MMU in pictures (part 1)
I want to talk about the memory management unit (Memory Management Unit, MMU). As you know, of course, the main function of the MMU is hardware support for virtual memory. The cybernetics dictionary edited by Academician Glushkov tells us that virtual memory is an imaginary memory allocated by the operating system for hosting a user program, its working fields and information arrays.
Systems with virtual memory have four basic properties:
The benefits of all of the above points are obvious: millions ofKrivorukov application programmers, thousands of developers of operating systems and countless number of processors are grateful to virtual memory for the fact that they are still in business.
Unfortunately, for some reason, all of the above comrades are not respectful of the MMU, and their familiarity with virtual memory usually begins and ends with the study of the paging organization of memory and the associative translation buffer (TLB). The most interesting thing remains behind the scenes.
I don’t want to repeat Wikipedia, so if you forget even what page memory is, then it's time to click on the link . About TLB will be a couple of lines below.
')
And now let's get down to business. This is how a processor without virtual memory support looks like:
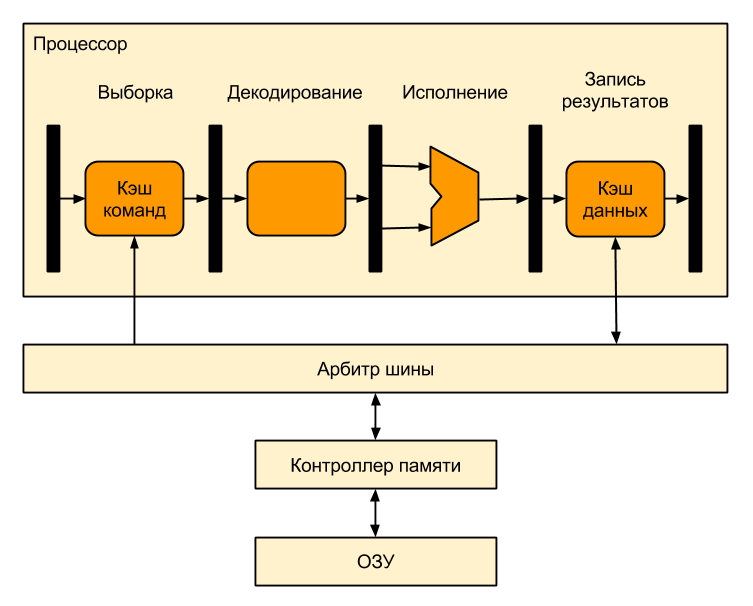
All addresses used in the program for such a processor are real, “physical”, i.e. the programmer, linking the program, must know what addresses the RAM is located at. If you soldered 640 kB of RAM, which is displayed in the address 0x02300000-0x0239FFFF, then all the addresses in your program should fall into this area.
If a programmer wants to think that he always has four gigabytes of memory (of course, this is a 32-bit processor), and his program is the only thing that distracts the processor from sleep, then we will need virtual memory. To add support for virtual memory, it is sufficient to place an MMU between the processor and RAM, which will translate virtual addresses (addresses used in the program) into physical addresses (addresses that fall on the input of memory chips):

This arrangement is very convenient - the MMU is used only when the processor accesses the memory (for example, when the cache misses), and the rest of the time is not used and saves energy. In addition, in this case, the MMU has almost no effect on the speed of the processor.
Here is what happens inside the MMU:

This process looks like this:
Consider the work of TLB on a simple example. Suppose we have two processes A and B. Each of them exists in its own address space and all addresses from zero to 0xFFFFFFFF are available to it. The address space of each process is paginated by 256 bytes (I took this number from the ceiling - usually the page size is at least one kilobyte), i.e. the address of the first page of each process is zero, the second is 0x100, the third is 0x200 and so on up to the last page at 0xFFFFFF00. Of course, the process does not have to occupy all the space available to it. In our case, Process A takes only two pages, and Process B takes three. And one of the pages is common to both processes.
We also have 1536 bytes of physical memory, divided into six pages of 256 bytes (virtual and physical memory pages are always the same size), and this memory is mapped into the physical address space of the processor from 0x40000000 (well, this is how it was soldered to the processor).
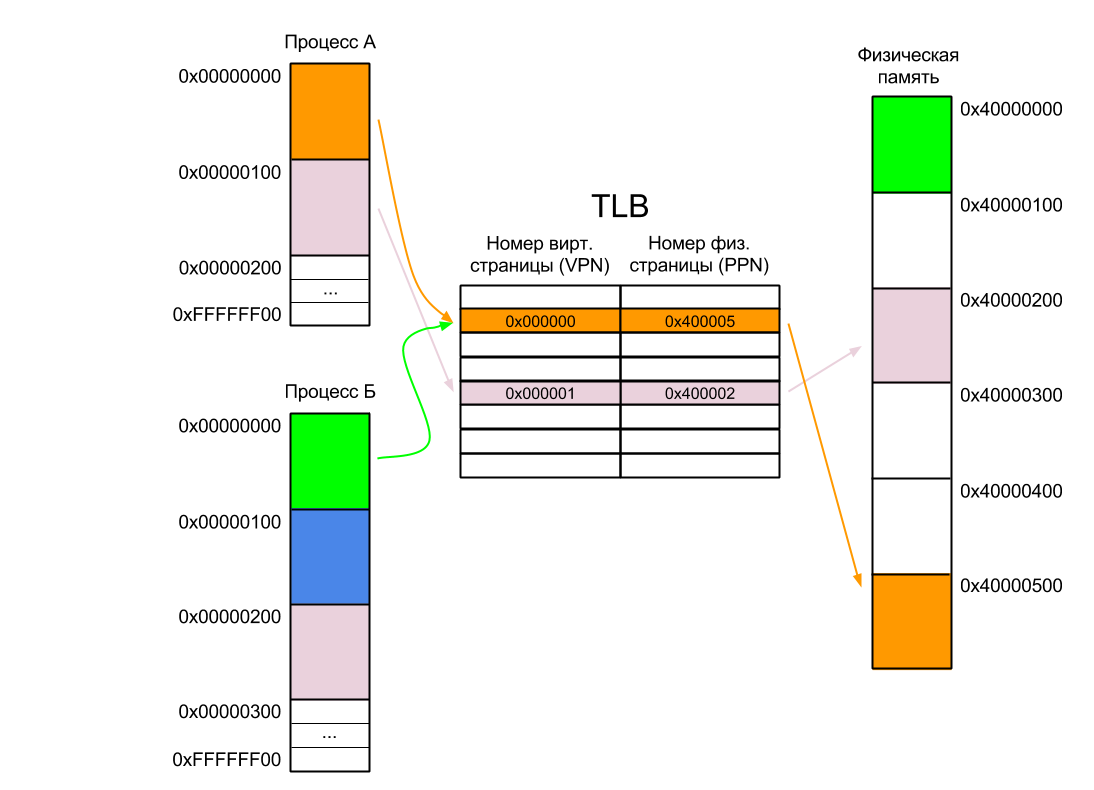
In our case, the first page of Process A is located in physical memory at address 0x40000500. We will not go into details of how this page gets there - it’s enough to know that the operating system is loading it. It adds an entry to the page table (but not to the TLB), associating this physical page with its corresponding virtual one, and transfers control to the process. The very first command executed by Process A will cause a TLB miss, as a result of which a new record will be added to the TLB.
When Process A needs access to its second page, the operating system will load it into some free space in physical memory (let it be 0x40000200). Another TLB slip will happen, and the desired entry will be added to the TLB again. If there is no space in the TLB, one of the earlier entries will be overwritten.
After that, the operating system can pause Process A and start Process B. It will load its first page at the physical address 0x40000000. However, unlike Process A, the first command of Process B will not cause a TLB miss, since there is already an entry for the zero virtual address in the TLB. As a result, Process B will begin to execute Process A code! Interestingly, this is how the ARM9 processor, widely known in narrow circles, worked.
The easiest way to solve this problem is to invalidate the TLB when switching context, that is, mark all entries in the TLB as invalid. This is not a good idea, as:
The more complicated way is to link all the programs so that they use different parts of the processor’s virtual address space. For example, Process A may occupy the lower part (0x0-0x7FFFFFFF), and Process B may occupy the lower part (0x80000000-0xFFFFFFFF). Obviously, in this case, there is no longer any talk of isolation of processes from each other, however this method is sometimes used in embedded systems. For general purpose systems, for obvious reasons, it is not suitable.
The third way is the development of the second. Instead of sharing four gigabytes of virtual address space of a processor between several processes, why not just increase it? Say 256 times? And to ensure the isolation of processes, to make sure that each process still has exactly four gigabytes of RAM available?
It turned out to be very simple. The virtual address was expanded to 40 bits, while the upper eight bits are unique for each process and are recorded in a special register - the process identifier (PID). When switching context, the operating system overwrites the PID with a new value (the process itself cannot change its PID).
If for our Process A, the PID is equal to one, and for Process B it is a two, then the virtual addresses that are identical from the process point of view, for example, 0x00000100, are different from the processor point of view - 0x0100000100 and 0x0200000100, respectively.
Obviously, our TLB should now be located not 32-bit, but 32-bit virtual page numbers. For convenience, the upper eight bits are stored in a separate field - the address space identifier (Address Space IDentifier - ASID).
Now, when the processor submits the virtual address to the MMU, a TLB search is performed using a combination of VPN and ASID, so the first Process B command will cause a page error even without prior invalidation of the TLB.

In modern processors, ASID is most often either eight-bit or 16-bit. For example, in all ARM processors with MMU, starting with ARM11, ASID is eight-bit, and ARMv8 architecture adds support for 16-bit ASID.
By the way, if the processor supports virtualization, then in addition to the ASID, it can also have a VSID (Virtual address Space IDentificator), which further expands the virtual address space of the processor and contains the number of the virtual machine running on it.
Even after adding an ASID, there may be situations where it will be necessary to invalidate one or several entries or even the entire TLB:
This would complete the story about the MMU, if it were not for one nuance. The fact is that between the processor and RAM, in addition to the MMU, there is also a cache memory.
Those who have forgotten what cache memory is and how it works can refresh knowledge here and there .
For example, let's take a two-channel (2-way) cache of one kilobyte in size with a cache line size (or cache lines, as you please) of 64 bytes. Now it doesn't matter whether it is a command cache, a data cache, or a merged cache. Since the memory page size is 256 bytes, each page contains four cache lines.
Since the cache is located between the processor and the MMU, it is obvious that only virtual addresses are used for indexing and for comparison of tags (physical addresses appear only on the output of the MMU). In English, this cache is called Virtually Indexed, Virtually Tagged cache (VIVT).
What is the problem? It's time to consider another example. Take all the same two processes A and B:
Wait, you say, we just solved this problem by adding the ASID to the TLB? And we have a cache before MMU - when there is no cache miss, then we don’t look at the MMU, and we don’t know what is the ASID.
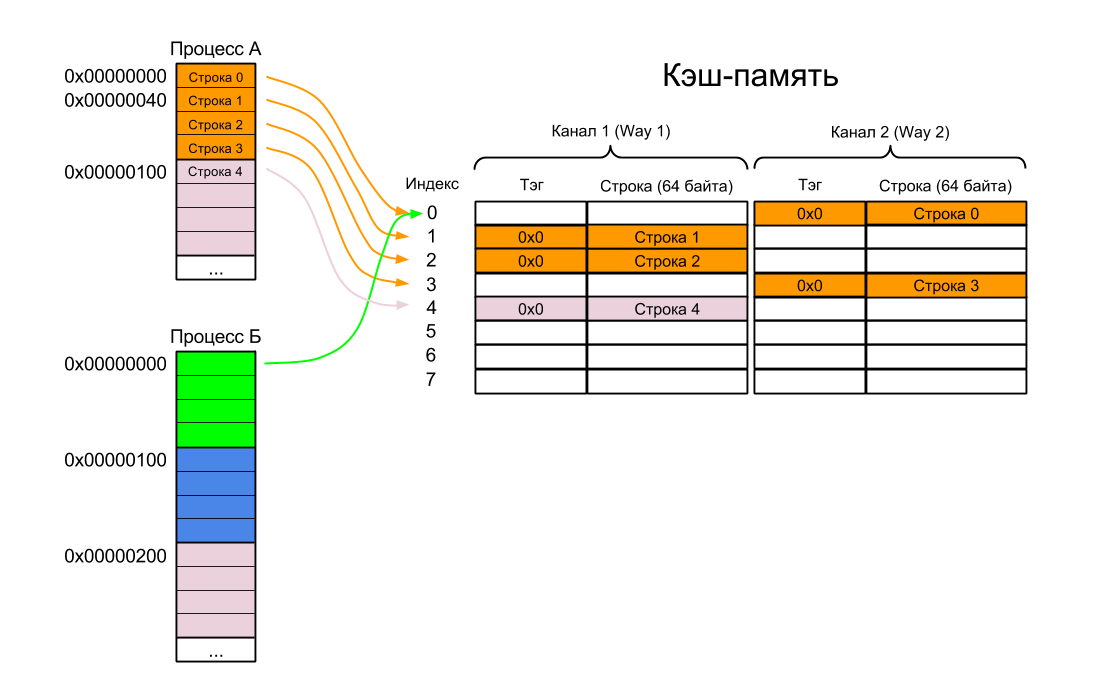
This is the first problem with the VIVT cache — so-called homonyms, when the same virtual address can be mapped to different physical addresses (in our case, the virtual address 0x00000000 is mapped to the physical address 0x40000500 for Process A and 0x40000000 for Process B).
There are many options for solving the problem of homonyms:
Which option do you like? I would probably think about the second. In ARM9 and some other processors with VIVT-caches, the third one is implemented.
If the homonyms in the cache would be the only problem, the processor developers would be the happiest people in the world. There is a second problem - synonyms (synonyms, aliases), when several virtual addresses are mapped to the same physical address.
Let us return to oursheep processes A and B. Suppose that we decided to solve the problem of homonyms in some decent way, because flashing the cache every time is really very expensive!
So:
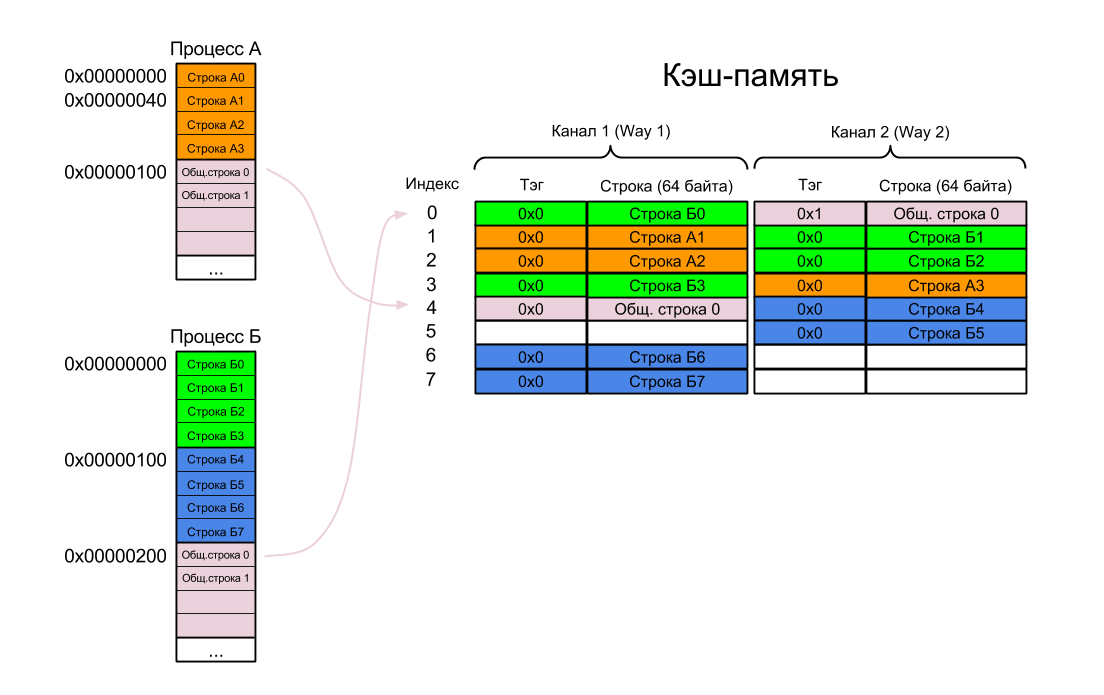
As a result, the same piece of physical memory is located in the cache in two different places. Now, if both processes change their copy, and then they want to keep it in memory, then one of them will have a surprise.
Obviously, this problem is relevant only for the data cache or for the combined cache (again, the instruction cache is read-only), but it is much more difficult to solve than the homonym problem:
But that's not all! We live in an era of multi-core processors with their own L1-caches, which still tend to become incoherent. To tackle cache incoherence, clever protocols were invented. But here's the ill luck: the protocols monitor the external bus, and which addresses are there on it? Physical! And virtual cache is used.
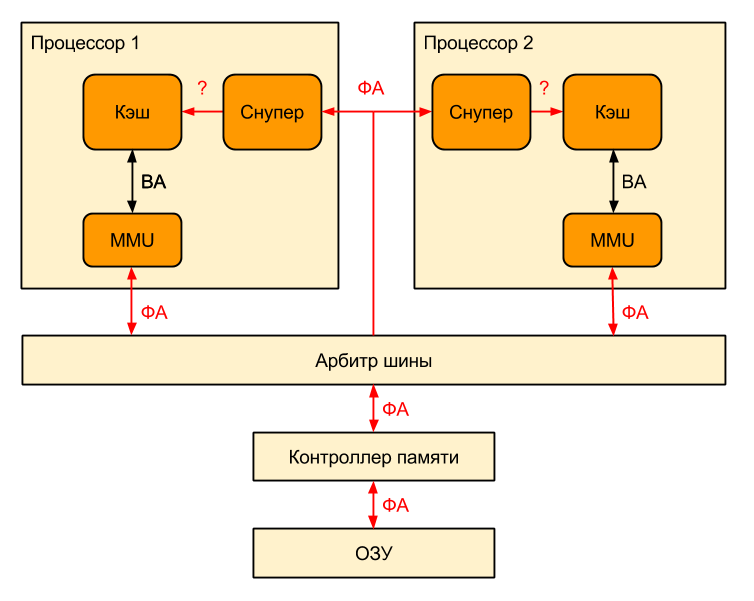
How, then, to find out which cache line should be urgently written to memory, because the neighboring processor is waiting for it?And no way Perhaps this is a topic for a separate article.
The VIVT-cache has one significant advantage: if the physical page is unloaded from memory, then the corresponding cache lines need to be flashed, but do not disable it. Even if this physical page is loaded to another place after some time, this will not affect the contents of the cache, because when accessing the VIVT cache, physical addresses are not used and the processor does not care whether they have changed or not.
A dozen years ago there were more advantages. VIVT-caches were actively used when an external MMU was used as a separate chip. Accessing such an MMU took much longer than accessing an MMU located on the same chip as the processor. But since a call to the MMU was required only in the case of cache miss, this allowed for acceptable system performance.
So, VIVT-caches have too many disadvantages and few advantages (by the way, if I forgot any other sins, write in comments). The smart people thought and decided: let's transfer the cash memory for the MMU. Let both indexes and tags come from physical addresses, not from virtual addresses. And moved. And whether it worked - you will find out in the next part.
Systems with virtual memory have four basic properties:
- User processes are isolated from each other and, dying, do not pull the whole system behind them.
- User processes are isolated from physical memory, that is, they do not know how much RAM you actually have and at what addresses it is located.
- The operating system is much more complicated than in systems without virtual memory.
- You can never know in advance how long the next processor command will take.
The benefits of all of the above points are obvious: millions of
Unfortunately, for some reason, all of the above comrades are not respectful of the MMU, and their familiarity with virtual memory usually begins and ends with the study of the paging organization of memory and the associative translation buffer (TLB). The most interesting thing remains behind the scenes.
I don’t want to repeat Wikipedia, so if you forget even what page memory is, then it's time to click on the link . About TLB will be a couple of lines below.
')
MMU device
And now let's get down to business. This is how a processor without virtual memory support looks like:
All addresses used in the program for such a processor are real, “physical”, i.e. the programmer, linking the program, must know what addresses the RAM is located at. If you soldered 640 kB of RAM, which is displayed in the address 0x02300000-0x0239FFFF, then all the addresses in your program should fall into this area.
If a programmer wants to think that he always has four gigabytes of memory (of course, this is a 32-bit processor), and his program is the only thing that distracts the processor from sleep, then we will need virtual memory. To add support for virtual memory, it is sufficient to place an MMU between the processor and RAM, which will translate virtual addresses (addresses used in the program) into physical addresses (addresses that fall on the input of memory chips):
This arrangement is very convenient - the MMU is used only when the processor accesses the memory (for example, when the cache misses), and the rest of the time is not used and saves energy. In addition, in this case, the MMU has almost no effect on the speed of the processor.
Here is what happens inside the MMU:
This process looks like this:
- The processor delivers a virtual address to the MMU.
- If the MMU is turned off, or if the virtual address is in an untranslated region, then the physical address is simply equated to virtual
- If the MMU is enabled and the virtual address is in the broadcast area, the address is translated, that is, the virtual page number is replaced with the physical page number corresponding to it (the same offset within the page):
- If the record with the desired virtual page number is in the TLB, then the physical page number is taken from it
- If there is no necessary record in the TLB, then it is necessary to look for it in the page tables that the operating system places in the non-translated RAM area (so that there is no TLB miss when processing the previous slip). The search can be implemented both in hardware and in software - through an exception handler, called a page fault. The found entry is added to the TLB, after which the command that caused the TLB miss is executed again.
Lyrical digression about MPU
By the way, do not confuse MMU and MPU (Memory Protection Unit), which is often used in microcontrollers. Roughly speaking, MPU is a greatly simplified MMU, of all functions providing only memory protection. Accordingly, the TLB is not there. When using MPU, the address space of the processor is divided into several pages (for example, 32 pages of 128 megabytes for a 32-bit processor), for each of which you can set individual access rights.
Consider the work of TLB on a simple example. Suppose we have two processes A and B. Each of them exists in its own address space and all addresses from zero to 0xFFFFFFFF are available to it. The address space of each process is paginated by 256 bytes (I took this number from the ceiling - usually the page size is at least one kilobyte), i.e. the address of the first page of each process is zero, the second is 0x100, the third is 0x200 and so on up to the last page at 0xFFFFFF00. Of course, the process does not have to occupy all the space available to it. In our case, Process A takes only two pages, and Process B takes three. And one of the pages is common to both processes.
We also have 1536 bytes of physical memory, divided into six pages of 256 bytes (virtual and physical memory pages are always the same size), and this memory is mapped into the physical address space of the processor from 0x40000000 (well, this is how it was soldered to the processor).
In our case, the first page of Process A is located in physical memory at address 0x40000500. We will not go into details of how this page gets there - it’s enough to know that the operating system is loading it. It adds an entry to the page table (but not to the TLB), associating this physical page with its corresponding virtual one, and transfers control to the process. The very first command executed by Process A will cause a TLB miss, as a result of which a new record will be added to the TLB.
When Process A needs access to its second page, the operating system will load it into some free space in physical memory (let it be 0x40000200). Another TLB slip will happen, and the desired entry will be added to the TLB again. If there is no space in the TLB, one of the earlier entries will be overwritten.
After that, the operating system can pause Process A and start Process B. It will load its first page at the physical address 0x40000000. However, unlike Process A, the first command of Process B will not cause a TLB miss, since there is already an entry for the zero virtual address in the TLB. As a result, Process B will begin to execute Process A code! Interestingly, this is how the ARM9 processor, widely known in narrow circles, worked.
The easiest way to solve this problem is to invalidate the TLB when switching context, that is, mark all entries in the TLB as invalid. This is not a good idea, as:
- In TLB at this moment only two of eight records are occupied, that is, a new record would fit there without problems
- Removing records belonging to other processes from the TLB, we force these processes to generate repeated page errors when the operating system starts them again. If a TLB does not have eight records, but a thousand, then system performance can drop significantly.
The more complicated way is to link all the programs so that they use different parts of the processor’s virtual address space. For example, Process A may occupy the lower part (0x0-0x7FFFFFFF), and Process B may occupy the lower part (0x80000000-0xFFFFFFFF). Obviously, in this case, there is no longer any talk of isolation of processes from each other, however this method is sometimes used in embedded systems. For general purpose systems, for obvious reasons, it is not suitable.
The third way is the development of the second. Instead of sharing four gigabytes of virtual address space of a processor between several processes, why not just increase it? Say 256 times? And to ensure the isolation of processes, to make sure that each process still has exactly four gigabytes of RAM available?
It turned out to be very simple. The virtual address was expanded to 40 bits, while the upper eight bits are unique for each process and are recorded in a special register - the process identifier (PID). When switching context, the operating system overwrites the PID with a new value (the process itself cannot change its PID).
If for our Process A, the PID is equal to one, and for Process B it is a two, then the virtual addresses that are identical from the process point of view, for example, 0x00000100, are different from the processor point of view - 0x0100000100 and 0x0200000100, respectively.
Obviously, our TLB should now be located not 32-bit, but 32-bit virtual page numbers. For convenience, the upper eight bits are stored in a separate field - the address space identifier (Address Space IDentifier - ASID).
Now, when the processor submits the virtual address to the MMU, a TLB search is performed using a combination of VPN and ASID, so the first Process B command will cause a page error even without prior invalidation of the TLB.
In modern processors, ASID is most often either eight-bit or 16-bit. For example, in all ARM processors with MMU, starting with ARM11, ASID is eight-bit, and ARMv8 architecture adds support for 16-bit ASID.
By the way, if the processor supports virtualization, then in addition to the ASID, it can also have a VSID (Virtual address Space IDentificator), which further expands the virtual address space of the processor and contains the number of the virtual machine running on it.
Even after adding an ASID, there may be situations where it will be necessary to invalidate one or several entries or even the entire TLB:
- If the physical page is unloaded from RAM to disk - because back to memory this page can be loaded to a completely different address, that is, the virtual address will not change, but the physical one will change
- If the operating system has changed the PID of the process - because the ASID will be different
- If the operating system has completed the process
This would complete the story about the MMU, if it were not for one nuance. The fact is that between the processor and RAM, in addition to the MMU, there is also a cache memory.
Those who have forgotten what cache memory is and how it works can refresh knowledge here and there .
For example, let's take a two-channel (2-way) cache of one kilobyte in size with a cache line size (or cache lines, as you please) of 64 bytes. Now it doesn't matter whether it is a command cache, a data cache, or a merged cache. Since the memory page size is 256 bytes, each page contains four cache lines.
Since the cache is located between the processor and the MMU, it is obvious that only virtual addresses are used for indexing and for comparison of tags (physical addresses appear only on the output of the MMU). In English, this cache is called Virtually Indexed, Virtually Tagged cache (VIVT).
Parasites in Homonyms in VIVT Cache
What is the problem? It's time to consider another example. Take all the same two processes A and B:
- Suppose that Process A is first executed. In the process of execution, lines with commands or data for this process are loaded into the cache memory one by one (Lines 0-4).
- The operating system stops Process A and transfers control to Process B.
- In theory, at this moment the processor should load the first line in the cache from the first page of Process B and start executing commands from there. In fact, the processor supplies the cache with a virtual address of 0x0, after which the cache responds that you do not need to load anything, because the necessary string is already cached.
- Process B begins to cheerfully execute Process A code.
Wait, you say, we just solved this problem by adding the ASID to the TLB? And we have a cache before MMU - when there is no cache miss, then we don’t look at the MMU, and we don’t know what is the ASID.
This is the first problem with the VIVT cache — so-called homonyms, when the same virtual address can be mapped to different physical addresses (in our case, the virtual address 0x00000000 is mapped to the physical address 0x40000500 for Process A and 0x40000000 for Process B).
There are many options for solving the problem of homonyms:
- Flush the cache (cache flush, i.e., write the changed cache contents back to memory) and disable the cache (i.e., mark lines as invalid) when switching context. If we have a separate instruction and data cache, then the instruction cache is simply enough to invalidate (i.e., mark all lines as empty), because the instruction cache is accessible to the processor only for reading and there is no point in flashing it
- Add ASID to cache tag
- Contact the MMU every time we access the cache, and not only when there was a mistake - then we can use the existing logic for comparing PID with ASID. Goodbye, energy saving and speed!
Which option do you like? I would probably think about the second. In ARM9 and some other processors with VIVT-caches, the third one is implemented.
Synonyms in VIVT Cache
If the homonyms in the cache would be the only problem, the processor developers would be the happiest people in the world. There is a second problem - synonyms (synonyms, aliases), when several virtual addresses are mapped to the same physical address.
Let us return to our
So:
- First, Process A is executed — Lines A0 - A3 and General Line 0 are loaded into the cache one by one (remember that processes A and B have one page)
- Then the operating system, not the flash cache, switches the context
- Process B is starting up. The lines B0 - B7 are loaded into the cache.
- Finally, Process B refers to Shared Line 0. This line is already loaded into cache by Process A, but the processor does not know about it, since it appears in the cache under a different virtual address (I recall that there are no physical addresses in the VIVT cache)
- There is a cache miss. The virtual address 0x00000200 is translated to the physical address 0x40000200, and the Shared Line 0 is re-loaded into the cache. Its location is determined by the virtual address - and the address 0x00000200 corresponds to the Index 0 (bits 8-6) and Tag 0x1 (bits 31-9).
- Since both channels in the set with index 0 are already occupied, you have to throw out one of the already loaded lines (A0 or B0). Using the LRU (Least Recently Used) algorithm, the cache throws out the A0 Line and in its place adds the General line 0.
As a result, the same piece of physical memory is located in the cache in two different places. Now, if both processes change their copy, and then they want to keep it in memory, then one of them will have a surprise.
Obviously, this problem is relevant only for the data cache or for the combined cache (again, the instruction cache is read-only), but it is much more difficult to solve than the homonym problem:
- The easiest way, as we have already figured out, is to flush the cache with each context switch (by the way, to combat synonyms, unlike homonyms, you don’t need to disable the cache). However, firstly, it is expensive, and secondly, it does not help if the process wants to have several copies of the same physical page in its address space
- You can identify synonyms by hardware:
- Or, with each miss, run through the entire cache, performing the translation of the address for each tag and comparing the received physical addresses with the one obtained during the translation of the address that caused the miss (and the living dead envy!)
- Or add to the processor a new block that will perform the reverse translation - the conversion of a physical address into a virtual one. After that, with each miss, perform the translation of the address that caused it, and then use the back translation to convert this physical address to a virtual one and compare it with all tags in the cache. By golly, you'd better flush your cache!
- The third way is to avoid synonyms programmatically. For example, do not use shared pages. Or again start linking programs into a shared address space.
Coherence and VIVT Cache
But that's not all! We live in an era of multi-core processors with their own L1-caches, which still tend to become incoherent. To tackle cache incoherence, clever protocols were invented. But here's the ill luck: the protocols monitor the external bus, and which addresses are there on it? Physical! And virtual cache is used.
How, then, to find out which cache line should be urgently written to memory, because the neighboring processor is waiting for it?
Advantages of VIVT Cache
The VIVT-cache has one significant advantage: if the physical page is unloaded from memory, then the corresponding cache lines need to be flashed, but do not disable it. Even if this physical page is loaded to another place after some time, this will not affect the contents of the cache, because when accessing the VIVT cache, physical addresses are not used and the processor does not care whether they have changed or not.
A dozen years ago there were more advantages. VIVT-caches were actively used when an external MMU was used as a separate chip. Accessing such an MMU took much longer than accessing an MMU located on the same chip as the processor. But since a call to the MMU was required only in the case of cache miss, this allowed for acceptable system performance.
What to do?
So, VIVT-caches have too many disadvantages and few advantages (by the way, if I forgot any other sins, write in comments). The smart people thought and decided: let's transfer the cash memory for the MMU. Let both indexes and tags come from physical addresses, not from virtual addresses. And moved. And whether it worked - you will find out in the next part.
Source: https://habr.com/ru/post/211150/
All Articles