Theory and practice of source code parsing with ANTLR and Roslyn
Our project PT Application Inspector implements several approaches to source code analysis in various programming languages:
- search by signatures;
- study of the properties of mathematical models obtained as a result of static abstract interpretation of code;
- dynamic analysis of the deployed application and verification of the results of static analysis on it.
Our series of articles is devoted to the structure and principles of the signature search module (PM, pattern matching). The advantages of such an analyzer are speed, simplicity of the template description and scalability in other languages. Among the shortcomings, it is possible to highlight the fact that the module is not able to analyze complex vulnerabilities that require building high-level models of code execution.
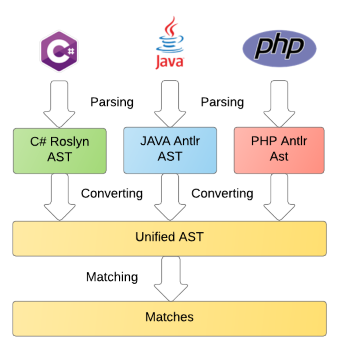
Among others, the following requirements were formulated for the module being developed:
- support of several programming languages and simple addition of new ones;
- support for analyzing code containing syntactic and semantic errors;
- The ability to describe templates in a universal language (DSL, domain specific language).
In our case, all templates describe any vulnerabilities or shortcomings in the source code.
The entire code analysis process can be broken down into the following steps:
- parsing into a language dependent view (abstract syntax tree, AST);
- AST to language independent uniform format;
- direct comparison with the templates described on DSL.
This article is devoted to the first stage, namely: parsing, comparing the functionality and features of various parsers, applying the theory in practice using the example of Java, PHP, PLSQL, TSQL and even C # grammars. The remaining stages will be discussed in the following publications.
Content
Parsing theory
At the beginning, the question may arise: why build a unified AST, develop graph matching algorithms instead of using regular regular expressions? The fact is that not all patterns can be simply and conveniently described using regular expressions. It is worth noting that, for example, in C #, regular expressions have the power of context-free grammars thanks to named groups and backlinks (however, the process of writing patterns using such expressions will be accompanied by other obscene expressions complex). On this occasion there is also an article from the PVS-Studio developers. In addition, the connectedness of the resulting unified AST will allow it to be used in the future to build more complex code execution representations, such as the graph of code properties .
Terminology
Those familiar with the theory of parsing may skip this section.
Parsing is the process of transforming source code into a structured form. A typical parser is a combination of a lexer and a parser. Lexer groups source code symbols into meaningful sequences called lexemes. After this, the type of the token is determined (identifier, number, string, etc.). A token is a collection of the value of a token and its type. In the example in the figure below, the tokens are sp , = , 100 . A parser from a stream of tokens builds a coherent tree structure, which is called a parse tree. In this case, assign is one of the nodes in the tree. An abstract syntax tree or AST is a parse tree at a higher level, from which non-relevant tokens, such as parentheses, commas, are removed. However, there are parsers in which the lexing and parsing steps are combined.
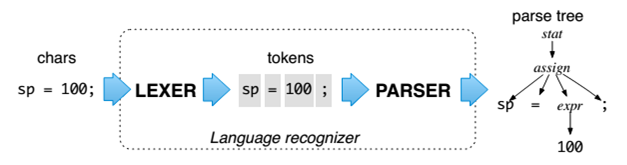
Rules are used to describe the various AST nodes. The union of all the rules is called the grammar of the language. There are tools that generate code for a specific platform (runtime) for parsing languages based on grammars. They are called parser generators. For example, ANTLR , Bison , Coco / R. However, often the parser is written by hand for certain reasons, for example Roslyn . The advantages of the manual approach are that the parsers, as a rule, are more productive and readable.
Since the project was originally decided to develop on .NET technologies, it was decided to use Roslyn for analyzing C # code, and for other languages - ANTLR, since the latter supports .NET runtime, and other alternatives have fewer features.
Types of formal languages
According to the Chomsky hierarchy , there are 4 types of formal languages:
- regular, example: a n
- context-free (KS, example: a n b n )
- context-sensitive (short-circuit, example: a n b n c n )
- turing-full.
Regular expressions allow to describe only the simplest constructions for matching, which, however, cover most of the tasks in everyday practice. Another advantage of regular expressions is that their support is included in most modern programming languages. Turing-complete languages have no practical application because of their complexity both in writing and in parsing (from esoteric one can recall Thue ).
At present, almost the entire syntax of modern programming languages can be described with the help of KS grammars. If we compare the parsers of KS languages and regular expressions “on fingers”, then the latter have no memory. And if we compare the parsers of KZ and KS languages, the latter do not remember the rules visited earlier.
In addition, the language in one case may be the COP, and in the other - short-circuit. Given semantics, i.e. consistency with language definitions, in particular, type consistency, the language can be considered as short-circuit. For example, T a = new T (). Here the type in the constructor on the right should be the same as the one on the left. It is usually advisable to check the semantics after the parsing stage. However, there are syntactic constructions that can not be parsed using KS grammars, for example Heredoc in PHP: $ x = <<< EOL Hello world EOL ; In it, the EOL token is a marker of the beginning and end of the discontinuous line, therefore, the value of the visited token is required. This article focuses on the analysis of such KS- and KZ- languages.
ANTLR

This parser generator is LL (*) , it has existed for more than 20 years, and in 2013 its 4th version was released. Now its development is conducted on GitHub. At the moment, it allows you to generate parsers in Java, C #, Python2, Python3, JavaScript. On the approach of C ++, Swift. I must say, now in this tool it is quite simple to develop and debug grammars. Despite the fact that LL grammars do not allow left-recursive rules, in ANTLR, starting with the 4th version, it became possible to record such rules (except for rules with hidden or indirect left-recursion). When generating a parser, such rules are transformed into ordinary non-left-recursive ones. This shortens the entry of, for example, arithmetic expressions:
expr : expr '*' expr | expr '+' expr | <assoc=right> expr '^' expr | id ; In addition, in the 4th version, the parsing performance is significantly improved due to the use of the Adaptive LL algorithm (*). This algorithm combines the advantages of relatively slow and unpredictable GLL and GLR algorithms, which, however, are capable of resolving cases with ambiguity (used in parsing natural languages), and standard, fast LL-algorithms of recursive descent, which, in turn, are not capable of resolving all ambiguity problems. The essence of the algorithm lies in the pseudo-parallel launch of LL parsers on each rule, their caching and the selection of a suitable prediction (unlike GLR, where several alternatives are acceptable). Thus, the algorithm is dynamic. Despite the fact that the worst theoretical complexity of the algorithm is O (n 4 ), in fact the speed of parsing for existing programming languages is linear. Also in the fourth version, the possibility of restoring the parsing process after detecting syntax errors has evolved greatly. Learn more about the ANTLR 4 algorithms and how they differ from other parsing algorithms written in Adaptive LL (*) Parsing: The Power of Dynamic Analysis .
Roslyn

Roslyn is not just a parser, but a complete tool for parsing, analyzing and compiling C # code. It is also being developed on GitHub, but it is much younger than ANTLR. This article only discusses its ability to parse without semantics. Roslyn parsit the code into a reliable (fidelity), immutable (immutable) and thread-safe (threadsafe) tree. The validity lies in the fact that such a tree can be converted back into a character code into a character, including spaces, comments, and preprocessor directives, even if it contains syntax errors. Immutability makes it easy to process a tree in several threads, because each stream creates a “smart” copy of the tree, in which only changes are stored. This tree can contain the following objects:
- Syntax Node is a non-terminal tree node containing several other nodes and representing a specific construction. It may also contain an optional node (for example, ElseClauseSyntax for if);
- Syntax Token - a terminal node that displays a keyword, identifier, literal or punctuation;
- Syntax Trivia is a terminal node that displays a space, comment, or preprocessor directive (can be safely removed without losing any code information). Trivia cannot have a parent. These nodes are indispensable for transforming a tree back into code (for example, for refactoring).
Parsing issues
When developing grammars and parsers, there are some problems that need to be solved.
Keywords as identifiers
It often happens that when parsing keywords can also be identifiers. For example, in C #, the async keyword placed before the signature of the async Method() method means that this method is asynchronous. But if this word will be used as the variable identifier var async = 42; , the code will also be valid. In ANTLR, this problem is solved in two ways:
- using the semantic predicate for the syntax rule:
async: {_input.LT(1).GetText() == "async"}? ID ;async: {_input.LT(1).GetText() == "async"}? ID ;; while the async token itself will not exist. This approach is bad because the grammar becomes runtime dependent and looks ugly; - inclusion of a token in the id rule itself:
ASYNC: 'async'; ... id : ID ... | ASYNC;
Ambiguity
In natural language, there are ambiguously interpreted phrases (such as “these types of steel have been in our workshop”). In formal languages, such constructions can also occur. For example, the following snippet:
stat: expr ';' // expression statement | ID '(' ')' ';' // function call statement; ; expr: ID '(' ')' | INT ; However, unlike natural languages, they are most likely the result of improperly designed grammars. ANTLR is not able to detect such ambiguities in the parser generation process, but can detect them directly in the parsing process if the LL_EXACT_AMBIG_DETECTION option is LL_EXACT_AMBIG_DETECTION (because, as already mentioned, ALL is a dynamic algorithm). Ambiguity can occur both in the lexer and in the parser. In the lexer for two identical tokens, the token is declared, which is declared above in the file (for example, with identifiers). However, in languages where ambiguity is valid (for example, C ++), semantic predicates (code inserts) can be used to resolve it, for example:
expr: { isfunc(ID) }? ID '(' expr ')' // func call with 1 arg | { istype(ID) }? ID '(' expr ')' // ctor-style type cast of expr | INT | void ; Also, sometimes ambiguity can be corrected with a little tinkering with grammar. For example, in C # there is a bitwise right shift operator RIGHT_SHIFT: '>>' ; Two angle brackets can also be used to describe generic classes: List<List<int>> . If you define a token >> , then the construction of two lists can never be parsed, because the parser will assume that instead of two closing brackets the >> operator is written. To solve this problem, simply abandon the RIGHT_SHIFT token. In this case, the token LEFT_SHIFT: '<<' can be left, since such a sequence of characters when parsing the angle brackets cannot be found in the valid code.
In our module, we have not yet tested in detail whether there is ambiguity in the developed grammars.
Handling spaces, comments.
Another problem with parsing is the handling of comments. The inconvenience here is that if you include comments in the grammar, then it will turn out to be overcomplicated, since in essence each node will contain comments in itself. However, it is also impossible to simply throw out comments, because they may contain important information. For processing comments in ANTLR, so-called channels are used that isolate a lot of comments from other tokens: Comment: ~[\r\n?]+ -> channel(PhpComments);
Roslyn comments are included in tree nodes, but they have a special type of Syntax Trivia. Both ANTLR and Roslyn provide a list of trivial tokens associated with a specific regular token. In ANTLR, for a token with index i, there is a method in the stream that returns all tokens from a specific channel to the left or right: getHiddenTokensToLeft(int tokenIndex, int channel) , getHiddenTokensToRight(int tokenIndex, int channel) . In Roslyn, such tokens are immediately included in the terminal Syntax Token.
In order to receive all comments, you can take all the tokens of a specific channel in ANTLR: lexer.GetAllTokens().Where(t => t.Channel == PhpComments) , and in Roslyn you can take all the DescendantTrivia for the root node with the following SyntaxKind: SingleLineCommentTrivia , MultiLineCommentTrivia , SingleLineDocumentationCommentTrivia , MultiLineDocumentationCommentTrivia , DocumentationCommentExteriorTrivia , XmlComment .
Processing spaces and comments is one of the reasons why you cannot use code for analysis, for example, LLVM: they will simply be thrown out in it. In addition to comments, even the handling of spaces is important. For example, to detect errors with a single statement in if (an example taken from the article PVS-Studio rummaged in the FreeBSD kernel ):
case MOD_UNLOAD: if (via_feature_rng & VIA_HAS_RNG) random_nehemiah_deinit(); random_source_deregister(&random_nehemiah); Handling parsing errors.

An important ability of each parser is error handling - for the following reasons:
- The parsing process should not interrupt only because of one error, but should be correctly restored and parse the code further (for example, after a missing semicolon);
- search for a relevant error and its location, instead of a set of irrelevant ones.
Errors in ANTLR
The following types of parsing errors exist in ANTLR:
token recognition error (Lexer no viable alt); the only existing lexical error, indicating the absence of a rule for the formation of a token from an existing token:
class # {int i; } - here such a token is # .Missing token in this case, ANTLR inserts a missing token into the stream of tokens, marks that it is missing, and continues to parse as if it exists.
class T {int f (x) {a = 3 4 5; } } - here this token is}at the end;extra token (Extraneous token); ANTLR marks that the token is erroneous and continues the parsing further, as if it is missing: in the example, this is the first token ;
')
class T ; {int i; }incompatible input chain (Mismatched input); this turns on the “panic mode”, the chain of input tokens is ignored, and the parser waits for the token from the synchronization set. In the following example, lexemes 4 and 5 are ignored, and the sync token is ;
class T {int f (x) {a = 3 4 5 ; }}- No viable alternative input; This error describes all other possible errors of parsing.
class T { int; }
In addition, errors can be processed manually by adding alternatives to the rule, for example:
function_call : ID '(' expr ')' | ID '(' expr ')' ')' {notifyErrorListeners("Too many parentheses");} | ID '(' expr {notifyErrorListeners("Missing closing ')'");} ; Moreover, in ANTLR 4 you can use your own error handling mechanism. This is needed, for example, to increase the performance of the parser: first, the code is parsed using the fast SLL algorithm, which, however, may incorrectly parse the code with ambiguity. If using this algorithm it turned out that there is at least one error (this can be both an error in the code and ambiguity), the code is parsed with the help of a complete, but less fast ALL-algorithm. Of course, code with real errors (for example, missed;) will always be parsed using LL, however there are usually less such files than files without errors.
// try with simpler/faster SLL(*) parser.getInterpreter().setPredictionMode(PredictionMode.SLL); // we don't want error messages or recovery during first try parser.removeErrorListeners(); parser.setErrorHandler(new BailErrorStrategy()); try { parser.startRule(); // if we get here, there was no syntax error and SLL(*) was enough; // there is no need to try full LL(*) } catch (ParseCancellationException ex) { // thrown by BailErrorStrategy tokens.reset(); // rewind input stream parser.reset(); // back to standard listeners/handlers parser.addErrorListener(ConsoleErrorListener.INSTANCE); parser.setErrorHandler(new DefaultErrorStrategy()); // full now with full LL(*) parser.getInterpreter().setPredictionMode(PredictionMode.LL); parser.startRule(); } Errors in Roslyn
Roslyn has the following parsing errors:
- missing syntax ; Roslyn completes the corresponding node with the value of the property
IsMissing = true(a typical example is the Statement without a semicolon); - incomplete member ; a separate
IncompleteMembernode is created; - incorrect numeric, string, or character literal value (for example, too large, empty char): separate node with Kind equal to
NumericLiteralToken,StringLiteralTokenorCharacterLiteralToken; - extra syntax (for example, a randomly typed character): a separate node is created with Kind =
SkippedTokensTrivia.
The following code snippet shows all these errors.
(Roslyn is also convenient to feel with the help of the plug-in for Visual Studio Syntax Visualizer ):
namespace App { class Program { ; // Skipped Trivia static void Main(string[] args) { a // Missing ';' ulong ul = 1lu; // Incorrect Numeric string s = """; // Incorrect String char c = ''; // Incorrect Char } } class bControl flow { c // Incomplete Member } } Thanks to such thoughtful types of syntax errors, Roslyn can convert a tree with any number of errors back to character code into a character.
From theory to practice

For PHP parsers, T-SQL has been developed and laid out in the open source grammar php , tsql , plsql , which are visual applications of the above theory. For Java parsing, ready-made java and java8 grammars were used and compared. Also, to compare parsers based on Roslyn and ANTLR, we modified the grammar of C # to support versions 5 and 6 of the language. We described the interesting moments of development and use of these grammars below. Although SQL-based languages are more declarative than imperative, in their T-SQL and PL / SQL dialects there is support for imperative constructs ( Control flow ), for which for the most part our analyzer is being developed.
Java and Java8 grammar
For most cases, the parser is based on the Java 7 grammar faster than the parsing code, compared to Java 8, except for cases with deep recursion, for example, in the ManyStringConcatenation.java file, when parsing takes an order of magnitude more time and memory. I want to note that this is not just a synthetic example - we really came across files with such a “code-spaghetti”. As it turned out, the whole problem is precisely because of the left-recursive rules in expression. The Java 8 grammar contains rules with only primitive recursion. Rules with primitive recursion differ from the rules with the usual fact that they refer to themselves only in the left or right side of any alternative, but not simultaneously in both. An example of a regular recursive expression:
expression : expression ('*'|'/') expression | expression ('+'|'-') expression | ID ; And the following rules are obtained after transforming the rules above into primitive left-recursive ones:
expression : multExpression | expression ('+'|'-') multExpression ; multExpression : ID | multExpression ('*'|'/') ID ; Or non-recursive at all (however, in this case, the expressions after parsing will not be very convenient to process, because they will no longer be binary):
expression : multExpression (('+'|'-') multExpression)* ; If the operation has the right associativity (for example, exponentiation), then primitive right-recursive rules are used:
expression : <assoc=right> expression '^' expression | ID ; powExpression : ID '^' powExpression | ID ; On the one hand, the transformation of the levorcrusive rules eliminates the problem of large memory consumption and poor performance for rarely encountered files with a large number of homogeneous operations, on the other hand it introduces performance problems for the rest of the set of files. Therefore, it is advisable to use primitive recursion for expressions that can potentially be very deep (for example, string concatenation), and usual recursion for all other cases (for example, comparison of numbers).
Php grammar
For parsing PHP on the .NET platform there is a project Phalanger . However, we were not satisfied with the fact that this project is practically not developed, and also does not provide the Visitor interface for bypassing AST nodes (Walker only). Thus, it was decided to develop a PHP grammar under ANTLR in-house.
Register independent keywords.
As you know, in PHP all lexemes, with the exception of variable names (which begin with a '$') are case insensitive. In ANTLR, case insensitivity can be implemented in two ways:
Declaring fragmentary lexical rules for all Latin letters and using them in the following way:
Abstract: ABSTRACT; Array: ARRAY; As: AS; BinaryCast: BINARY; BoolType: BOOLEAN | BOOL; BooleanConstant: TRUE | FALSE; ... fragment A: [aA]; fragment B: [bB]; ... fragment Z: [zZ];A fragment in ANTLR is a part of a lexeme that can be used in other lexemes,
however, in itself, it is not a lexeme. This is essentially syntactic sugar for describing tokens. Without using fragments, for example, the first token can be written like this:Abstract: [Aa] [Bb] [Ss] [Tt] [Rr] [Aa] [Cc] [Tt]. The advantage of this approach is that the generated lexer is independent of runtime, since the characters in upper and lower case are declared immediately in grammar. Of the minuses it can be noted that the performance of the lexer with this approach is lower than in the second method.- Reducing the entire input stream of characters to a lower (or upper) register and starting a lexer, in which all tokens are described in this register. However, such a transformation will have to be done for each runtime (Java, C #, JavaScript, Python) separately, as described in the Implement a custom File or String Stream and Override LA . Moreover, with this approach, it is difficult to make some lexemes to be case-sensitive, while others are not.
In the developed PHP grammar, the first approach was used, since lexical analysis is usually performed in less time than the syntactic one. And despite the fact that the grammar was still dependent on runtime, this approach potentially simplifies the task of porting the grammar to other runtimes. Moreover, we created the Case Request RFC Case Insensitivity Proof of Concept - to facilitate the description of case-insensitive tokens. But unfortunately, he did not get much approval from the ANTLR community.
Lexical modes for PHP, HTML, CSS, JavaScript.
As you know, PHP code inserts can be located inside HTML code almost anywhere. In the same HTML, CSS and JavaScript code inserts can be found (these inserts are also called “islands”). For example, the following code (using Alternative Syntax ) is valid:
<?php switch($a): case 1: // without semicolon?> <br> <?php break ?> <?php case 2: ?> <br> <?php break;?> <?php case 3: ?> <br> <?php break;?> <?php endswitch; ?> or
<script type="text/javascript"> document.addEvent('domready', function() { var timers = { timer: <?=$timer?> }; var timer = TimeTic.periodical(1000, timers); functionOne(<?php echo implode(', ', $arrayWithVars); ?>); }); </script> Fortunately, ANTLR has a mechanism of so-called modes (mode) that allow you to switch between different sets of tokens under a certain condition. For example, the SCRIPT and STYLE modes are designed to generate a stream of tokens for JavaScript and CSS, respectively (but in this grammar they are actually simply ignored). In the default mode DEFAULT_MODE , HTML tokens are generated. It is worth noting that you can implement Alternative Syntax support in ANTLR without a single insertion of the target code into the lexer. Namely: nonEmptyStatement includes the inlineHtml rule, which, in turn, includes tokens obtained in the DEFAULT_MODE mode:
nonEmptyStatement : identifier ':' | blockStatement | ifStatement | ... | inlineHtml ; ... inlineHtml : HtmlComment* ((HtmlDtd | htmlElement) HtmlComment*)+ ; Complex context-sensitive constructs.
It is worth noting that although ANTLR supports only the grammar grammar, there are so-called actions in it, that is, insertions of arbitrary code that extend the admissible set of languages at least to context-sensitive ones. With the help of such inserts, processing of structures such as Heredoc and others was implemented:
<?php foo(<<< HEREDOC Heredoc line 1. Heredoc line 2. HEREDOC ) ; ?> T-SQL grammar
Despite the common root “SQL”, the T-SQL (MSSQL) and PL / SQL grammars are quite different from each other.
We would be happy not to develop our own parser for this difficult language. However, the existing parsers did not meet the criteria for completeness of coverage, relevance ( grammar under the abandoned GOLD-parser) and open source code in C # ( General SQL Parser ). TSQL MSDN. : , , ( SQL- MSDN). , . , . , - .
PL/SQL
PL/SQL , ANTLR3 . , java-runtime. java , AST ( , ). ,
decimal_key : {input.LT(1).getText().equalsIgnoreCase("decimal")}? REGULAR_ID :decimal_key: DECIMAL , .
C#-
, , 5 6 , . . -, runtime.
C# ( , , . . false ):
#if DEBUG && false Sample not compilied wrong code var 42 = a + ; #else // Compilied code var x = a + b; #endif , -, COMMENTS_CHANNEL DIRECTIVE . codeTokens , . . , ANTLR . — CSharpPreprocessorParser.g4 . true false #if , #elif , else , true , , . Conditional Symbols ( "DEBUG").
true , codeTokens , — . ( var 42 = a + ; ) . : CSharpAntlrParser.cs .
, , , (interpolation-expression), . , (, #0.##). , (regular), (verbatium), . MSDN .
, :
s = $"{p.Name} is \"{p.Age} year{(p.Age == 1 ? "" : "s")} old"; s = $"{(p.Age == 2 ? $"{new Person { } }" : "")}"; s = $@"\{p.Name} ""\"; s = $"Color [ R={func(b: 3):#0.##}, G={G:#0.##}, B={B:#0.##}, A={A:#0.##} ]"; , . CSharpLexer.g4 .
Testing
ANTLR
Roslyn, , . ANTLR :
- , . , TSQL antlr grammars-v4 . C# AllInOne.cs , Roslyn.
- .
- . PHP WebGoat , phpbb , Zend Framework . C# Roslyn-1.1.1 , Corefx-1.0.0-rc2 , ImageProcessor-2.3.0 , Newtonsoft.Json-8.0.2 .
ANTLR Roslyn
Release . ANTLR 4 4.5.0-alpha003 Roslyn (Microsoft.CodeAnalysis) 1.1.1.
WebGoat.PHP
— 885. — 137 248, — 4 461 768.
— 00:00:31 ( 55%, 45%).
PL/SQL Samples
— 175. — 1 909, — 55 741.
< 1 . ( 5%, 95%).
CoreFX-1.0.0-rc2
— 7329. — 2 286 274, — 91 132 116.
:
- Roslyn: 00:00:04 .,
- ANTLR: 00:00:24 . ( 12%; 88%).
Roslyn-1.1.1
— 6527. — 1 967 672, — 74 319 082.
:
- Roslyn: 00:00:03 .,
- ANTLR: 00:00:16 . ( 12%; 88%).
CoreFX Roslyn , C# ANTLR 5 Roslyn, . , « » , Roslyn, C#- Java, Python JavaScript ( ), .
, , . PHP, , . , , T-SQL PL/SQL ( ) ( 20). , C# SHARP: NEW_LINE Whitespace* '#'; SHARP: '#'; , 7 , 10 ! , , #, ( , ).
ANTLR Roslyn
C#-, ANTLR:
namespace App { class Program { static void Main(string[] args) { a = 3 4 5; } } class B { c } ANTLR
- token recognition error at: '' at 3:5
- mismatched input '4' expecting {'as', 'is', '[', '(', '.', ';', '+', '-', '*', '/', '%', '&', '|', '^', '<', '>', '?', '??', '++', '--', '&&', '||', '->', '==', '!=', '<=', '>=', '<<'} at 8:19
- extraneous input '5' expecting {'as', 'is', '[', '(', '.', ';', '+', '-', '*', '/', '%', '&', '|', '^', '<', '>', '?', '??', '++', '--', '&&', '||', '->', '==', '!=', '<=', '>=', '<<'} at 8:21
- no viable alternative at input 'c}' at 15:5
- missing '}' at 'EOF' at 15:6
Roslyn
- test(3,5): error CS1056: Unexpected character ''
- test(8,19): error CS1002:; expected
- test(8,21): error CS1002:; expected
- test(15,5): error CS1519: Invalid token '}' in class, struct, or interface member declaration
- test(15,6): error CS1513: } expected
, Roslyn , ANTLR. . . , Roslyn , . , ( , ), ANTLR . ANTLR , ( , ). , #if , . ( - ).
, ANTLR 4 , , . ( 70000 PHP ) , . lexer.Interpreter.ClearDFA() parser.Interpreter.ClearDFA() .
, . , GetAllTokens() ClearDFA() ( ) "Object reference not set to an instance of an object". , ANTLR C#, ( ) ( ) ReadWriterLockSlim .
Roslyn . 5 C# aspnet-mvc-6.0.0-rc1 , roslyn-1.1.1 , corefx , Newtonsoft.Json-8.0.2 ImageProcessor-2.3.0 200 .
Conclusion
ANTLR Roslyn. :
- AST Visitor Walker (Listener);
- , ANTLR 4;
- .NET;
- AST;
- DSL .
VladimirKochetkov « SAST» 40 60 .
Sources
- Modeling and Discovering Vulnerabilities with Code Property Graphs; Fabian Yamaguchi; 2014.
- Compilers: Principles, Techniques, and Tools; Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman; 2006.
- The Definitive ANTLR Reference; Terence Parr; 2014.
- Adaptive LL(*) Parsing: The Power of Dynamic Analysis, Terence Parr; Sam Harwell; 2014.
- Roslyn code & docs, https://github.com/dotnet/roslyn
- ANTLR grammars, https://github.com/antlr/grammars-v4
- ANTLR code, https://github.com/antlr/antlr4
Source: https://habr.com/ru/post/210772/
All Articles