We parallelize processes to speed up computations and tasks in Linux.

Almost all personal computers released over the past few years have at least a dual-core processor. If you, the reader, are not very old computer or not some budget laptop, then most likely you are the owner of a multiprocessor system. And if you still like to play games, then about a hundred GPU-cores are available to you. However, the lion's share of time all this power gathering dust. Let's try to fix it.
Introduction
Very rarely, we use the power of several processors (or cores) to solve everyday tasks, and the use of a powerful graphics processor is often reduced to computer games. Personally, I don’t like it: I’m working - why should the processor rest? Disorder. It is necessary to adopt all the capabilities and advantages of multiprocessors (multi-core) and parallelize all that is possible, saving them a lot of time. And if you also connect a powerful video card with a hundred cores on board to work ... which, of course, will fit only for a narrow circle of tasks, but it will nevertheless speed up the calculations quite significantly.
')
Linux is very strong in this regard. First, in the majority of distributions out of the box are available good tools for parallel execution, and secondly, a lot of software is written, designed for multi-core systems. On the flexibility of customization, I think, do not even need to talk. The only thing that can cause problems is the drivers for the video card, but there's nothing you can do.
To begin with we will be defin with methods of parallelization. There are two of them: by the means of the application itself, which runs several parallel threads (multithreading) to perform the task. Another method is to run multiple copies of the application, each of which will process a certain portion of data. The operating system in this case will independently distribute the processes to the cores or processors (multitasking).
We parallelize directly in the terminal
Let's begin, perhaps, with parallel start of processes directly from a terminal window. Running terminal processes running for a long time is not a problem. And what if you need two such processes? “It’s not a problem either,” you say, “we’ll just run the second process in another terminal window.” And if you want to run ten or more? Hmm ... The first thing that comes to mind is to use the xargs utility. If you give it the option --max-procs = n, then the software will execute n processes at the same time, which is of course good for us. The official manual recommends using grouping by arguments with the --max-procs option (the -n option): without this, problems with parallel launch are possible. For example, imagine that we need to archive a bunch of large (or small) files:
$ cd folder/with/files $ ls | xargs -n1 --max-procs=4 gzip How much time have we won? Is it worth bothering with this? It will be appropriate to bring the numbers. On my quad-core processor, the usual archiving of five files, each of which weighed about 400 MB, took 1 minute 40 seconds. Using
xargs --max-procs=4 elapsed time was reduced almost four times: 34 seconds! I think the answer to the question is obvious.Let's try something more interesting. Convert, for example, WAV files to MP3 using lame:
$ ls *.wav | xargs -n1 --max-procs=4 -I {} lame {} -o {}.mp3 Looks awkward? I agree. But parallel execution of processes is not the main task of xargs, but only one of its capabilities. In addition, xargs does not behave very well with passing special characters, such as space or quotation marks. And here we come to the aid of a wonderful utility called GNU Parallel. The software is available in standard repositories, but I do not recommend installing it from there: in the Ubuntu repositories, for example, I came across a version two years ago. It is better to compile yourself a fresh version from source:
$ wget ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2 $ tar xjf parallel-latest.tar.bz2 $ cd parallel-20130822 $ ./configure && make # make install The very name of the utility speaks of its narrow specialization. Indeed, Parallel is much more convenient for parallelization, and its use looks more logical. The above example using Parallel instead of xargs turns into this:
$ ls *.wav | parallel lame {} -o {}.mp3 By the way, if you are sitting under Ubuntu or Kubuntu, then the example will not work, giving out incomprehensible errors. This is fixed by adding the '--gnu' key (this also applies to the following example). Read more about the problem here .
And why do not we set the number of simultaneously running processes? Because Parallel will do it for us: it will determine the number of cores and will run on the process to the core. Of course, you can also set this number manually using the -j option. By the way, if you need to run a task on different machines, then to improve portability, it is convenient to set this option in the -j + 2 format, which in this particular case means “to run two more processes at a time than there are computing units in the system”.
If you make friends with Parallel c Python, then we get a powerful tool for parallel execution of tasks. For example, downloading web pages from the Web and their subsequent processing may look like this:
$ python makelist.py | parallel -j+2 'wget "{}" -O - | python parse.py' But even without Python, this utility has plenty of features. Be sure to read the man - there are a lot of interesting examples.
In addition to Parallel and xargs, of course, there are a lot of other utilities with similar functionality, but they can’t do anything that the first two don’t.
With this sorted out. Moving on.
Parallel compilation
Collecting something from the source is a common thing for Linux users. Most often, you have to collect something insignificant, for such projects, no one thinks about any parallel compilation. But sometimes more projects come across, and it takes almost an eternity to wait until the end of the build: the build, for example, Android (AOSP) from source (in one thread) lasts about five hours! For this kind of project you need to start all the cores.
First of all, I think it is obvious that the actual compilation itself (GCC, for example) is not parallelized. But large projects are often composed of a large number of independent modules, libraries, and other things that can and should be compiled simultaneously. Of course, we don’t need to think about how to parallelize the compilation - make will take care of this, but only if the dependencies are written in the makefile. Otherwise, make will not know in which sequence to build and what can be built at the same time and what cannot. And since the makefile is the concern of the developers, for us it all comes down to executing the command
$ make -jN after which make will begin building the project, simultaneously running up to N tasks.
By the way, about choosing the value for the -j parameter. The web often recommends using the number 1.5 * <number of computing units>. But this is not always true. For example, the project build with a total weight of 250 MB on my quad core was the fastest with the -j parameter value equal to four (see screenshot).
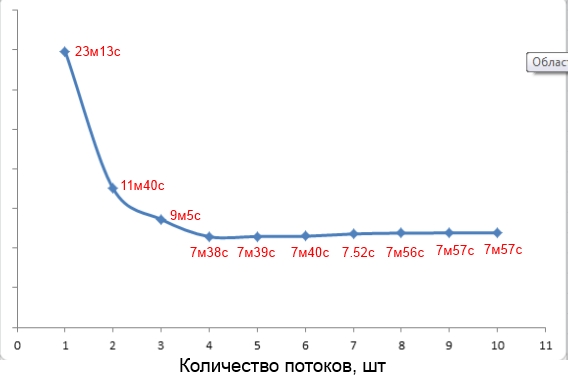
Compilation time versus parameter value
To win some more time, you can add the key '-pipe' to the GCC. With this key, data transfer between different stages of compilation occurs through the exchange channels (pipes), and not through temporary files, which slightly (very little) speeds up the process.
In addition to make, you can also try pmake , a parallel build system written in Python. For users, its use is not much different from make, but for developers it can be quite interesting, since it has more extensive features than the standard tool.
Parallel rsync
If you have ever used Rsync to synchronize a huge number of small files with a remote server, you probably noticed a decent delay in the receiving file list stage. Is it possible to speed up this stage by paralleling? Sure you may. Much time is spent on network latency. To minimize these temporary losses, we will run several copies of Rsync, and in order not to copy the same files - we will set each copy, for example, into a separate directory. To do this, we use a combination of the --include and --exclude parameters, like this:
$ rsync -av --include="/a*" --exclude="/*" -P login@server:remote /localdir/ $ rsync -av --include="/b*" --exclude="/*" -P login@server:remote /localdir/ You can manually start multiple copies in different terminals, but you can connect Parallel:
$ cat directory_list.txt | parallel rsync -av --include="/{}*" --exclude="/*" ... Turbojet file copying over SSH
Typically, to synchronize directories between two hosts, Rsync runs on top of SSH. By speeding up the SSH connection, let's speed up the work of Rsync. And SSH can be accelerated by using the OpenSSH HPN patch set, eliminating a number of bottlenecks in the server-side and client-side SSH buffering mechanism. In addition, HPN uses a multi-threaded version of the AES-CTR algorithm, which improves file encryption speed (activated with the
-oCipher=aes[128|192|256]-ctr ). To check if you have OpenSSH HPN installed, drive in the terminal: $ ssh -V and look for the HPN substring entry. If you have the usual OpenSSH, you can install the HPN version like this:
$ sudo add-apt-repository ppa:w-rouesnel/openssh-hpn $ sudo apt-get update -y $ sudo apt-get install openssh-server Then add the following lines to
/etc/ssh/sshd_config : HPNDisabled no TcpRcvBufPoll yes HPNBufferSize 8192 NoneEnabled yes then restart the SSH service. Now create the Rsync / SSH / SCP connection again and evaluate the winnings.

We include support HPN
File compression
All the accelerations that we have done above are based on the simultaneous launch of several copies of the same process. The process scheduler of the operating system resolved these processes between the cores (processors) of our machine, due to which we received acceleration. Let's go back to the example where we compressed several files. But what if you need to compress one huge file, and even slow bzip2? Fortunately, file compression lends itself very well to parallel processing — the file is divided into blocks, and they are compressed independently. However, standard utilities, like gzip and bzip2, do not have this functionality. Fortunately, there are many third-party products that can do this. Consider only two of them: parallel analog gzip - pigz and analog bzip2 - pbzip2 . These two utilities are available in the standard Ubuntu repositories.
Using pigz is absolutely no different from working with gzip, except the ability to specify the number of threads and the block size. In most cases, the block size can be left at default, and as the number of threads, it is desirable to specify a number equal to (or 1–2 more) the number of processors (cores) of the system:
$ pigz -c -p5 backup.tar > pigz-backup.tar.gz Executing this command on the backup.tar file weighing 620 MB took me 12.8 seconds, the resulting file weighed 252.2 MB. Processing the same file with gzip:
$ gzip -c backup.tar > gzip-backup.tar.gz took 43 seconds. The resulting file at the same time weighed only 100 KB less, compared to the previous one: 252.1 MB. Again, we received almost fourfold acceleration, which is good news.
Pigz can only parallelize compression, but not unpacking, which can't be said about pbzip2 - which both can do. Using the utility is similar to its non-parallel version:
$ pbzip2 -c -p5 backup.tar > pbzip-backup.tar.bz2 Processing the same backup.tar file took me 38.8 seconds, the size of the resulting file was 232.8 MB. Compression using normal bzip2 took 1 min 53 s, with a file size of 232.7 MB.
As I said, with pbzip2, you can speed up unpacking. But here you need to take into account one nuance - in parallel, you can only unpack what was previously packed in parallel, that is, only archives created with pbzip2. Unpacking in several streams of a regular bzip2 archive will be done in one stream. Well, some more numbers:
- normal unpacking - 40.1 s;
- unpacking in five streams - 16.3 s.
It remains only to add that the archives created using pigz and pbzip2 are fully compatible with archives created using their non-parallel counterparts.
Encryption
By default, eCryptfs is used to encrypt the home directory in Ubuntu and all derivative distributions. At the time of writing, eCryptfs did not support multi-threading. And this is especially noticeable in folders with a large number of small files. So if you have a multi-core, then eCryptfs use impractical. A better replacement would be to use dm-crypt or Truecrypt systems. True, they can only encrypt entire partitions or containers, but they do support multi-streaming.
INFO
The NPF packet filter from NetBSD 6.0 allows you to achieve maximum performance on multi-core systems through parallel multi-stream processing of packets with the minimum number of locks.
If you want to encrypt only a specific directory, and not a whole disk, then you can try EncFS . It is very similar to eCryptfs, but it works, unlike the latter, not in kernel mode, but using FUSE, which makes it potentially slower than eCryptfs. But it supports multi-threading, so on multi-core systems there will be a speed advantage. In addition, it is very easy to install (available in most standard repositories) and use. All you need to do
$ encfs ~/.crypt-raw ~/crypt enter a passphrase, and that’s all: encrypted versions of files will be in .crypt-raw, and unencrypted in crypt. To unmount EncFS, run:
$ fusermount -u ~/name Of course, all this can be automated. How to do this, you can read here .
I love to watch kernels plow
We load the processor to the full, but sometimes it is necessary to monitor its work. In principle, almost every distribution has a good snap to monitor processor utilization, including information about each individual core or processor. In Kubuntu, for example, KSysGuard very successfully displays the current load of cores (see the screen “KSysGuard on a quad-core system”).
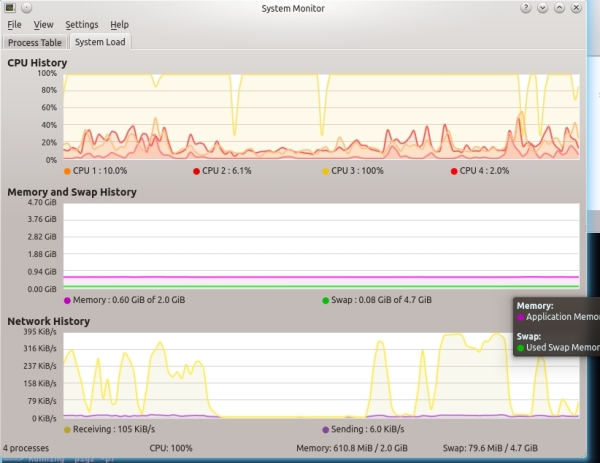
KSysGuard on quad-core system
But there are other interesting utilities that allow you to contemplate the work of the processor. Fans of console solutions will love htop, a more colorful and interactive equivalent of top. I also advise you to pay attention to Conky - a powerful and easily customizable system monitor. It is very easy to configure it to monitor the workload of each core and processor as a whole. For each core, you can display a separate schedule. In the screenshot you can see my version of the utility configuration.

This is what Conky looks like.
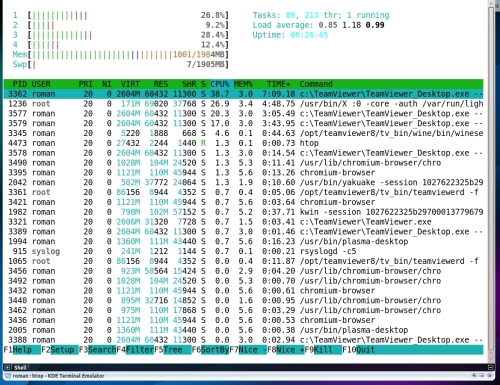
Htop in action
I uploaded the contents of the corresponding configuration file here . On the Web, by the way, is full of interesting configs, which can be used as a basis and remade for yourself.
But these utilities provide only information about the workload, which often may not be enough. Mpstat from the sysstat set provides more interesting information, such as the idle time of each kernel, the time spent waiting for I / O, or the time taken to process interrupts.

Mpstat utility output
GPU not only for games
It is no secret that modern GPUs have very large processing power. But due to the fact that the GPU cores have a special architecture and a limited set of available commands, the GPU is only suitable for solving a narrow circle of tasks. Previously, only shading gurus could perform calculations on the GPU. Now, video card manufacturers are doing everything possible to simplify the lives of enthusiasts and developers who want to use the power of graphics processors in their projects: CUDA from NVIDIA, AMD FireStream, OpenCL standard. Every year computing on the GPU is becoming more and more accessible.
Calculating hashes
Today, of the tasks launched on the GPU, the most popular is probably the calculation of hashes. And all this because of Bitcoin mining, which, in fact, lies in the calculation of hashes. Most bitcoin miners are available for Linux. If you want to mine Bitcoins and if your graphics processor supports OpenCL (if it supports CUDA, then OpenCL also), then I recommend paying attention to bfgminer : it is fast, convenient and functional, though not that simple to set up.
Accelerate Snort with GPU
A very interesting concept called Gnort was developed by researchers from the Greek FORTH Institute (Foundation for Research and Technology - Hellas). They offer to increase the efficiency of detecting attacks by Snort by porting the code responsible for checking regular expressions onto the GPU. According to the graphs given in the official PDF of the study , they achieved an almost twofold increase in the throughput of Snort.
But not a single bitcoin live. Nothing prevents the use of GPU power for brute force hashes (in order to find out your forgotten password, of course, no more). In solving this problem, the oclHashcat-plus utility, a true harvester with hashes, has proven itself well. It can pick up MD5 hashes with salt and without salt, SHA-1, NTLM, cached domain passwords, MySQL database passwords, GRUB passwords, and this is not even half the list.
GPU encryption
Weibin Sun and Xing Lin students from the University of Utah in the framework of the KGPU project presented us a very interesting application of graphics processor power . The essence of the project is to transfer the execution of some parts of the Linux kernel code to a CUDA-compatible GPU. The first developers decided to put the AES algorithm on the GPU. Unfortunately, the development of the project stopped at this, although the developers promised to continue the work. But besides this, the existing experience can be used to speed up AES encryption in eCryptfs and dm-crypt, it’s a pity that the kernel version 3.0 and higher is not supported.
GPU Performance Monitoring
Why not? Of course, the load of each GPU core cannot be found, but at least you can get some information about what is happening on the GPU. The CUDA-Z program (almost analogous to the GPU-Z Windows program), in addition to various static information about the GPU, can also get dynamic: the current speed of data exchange between the graphics processor and the machine, as well as the overall performance of all GPU cores in flops.
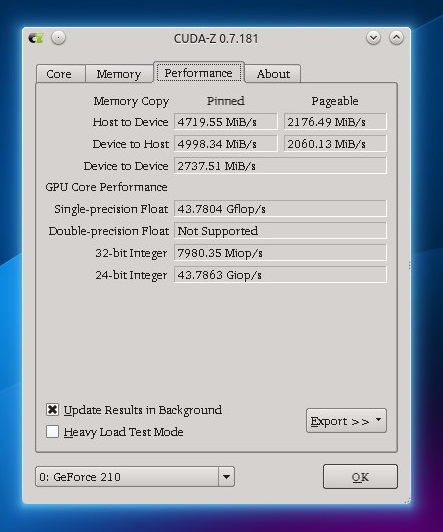
CUDA-Z tab with GPU performance information
findings
Multicore or multiprocessor workstations entered our everyday life quite a long time ago - it's time to change our single-threaded approach when working with them. After all, the parallelization of tasks on such systems gives us a huge time gain, which we have already seen.
useful links
- Tuning JVM to increase the performance of Java EE applications on a multi-core system:
bit.ly/JavaTuning- Measuring multi-core CPU performance with MPI tests: bit.ly/MPIbenchmark
- If you have nothing to occupy your computer, give your computing power to search for drugs, study global warming and other interesting scientific research: https://boinc.berkeley.edu

First published in the Hacker magazine dated 10/2013.
Publication on Issuu.com
Subscribe to "Hacker"


Source: https://habr.com/ru/post/210480/
All Articles