List of DOM rendering optimizations implemented at the Javascript framework level
Since October 2009, I have been developing an application for searching and listening to music. I strive to organize the ability of the user to quickly interact with the interface, and as a means of speeding up the interaction, I use various methods for quickly rendering pages.
I suggest to get acquainted with the methods implemented by me in the application at the system level:
')
images from the part with the title "Attaching parts of changing collections at the same time ..."
The principle that the maximum of the visual part is transferred to CSS, and the change in the displayed one occurs by switching classes (for example, switching the class .hidden {display: none} instead of deleting / creating a node if you just need to hide the element). At the same time, the use of this principle allows us not to overload the browser with an excessive number of DOM nodes in the document.
in this example, to display the complete list of one of the nodes, the class wants_more_songs is simply switched
By atomic changes, I mean the principle that instead of completely reworking, re-parsing and building new large parts of the DOM structure, we change some specific part of an already existing DOM. Moreover, structure changes are tied to state changes as specifically as possible. If the class should change, change it through $ ('. Target_node'). AddClass ('active') , if the text is changed, then through $ ('. Target_node'). Text ('place an order') . The same goes for attributes and other parts of the DOM.
This is the first optimization, one of the first principles that I used (in connection with which I refused from template engines, especially in the underscorejs.template style). They will stop to not redraw the entire view when the state of the model changes, but to change only a part. According to them, I should not use .innerHTML (or jquery (...). Html () ), and should also cache samples of nodes (selectors), i.e. if I need to change any part, then I do not do a sample every time, but just take the necessary node from the cache.
I have these two things organized like this: the code is divided according to MVC, when changes of model states, information about changes is sent to the view, the function associated with the changeable state is triggered in the view. The function uses caching for samples.
For example, the model had the following states:
we changed them with this code:
states have become such:
The state of the track field has changed , and we sent these changes from the model to the view.
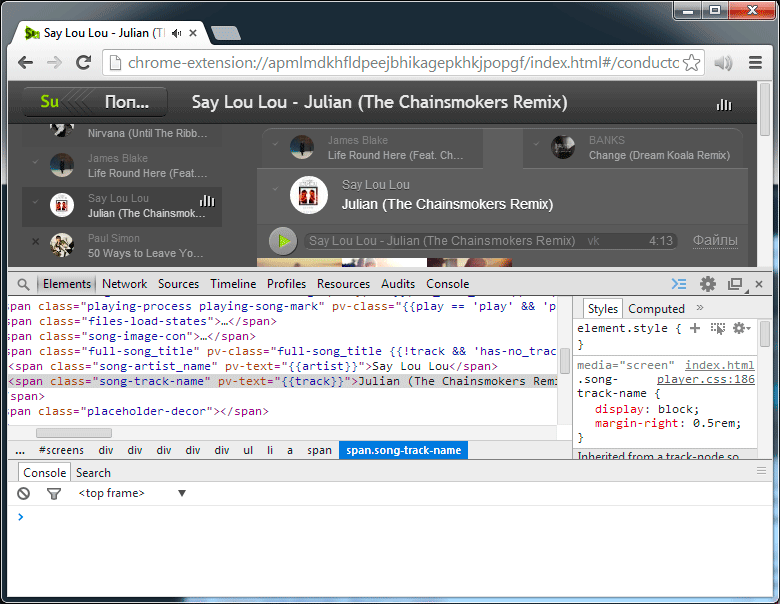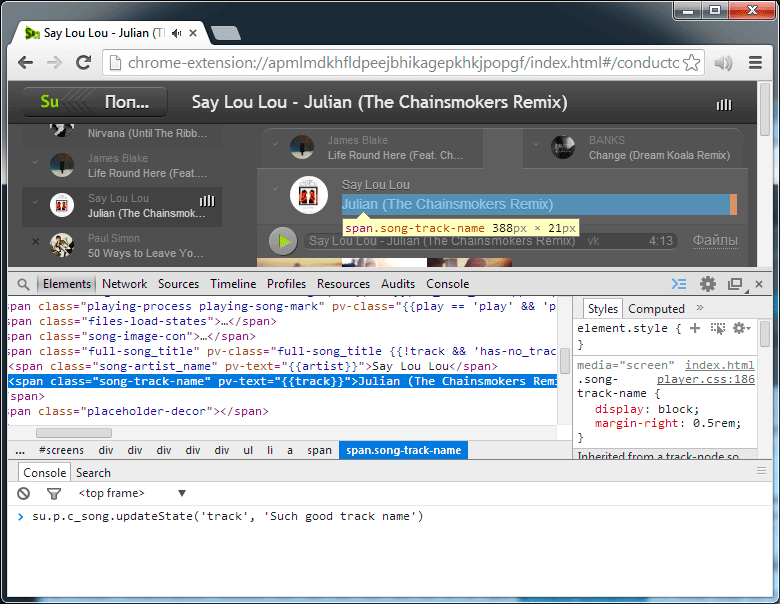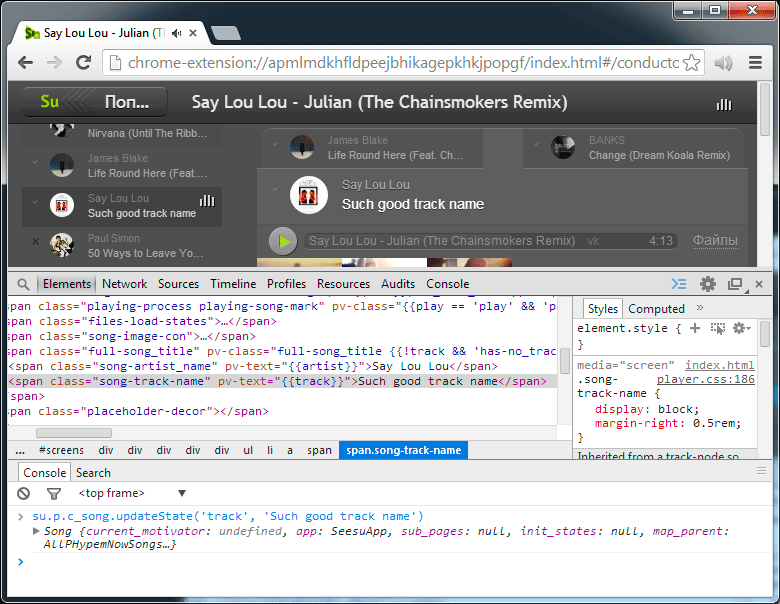
Animation, 3 frames. We change track state in model, 2 views instantly react to change
in View, a function that responds to a change in a particular state and makes a DOM change is triggered, in this case the following code will work:
(note the name of the method of the form 'stch-' + state_name , in this case 'stch-track' );
so specific changes are tied to specific parts of the DOM
Now let's pay attention to caching. If you make a selection with each change ( this.container.find ('. Song-track-name') ), this will negatively affect the performance, therefore, in order not to make a selection every time, for example, we immediately change this code:
( so I cached samples when I first started writing code, in accordance with the principles of atomic changes )
Later, when I started to make and use my template, for cases when it is necessary to make changes in the DOM in manual mode, I created a directive (<span pv-anchor = "track_name_con" class = "song-track-name"> </ span >) , which indicates that the node must be cached in the repository, because I will contact it manually (instead of writing the imperative code this.container.find ('. song-track-name') each time). Thus, I can rewrite the reaction to changes like this:
Such simple changes (when text or a class or some other attribute depends on the state) are usually described by other directives, and the pv-anchor directive is used for more complex changes (for example, affecting the location or size of other nodes) for hanging events in complex interactions. and for other cases where the DOM is changed manually.
The browser tries to render after all changes to the DOM have been made. However, he will have to calculate everything much earlier, and then again, if you try to count some properties. Therefore, I strive to read the DOM as rarely as possible, and if it does not work out, then cache (if possible) the read results.
Now there are fast-acting and relatively convenient template engines, for example, the template engine in angularjs and Facebook React . When I was at the very beginning of the journey, I did not know about the existence of convenient template engines that make these simple things (were they then?), So I did not use them.
When the code in the application evolved, divided according to the MVC principle, I still did not have a template engine, so I described all reactions to changes manually (as described in the example above).
Later I paid attention to the template engine in angularjs , which is rapidly gaining popularity, and also adhered to the principle of atomic changes (and had data binding). But I was more interested in the principle that state changes are tied to the properties of elements. This is done by declaring additional attributes in the html document.
I took from angularjs the code responsible for parsing the expressions, and the declarative way of date-binding through the attributes itself. This way of describing the connection leaves the HTML code working and allows the browser to perform the most difficult part of the work (HTML parsing), and then reuse the result (using the cloning method .cloneNode () .
Example:
This example uses the pv-class directive. According to its value, the element will always have the lula_page usual_page classes, and also, if the model does not have the state vmp_show, then the element must have one more class - “hidden”. The template engine will overwrite .className automatically when the state of vmp_show changes , however, if template is not used, the className will not be overwritten and its value will be the same as we originally recorded it - class = "user_tag_page usual_page" .
This method is not only convenient and allows for optimization of parsing, but also gives the potential for performance optimizations associated with making changes to the DOM. For example, performance optimization is implemented when the classes of elements change. Perhaps you know that the jQuery (node) .addClass ('sample-class') method, before adding a class, checks if the element has such a class, i.e. makes additional reading before writing (at least until classList api appears). But since in the template we know the full set of classes and the set of classes that should be at the current state of the model (for example, " lula_page usual_page hidden "), we can immediately do this:
those. we didn’t have to read the previous value of the className at all, because we only change it if the state has changed, and we know the entire list of the states on which it depends, and what exactly the class value should be.
Knowing the state of the models and the structure of the DOM structure, they don’t need to read this DOM at all (unless it depends on the size of any other parts).
However, specifically with reading classes, the described principle may not give a performance boost at all (at least, a modern browser should understand that it does not need to calculate any dimensions or arrangements in order to provide the full value of className ), but this is a small bonus that I get from the template.
However, in the record related to the release of the latest, currently released version of jquery (1.11, 2.1, January 24, 2014), the developers reported (see under the heading Fewer forced layouts) that they corrected the extra layout change changes as the class changed. Those. it matters, and quite seriously. Chrome developers are also working on this issue.
Reading the size or position of the elements causes a premature calculation of all other changes made - this is a good place for optimizations. For cases where this is possible, I use caching.
For example, to set the width of the nodes that display the current progress of playback and loading, I use not pixel width, but pixel.
normal width file bar progress

width of the progress bar when the list of files is expanded

width progress bar with a different width of the window
To calculate it is necessary to know the width of the parent element. The width of the parent element can vary from the width of the screen and the full or single display of the list of found files.
In this case, the width does not depend on any other parameters. With the same width and list display mode, the node width will always be the same. I use states that can affect the width as part of the key when accessing the repository.
The first parameter of the method ( getProgressWidth ) is simply a function that the getBoxDemension method itself will call if there is no value for the given key in the repository.
All other parameters are simply added to the string. In this case, the p_wmss in the line becomes 'false' or 'true' (only one file or the entire list is displayed). As a result, the key may look like for example progress_c-width-1372-false .
When the window width or display mode is changed, the new width for the new key will be calculated (if it is not already in the repository), and parts depending on this width will be automatically redrawn.
In fact, two more lines are added to the key each time - this is the name of the position of the slot-slot of this view inside the parent view (in the terminology of my framework, which automatically assigns this name to the position of the view), and the same is true for the parent view parent view. This is used for cases when the same view is used in different places, and therefore the calculated dimensions depend not only on, for example, the width of the screen and the display mode of the file list, but also on where the view is used.
Additionally, you can see the videotape , where Google’s employee Paul Lewis tells about this in part of his report. See also the joint article by Paul Lewis and Paul Irish on the same topic. The list of properties that somehow affect the rendering of that article.
The framework implements the collection of all states in the packet before being sent to the views for model states that depend on a different state and change when the state is updated. But only with this model, and not with the entire application.
When the model state is updated, all other model states that depend on it will also be automatically updated, and the changes will be collected in one large package and sent to the view so that rendering takes place in one iteration. Calculations of changes will occur until new changes in this model cease to appear, i.e. sending will be delayed only by calculating the states of this model (and nothing more). Changes in states that depend on other models (for example, on our updated one) will be calculated in these models only after the updated model sends changes to its views.
Thus, the accumulation of state changes is realized, which is not delayed for too long.
To render in one iteration when manually updating several states, I use the following method:
instead of doing two such steps:
In the future, in addition to this principle, I am using the requestAnimationFrame to accumulate changes directly on the template side.
When changing lists, the list is not redrawn again.
When you change lists, DOM parts associated with list items are not recreated.
When the lists change, the new order of DOM elements of the list is set not by unpinning completely from the document, but by unpinning, if necessary, and by attaching changes in their position (or new) elements to a strictly defined place for them.
The DOM corresponding to the elements of the list to be attached is not attached individually, but with the help of createDocumentFragment , if the elements follow each other. The elements are attached to the documentDrafment in the desired order, then the documentDrafment is attached to the document in the right place using the methods after , before or append .
Thus, when changing the list in the DOM, only the most necessary and minimal changes occur.

a list with the last element highlighted in this list (the global variable $ 0 in the console is the selected and highlighted element, $ 1, $ 2, $ 3 - the elements selected before)
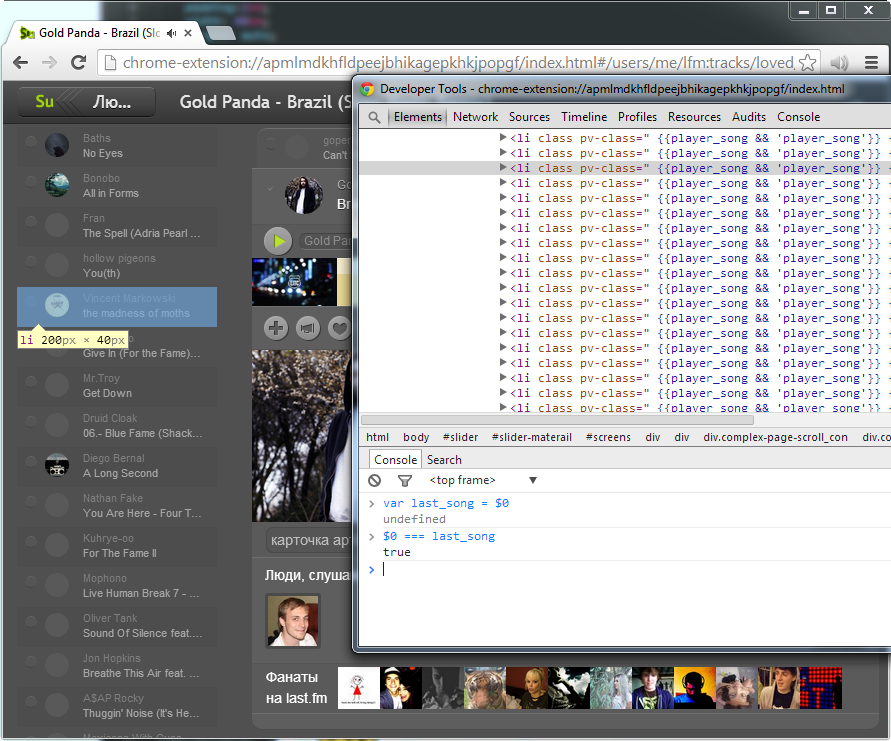
A large number of new compositions have been added to the list, while the element responsible for the presentation of the composition (the list has changed) that was chosen before has remained absolutely the same node.
Additionally, you can read the translation of the recording from the blog of John Resig.
If necessary, draw a large structure with elements nested into each other (even simple things are most often implemented as nested parts), including if necessary to draw a list, the framework in the first iteration will draw views for models at the very top of the structure. Inside this iteration, there will be two more: the very base that defines the visual dimensions will be drawn, then the details will be drawn (relating directly to this model, reactions to changes in its states). In the next iteration, the framework will draw nested models, and this will continue until the nesting ends. All iterations are separated and can be discharged using setTimeout , if drawing takes for example more than 200 ms (in the future I plan to replace requestAnimationFrame), in order not to block the interface and allow the browser to render what is already there. For the user, the interface will change gradually, i.e. it will see that some changes occur, in contrast to a simpler way, when after a long pause (during which the browser does not respond to clicks and displays the same thing), the browser drastically changes the picture.
It looks like a progressive jpeg or can remind you of game engines. In moments when the engine does not have enough resources, and the image appears first in poor quality (unfiltered textures, low poly models, etc.), and then the picture is improved.
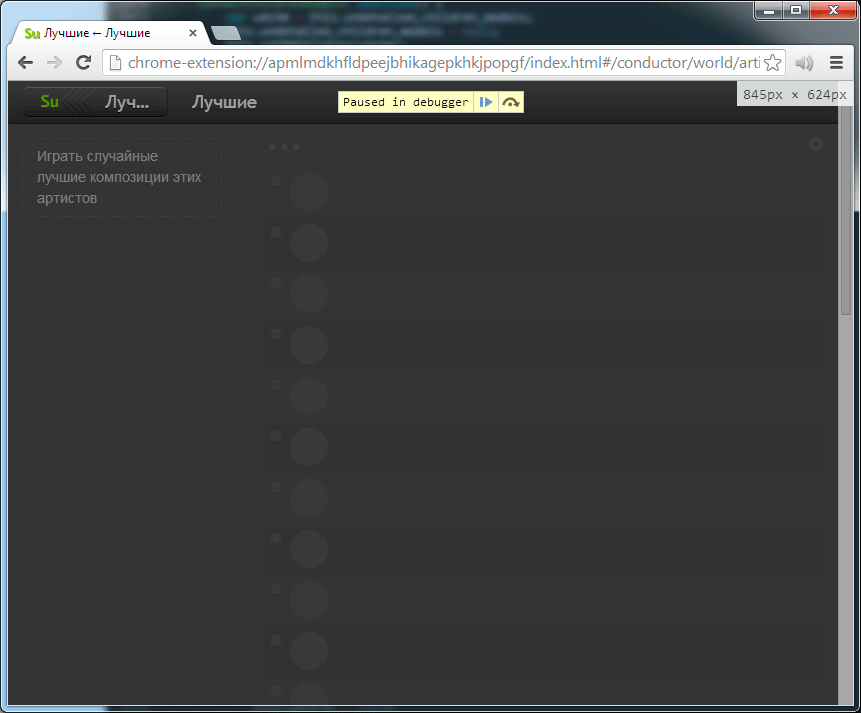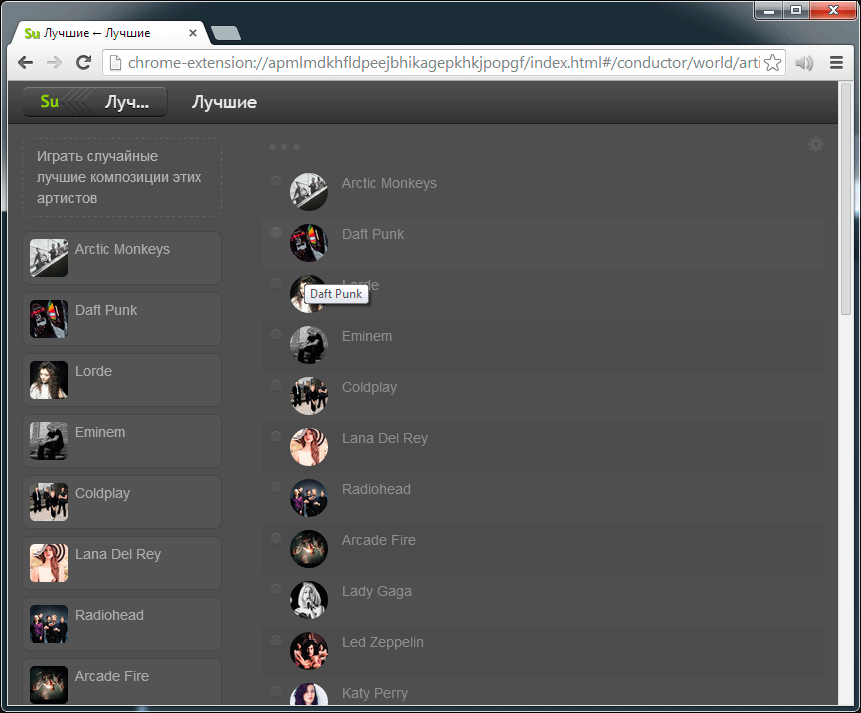 Animation, 2 frames. Progressive rendering: first garabits, then details. It was possible to catch the moment and capture the first part only in the debugging mode, which is why the darkening is visible.
Animation, 2 frames. Progressive rendering: first garabits, then details. It was possible to catch the moment and capture the first part only in the debugging mode, which is why the darkening is visible.
Getting the DOM structure for the View is approximately as follows: the HTML parser of the browser itself once parses the HTML (performs the hardest work, it happens beforehand, while loading the entire page), then, if necessary, the result is cloned through the DOM API ( .cloneNode () ). The copies from the template are created by cloning the DOM of the template tree, after which the directives associated with this node are read and understood.
So that after cloning the nodes, you do not have to re-read the attributes to search for directives (such service data is not copied when the node is cloned), as well as to reuse objects that are created by directives (for subsequent use by the template engine) in order to use memory more efficiently and rarer garbadge collector, a solution was found that allows you to quickly copy the service data from the original node to the clone node.
This happens as follows: the template DOM structure is parsed, analyzed. All the nodes of elements with directives are set to the pvprsd property with a unique value corresponding to a unique set of directives that is stored in the repository and can be used in the future. After all necessary elements are set to a property, starting from the root, the structure is expanded into an array. The template structure is cloned from the root, and this instance is also cloned. Exemplar further in a similar way from the root is decomposed into an array. Such cloning and unfolding ensures that there will be absolutely similar nodes in the arrays under the same indices. After this, the usual pass through the array copies pvprsd from the element of the first array to the element of the instance array:
I talked about the optimization methods that I implemented in the application at the system level. This allows me not to program the same optimization every time, but, following some rules, to write code resulting from high-performance. Of course, I use other methods, I use profiling, but this happens in some specific cases and additional time is spent.
I would be interested to know what other optimizations can be implemented at the system level. For example, automatically creating visually isolated areas based on iframe / object elements — as done manually in this example: http://fb.html5isready.com .
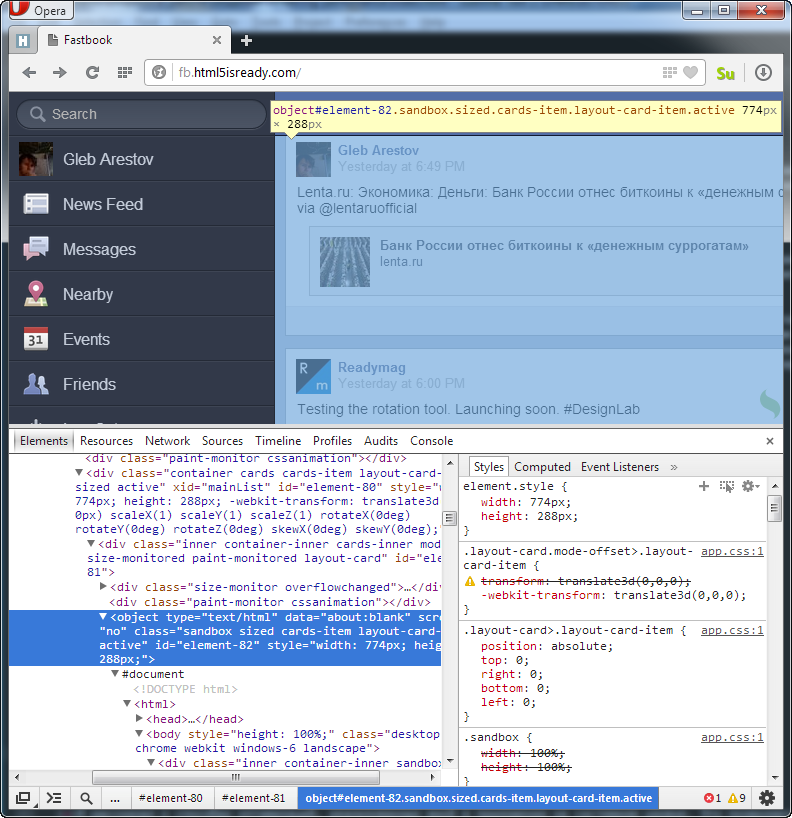
part of the visual representation of the application is inside the object element
I have not implemented such a method, but I imagine it realistic to implement it automatically - when a template, its instances, styles, operational state changes themselves fall into an automatically generated, based on some criteria, an iframe.
Please tell us about other implementations of optimization techniques at the system level that you know about (like such or such ). Or about somewhere expressed ideas of such optimizations ( example ), or about their ideas, if they are ready to share.
I suggest to get acquainted with the methods implemented by me in the application at the system level:
- Using CSS and switching classes instead of rebuilding the DOM tree
- Pervasive caching of element selections ( $ ('div.active_part span.highlighter') ), atomic change operations (instead of a total redraw, instead of redoing large portions of the DOM tree)
- Minimize DOM reads while writing state changes
- Caching the size and location of elements (this saves from unnecessary computation when reading these values in the presence of other changes: reading while changing many parts of the tree has a very negative effect on performance)
- Accurate, not delayed accumulation of changes needed in the DOM
- Attaching parts of changing collections at a time (for example, when 3 new items are inserted in the middle of the list; createDocumentFragment ) at a specific place ( after , before ) instead of unpinning the entire collection from the DOM and re-attaching it (and instead of redrawing the entire list)
- Progressive asynchronous rendering: the picture is drawn immediately with a small amount of detail, then more details appear
- Clone nodes (as part of templating)
- Caching and using the cache of the results of parsing DOM templates
')
images from the part with the title "Attaching parts of changing collections at the same time ..."
Using CSS and switching classes instead of rebuilding the DOM tree
The principle that the maximum of the visual part is transferred to CSS, and the change in the displayed one occurs by switching classes (for example, switching the class .hidden {display: none} instead of deleting / creating a node if you just need to hide the element). At the same time, the use of this principle allows us not to overload the browser with an excessive number of DOM nodes in the document.
in this example, to display the complete list of one of the nodes, the class wants_more_songs is simply switched
Ubiquitous caching of node samples, atomic changes
By atomic changes, I mean the principle that instead of completely reworking, re-parsing and building new large parts of the DOM structure, we change some specific part of an already existing DOM. Moreover, structure changes are tied to state changes as specifically as possible. If the class should change, change it through $ ('. Target_node'). AddClass ('active') , if the text is changed, then through $ ('. Target_node'). Text ('place an order') . The same goes for attributes and other parts of the DOM.
This is the first optimization, one of the first principles that I used (in connection with which I refused from template engines, especially in the underscorejs.template style). They will stop to not redraw the entire view when the state of the model changes, but to change only a part. According to them, I should not use .innerHTML (or jquery (...). Html () ), and should also cache samples of nodes (selectors), i.e. if I need to change any part, then I do not do a sample every time, but just take the necessary node from the cache.
I have these two things organized like this: the code is divided according to MVC, when changes of model states, information about changes is sent to the view, the function associated with the changeable state is triggered in the view. The function uses caching for samples.
For example, the model had the following states:
{ artist: "The Killers", track: null } we changed them with this code:
track_model.updateState('track', "When You Were Young"); states have become such:
{ artist: "The Killers", track: "When You Were Young" } The state of the track field has changed , and we sent these changes from the model to the view.
Animation, 3 frames. We change track state in model, 2 views instantly react to change
in View, a function that responds to a change in a particular state and makes a DOM change is triggered, in this case the following code will work:
'stch-track': function(new_state, old_state){ this.container .find('.song-track-name') .text(new_state) .toggleClass('hidden', !new_state); } (note the name of the method of the form 'stch-' + state_name , in this case 'stch-track' );
so specific changes are tied to specific parts of the DOM
Now let's pay attention to caching. If you make a selection with each change ( this.container.find ('. Song-track-name') ), this will negatively affect the performance, therefore, in order not to make a selection every time, for example, we immediately change this code:
'stch-track': function(new_state, old_state){ if (!this.track_name_node){ this.track_name_node = this.container.find('.song-track-name'); // } this.track_name_node.text(new_state).toggleClass('hidden', !new_state); } ( so I cached samples when I first started writing code, in accordance with the principles of atomic changes )
Later, when I started to make and use my template, for cases when it is necessary to make changes in the DOM in manual mode, I created a directive (<span pv-anchor = "track_name_con" class = "song-track-name"> </ span >) , which indicates that the node must be cached in the repository, because I will contact it manually (instead of writing the imperative code this.container.find ('. song-track-name') each time). Thus, I can rewrite the reaction to changes like this:
'stch-track': function(new_state, old_state){ this.tpl.ancs['track_name_con'].text(new_state).toggleClass('hidden', !new_state); } Such simple changes (when text or a class or some other attribute depends on the state) are usually described by other directives, and the pv-anchor directive is used for more complex changes (for example, affecting the location or size of other nodes) for hanging events in complex interactions. and for other cases where the DOM is changed manually.
Minimize DOM reads while writing state changes
The browser tries to render after all changes to the DOM have been made. However, he will have to calculate everything much earlier, and then again, if you try to count some properties. Therefore, I strive to read the DOM as rarely as possible, and if it does not work out, then cache (if possible) the read results.
Now there are fast-acting and relatively convenient template engines, for example, the template engine in angularjs and Facebook React . When I was at the very beginning of the journey, I did not know about the existence of convenient template engines that make these simple things (were they then?), So I did not use them.
When the code in the application evolved, divided according to the MVC principle, I still did not have a template engine, so I described all reactions to changes manually (as described in the example above).
Later I paid attention to the template engine in angularjs , which is rapidly gaining popularity, and also adhered to the principle of atomic changes (and had data binding). But I was more interested in the principle that state changes are tied to the properties of elements. This is done by declaring additional attributes in the html document.
I took from angularjs the code responsible for parsing the expressions, and the declarative way of date-binding through the attributes itself. This way of describing the connection leaves the HTML code working and allows the browser to perform the most difficult part of the work (HTML parsing), and then reuse the result (using the cloning method .cloneNode () .
Example:
<div class="user_tag_page usual_page" pv-class="lula_page usual_page {{!vmp_show && 'hidden'}}" ></div> This example uses the pv-class directive. According to its value, the element will always have the lula_page usual_page classes, and also, if the model does not have the state vmp_show, then the element must have one more class - “hidden”. The template engine will overwrite .className automatically when the state of vmp_show changes , however, if template is not used, the className will not be overwritten and its value will be the same as we originally recorded it - class = "user_tag_page usual_page" .
This method is not only convenient and allows for optimization of parsing, but also gives the potential for performance optimizations associated with making changes to the DOM. For example, performance optimization is implemented when the classes of elements change. Perhaps you know that the jQuery (node) .addClass ('sample-class') method, before adding a class, checks if the element has such a class, i.e. makes additional reading before writing (at least until classList api appears). But since in the template we know the full set of classes and the set of classes that should be at the current state of the model (for example, " lula_page usual_page hidden "), we can immediately do this:
node.className = "lula_page usual_page hidden"; those. we didn’t have to read the previous value of the className at all, because we only change it if the state has changed, and we know the entire list of the states on which it depends, and what exactly the class value should be.
Knowing the state of the models and the structure of the DOM structure, they don’t need to read this DOM at all (unless it depends on the size of any other parts).
However, specifically with reading classes, the described principle may not give a performance boost at all (at least, a modern browser should understand that it does not need to calculate any dimensions or arrangements in order to provide the full value of className ), but this is a small bonus that I get from the template.
However, in the record related to the release of the latest, currently released version of jquery (1.11, 2.1, January 24, 2014), the developers reported (see under the heading Fewer forced layouts) that they corrected the extra layout change changes as the class changed. Those. it matters, and quite seriously. Chrome developers are also working on this issue.
Cache size and location of elements
Reading the size or position of the elements causes a premature calculation of all other changes made - this is a good place for optimizations. For cases where this is possible, I use caching.
For example, to set the width of the nodes that display the current progress of playback and loading, I use not pixel width, but pixel.
normal width file bar progress
width of the progress bar when the list of files is expanded
width progress bar with a different width of the window
To calculate it is necessary to know the width of the parent element. The width of the parent element can vary from the width of the screen and the full or single display of the list of found files.
In this case, the width does not depend on any other parameters. With the same width and list display mode, the node width will always be the same. I use states that can affect the width as part of the key when accessing the repository.
this.getBoxDemension(this.getProgressWidth, 'progress_c-width', window_width, !!p_wmss); The first parameter of the method ( getProgressWidth ) is simply a function that the getBoxDemension method itself will call if there is no value for the given key in the repository.
All other parameters are simply added to the string. In this case, the p_wmss in the line becomes 'false' or 'true' (only one file or the entire list is displayed). As a result, the key may look like for example progress_c-width-1372-false .
When the window width or display mode is changed, the new width for the new key will be calculated (if it is not already in the repository), and parts depending on this width will be automatically redrawn.
In fact, two more lines are added to the key each time - this is the name of the position of the slot-slot of this view inside the parent view (in the terminology of my framework, which automatically assigns this name to the position of the view), and the same is true for the parent view parent view. This is used for cases when the same view is used in different places, and therefore the calculated dimensions depend not only on, for example, the width of the screen and the display mode of the file list, but also on where the view is used.
Additionally, you can see the videotape , where Google’s employee Paul Lewis tells about this in part of his report. See also the joint article by Paul Lewis and Paul Irish on the same topic. The list of properties that somehow affect the rendering of that article.
Accurate, not delayed accumulation of changes necessary to make in the DOM
The framework implements the collection of all states in the packet before being sent to the views for model states that depend on a different state and change when the state is updated. But only with this model, and not with the entire application.
When the model state is updated, all other model states that depend on it will also be automatically updated, and the changes will be collected in one large package and sent to the view so that rendering takes place in one iteration. Calculations of changes will occur until new changes in this model cease to appear, i.e. sending will be delayed only by calculating the states of this model (and nothing more). Changes in states that depend on other models (for example, on our updated one) will be calculated in these models only after the updated model sends changes to its views.
Thus, the accumulation of state changes is realized, which is not delayed for too long.
To render in one iteration when manually updating several states, I use the following method:
.updateManyStates({ artist: 'artist_224', title: 'radnomd title 014' }) instead of doing two such steps:
updateState('artist', 'artist_224') updateState('title', 'radnomd title 014') In the future, in addition to this principle, I am using the requestAnimationFrame to accumulate changes directly on the template side.
Attaching portions of a changing collection at a time ( createDocumentFragment ) to a specific location ( after , before ) instead of detaching the entire collection from the DOM and reattaching
When changing lists, the list is not redrawn again.
When you change lists, DOM parts associated with list items are not recreated.
When the lists change, the new order of DOM elements of the list is set not by unpinning completely from the document, but by unpinning, if necessary, and by attaching changes in their position (or new) elements to a strictly defined place for them.
The DOM corresponding to the elements of the list to be attached is not attached individually, but with the help of createDocumentFragment , if the elements follow each other. The elements are attached to the documentDrafment in the desired order, then the documentDrafment is attached to the document in the right place using the methods after , before or append .
Thus, when changing the list in the DOM, only the most necessary and minimal changes occur.
a list with the last element highlighted in this list (the global variable $ 0 in the console is the selected and highlighted element, $ 1, $ 2, $ 3 - the elements selected before)
A large number of new compositions have been added to the list, while the element responsible for the presentation of the composition (the list has changed) that was chosen before has remained absolutely the same node.
Additionally, you can read the translation of the recording from the blog of John Resig.
Progressive asynchronous rendering: the picture is drawn immediately with a small amount of detail, then more details appear
If necessary, draw a large structure with elements nested into each other (even simple things are most often implemented as nested parts), including if necessary to draw a list, the framework in the first iteration will draw views for models at the very top of the structure. Inside this iteration, there will be two more: the very base that defines the visual dimensions will be drawn, then the details will be drawn (relating directly to this model, reactions to changes in its states). In the next iteration, the framework will draw nested models, and this will continue until the nesting ends. All iterations are separated and can be discharged using setTimeout , if drawing takes for example more than 200 ms (in the future I plan to replace requestAnimationFrame), in order not to block the interface and allow the browser to render what is already there. For the user, the interface will change gradually, i.e. it will see that some changes occur, in contrast to a simpler way, when after a long pause (during which the browser does not respond to clicks and displays the same thing), the browser drastically changes the picture.
It looks like a progressive jpeg or can remind you of game engines. In moments when the engine does not have enough resources, and the image appears first in poor quality (unfiltered textures, low poly models, etc.), and then the picture is improved.
Animation, 2 frames. Progressive rendering: first garabits, then details. It was possible to catch the moment and capture the first part only in the debugging mode, which is why the darkening is visible.Node cloning
Getting the DOM structure for the View is approximately as follows: the HTML parser of the browser itself once parses the HTML (performs the hardest work, it happens beforehand, while loading the entire page), then, if necessary, the result is cloned through the DOM API ( .cloneNode () ). The copies from the template are created by cloning the DOM of the template tree, after which the directives associated with this node are read and understood.
Caching and using the cache of the results of parsing DOM templates
So that after cloning the nodes, you do not have to re-read the attributes to search for directives (such service data is not copied when the node is cloned), as well as to reuse objects that are created by directives (for subsequent use by the template engine) in order to use memory more efficiently and rarer garbadge collector, a solution was found that allows you to quickly copy the service data from the original node to the clone node.
This happens as follows: the template DOM structure is parsed, analyzed. All the nodes of elements with directives are set to the pvprsd property with a unique value corresponding to a unique set of directives that is stored in the repository and can be used in the future. After all necessary elements are set to a property, starting from the root, the structure is expanded into an array. The template structure is cloned from the root, and this instance is also cloned. Exemplar further in a similar way from the root is decomposed into an array. Such cloning and unfolding ensures that there will be absolutely similar nodes in the arrays under the same indices. After this, the usual pass through the array copies pvprsd from the element of the first array to the element of the instance array:
var getAll = function(node) { var result = []; var iteration_list = [ node ]; var i = 0; while( iteration_list.length ){ var cur_node = iteration_list.shift(); if ( cur_node.nodeType != 1 ){ continue; } for ( i = 0; i < cur_node.childNodes.length; i++ ) { iteration_list.push( cur_node.childNodes[i] ); } result.push( cur_node ); } return result; }; var cloned = this.onode.cloneNode(true); var all_onodes = getAll(this.onode); var all_cnodes = getAll(cloned); Conclusion
I talked about the optimization methods that I implemented in the application at the system level. This allows me not to program the same optimization every time, but, following some rules, to write code resulting from high-performance. Of course, I use other methods, I use profiling, but this happens in some specific cases and additional time is spent.
I would be interested to know what other optimizations can be implemented at the system level. For example, automatically creating visually isolated areas based on iframe / object elements — as done manually in this example: http://fb.html5isready.com .
part of the visual representation of the application is inside the object element
I have not implemented such a method, but I imagine it realistic to implement it automatically - when a template, its instances, styles, operational state changes themselves fall into an automatically generated, based on some criteria, an iframe.
Please tell us about other implementations of optimization techniques at the system level that you know about (like such or such ). Or about somewhere expressed ideas of such optimizations ( example ), or about their ideas, if they are ready to share.
Source: https://habr.com/ru/post/210558/
All Articles