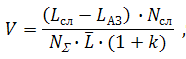
Where - the total number of words in the body,
- the total number of words in the body,
 - average word length in Russian,
- average word length in Russian,
k - the proportion of service characters, numbers and other characters that are not included in the words.
The remaining notation has been deciphered earlier.
Thus, for a single autochange, on the word “what” we get a relative gain equal to

As we can see, for one word the gain is large enough, and many may think that for a developed system of AZ, we can expect a gain of the order of tens of percent. But we used one of the most frequent words. And since the statistics of the occurrence of words is subject to a hyperbolic law, the contribution (frequency) of each subsequent word will decrease significantly. Accordingly, the gain from AZ on such less frequent words will also not be very noticeable.
The lines are sorted by total winnings, obtained from all AZ of the specified word throughout the body.
When choosing the number of words to be AZ, it is necessary to take into account the fact that the time spent studying the AZ system in the first approximation is proportional to the number of abbreviations. Those. the list of AZ must be of a reasonable size, where a compromise is found between the number of AZ and the gain they give. For this it is necessary to construct an approximate graph of the relative gain from the number of AZ.
A priori, we can assume that at first the gain will be significant, and the slope of the curve will be maximum (because the words are more frequent). With a decrease in the frequency of words, the gain from each subsequent word will decrease, the slope of the curve will also decrease. An interesting question is whether there will be saturation? Each AZ will give some gain, but will not the frequency of the word fall so much that each successive increment will tend to zero?
In this section, the main task is to find out to what number of AZs it is necessary to increase the list in order to observe a compromise between relative gain and time for training. Those. it is necessary to identify the transition region where the slope of the payoff curve becomes relatively small, in order to exclude inefficient AZ.
The graph was constructed on the basis of some simplifications for the general analysis. First, the lengths of all abbreviations AZ were assumed to be equal to two characters. Accordingly, words with a length of less than 3 characters were excluded from the list of the most frequent words, since AZ will not benefit from them on such a system. Further, it was assumed that the number of 2-character abbreviations would be no more than 700. This should be close to the truth, even with a somewhat overestimated estimate, since Obviously, absolutely all 1089 digrams cannot be used as abbreviations for obvious reasons (for example, unassociated combinations of letters, as mentioned above). Three-letter abbreviations were not considered at this stage.

The abscissa axis shows the total number of words with AZ, the ordinate axis shows the relative reduction in the number of keystrokes.
As expected, at the very beginning of the graph, for the first 100 cuts, the gain rate is maximum.
We present some data on the schedule:
for the first 10 cuts, the gain is 0.82%,
for the first 20 - 1.24%,
for the first 50 - 2.23%,
for the first 100 - 3.50%,
for the first 200 - 5.37%,
for the first 300 - 6.63%,
for the first 400 - 7.52%,
for the first 500 - 8.33%,
for the first 600 - 9.04%,
for the first 700 - 9.76%.
We calculate the winnings for the 1st, 2nd, 3rd, etc. hundreds of AZ.
For the first hundred, as already mentioned - 3.50%,
for the second - 1.87%,
for the third - 1.26%,
for the fourth - 0.89,
5th - 0.81%,
6th - 0.72%,
7th - 0.72%.
As we can see, the growth rate falls, but then stabilizes. This is a rather unexpected result that does not coincide with the a priori assumption. There is not even a hint of dependency saturation. Apparently, with a sufficient number of cuts, you can provide a big win. For example, at 700 AZ, the gain on the schedule will be 9.76%. This is an acceptable value.
In reality, the gain will be even greater (approximately by 0.2-0.3%), since not only 2-character AZ are used, but also 1-character AZ for the most frequent words. But in the future it will be necessary to use already 3-character abbreviations, therefore, the gain rate will drop slightly, abruptly, relative to that observed at the 6th and 7th hundreds of AZ.
Based on the increase in gain, you can limit the list of AZ, consisting of 500 cuts, which will give a gain of 8.33%. It is also necessary to mention that in everyday life a person uses for correspondence, communication, writing texts a limited set of words that is not at all equivalent in structure to the Russian language corpus. The words that are among the most frequent are used daily. Thus, for everyday tasks that do not include writing scientific articles, the gain will be even more significant, perhaps even at times.
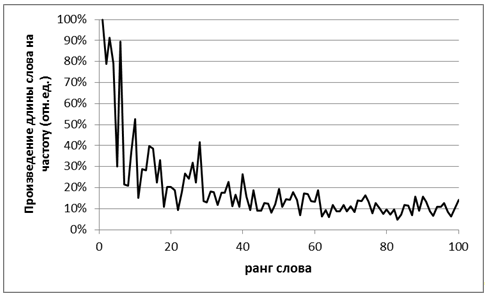
It is possible to suggest why the growth rate of the gain does not slow down constantly. Apparently, the decrease in the frequency of the word is compensated by the fact that the less frequency words are also longer, and the gain is proportional to the product of the difference between the lengths of the word and AZ by the frequency of the word.
For visual analysis, it is necessary to plot the dependence of the product of the word length on its frequency on the rank of the word in the frequency list. The most effective will be AZ words that form peaks relative to the average trend (of course, with some reservations - for example, the word should be long enough).
Autocorrects will not be equally effective for different languages due to the varying complexity of the languages themselves. Printing in those languages that are considered “richer” (in the sense of a larger number of word forms) will be harder to reduce with the help of AZ.
For example, for a number of European languages, apparently, AZ will be more effective than for Russian. In turn, English will probably be more adapted to AZ than German.
Take an example: in Russian there are cases, numbers, in English cases there, but there is a number. For example, the word lamp - lamp.

Perhaps this example is not valid in all cases (for example, the situation for verbs will be different). However, it shows several salient features.
The table shows that for all cases the word "lamp" in the singular and plural numbers for the Russian language will require 12-3 = 9 autochange, and for the English language - only 2 autochangers (singular and plural). Those. with a highly developed, more redundant, with a large number of word forms, the task of assigning autochange is much more complicated.
Also in English, there are fewer letters themselves (26 vs. 33 in Russian), and, therefore, much less combinations of these characters. The maximum possible upper score is 26 2 for English and 33 2 for Russian. In reality, of course, even less is used. For Russian, there are about ~ 700 semantic digrams (two-letter combinations). These circumstances indicate once again that languages whose entropy (redundancy) is higher are worse than auto-replacements.
Finally, the list of the most frequent words in English should also be significantly shorter than for Russian. Those. If, for example, we take 10%, 20% coverage (the most frequent words that make up 10%, 20% of all words), then for English such a list should also be shorter.
From the above examples, it is already clear that the task of constructing a flexible system of automatic replacement for the Russian language is a rather complicated non-trivial task, and it is even more difficult to ensure a good performance increase. In our case, the total performance increase, starting from 10%, will be considered good in the average sense. This is the minimum to which we must strive.
In addition to words, a tangible share of characters is so-called. service, syntactic symbols: space, punctuation, etc. They account for about 20% of the total number of characters.
Let us turn to the list of the most frequent 2-character combinations (for all characters, such tables are usually not, so they need to be done independently, analyzing large amounts of textual information). The most frequent 2-character combination is the combination ",", i.e. comma + space. According to its own data, it accounts for 1.64% of the total number of digits (two-character combinations).
We will estimate the winnings when auto-replacing this combination with one symbol (or one click). You can assign such a combination to the CapsLock key, since it is rarely used in everyday work (of course, you can use other options that are convenient for a particular user).
In the standard YTsUKEN layout, you need to press 2 keys - “Shift” and “.” To type a comma. Thus, a combination that requires 3 presses to be dialed will be dialed with a single tap. Which is equivalent to a reduction of 2 clicks.
In this case, the gain is calculated as follows: if the digram was completely excluded from the set, then the gain would be equal to its frequency. But in our case there is just a reduction in the combination. Those. the gain will be proportional to the relative reduction of the combination and its frequency:

Where - combination length before contraction,
- combination length before contraction,
 - combination length after contraction (including AZ),
- combination length after contraction (including AZ),
 - combination frequency among combinations of the same length.
- combination frequency among combinations of the same length.
Thus, we get the benefit from the reduction “,” up to one click.

In reality, taking into account this single digram will not give an overall picture, since it is necessary to take into account the fact that commas are also excluded in the digits, where they are in the second position.
To calculate the gain in this case, it is convenient to use unary (single-character) statistics, if it was calculated in the process of preparing the tables. In our case, this table was calculated. Despite some variability of statistical characteristics for texts of different genres, their considerable stability is still observed, which makes it possible to speak about a certain statistical structure of the Russian language on average.
In texts that are more or less widely encountered in practice, the fractions of a dot and comma are generally equal and make up approximately 1.5% each. For approximate calculations, the gain from replacing “,” with CapsLock is quite sufficient.
In order to understand how to consider the effectiveness of AZ in this case, we can give an example. Consider a piece of text consisting of three sentences, each with 70 characters. Let each sentence have one capital letter (beginning) and 2 commas. Then the total number of hits will be 219. Use the replacement "," on CapsLock. Further, the gain can be determined as follows: since instead of three clicks for the set “,” we only make one (CapsLock), this is equivalent to excluding a comma from the set, since It requires 2 clicks. Total remains 207 clicks. The gain will be 12 / 219≈5.5%, which is a lot for one combination with AZ. Of course, this is a purely hypothetical example in which the frequency of commas is too high.
From here, by the way, another aspect of the use of AZ follows - competitive, because on a short light text, with frequency words, you can very significantly raise the result - up to 20-25% (and even higher). As mentioned at the very beginning of the article, when using the AZ should be a separate test.
In general, in order to estimate the real gain, it is necessary to recalculate the statistics of symbols in the statistics of clicks, i.e. the characters do not take into account such frequently pressed key as “Shift”. We should also mention “Enter”, but in the usual analysis of arrays of text data this key (equivalent to a paragraph or transition to a new line) is usually not taken into account. And in this article this question is not covered.
To count the number of keystrokes of the “Shift” key when typing on the YTZUKEN standard layout, you need to know the proportion of capital letters, as well as the proportion of the characters “,” and “!”, “”, ”“, ”,“ No. ”,“; ”,“ % ",": ","? "," * "," (",") "," _ "," + ", I.e. all recruited on the fourth row (digital) using Shift. For the first approximation (which, however, should be sufficiently accurate), we assume that the shares of characters typed on the fourth row are approximately equal to zero (to a sufficient extent this corresponds to reality).
Capital letters in most cases are typed only at the beginning of sentences. You can add one upper case in the middle of a sentence to account for a proper name, if used. Let us simply say that 1 sentence contains 2 capital letters. The total length of the sentence in characters, according to the statistics of the Russian language corpus, will be

Where - The average number of words in the sentence.
- The average number of words in the sentence.
If we take into account that the comma makes up 1.5%, then this corresponds to approximately one comma per sentence: 65.8 ,8 0.015≈0.9. In addition, there are an average of 2 capital letters. That is, it turns out that there are 3 more clicks than symbols or 68.8 clicks on 1 sentence on average. Of these 68.8 clicks, 2 clicks are comma-separated. As mentioned earlier, the AZ "," on CapsLock is equivalent to excluding a comma from the set, therefore the gain from such AZ in the clicks will be:
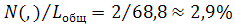
Compared to the gains that have been received in words, this is a very tangible increase from just one combination. In principle, this was to be expected, because the more often the combination, the greater will be the gain from the reduction of such a combination (with sufficient length or number of clicks). Of course, the minimum that can be shortened is two-character combinations. And the individual letters are no longer abbreviated. Here you can consider different levels of aggregation: 2-character, 3-character, etc. After 4-character it is more reasonable to consider the level of words, and then the phraseological level. Of course, there are some frequency combinations of letters, symbols, words, except for those that have already been considered by us.
What other common syntactic characters can improve performance? For example, you can see that in the overwhelming majority of cases there is a space after the dot (except for the ellipsis, which is rare, and it can also be assigned to a separate key, at least in the extra layer). Also, the space always goes after the dash (but not after the hyphen). In principle, in most editors, a dash and a hyphen are typed with the same "- / _" key, but, for example, in the Word, a dash is set if there are spaces before and after it.
It is proposed to put the autospace after the dash, i.e. the combination "-" puts an extra space. This will also save a little on the set of service marks. It is also possible to put autospaces after such common characters as the colon “:” and the semicolon “;”. You can put the auto-space and after the other signs of the end of the sentence - interrogative and exclamatory "?" And "!".
There are cases, but very rarely, when it is necessary to type several identical characters in a row. For this case, you can provide the following AZ. Suppose you need to type five exclamation marks: "!!!!!", for this will be used AZ of the form "5!". For the rarely occurring dots, you can also provide a separate key, for example, “e”, since the letters “e” and “e” often do not differ and “e” remains unused (I ask you not to throw stones at me for supporters of the universal use of “e”, since AZ can be assigned to any other key). In principle, everyone can define for himself unused keys and assign the most effective AZ to them.
Consider the auto space after the point, and the gain from such a function. As mentioned, the probability of a dot in the text is 1.5%. Each sentence has approximately one point, after which there is a space. Except when using dots "...", which are very rare. The point and the space after it make up about 1.5% 2 = 3% of all characters. Using the automated statement of the space after the point, we exclude half of these 3%, i.e. we get another 1.5% winnings. This is a good result for one function. Considering auto spaces after other signs - interrogative and exclamatory, it is possible to increase the gain even more. But, as a rule, the share of such signs is very small in comparison with a period and it is possible not to consider it as significant.
A rather frequent combination is "-" (space and dash), followed by another space. If you set the auto-space after this combination, the gain in symbols will be equal to the number of such combinations, respectively, the percentage gain will be equal to the share of such combinations in% of the total number of combinations of a given length.
You can write a general formula for calculating the gain from the reduction of any combination, knowing its share (frequency) in the general structure of the language, including syntactic symbols:

where k is the proportion of this combination among all combinations of the same length; it can be a digram (2 characters), a trigram (3 characters), n-gram (length n characters); in our case we deal with digrams;
n- the number of characters for which you can reduce the text after meeting this combination; this formulation takes into account both the possibility of AZ, and the autogap and similar functions;
V additional - an additional benefit from the reduction of all other combinations, which include excluded characters; in each case must be calculated separately.
As already mentioned, AZ can be used not only at the level of words, but also at the level of phrases, phraseological level. There are stable phrases, for example, some of them: “how are you”, “like life”, “good afternoon”, “because”, “despite”, “by all means”, etc .; less frequent - “in any case,” “based on the foregoing,” “follows from what has been said.”
Everyone has his own most frequent phrases that he uses in conversation and business communication, in correspondence. Based on these stable phrases, you can develop an addition to the AZ system for them. In each particular case, consistency with the existing AZ system should be taken into account and the gain provided by the auto-replacement of each new combination should be calculated.
But much more frequent than words or phrases are n-grams (n-character combinations with a small n, n <5). For example, one can single out such frequent combinations at the end of words, such as “ny”, “ny”, “tsya”, “tsya”. You can provide AZ for them.
For example, if you do not use the key with the letter "" (forgive me supporters of its use), then assign one of the AZ to this key. And the combination of this key with Shift will give another combination, i.e. Shitf + = tsya; e = tsya Again, each of these combinations should be considered separately, in accordance with their frequency and consistency with the already-made system of abbreviations. It is important that there is no confusion, and there are no similar writing abbreviations on words that are written entirely in completely different ways.
Next, you can link the system AZ and the procedure for optimizing the layout.
The optimization procedure described in the previous article has as a input parameter a system of penalties and statistics of digrams. The system of penalties / incentives will remain the same, and as a result of the use of the AZ system, the statistics of digrams will somehow change.
Accordingly, the optimal layout for some system AZ will differ from the optimal layout used without AZ. It is necessary to recalculate changes in statistics for each position of autochange — for each word with AZ, combinations, combinations of syntactic symbols.
To calculate the change in the frequency of a combination, one needs to consider a specific example, from which general patterns can then be derived. Take the word "more." The frequency of occurrence of the word in the body - 124201 times. The total number of words of the corpus= 1.93 ∙ 10 8 . The average word length is ≈5.28 characters. The proportion of syntactic symbols is k ≈ 20%. Now we have all the data to count the number of characters in the package. Such a recalculation is needed to bring the statistics of words to the statistics of digrams (and the number of digrams in the text is equal to the number of characters in it minus 1). The total number of characters in the body:
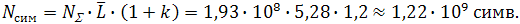
Knowing the number of occurrences of a specific word in the body, we automatically know the number of occurrences of each digram from this word in the body. Those.for the word “more” it will not be the total frequency of the digits “bo”, “ol”, “eh”, etc., but only the frequency of the digrams “bo”, “ol”, “eh”, ... of this word. This frequency will be written:

Where - the frequency of any digram of the word in question;
- the frequency of any digram of the word in question;
 - the frequency of occurrence of the word in the body;
- the frequency of occurrence of the word in the body;
 - the total number of shell symbols found above.
- the total number of shell symbols found above.
For example, let's calculate the frequencies of the digrams introduced into the body by the word “more”:
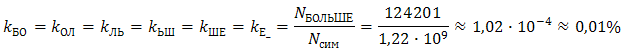
When using the AZ, these frequencies will be subtracted from the total number of the corresponding digrams, and some new ones introduced by the abbreviation will be added.
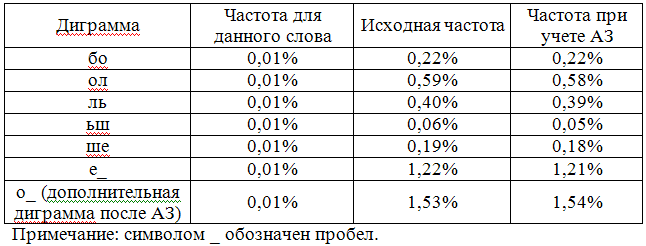
To be specific, assume that the word “more” will be shortened when typing to “bo”. Then the frequencies of the digits “ol”, “eh”, “ush”, “above”, “e” will be subtracted from the general table of frequencies of the digrams. The combination of "bo" remains unchanged, and it is not necessary to recalculate it. But a new digram will be added, which previously did not exist in the word “o”.
Its frequency will be the same as the others (i.e. the number of its occurrences in the body is equal to the frequency of occurrences of the word) - 0.01%. The value of this frequency will be added to the general table of frequencies of digrams. To complete the review, we calculate the resulting frequencies obtained only for AZ “bo” = “more”.
If strictly, then you must also take into account the fact that the amount of typed text with an increase in the number of AZ will decrease. Those.it is better to consider the effect in absolute values attributable to the text of any volume. Thus, it will be more accurate if we consider not the relative changes (percentages), but the absolute values: how many digrams of this type were in the text and how many became. Conversion to relative values is needed only at the final stage of calculation, before starting the optimization procedure.
Since the amount of data is quite large, this stage (as well as all), needs partial or complete automation.
The described procedure should be repeated for each autochange. As a result, we get the recalculated statistics of the digrams, which can be used as an input variable for the layout optimization procedure.
It is possible to achieve the use of the system, both in terms of convenience and speed.
For practical use of AutoCorrect, you can use the popular programs AutoHotKey or PuntoSwitcher .
CAN see the You AutoHotKey program documentation found here , some of the features found here .
Lines of a common script with AZ:
the word "time" will appear after pressing "in" and the activator key, usually a space.
in this case, the word “time” will appear immediately after dialing “c”.
; - optional character, separates comments.
As an afterword, I note that this article, like the previous one, is mainly academic. Practical application is limited only by professional or semi-professional typesetters, which are extremely small in the total mass of PC users. Nevertheless, I hope that some of the most convenient replacements are already used or can be used by almost everyone. Constructive criticism on calculations and presentation logic is welcome.
Here we will go in a slightly different way and consider the possibility of reducing the total number of keystrokes (except for using chord set methods and stenotypes , because this is another big topic).
At once I will make a reservation that the use of a stenotype together with the knowledge of shorthand, of course, will have a much greater effect in terms of productivity gains. But the method discussed below is easy to implement (there is no need for special equipment, complex software) and takes less time to study (remembering a few dozen abbreviations is usually easy).
')
What is autoCorrect?
AutoCorrect (AZ) will be called a way of printing a combination of letters / words / phrases, in which the source text is programmatically reassigned to other shortcuts. For performance reasons, the typed key combination (let's call it a key or abbreviation) should have a minimum length relative to the original sequence of letters. The difference in the number of keystrokes when typing a combination in its original form and when typing with abbreviations will be a gain on this combination due to AZ.
For example, you need to type in such a frequently used word as “because.” If the abbreviation looks like "n", then the gain when typing only one word will be 5 characters.
Note that in the world this practice has long existed. Even competitions are held in various offsets - using the system of reductions and without it. In the first case, the world record in the 30-minute interval is 955 beats / min , in the second - 821 beats / min . Both records set the infamous Helena Matushkova.
The most developed system of abbreviations for the Czech language, called Zavisie (ZAVpis). There is even a training site , and there is information that mastering the system of cuts begins only after acquiring a sufficiently high level of blind typing skill.
As we see from the ratio of numbers 955 and 821, the gain when using AZ is not that high (~ 16%). However, in this case, the system AZ is adapted to the average structure of the language, and does not take into account the specific words, features characteristic of different areas of knowledge. The user’s lexicon used in communication and everyday correspondence are also not taken into account. In everyday life or a narrow practical field, the vocabulary is much smaller in volume, and the effectiveness of the AZ system, tailored to specific needs, can increase significantly.
The choice of words and other issues create a system AutoCorrect
First, you need to decide for what purposes the autochange system is created. If the AZ system is required to reduce the time for recruiting an average sentence in Russian, then it is necessary to take into account the structure of the language as a whole. Here you can go two ways.
One of them is to personally collect a large sample of texts that adequately represent a language (usually the size of such a sample is from several hundred megabytes) and analyze them statistically to highlight the most frequent words, combinations of letters, symbols. Then, based on the analysis, build statistical tables.
Note that this method is more suitable for the case when the AZ system is created for itself, under its most frequently used words - in articles, in business correspondence, when communicating in a chat, on a forum, etc.
The second is to use ready-made tables. Of course, such tables are already in a usable form. This implies the use of the National Corpus of the Russian language and frequency dictionaries of the Russian language (one of the most famous is the Sharov frequency dictionary: [1] ; [2] ).
A list of the 100 most frequent word forms can be viewed here .
It seems logical that the most frequent words should be subjected to autocaps first, and the longest among them. In general, all language statistics are subject to Zipf's law . This is a generalized hyperbolic distribution of ranked statisticians, no matter at what level - whether it is the level of individual letters or symbols; letter combinations (n-grams); word level; phraseological level.
Such statistics, along with Gaussian, very often appear in the world around us, and were found in various fields of knowledge. For example, the distribution of people by income (Pareto), the distribution of scientists by productivity (Lotka), the distribution of articles by journals (Bradford), the distribution of settlements by population, the distribution of earthquakes by intensity, etc. In general, such statistics arise from the strong interdependence of events in the system (analogue of positive feedback), a type of chain reaction, as a result of which both extreme amplification and strong weakening can occur.
For us, it is important that the peaks, positive deviations from the hyperbolic trend will just indicate the words that must first enter the AZ system. In this case, the greatest contribution to the final effectiveness of the system will be made by the first few hundred most frequent words.
Consider other features of the construction of the system AZ:
1. Keys must be unique (do not coincide with words and other keys), minimal in length, easily remembered. Such keys should consist either of the first few letters of the word, or of the first and last.
2. The purpose of the keys (their length, letters, symbols used) will depend on the size of the AZ system itself. Consider the simplest example. Suppose we want to create a system for a single word “later”, it is obvious that the best option is the abbreviation “n”. If the system consists of two more words (the real version), then the occurrences should be taken into account, as well as claim 1. Let the word “later” be met 10,000 times, and the word “because” - 100,000 times. Obviously, the word with the maximum occurrence must be assigned a reduction in the minimum length “n”, and the word “later” - an abbreviation “pm”. Of course, in the case of only two abbreviations, a single letter can also be attributed to the second word. But this case is still far from practical application, and therefore we have applied the abbreviation “PM”, which is more likely.
It is also necessary to take into account that single-letter keys are maximum 33 (without using numbers and symbols as keys), two-letter 33 2 = 1089. And then, with an overestimation. It is unlikely that there will be keys like “” or “yu”.
3. Some keys may be in a hierarchical form. For example, “h” -> “what” -> “something”. In this case, the key can “unfold” both immediately after dialing and after pressing the activator key.
4. The size of the AZ system should be a compromise between the theoretical gain and the time needed to study the system. I did not use AZ widely, but for a deployed system I estimate a decent ceiling of about 1000 cuts. For the system used in everyday life - 100 cuts will be enough for the most frequently used words, phrases, turns.
Calculate the winnings from using AutoCorrect
AutoCorrect reduces the number of characters typed. Those. word length is reduced by L cl- L AZ . Suppose if we replace the word “what” with “h”, then on one word the gain will be L (what) -L (h) = 3-1 = 2 characters. Further, each word has its own specific frequency, expressed as a percentage. Or, if we use a corpus , then it usually provides data on the occurrence of a word - i.e. In general, the number of such words in the body.
For example, the word “what” occurs in the corpus 2210373 times. Then the total gain from a set of all the words "what" in the body will be
characters.
To calculate the relative gain as a percentage of the total number of characters typed, we need to know the characteristics of the Russian language on average. The total volume of the body is 1.93 8 10 8 words. It would be logical to divide the number of words “what” by the total number of words, but the words have different lengths, which must also be taken into account. The average length of words in Russian, according to the body, is 5.28 characters.
Now we can now calculate the volume of the body in characters. But the body is not the whole text. In fact, there are many service signs in the text, such as a space, a period, a comma, a semicolon, quotes, various signs, numbers, etc. And in order to find the volume of all the text in the corpus we need to multiply the number of characters found by a certain coefficient, which reflects the share of service marks in the Russian-language text. According to his own calculations, approximately, the share of service marks is ~ 20%, with small deviations in one direction or another.
Then the expression for calculating the relative gain in the constant autocorrect of one word takes the form:
Where
- the total number of words in the body, - average word length in Russian,k - the proportion of service characters, numbers and other characters that are not included in the words.
The remaining notation has been deciphered earlier.
Thus, for a single autochange, on the word “what” we get a relative gain equal to
As we can see, for one word the gain is large enough, and many may think that for a developed system of AZ, we can expect a gain of the order of tens of percent. But we used one of the most frequent words. And since the statistics of the occurrence of words is subject to a hyperbolic law, the contribution (frequency) of each subsequent word will decrease significantly. Accordingly, the gain from AZ on such less frequent words will also not be very noticeable.
Begin Table Abbreviations
The lines are sorted by total winnings, obtained from all AZ of the specified word throughout the body.
The impact of system volume autochange on its effectiveness
When choosing the number of words to be AZ, it is necessary to take into account the fact that the time spent studying the AZ system in the first approximation is proportional to the number of abbreviations. Those. the list of AZ must be of a reasonable size, where a compromise is found between the number of AZ and the gain they give. For this it is necessary to construct an approximate graph of the relative gain from the number of AZ.
A priori, we can assume that at first the gain will be significant, and the slope of the curve will be maximum (because the words are more frequent). With a decrease in the frequency of words, the gain from each subsequent word will decrease, the slope of the curve will also decrease. An interesting question is whether there will be saturation? Each AZ will give some gain, but will not the frequency of the word fall so much that each successive increment will tend to zero?
In this section, the main task is to find out to what number of AZs it is necessary to increase the list in order to observe a compromise between relative gain and time for training. Those. it is necessary to identify the transition region where the slope of the payoff curve becomes relatively small, in order to exclude inefficient AZ.
The graph was constructed on the basis of some simplifications for the general analysis. First, the lengths of all abbreviations AZ were assumed to be equal to two characters. Accordingly, words with a length of less than 3 characters were excluded from the list of the most frequent words, since AZ will not benefit from them on such a system. Further, it was assumed that the number of 2-character abbreviations would be no more than 700. This should be close to the truth, even with a somewhat overestimated estimate, since Obviously, absolutely all 1089 digrams cannot be used as abbreviations for obvious reasons (for example, unassociated combinations of letters, as mentioned above). Three-letter abbreviations were not considered at this stage.
The abscissa axis shows the total number of words with AZ, the ordinate axis shows the relative reduction in the number of keystrokes.
As expected, at the very beginning of the graph, for the first 100 cuts, the gain rate is maximum.
We present some data on the schedule:
for the first 10 cuts, the gain is 0.82%,
for the first 20 - 1.24%,
for the first 50 - 2.23%,
for the first 100 - 3.50%,
for the first 200 - 5.37%,
for the first 300 - 6.63%,
for the first 400 - 7.52%,
for the first 500 - 8.33%,
for the first 600 - 9.04%,
for the first 700 - 9.76%.
We calculate the winnings for the 1st, 2nd, 3rd, etc. hundreds of AZ.
For the first hundred, as already mentioned - 3.50%,
for the second - 1.87%,
for the third - 1.26%,
for the fourth - 0.89,
5th - 0.81%,
6th - 0.72%,
7th - 0.72%.
As we can see, the growth rate falls, but then stabilizes. This is a rather unexpected result that does not coincide with the a priori assumption. There is not even a hint of dependency saturation. Apparently, with a sufficient number of cuts, you can provide a big win. For example, at 700 AZ, the gain on the schedule will be 9.76%. This is an acceptable value.
In reality, the gain will be even greater (approximately by 0.2-0.3%), since not only 2-character AZ are used, but also 1-character AZ for the most frequent words. But in the future it will be necessary to use already 3-character abbreviations, therefore, the gain rate will drop slightly, abruptly, relative to that observed at the 6th and 7th hundreds of AZ.
Based on the increase in gain, you can limit the list of AZ, consisting of 500 cuts, which will give a gain of 8.33%. It is also necessary to mention that in everyday life a person uses for correspondence, communication, writing texts a limited set of words that is not at all equivalent in structure to the Russian language corpus. The words that are among the most frequent are used daily. Thus, for everyday tasks that do not include writing scientific articles, the gain will be even more significant, perhaps even at times.
It is possible to suggest why the growth rate of the gain does not slow down constantly. Apparently, the decrease in the frequency of the word is compensated by the fact that the less frequency words are also longer, and the gain is proportional to the product of the difference between the lengths of the word and AZ by the frequency of the word.
For visual analysis, it is necessary to plot the dependence of the product of the word length on its frequency on the rank of the word in the frequency list. The most effective will be AZ words that form peaks relative to the average trend (of course, with some reservations - for example, the word should be long enough).
On the comparative effectiveness of autoexchange for Russian and English
Autocorrects will not be equally effective for different languages due to the varying complexity of the languages themselves. Printing in those languages that are considered “richer” (in the sense of a larger number of word forms) will be harder to reduce with the help of AZ.
For example, for a number of European languages, apparently, AZ will be more effective than for Russian. In turn, English will probably be more adapted to AZ than German.
Take an example: in Russian there are cases, numbers, in English cases there, but there is a number. For example, the word lamp - lamp.
Perhaps this example is not valid in all cases (for example, the situation for verbs will be different). However, it shows several salient features.
The table shows that for all cases the word "lamp" in the singular and plural numbers for the Russian language will require 12-3 = 9 autochange, and for the English language - only 2 autochangers (singular and plural). Those. with a highly developed, more redundant, with a large number of word forms, the task of assigning autochange is much more complicated.
Also in English, there are fewer letters themselves (26 vs. 33 in Russian), and, therefore, much less combinations of these characters. The maximum possible upper score is 26 2 for English and 33 2 for Russian. In reality, of course, even less is used. For Russian, there are about ~ 700 semantic digrams (two-letter combinations). These circumstances indicate once again that languages whose entropy (redundancy) is higher are worse than auto-replacements.
Finally, the list of the most frequent words in English should also be significantly shorter than for Russian. Those. If, for example, we take 10%, 20% coverage (the most frequent words that make up 10%, 20% of all words), then for English such a list should also be shorter.
From the above examples, it is already clear that the task of constructing a flexible system of automatic replacement for the Russian language is a rather complicated non-trivial task, and it is even more difficult to ensure a good performance increase. In our case, the total performance increase, starting from 10%, will be considered good in the average sense. This is the minimum to which we must strive.
Using AutoCorrect for Service Symbols
In addition to words, a tangible share of characters is so-called. service, syntactic symbols: space, punctuation, etc. They account for about 20% of the total number of characters.
Let us turn to the list of the most frequent 2-character combinations (for all characters, such tables are usually not, so they need to be done independently, analyzing large amounts of textual information). The most frequent 2-character combination is the combination ",", i.e. comma + space. According to its own data, it accounts for 1.64% of the total number of digits (two-character combinations).
We will estimate the winnings when auto-replacing this combination with one symbol (or one click). You can assign such a combination to the CapsLock key, since it is rarely used in everyday work (of course, you can use other options that are convenient for a particular user).
In the standard YTsUKEN layout, you need to press 2 keys - “Shift” and “.” To type a comma. Thus, a combination that requires 3 presses to be dialed will be dialed with a single tap. Which is equivalent to a reduction of 2 clicks.
In this case, the gain is calculated as follows: if the digram was completely excluded from the set, then the gain would be equal to its frequency. But in our case there is just a reduction in the combination. Those. the gain will be proportional to the relative reduction of the combination and its frequency:
Where
- combination length before contraction,- combination length after contraction (including AZ),- combination frequency among combinations of the same length.Thus, we get the benefit from the reduction “,” up to one click.
In reality, taking into account this single digram will not give an overall picture, since it is necessary to take into account the fact that commas are also excluded in the digits, where they are in the second position.
To calculate the gain in this case, it is convenient to use unary (single-character) statistics, if it was calculated in the process of preparing the tables. In our case, this table was calculated. Despite some variability of statistical characteristics for texts of different genres, their considerable stability is still observed, which makes it possible to speak about a certain statistical structure of the Russian language on average.
In texts that are more or less widely encountered in practice, the fractions of a dot and comma are generally equal and make up approximately 1.5% each. For approximate calculations, the gain from replacing “,” with CapsLock is quite sufficient.
In order to understand how to consider the effectiveness of AZ in this case, we can give an example. Consider a piece of text consisting of three sentences, each with 70 characters. Let each sentence have one capital letter (beginning) and 2 commas. Then the total number of hits will be 219. Use the replacement "," on CapsLock. Further, the gain can be determined as follows: since instead of three clicks for the set “,” we only make one (CapsLock), this is equivalent to excluding a comma from the set, since It requires 2 clicks. Total remains 207 clicks. The gain will be 12 / 219≈5.5%, which is a lot for one combination with AZ. Of course, this is a purely hypothetical example in which the frequency of commas is too high.
From here, by the way, another aspect of the use of AZ follows - competitive, because on a short light text, with frequency words, you can very significantly raise the result - up to 20-25% (and even higher). As mentioned at the very beginning of the article, when using the AZ should be a separate test.
In general, in order to estimate the real gain, it is necessary to recalculate the statistics of symbols in the statistics of clicks, i.e. the characters do not take into account such frequently pressed key as “Shift”. We should also mention “Enter”, but in the usual analysis of arrays of text data this key (equivalent to a paragraph or transition to a new line) is usually not taken into account. And in this article this question is not covered.
To count the number of keystrokes of the “Shift” key when typing on the YTZUKEN standard layout, you need to know the proportion of capital letters, as well as the proportion of the characters “,” and “!”, “”, ”“, ”,“ No. ”,“; ”,“ % ",": ","? "," * "," (",") "," _ "," + ", I.e. all recruited on the fourth row (digital) using Shift. For the first approximation (which, however, should be sufficiently accurate), we assume that the shares of characters typed on the fourth row are approximately equal to zero (to a sufficient extent this corresponds to reality).
Capital letters in most cases are typed only at the beginning of sentences. You can add one upper case in the middle of a sentence to account for a proper name, if used. Let us simply say that 1 sentence contains 2 capital letters. The total length of the sentence in characters, according to the statistics of the Russian language corpus, will be
Where
- The average number of words in the sentence.If we take into account that the comma makes up 1.5%, then this corresponds to approximately one comma per sentence: 65.8 ,8 0.015≈0.9. In addition, there are an average of 2 capital letters. That is, it turns out that there are 3 more clicks than symbols or 68.8 clicks on 1 sentence on average. Of these 68.8 clicks, 2 clicks are comma-separated. As mentioned earlier, the AZ "," on CapsLock is equivalent to excluding a comma from the set, therefore the gain from such AZ in the clicks will be:
Compared to the gains that have been received in words, this is a very tangible increase from just one combination. In principle, this was to be expected, because the more often the combination, the greater will be the gain from the reduction of such a combination (with sufficient length or number of clicks). Of course, the minimum that can be shortened is two-character combinations. And the individual letters are no longer abbreviated. Here you can consider different levels of aggregation: 2-character, 3-character, etc. After 4-character it is more reasonable to consider the level of words, and then the phraseological level. Of course, there are some frequency combinations of letters, symbols, words, except for those that have already been considered by us.
What other common syntactic characters can improve performance? For example, you can see that in the overwhelming majority of cases there is a space after the dot (except for the ellipsis, which is rare, and it can also be assigned to a separate key, at least in the extra layer). Also, the space always goes after the dash (but not after the hyphen). In principle, in most editors, a dash and a hyphen are typed with the same "- / _" key, but, for example, in the Word, a dash is set if there are spaces before and after it.
It is proposed to put the autospace after the dash, i.e. the combination "-" puts an extra space. This will also save a little on the set of service marks. It is also possible to put autospaces after such common characters as the colon “:” and the semicolon “;”. You can put the auto-space and after the other signs of the end of the sentence - interrogative and exclamatory "?" And "!".
There are cases, but very rarely, when it is necessary to type several identical characters in a row. For this case, you can provide the following AZ. Suppose you need to type five exclamation marks: "!!!!!", for this will be used AZ of the form "5!". For the rarely occurring dots, you can also provide a separate key, for example, “e”, since the letters “e” and “e” often do not differ and “e” remains unused (I ask you not to throw stones at me for supporters of the universal use of “e”, since AZ can be assigned to any other key). In principle, everyone can define for himself unused keys and assign the most effective AZ to them.
Consider the auto space after the point, and the gain from such a function. As mentioned, the probability of a dot in the text is 1.5%. Each sentence has approximately one point, after which there is a space. Except when using dots "...", which are very rare. The point and the space after it make up about 1.5% 2 = 3% of all characters. Using the automated statement of the space after the point, we exclude half of these 3%, i.e. we get another 1.5% winnings. This is a good result for one function. Considering auto spaces after other signs - interrogative and exclamatory, it is possible to increase the gain even more. But, as a rule, the share of such signs is very small in comparison with a period and it is possible not to consider it as significant.
A rather frequent combination is "-" (space and dash), followed by another space. If you set the auto-space after this combination, the gain in symbols will be equal to the number of such combinations, respectively, the percentage gain will be equal to the share of such combinations in% of the total number of combinations of a given length.
You can write a general formula for calculating the gain from the reduction of any combination, knowing its share (frequency) in the general structure of the language, including syntactic symbols:
where k is the proportion of this combination among all combinations of the same length; it can be a digram (2 characters), a trigram (3 characters), n-gram (length n characters); in our case we deal with digrams;
n- the number of characters for which you can reduce the text after meeting this combination; this formulation takes into account both the possibility of AZ, and the autogap and similar functions;
V additional - an additional benefit from the reduction of all other combinations, which include excluded characters; in each case must be calculated separately.
AutoCorrect at the level of individual combinations of letters and words
As already mentioned, AZ can be used not only at the level of words, but also at the level of phrases, phraseological level. There are stable phrases, for example, some of them: “how are you”, “like life”, “good afternoon”, “because”, “despite”, “by all means”, etc .; less frequent - “in any case,” “based on the foregoing,” “follows from what has been said.”
Everyone has his own most frequent phrases that he uses in conversation and business communication, in correspondence. Based on these stable phrases, you can develop an addition to the AZ system for them. In each particular case, consistency with the existing AZ system should be taken into account and the gain provided by the auto-replacement of each new combination should be calculated.
But much more frequent than words or phrases are n-grams (n-character combinations with a small n, n <5). For example, one can single out such frequent combinations at the end of words, such as “ny”, “ny”, “tsya”, “tsya”. You can provide AZ for them.
For example, if you do not use the key with the letter "" (forgive me supporters of its use), then assign one of the AZ to this key. And the combination of this key with Shift will give another combination, i.e. Shitf + = tsya; e = tsya Again, each of these combinations should be considered separately, in accordance with their frequency and consistency with the already-made system of abbreviations. It is important that there is no confusion, and there are no similar writing abbreviations on words that are written entirely in completely different ways.
Optimization of layouts taking into account autocheck
Next, you can link the system AZ and the procedure for optimizing the layout.
The optimization procedure described in the previous article has as a input parameter a system of penalties and statistics of digrams. The system of penalties / incentives will remain the same, and as a result of the use of the AZ system, the statistics of digrams will somehow change.
Accordingly, the optimal layout for some system AZ will differ from the optimal layout used without AZ. It is necessary to recalculate changes in statistics for each position of autochange — for each word with AZ, combinations, combinations of syntactic symbols.
To calculate the change in the frequency of a combination, one needs to consider a specific example, from which general patterns can then be derived. Take the word "more." The frequency of occurrence of the word in the body - 124201 times. The total number of words of the corpus
= 1.93 ∙ 10 8 . The average word length is ≈5.28 characters. The proportion of syntactic symbols is k ≈ 20%. Now we have all the data to count the number of characters in the package. Such a recalculation is needed to bring the statistics of words to the statistics of digrams (and the number of digrams in the text is equal to the number of characters in it minus 1). The total number of characters in the body:Knowing the number of occurrences of a specific word in the body, we automatically know the number of occurrences of each digram from this word in the body. Those.for the word “more” it will not be the total frequency of the digits “bo”, “ol”, “eh”, etc., but only the frequency of the digrams “bo”, “ol”, “eh”, ... of this word. This frequency will be written:
Where
- the frequency of any digram of the word in question;- the frequency of occurrence of the word in the body;- the total number of shell symbols found above.For example, let's calculate the frequencies of the digrams introduced into the body by the word “more”:
When using the AZ, these frequencies will be subtracted from the total number of the corresponding digrams, and some new ones introduced by the abbreviation will be added.
To be specific, assume that the word “more” will be shortened when typing to “bo”. Then the frequencies of the digits “ol”, “eh”, “ush”, “above”, “e” will be subtracted from the general table of frequencies of the digrams. The combination of "bo" remains unchanged, and it is not necessary to recalculate it. But a new digram will be added, which previously did not exist in the word “o”.
Its frequency will be the same as the others (i.e. the number of its occurrences in the body is equal to the frequency of occurrences of the word) - 0.01%. The value of this frequency will be added to the general table of frequencies of digrams. To complete the review, we calculate the resulting frequencies obtained only for AZ “bo” = “more”.
If strictly, then you must also take into account the fact that the amount of typed text with an increase in the number of AZ will decrease. Those.it is better to consider the effect in absolute values attributable to the text of any volume. Thus, it will be more accurate if we consider not the relative changes (percentages), but the absolute values: how many digrams of this type were in the text and how many became. Conversion to relative values is needed only at the final stage of calculation, before starting the optimization procedure.
Since the amount of data is quite large, this stage (as well as all), needs partial or complete automation.
The described procedure should be repeated for each autochange. As a result, we get the recalculated statistics of the digrams, which can be used as an input variable for the layout optimization procedure.
It is possible to achieve the use of the system, both in terms of convenience and speed.
Implementation AutoCorrect
For practical use of AutoCorrect, you can use the popular programs AutoHotKey or PuntoSwitcher .
CAN see the You AutoHotKey program documentation found here , some of the features found here .
Lines of a common script with AZ:
::::; the word "time" will appear after pressing "in" and the activator key, usually a space.
::; in this case, the word “time” will appear immediately after dialing “c”.
:*:::; - , . ; - optional character, separates comments.
As an afterword, I note that this article, like the previous one, is mainly academic. Practical application is limited only by professional or semi-professional typesetters, which are extremely small in the total mass of PC users. Nevertheless, I hope that some of the most convenient replacements are already used or can be used by almost everyone. Constructive criticism on calculations and presentation logic is welcome.
Source: https://habr.com/ru/post/211827/
All Articles