Treating tree structures and unified AST
The previous article in the series was devoted to the theory of source parsing using ANTLR and Roslyn. It noted that the process of signature-based code analysis in our PT Application Inspector project is divided into the following steps:
- parsing into a language dependent view (abstract syntax tree, AST);
- AST to language independent unified format (AST, UAST);
- direct comparison with the templates described on DSL.
This article is devoted to the second stage, namely: processing the AST using Visitor and Listener strategies, transforming the AST into a unified format, simplifying the AST, and also the algorithm of matching tree structures.
Content
- AST bypass
- Types of Unified AST Nodes
- Converter testing
- Simplify uast
- Algorithm comparison of tree structures
- Conclusion
AST bypass
As you know, the parser converts the source code into a parse tree (into a tree in which all insignificant tokens are removed), called AST. There are various ways to process such a tree. The simplest is to process the tree using a recursive walk of the descendants in depth. However, this method is applicable only for very simple cases, in which there are few types of nodes and the processing logic is simple. In other cases, it is necessary to bring the processing logic of each type of node into separate methods. This is done using two typical approaches (design patterns): Visitor and Listener.
Visitor and Listener
In the Visitor, to handle the descendants of a node, you must manually call their crawl methods. Moreover, if the parent has three children, and only methods for two nodes are called, then part of the subtree will not be processed at all. In the Listener (Walker), the same methods of visiting all descendants are called automatically. In the Listener, there is a method called at the beginning of a site visit (enterNode) and a method called after a site visit (exitNode). These methods can also be implemented using an event mechanism. Visitor methods, unlike Listener, can return objects and can even be typed, i.e. when declaring CSharpSyntaxVisitor, each Visit method will return an AstNode object, which in our case is a common ancestor for all other nodes of the unified AST.
Thus, when using the Visitor design pattern, the tree transformation code is more functional and concise due to the fact that it does not need to store information about visited nodes. In the figure below you can see that, for example, when converting the PHP language, unnecessary HTML and CSS nodes are cut off. The traversal order is indicated by numbers. Listener is usually used for data aggregation (for example, from files of type CSV), conversion of one code to another (JSON -> XML). Read more about this in The Definitive ANTLR 4 Reference .
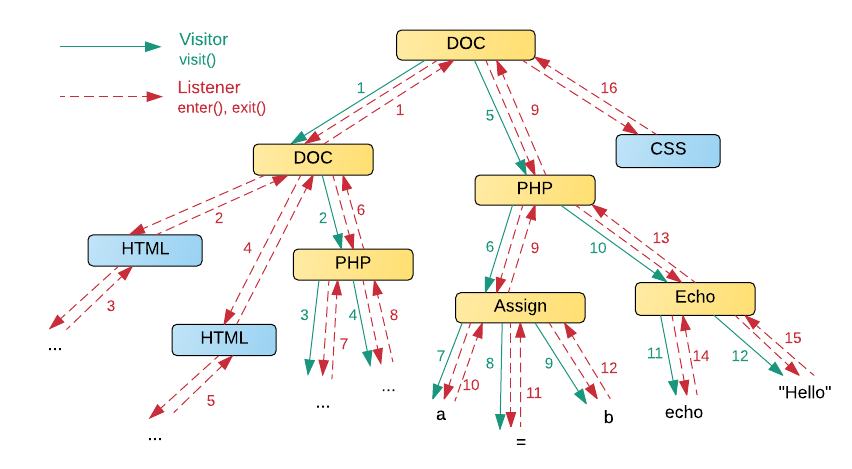
Differences in Visitor at ANTLR and Roslyn.
The implementation of Visitor and Listener may vary in libraries. For example, the table below describes the classes and methods of the Visitor and Listener in Roslyn and ANTLR.
| ANTLR | Roslyn | |
|---|---|---|
| Visitor | AbstractParseTreeVisitor <Result> | CSharpSyntaxVisitor <Result> |
| Listener | IParseTreeListener | CSharpSyntaxWalker |
| Default | DefaultResult | DefaultVisit (SyntaxNode node) |
| Visit | Visit (IParseTree tree) | Visit (SyntaxNode node) |
Both ANTLR and Roslyn have methods for returning the default result (if the Visitor method is not overridden for some syntax), as well as the generic Visit method, which itself determines which Visitor special method should be called.
An ANTLR visitor generates its own Visitor for each syntax grammar rule. There are also special types of methods:
VisitChild(IRuleNode node); used to implement a default site bypass.VisitTerminal(IRuleNode node); used when traversing terminal nodes, i.e. tokens.VisitErrorNode(IErrorNode node); used when traversing tokens resulting from parsing code with lexical or syntactical errors. For example, if the statement is missing a semicolon at the end, then the parser inserts such a token and indicates that it is erroneous. More details about parsing errors are written in the previous article .AggregateResult(AstNode aggregate, AstNode nextResult); A rarely used method designed to aggregate the results of the crawling of descendantsShouldVisitNextChild(IRuleNode node, AstNode currentResult); A rarely used method designed to determine whether the next child of anodeshould be processed depending on the result of thecurrentNode.
Roslyn visitor has special methods for each syntactic construction and a generalized Visit method for all nodes. However, there are no methods for bypassing "intermediate" constructs in it, unlike ANTLR. For example, in Roslyn, there is no method for VisitStatement assertions, but there are special VisitDoStatement , VisitExpressionStatement , VisitForStatement , etc. As VisitStatement it is possible to use the generalized Visit . Another difference is that bypassing trivial (SyntaxTrivia) nodes, i.e. Nodes that can be deleted without losing any information about the code (spaces, comments) are called along with methods of traversing basic nodes and tokens.
The disadvantage of ANTLR visitors is that the names of the generated Visitor methods are directly dependent on the style of writing grammar rules, so they may not fit into the overall style of the code. For example, in sql grammars it is customary to use the so-called Snake case , in which underscores are used to separate words. Roslyn methods are written in the style of the C # code. Despite the differences, the processing methods of tree structures in Roslyn and ANTLR with new versions are more and more unified, which is good news (in ANTLR version 3 and below, there was no Visitor and Listener mechanism).
Grammar and Visitor in ANTLR.
In ANTLR for the rule
ifStatement : If parenthesis statement elseIfStatement* elseStatement? | If parenthesis ':' innerStatementList elseIfColonStatement* elseColonStatement? EndIf ';' ; the VisitIfStatement(PHPParser.IfStatementContext context) method VisitIfStatement(PHPParser.IfStatementContext context) will be formed in which the context will have the following fields:
parenthesisis a single node;elseIfStatement*- array of nodes. If there is no syntax, then the length of the array is zero;elseStatement?- optional node. If there is no syntax, it is null;If,EndIf- terminal nodes, begin with a capital letter;':',';'- terminal nodes are not contained in context (available only through GetChild ()).
It should be noted that the fewer rules exist in grammar, the easier and faster Visitor is to write. However, the duplicate syntax also needs to be put into separate rules.
Alternative and elemental labels in ANTLR
Often there are situations in which a rule has several alternatives and it would be more logical to handle these alternatives in separate methods. Fortunately, in ANTLR 4 for this, there are special alternative labels that begin with the # character and are added after each alternative rule. When generating the parser code, a separate Visitor method is generated for each label, which allows to avoid a large amount of code if the rule has many alternatives. It should be noted that either all alternatives or none should be marked. You can also use a rule element label to denote a terminal that takes a set of values:
expression : op=('+'|'-'|'++'|'--') expression #UnaryOperatorExpression | expression op=('*'|'/'|'%') expression #MultiplyExpression | expression op=('+'|'-') expression #AdditionExpression | expression op='&&' expression #LogicalAndExpression | expression op='?' expression op2=':' expression #TernaryOperatorExpression ; For this rule, ANTLR will be generated by VisitExpression , VisitUnaryOperatorExpression , VisitMultiplyExpression and so on. Each visitor will have an expression array consisting of 1 or 2 elements, as well as the literal op. Thanks to the tags, the visitor code will be more clean and concise:
public override AstNode VisitUnaryOperatorExpression(TestParser.UnaryOperatorExpressionContext context) { var op = new MyUnaryOperator(context.op().GetText()); var expr = (Expression)VisitExpression(context.expression(0)); return new MyUnaryExpression(op, expr); } public override AstNode VisitMultiplyExpression(TestParser.MultiplyExpressionContext context) { var left = (Expression)VisitExpression(context.expression(0)); var op = new MyBinaryOpeartor(context.op().GetText()); var right = (Expression)VisitExpression(context.expression(1)); return new MyBinaryExpression(left, op, right); } public override AstNode VisitTernaryOperatorExpression(TestParser.TernaryOperatorExpressionContext context) { var first = (Expression)VisitExpression(context.expression(0)); var second = (Expression)VisitExpression(context.expression(1)); var third = (Expression)VisitExpression(context.expression(2)); return new MyTernaryExpression(first, second, third); } ... Without alternative labels, Expression processing would be in the same method and the code would look like this:
public override AstNode VisitExpression(TestParser.ExpressionContext context) { Expression expr, expr2, expr3; if (context.ChildCount == 2) // Unary { var op = new MyUnaryOperator(context.GetChild<ITerminalNode>(0).GetText()); expr = (Expression)VisitExpression(context.expression(0)); return new MyUnaryExpression(op, expr); } else if (context.ChildCount == 3) // Binary { expr = (Expression)VisitExpression(context.expression(0)); var binaryOp = new MyBinaryOpeartor(context.GetChild<ITerminalNode>(0).GetText()); expr2 = (Expression)VisitExpression(context.expression(1)); return new MyBinaryExpression(expr, binaryOp, expr2); ... } else // Ternary { var first = (Expression)VisitExpression(context.expression(0)); var second = (Expression)VisitExpression(context.expression(1)); var third = (Expression)VisitExpression(context.expression(2)); return new MyTernaryExpression(first, second, third); } } It should be noted that alternative labels exist not only in ANTLR, but also other means for describing grammars. For example, in Nitra, a label with an assignment sign is placed to the left of the alternative, unlike ANTLR:
syntax Expression { | IntegerLiteral | BooleanLiteral | NullLiteral = "null"; | Parenthesized = "(" Expression ")"; | Cast1 = "(" !Expression AnyType ")" Expression; | ThisAccess = "this"; | BaseAccessMember = "base" "." QualifiedName; | RegularStringLiteral; Types of Unified AST Nodes
When developing the structure of the unified AST, we were guided by the structure of the AST from the NRefactory project in view of the fact that it is quite simple for us, and obtaining a reliable tree (fidelity reversible to the source code with an accuracy of a character) was not required. Any node is an inheritor of AstNode and has its own NodeType type, which is also used at the template matching stage and when deserializing from JSON. The structure of the nodes looked like this:
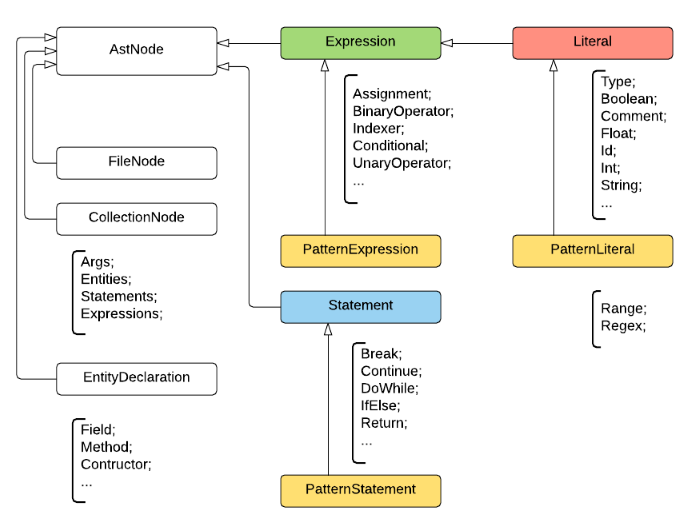
In addition to the type, each node has a property that stores the location in the code (TextSpan), which is used to display it in the source code when matching with the template. A non-terminal node stores a list of child nodes, and a terminal node holds a numeric, string, or other primitive value.
In order to map the AST nodes of different languages, a table was compiled, in which the lines were the syntax of certain nodes, and the columns were their implementation in C #, Java, PHP, which looked like this:
| Node | Args | C # | Java | Php | MCA | MDA |
|---|---|---|---|---|---|---|
| While | cond: Expression; stmt: Statement | while (cond) stmt | while (cond) stmt | while (cond) stmt | While (cond, stmt) | While (cond, stmt) |
| Binary op | l, r: Expression; op: Literal | l op r | l op r | l op r | BinaryOp (l, op, r) | BinaryOp (l, op, r) |
| ... | ... | ... | ... | ... | ... | ... |
| Checked | checked: Expression | checked (checked) | - | - | checked | Checked (checked) |
| NullConditional | a: Expression, b: Literal | a? .b | - | - | a! = null? ab: null | a? .b |
In this table:
- Expression ; expression, has a return value.
- Statement ; The statement (instruction) has no return value.
- Literal ; terminal node.
- Most Common Ast (MCA) is the most unified AST. This node is constructed if all three languages contain the type of such or similar node (for example, IfStatement, AssignmentExpression);
- Most Detail Ast (MDA) most detailed AST. This node is built if at least one language contains this type of node (for example, FixedStatenemt
fixed (a) { }for C #). These nodes are more relevant to SQL-like languages, due to the fact that the last declarative languages and between T-SQL and C # the difference is much greater than, for example, between PHP and C #.
In addition to the nodes shown in the figure (and the “pattern nodes”, which are described in the next section), there are also artificial nodes in order to still build the Most Common Ast node, “losing” as little syntax as possible. These nodes are:
- MultichildExpression; inherited from Expression and contains a collection of other Expression;
- WrapperExpression; inherited from Expression and contains a node with an arbitrary type AstNode;
- WrapperStatement; inherited from Statement and contains a node with an arbitrary type AstNode.
In imperative languages, programming the basic constructs is the expression Expression and the statement Statement . The former have a return value, the latter are used to perform any operations. Therefore, in our module, we also focused mainly on them. They are the basic building blocks for the implementation of CFG and other source code representations necessary for the implementation of taint analysis in the future. It is worth adding that knowledge of syntactic sugar, generics, and other language-specific things is not required to search for vulnerabilities in code. Therefore, syntactic sugar can be disclosed in standard constructions, and information about specific things can be deleted altogether.
Pattern nodes are artificial nodes representing custom patterns. For example, ranges of numbers, regular expressions are used as literal patterns.
Converter testing
For the code analyzer, the priority is to test the entire code, and not its individual parts. To solve this problem, it was decided to redefine visiting methods for all types of nodes. In this case, if the visitor is not used, then it generates an exception new ShouldNotBeVisitedException(context) . This approach simplifies development because IntelliSense takes into account which methods are redefined and which are not, therefore it is easy to determine which methods visitors have already implemented.
We also have some thoughts on how to improve testing of the coverage of the entire code. Each node of the unified AST stores the coordinates of the corresponding source code. Moreover, all terminals are connected with lexemes, i.e. certain sequences of characters. Since all lexemes should be processed as far as possible, the total coverage ratio can be expressed by the following formula, in which uterms are unified AST terminals and terms are ordinary Roslyn or ANTLR AST terminals:

This metric expresses code coverage with a single coefficient, which should tend to unity. Of course, the estimate for this coefficient is approximate, but it can be used for refactoring and improving the visitor code. For a more reliable analysis, you can also use a graphical representation of the covered terminals.
Simplify AST
After converting a regular AST to UAST, the latter needs to be simplified. The simplest and most useful optimization is constant folding. For example, there is a lack of code associated with setting too long a cookie lifetime: cookie.setMaxAge(2147483647); The argument in parentheses can be written as one number, for example 86400 , and some arithmetic expression, for example 60 * 60 * 24 . Another example is string concatenation when searching for SQL injection and other vulnerabilities.
To implement this task, a custom interface was implemented, and Visitor itself was implemented only for UAST. Since the simplification of the AST simply reduces the number of tree nodes, the Visitor is typed, accepting and returning the same type. Thanks to the support of reflection in .NET, it turned out to implement such a Visitor with a small amount of code. Since each node contains other nodes or terminal primitive values, using reflection, it is possible to extract all members of a particular node and process them, causing other visitors to recursively.
Algorithm mapping AST and templates
The template search algorithm consists of enumerating all AST nodes and matching each node with a template represented as a tree structure. Two nodes are comparable if they have the same types and, depending on the type, some of the conditions are met:
- Recursive comparison of descendants.
- Comparison of simple literal types (identifier, strings, numbers).
- Comparison of extended literal types (regular expressions, ranges). Comments are included in this group.
- Comparison of complex extended types (expressions, the sequence of the Statement).
This algorithm is based on simple principles that allow achieving high performance with a relatively small amount of code implementing them. The latter is achieved due to the fact that the CompareTo method for comparing nodes is implemented for the base class, terminals, and a small number of other nodes. More advanced matching algorithms, based on finite automata, have not yet been implemented to improve performance. However, this algorithm is problematic (or even impossible) to use for more advanced analysis, for example, taking into account the semantics of the language, i.e. communication between different AST nodes.
Conclusion
In this article, we looked at the Visitor and Listener patterns for treating trees, and also talked about the structure of a unified AST. In the following articles we will tell:
- about approaches to storing templates (Hardcoded, Json, DSL);
- developing and using DSL to describe patterns;
- examples of real templates and their search in open source projects;
- CFG, DFG and taint analysis.
')
Source: https://habr.com/ru/post/210060/
All Articles