Splitting web pages into semantic blocks
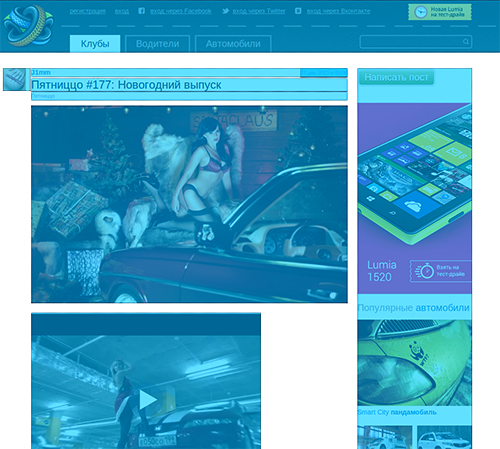
An example of the algorithm on the site Autokadabra.
Task
Probably everyone knows about the service "Webvisor", which allows you to record the actions of visitors to your site and view them in video mode. The tool is interesting, but when there are a lot of visitors on the site, it’s problematic to make a picture of the site’s life, you don’t look at each video, and you cannot group them.
It is much more useful to track the interaction of visitors with the site, find out how the site lives, with the ability to simultaneously cover many visitors. As a result, the idea to write information in the form of a meaningful list of actions of visitors appeared:
- Dima : go to the site from the Yandex RU search engine on request sepyra (3m. 10 seconds ago)
- Dima : transition from the page " Sepyra Web Analytics | Official Website " to the page " About the System | Sepyra Web Analytics (1 m. 30 seconds ago)
- Dima : highlighting the text of " time " in the block " One of the key features of Sepyra web analytics is the opportunity ... who wants to be aware of every step of visitors " (40 seconds ago)
- Dima : the average interest in the sub-block " Connect " in the block " Tariffs About the system FAQ Contacts English Connect Login " (20 seconds ago)
- Dima : filling in / changing the " Your Name " field in the " Registration " form (10 seconds ago)
The recording consists of two parts: a block in which the visitor’s action takes place and the action itself, for example, the selection of the text of “ time ” in the “ One of the key features ... ” block. For this description it is necessary to determine the block on the page and its name. If the name was more or less clear, then I had to think about the allocation of blocks.
Solution options
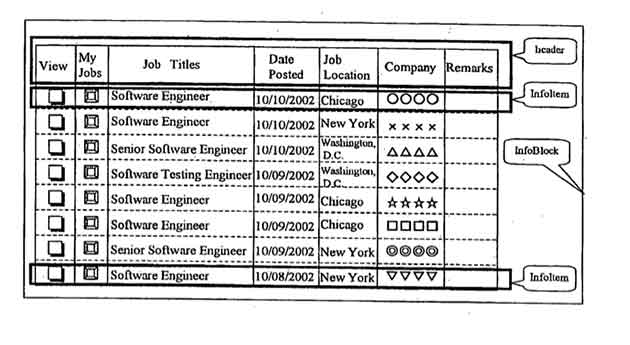
The first step is to search for existing solutions to this problem. One of them is “The method of splitting web pages into semantic blocks in order to identify similar documents” (DI Kosinov. Voronezh State University). Here the largest element was determined and removed from the page, and so on until the content remained. In order not to pull out the whole <BODY> at once, the node depth indicator was introduced into the weight function in order to select the blocks at the lowest possible levels. In the process of implementation and testing, it turned out that the problem occurs in several places, firstly, it is necessary to choose the correct coefficients for the weight function, secondly, after removing the content, there are “holes” on the page, and the next block is broken, for example, block 4 in the figure .

')
After that, we began to work out our solutions, one of the options was to allocate blocks with a certain length of content, which was not entirely successful. One evening another decision came, which became final. The essence was simple, why search for semantic blocks on the page, when the layout is basically so that the blocks are combined in meaning, you only need to determine to what level to break the blocks and which ones.
Final version
Algorithm for splitting web pages into blocks
The basic idea of the algorithm is to assume that the common elements of a web page often have a common parent in the DOM tree . Experimentally, it was found that the number of separate semantic blocks on a page is on average equal to the square root of the number of elements at the lowest level of the DOM tree (i.e. the square root of the number of elements that do not have children).
In short, the algorithm can be described in the following steps:
- Place the root element of the DOM tree into an array
- While the number of elements in the array is less than the square root of the number of elements at the lower level of the DOM tree, repeat the following cycle:
- Choose the element with the highest weight, which has children. If this is not, then exit.
- If a suitable element has been found, remove it from the array, add the remote elements to the array, and return to the beginning of the loop.
Example Splitting Function
function getSeparatedNodes(rootObj, numBlocks) { var nodes = [rootObj]; while (nodes.length < numBlocks) { var maxWeightNode = nodes[0]; var nodeIndex = 0; for (var i = 0; i < nodes.length; i++) { if (((nodes[i].weight > maxWeightNode.weight) || (maxWeightNode.lowerChildrenCount == 1)) && (nodes[i].lowerChildrenCount > 1)) { maxWeightNode = nodes[i]; nodeIndex = i; } } if (maxWeightNode.lowerChildrenCount <= 1) { break; } nodes.splice(nodeIndex, 1); nodes = nodes.concat(maxWeightNode.children); } return nodes; } Item weight
The weight will determine which next element will be divided into children, it takes into account both the size of the contents and the area of the element,
Element weight = log (text_length * 0.1 + 1.01) * log (area * 0.9 + 0.11).
The highest priority is given to the area of the element, the magic numbers 1.01 and 0.11 limit the logarithm so that the weight remains a positive number. Empty nodes are eliminated by the algorithm, so the minimum values for text size and area are one. For objects that cannot contain text inside (images, embedded objects, etc.), the text_length parameter is counted as area / 140 (140 is the average value of the area of one character of text). When calculating the length of the text, recurring spaces are excluded, and the inner text of the <STYLE> and <SCRIPT> elements is also not taken into account.
Block name
The search for the block name is quite simple:
- Header elements are searched inside the block (H1 - H6)
- If no header elements are found, elements with the maximum font size are searched.
- If all the elements have the same font, they are searched for elements with maximum bold font.
- If the entire text has the same fatness of the font, the beginning and end of the text is taken.
What happened
Below are examples of what happened in the end (the pictures are clickable):
Autokadabra
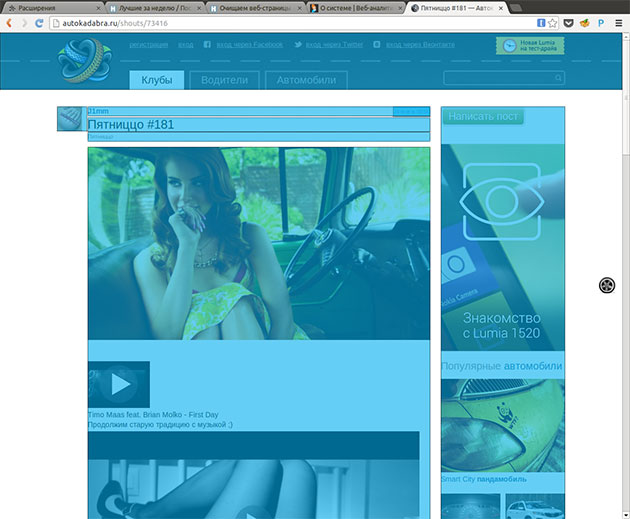
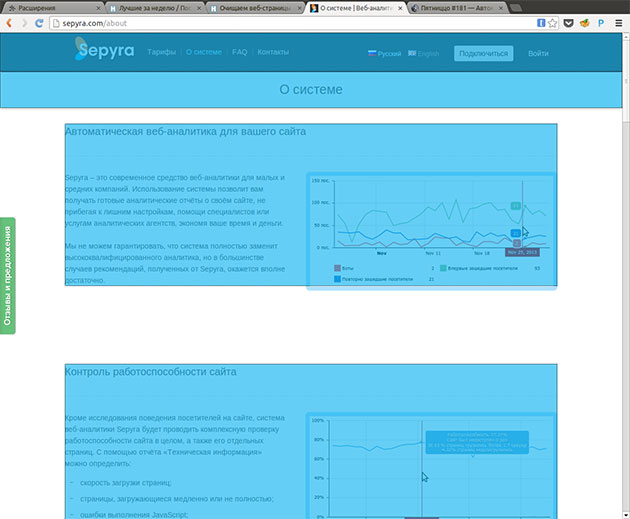
Sepyra
List of articles on Habré

According to the same algorithm, it is possible to divide the block into subblocks:

In live you can see here , as well as other examples.
Similar solutions
Also found a lot of patents on this topic, who can come in handy.
- The patent “APPARATUS AND METHOD FOR DISPLAYING WEB PAGE IN MOBILE COMMUNICATION TERMINAL” (US 2007/0110037 A1) represents a method of dividing a web page into blocks for display on mobile devices (if later in the text - so that each block has its own key, which is convenient for navigation);
- Patent US 2011/0289435 A1, divides the page into blocks for display on the TV screen when the remote control from the TV is used for navigation;
- Patent US 2004/0103371 A1, the page is divided into blocks, but in order to better be displayed on devices with a small screen, and the blocks are ranked according to the interest to the user, which is calculated by how often the user views these same blocks;
- Patent US 2011/0285750 A1, for convenient display of a web page on different screens;
- Patent US 2012/0005573 A1 keeps track of what the user is interested in, then highlights this area of the page;
- Patent US 2006/0149726 A1 web page segmentation, taking into account the heuristic analysis;
- Patent US 2005/0066269 A1 (Device and method for extracting information blocks from web pages), presents several methods for segmenting a web page into information blocks, based on repeated patterns
Conclusion
The algorithm turned out to be working, quite simple and understandable, which is important. Of the minuses, it is not very stable, it will survive small changes in the code, but when adding widgets to the page, other changes in the structure of the document, the blocks may break up differently.
Source: https://habr.com/ru/post/210824/
All Articles