Clouds at Zeppelin: the experience of creating a cloud service Mail.Ru Group

We started working on Mail.Ru Cloud in June 2012. In a year and a half, we have come a long and thorny path from the first prototype to a public service that can withstand loads over 60 Gbit / s. Today we want to share with you a story about how it was.
Do you remember how it all started
It all started with a single developer virtual machine that started the first prototype of the metadata storage daemon. Then everything was crystal simple. We stored logs of actions of each user (creation of a directory, creation of a file, deletion of a file, etc.), which resulted in the final state of its virtual file system. The bodies of the files were stored in a common directory for all users. This system, written on the knee for two weeks, worked for several months.
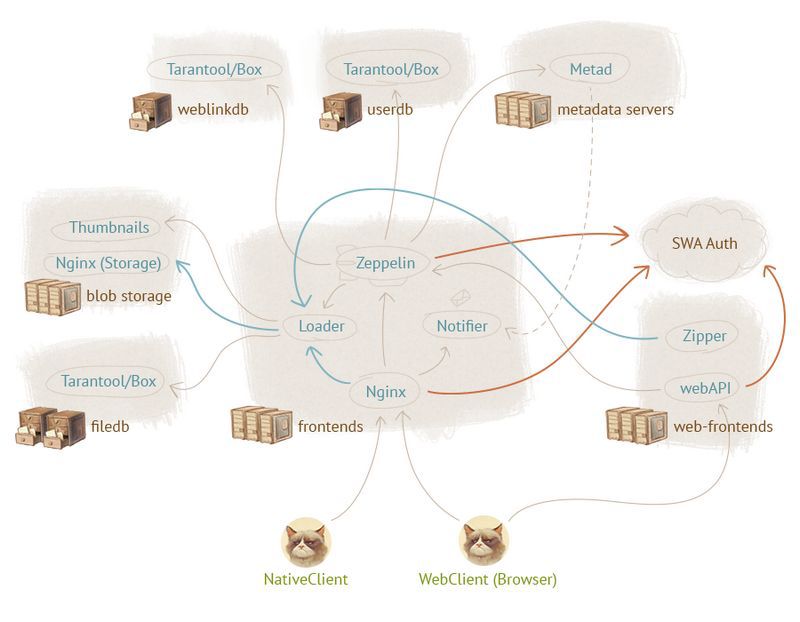
')
Metadata server
The prototype approached the product version when we wrote our server to store metadata. It can be called advanced key-value storage, where the key is a twelve-byte tree identifier, and the value is a hierarchy of files and directories of an individual user. Using this tree, the file system is emulated (files and directories are added and deleted). To communicate with the service, the first client used a binary session-oriented protocol: a TCP connection was established, notifications about changes were pushed into it, so that two clients could synchronize and clients wrote commands to this supported connection. This prototype worked for another couple of months.
Of course, we were well aware that clients could not afford to keep a permanent TCP connection to the server. Moreover, at that time we did not have any authentication: we believed the client. It was good for development, but completely unacceptable for production.
HTTP wrapper
The next step was to wrap the individual packages of which our binary protocol consisted of HTTP headers, and began to communicate with the server via HTTP, telling in the query string which tree we want to work with. This wrapper is currently implemented using the Nginx module, which supports a TCP connection to the metadata server; the server knows nothing about HTTP.
Such a solution, of course, still did not give us an authorization check, but the client could already work in conditions close to real ones: for example, during a short-term disconnection, everything did not go to ashes.
Also at this stage we are faced with the need for third-party HTTP-notifier. We took Nginx HTTP Push-Module - this is the Comet-server for notification - and began to send it notifications from our server metadata.
When it didn’t just work, but it became normal to experience the crashes and restarts of the Comet server, we proceeded to the next stage.
Authorization
The next step was the introduction of authorization both on the server and on the client. Armed with Nginx, the source of the module that produces similar actions, and the manual for working with our internal authorization and session verification interface, we wrote an authorization module. The implemented module received a user cookie at the entrance, and at the output calculated the identifier of this user, received his email and performed other useful actions.
We received two pleasant buns at once: authorization started working simultaneously with the work with the metadata server and with the work with the notification server.
Loader
The Nginx DAV module worked on downloading files, which received files with hashes and stored them locally in one directory. At that time, nothing backed up, everything worked until the first disc was taken out. Since then it was far away even to closed internal testing, and only the developers themselves used the system, this option was acceptable. Of course, in the production we came out with a fully foul-tolerant scheme, today each user file is stored in two copies on different servers in different data centers (DC).
By November 2012, the day came when we could not turn away from the fact that not only the hierarchy of user directories, but also the content that it stores is important.
We wanted to make the bootloader reliable and functional, but at the same time simple enough, so we didn’t build florid weaves between the hierarchy of directories and the bodies of files. We decided to limit the range of bootloader tasks to the following: accept the incoming file, calculate its hash and simultaneously write it on two backends. We called this entity Loader, and its concept has not changed much since those times. The first working Loader prototype was written within two weeks, and after a month we completely switched to the new loader.
He knew how to do everything that we needed: to receive files, read the hash and send it to the stack without saving the file on the local hard drive of the frontend.
Sometimes we get rave reviews that, for example, a gigabyte movie was poured into the Cloud instantly. This is due to the fill mechanism that our client applications support: before uploading, they consider the file hash, and then “ask” the Loader if we have such a hash in the Cloud; No, they fill it in, they just update the metadata.
Zeppelin: Python vs C
While the loader was being written, we realized that, first, a single server of metadata would not be enough for the entire audience that we would like to reach. Secondly, it would be nice if the metadata also existed in duplicate. Thirdly, none of us wanted to route the user to the necessary metadata server inside the Nginx module.
The solution seemed obvious: write your demon in Python. So do everything, it is fashionable, popular, and most importantly - quickly. The daemon's task is to find out on which metadata server the user lives on, and redirect all requests there. In order not to be involved in routing users on data servers, we wrote a layer on Twisted (this is an asynchronous framework for Python). However, it turned out that either we do not know how to prepare Python, or Twisted brake, or there are other unknown reasons, but this thing did not keep more than a thousand requests per second.
Then we decided that we would be like hardcore guys to write in C using the Metad framework, which allows us to write asynchronous code in a synchronous manner (it looks something like state threads ). The first working version of the sishny Zeppelin-a (the chain of associations Cloud - Airships - Zeppelin led us to the choice of such a name) appeared on the test servers in a month. The results were quite expected: the existing one and a half to two thousand requests per second were processed easily and naturally at close to zero CPU usage.
With time, Zeppelin's functionality has expanded, and today he is responsible for proxying requests to Metad, working with weblinks, reconciling data between Metad and filedb, and authorization.
Thumbnailer Thumbnail Generator
In addition, we wanted to teach Cloud to display previews of pictures. We considered two options - to store thumbnails or generate them on the fly and temporarily cache in RAM - and stopped at the second. The generator was written in Python and uses the GraphicsMagick library.
In order to ensure maximum speed, thumbnails are generated on the machine where the file is physically located. Since there are a lot of storages, the load on the generation of thumbnails is “smeared” approximately evenly, and, according to our feelings, the generator works quite fast (well, maybe, except when a 16,000 x 16,000 pixel file is requested).
The first stress phase: closed beta
A serious test of our decisions was the release of closed beta testing. Beta started like people - more people came than we expected, they created more traffic than we expected, the load on the disk turned out to be more than we expected. We fought these problems heroically, and over a half or two months, we overcame many of them. We very quickly grew to one hundred thousand users and in October we removed invites.
Second stress stage: public release
The second serious test was the public release: problems with the disks, which we once again solved, returned. Over time, the excitement began to fade, but then the New Year turned up, and we decided to distribute a terabyte to everyone. On the 20th of December, in connection with this, it was very cheerful: the traffic exceeded all our expectations. At that time, we had around 100 storages in which there were about 2,400 disks, while the traffic to individual machines exceeded gigabits. Total traffic exceeded 60 Gbps.
Of course, we did not expect this. Focusing on the experience of colleagues in the market, it was possible to assume that about 10 TB per day would be flooded. Now, when the peak is already asleep, 100 TB is flooded in our country, and on the most intense days it reached 150 TB / day. That is, every ten days we make petabyte of data.
Property Inventory
So, at the moment we have used:
● Samopisnaya database. Why was it necessary to write your base? Initially, we wanted to run on a large number of cheap machines, so when developing we struggled for every byte of RAM, for every processor clock. To do this on existing implementations, like MongoDB, which store JSON, even if it is binary packed, would be naive. In addition, we needed specific operations, such as Unicode case folding, the implementation of file operations.
This could be done by expanding the existing noSQL database, but in this case, the vfs logic would simply have to be entered into the existing database of existing code volumes, or the server functionality could be expanded through the built-in scripting languages, the effectiveness of which caused some doubt.
In traditional SQL databases, storing tree structures is not very convenient, and rather inefficient - nested sets will lay the foundation on updates.
It would be possible to store all the paths in rows in Tarantool, but this is unprofitable for two reasons. First, we obviously cannot fit all users in RAM, and Tarantool stores the data there; secondly, if you store the full path, we get a huge overhead.
As a result, it turned out that all existing solutions required intensive file development and / or were quite voracious in terms of resources. In addition, it would require learning to administer them.
That is why we decided to write our bike. It turned out to be quite simple and does exactly what we need from it. Thanks to the existing architecture, you can, for example, look at the user's metadata at a point in time in the past. In addition, you can implement file versioning.
● Tarantool key-value storage
● Nginx is widely used (wonderful Russian development, ideal until you have to write extensions for it)
● As a rudiment, the old notifier is temporarily used on the internal development of Mail.Ru Imagine
● More than three thousand pairs of discs. Our user files and metadata are stored in duplicate on different machines, each with 24 disks with a capacity of 2 or 4 TB (all new servers are setup with disks on 4TB).
Unexpected discoveries
We write detailed logs for each request. We have a separate team that writes an analyzer that builds various graphs for identifying and analyzing problems. Graphs are displayed in Graphite, in addition, we use Radar and other systems.
Exploring how to use our Cloud, we made some interesting discoveries. For example, the most popular file extension in the Cloud is .jpg. This is not surprising - people love photos. What's more interesting, the top 10 popular extensions include .php and .html. We do not know what is stored there - the code base or backups from the hosting, but the fact remains.
We notice significant traffic jumps in the days when updated modes appear, released to updates of popular online games: someone downloads another addon, and then an army of gamers together downloads it from our Cloud. It got to the point that on certain days up to 30% of visits to us were made to download these updates.
Questions and answers
We thought about a list of questions you might want to ask.
What about the HTTP extension?
Nowhere does the HTTP protocol expand. When we started the development of the Cloud, everything worked on open data channels without HTTPS (in production we went, of course, with full SSL encryption of all traffic between the client and the server). Therefore, when someone had a desire to pull out something in the headline, the threat of a wild proxy that would cut all the custom headlines quickly discouraged it. So everything that we need is concentrated either in the URL or in the body.
What is used as a file identifier?
Our file identifier is SHA-1.
What will happen to user data if the entire Cloud server or data center is “covered”?
Everything here is absolutely folly-tolerant, and the failure of a server or even a whole DC has almost no effect on the user's work. All user data is duplicated on different servers in different DCs.
What plans do you have for the future?
In our immediate development plans, WebDAV launch, further optimization of everything and everything, and many interesting features, which you will learn about soon.
If we have missed something, we will try to answer in the comments.
Source: https://habr.com/ru/post/211340/
All Articles