Access iFrame content from another domain
Today I want to talk about how we in our project indexisto.com made an analogue tool Google Webmaster Marker. Let me remind you that Marker is a tool in the Google Webmaster office that allows you to annotate your Open Graph pages with tags. To do this, you simply select with a mouse a piece of text on the page and indicate that this is a title, and this is a rating. Your page is loaded into the Iframe in the webmaster's office.
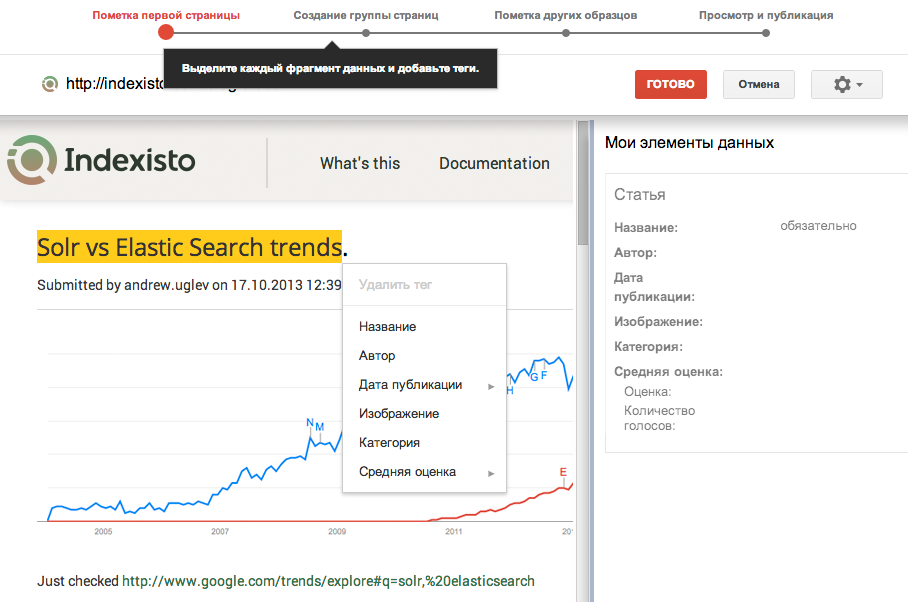
Now Google, having met a similar page on your site, already knows what content is published on it, and how beautiful it is to parse it into substance (article, product, video ..)
')
We needed similar functionality. The task seemed simple and client-side exclusively. However, in practice, the solution lies at the interface between the client side and the serverside (“pure” JS programmers may not know anything about various proxy servers and go to the projectile for a very long time). However, I did not find an article on the Internet that would describe all the technology from start to finish. I would also like to say thanks to the BeLove user and our security personnel for their help.
In our case, we wanted the webmaster to conveniently (with the mouse) get the xPath value to specific elements on his page.
And so in our admin a person should enter the URL of the page of his site, we will display it in iFrame, a person will click the mouse where necessary, we will get the desired xPath. Everything would be OK, but we do not have access to the content of the page from another domain loaded into the iframe in our admin panel (our domain), due to the security policy of the browser.
Some people advised me to use CORS. Trendy technology that solves many problems with access to content from another domain in the browser and allows you to bypass the same origin policy restrictions.
A site that wants to give access to its content on the pages of another domain simply writes the http header:
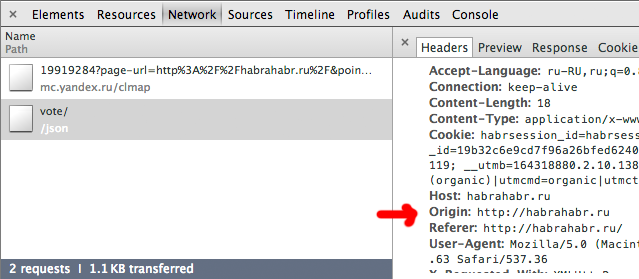
And in the header of the http request coming from the page of another domain from the browser should be the field of origin:
it is clear that the origin field for the request is added by the browser itself. Let's add an article on Habré and see that modern browsers add Origin even to the request for the same domain:
but:
Another fashionable technology. Sandbox is an attribute of the Iframe tag. As one of the values of this attribute, you can set the value of allow-same-origin . Before I started digging this topic, I did not know what exactly this attribute does, but it sounded very tempting. However, the sandbox attribute simply restricts what the page loaded in the iframe can do and has nothing to do with the problem of access from the parent document to the contents of the frame.
Specifically, the value of allow-same-origin (or rather its absence) just says that the iframe should always be regarded as loaded from someone else’s domain (for example, you cannot send an AJAX request to the domain of the parent document from such a frame)
Time to take care of how big brother has done
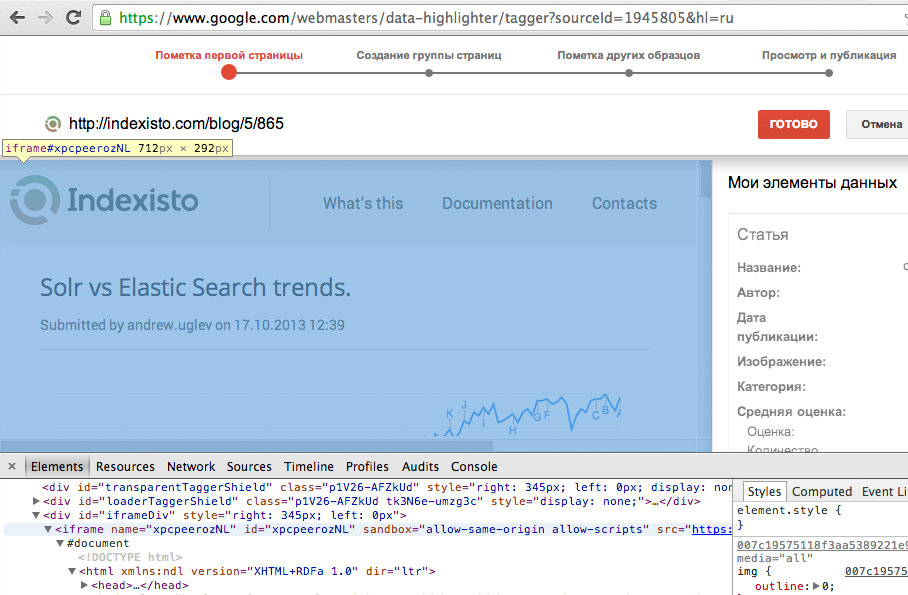
Pay attention to the src attribute of the iframe element:
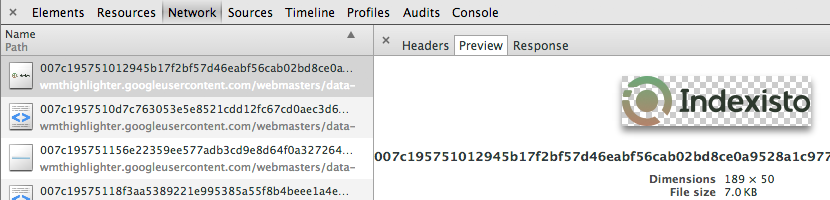
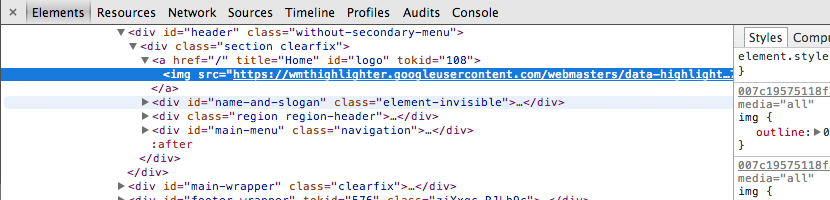
All resources that your page uses are also stored on Google proxy servers. For example, our logo on the proxy server Google .
It immediately seemed that in order to do the same you need to raise a full-fledged proxy like CGIProxy . This proxy server does about the same thing as Google’s wmthighlighter.googleusercontent.com
However, if you narrow down the task, it is much easier to write a simple proxy yourself. The fact is that doing so does Google, driving all the content through a proxy page is not necessary. We just need to give html of any page from our domain, and resources can be uploaded from the original domain. Https we have so far discarded.
The task of super performance or convenience settings is not worth it, and it can be done quickly and on anything, from node.js to php. We wrote a servlet in Java.
What should the proxy servlet do? Through the get parameter, we get the url of the page you want to load, then download the page.
Be sure to determine the page encoding (via http response or charset in html) - our proxy should respond in the same encoding as the page we downloaded. We will also define the Content-Type just in case, although it is clear that we get the page in text / html and give it the same way.
* For those who like to evaluate someone else's code: in our team we all have the same formatting options for the eclicpse code, and while saving the file, Eclipse itself adds to all final variables if they do not change anywhere else. Which by the way is quite convenient in the end.
It is necessary to go through all the attributes with src and href in the page (paths of style files, images), and replace the relative URLs with absolute ones. Otherwise, the page will try to download images from some folders on our proxy, which we naturally do not have. In any language there are ready-made classes or you can find code snippets for this case on stackoverflow:
That's it, the proxy servlet is ready. We send the answer, having set the necessary coding and mime.
Deploy our proxy servlet on the same address as adminpanel.indexisto.com admin panel , load the proxy webmaster site into our iframe page and all cross-domain problems disappear.
Our proxy works at
- that's how Habr will boot from our domain. We give this address in the iframe and try to get access to the DOM tree of the habr through JS in the admin panel - everything works. CSRF naturally does not pass as the page is loaded from our proxy which does not have cookies.
Let's load into our iframe site with the address “localhost” - opa, here is the start page of our nginx. Let's try some internal (not visible outside) resource on the same network as our proxy server. For example secured_crm.indexisto.com - everything is in place.
Of course, we are trying to ban these things in our proxy, in case someone tries to proxify localhost, we exit without returning anything:
but we obviously will not list all the resources of the network here. So you need to make a proxy in a completely isolated environment so that the machine can not see anything except the Internet, itself and our proxy. Select the machine, set up and start our servlet there.
Let's load into our iframe our page on which we will write:
Alert pops up. Sadly This can be bypassed with the iframe sandbox allow-scripts attribute, but what about old browsers that do not really understand this attribute? You can only steal your cookies, but you can’t leave it alone anyway.
We carry out the servlet not only on a separate machine, but also make it a separate subdomain highlighter.indexisto.com .
Sailed, we broke our own solution bypassing cross-domain restrictions. Now we can’t reach the iframe content again.
Continuing to reschedule the decision from google, I opened our proxy page in a separate window
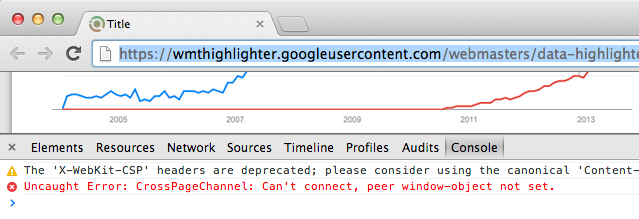
and drew attention to a strange error in the console.
It became clear that everything is organized more complicated than simply loading the page in the iframe from your domain. Pages communicate with each other. Respectively we move towards window.postMessage
To force our script to embed a webmaster into its page that would ensure the selection of page elements with a mouse, and then send xPath of these elements to our parent document via postMessage was not humane. However, no one bothers our proxy to inject any scripts on the page loaded into iFrame.
We save all the necessary scripts to a file, and paste them before the closing body :
For the test, we insert an alert - everything works.
Okay, let's go to JS itself, which we pasted on the webmaster's page.
We need to highlight the dom elements over which a person drives a mouse. It is better to do this with the help of shadow, since then the element will not shift, and the whole page will jump. We hang onmouseover on the body and look at the target of the event. In the same handler, I calculate the element's xpath. It is better to calculate the xPath element per click, but I did not notice any brakes in this implementation.
I don’t include here an implementation of getting the xPath of a DOM element. There are many snippets of how to do this. These snippets can be modified to suit your needs, for example, you need only tags in xpath. Or you need an id if they are and classes if there is no id - everyone has their own requirements.
Here is an example of a hacked Habr's main page with an embedded script:
http://highlighter.indexisto.com/?md5=6ec7rdHxUfRkrFy55jrJQA==&url=http%3A%2F%2Fhabrahabr.ru&expires=1390468360
A person’s click on the page in the iframe is immediately “extinguished” (no link will be followed in the iframe). And also we send the string obtained by xPath to the parent window (we saved it at the stage of driving the mouse over the element)
That's all, now in our admin webmaster can be much easier to quickly get xpath paths to the elements on your pages.

Okay, everything worked for us, but there is a moment with the fact that our proxy looks into the world completely unprotected. Anyone can log anything.
We put in front of the nginx proxy, it listens to port 80, we remove the proxy itself to another port. All other ports except 80 are closed from the outside world.
Now we will do so that the proxy only works through the admin panel. At the moment when the webmaster enters the URL of your site, we quickly run to the server where we generate the md5 hash from the current TimeStamp + 1 hour, the URL itself and the super secret when:
Also note that in the code we get the md5 string not as the usual hex, but in base64 encoding, plus in the resulting md5 we make strange replacements of the slash and plus characters for underscores and dashes.
The fact is that ngnix uses base64 Filename Safe Alphabet tools.ietf.org/html/rfc3548#page-6
And Java gives the canonical base64.
Having received a response from the server with security md5 in our admin panel, we are trying to load this url into the iframe:
highlighter.indexisto.com/?md5=Dr4u2Yeb3NrBQLgyDAFrHg==&url=http%3A%2F%2Fhabrahabr.ru&expires=1389791582
Now we configure the nginx HttpSecureLinkModule module. This module checks the md5 of all the parameters that came to it (the same secret key as in the admin servlet is registered in the module), checks whether the link has been pro-parked, and only in this case sends a request to our proxy servlet.
Now no one can use our proxy from the admin panel, nor can she insert a picture that has been proxied to our server somewhere — she will die in an hour anyway.
Google in its marker tool naturally went much further. In order to clearly identify an element on a page, you need to mark the same element (for example, the article title) on several pages of the same type so that you can more accurately build xpath and discard different “post-2334” type ids that obviously work only on one page . In our admin, while xpath must be corrected by hand to get an acceptable result
Now Google, having met a similar page on your site, already knows what content is published on it, and how beautiful it is to parse it into substance (article, product, video ..)
')
We needed similar functionality. The task seemed simple and client-side exclusively. However, in practice, the solution lies at the interface between the client side and the serverside (“pure” JS programmers may not know anything about various proxy servers and go to the projectile for a very long time). However, I did not find an article on the Internet that would describe all the technology from start to finish. I would also like to say thanks to the BeLove user and our security personnel for their help.
In our case, we wanted the webmaster to conveniently (with the mouse) get the xPath value to specific elements on his page.
Iframe "Same Origin"
And so in our admin a person should enter the URL of the page of his site, we will display it in iFrame, a person will click the mouse where necessary, we will get the desired xPath. Everything would be OK, but we do not have access to the content of the page from another domain loaded into the iframe in our admin panel (our domain), due to the security policy of the browser.
CORS - Cross origin resource sharing
Some people advised me to use CORS. Trendy technology that solves many problems with access to content from another domain in the browser and allows you to bypass the same origin policy restrictions.
A site that wants to give access to its content on the pages of another domain simply writes the http header:
Access-Control-Allow-Origin: http://example.com And in the header of the http request coming from the page of another domain from the browser should be the field of origin:
Origin: www.mysupersite.com it is clear that the origin field for the request is added by the browser itself. Let's add an article on Habré and see that modern browsers add Origin even to the request for the same domain:
but:
- the browser does not put origin in the request header for the page loaded in the iframe (can anyone explain why?)
- we do not want to ask webmasters to register the header Access-Control-Allow-Origin
Iframe sandbox
Another fashionable technology. Sandbox is an attribute of the Iframe tag. As one of the values of this attribute, you can set the value of allow-same-origin . Before I started digging this topic, I did not know what exactly this attribute does, but it sounded very tempting. However, the sandbox attribute simply restricts what the page loaded in the iframe can do and has nothing to do with the problem of access from the parent document to the contents of the frame.
Specifically, the value of allow-same-origin (or rather its absence) just says that the iframe should always be regarded as loaded from someone else’s domain (for example, you cannot send an AJAX request to the domain of the parent document from such a frame)
Let's see how Google does
Time to take care of how big brother has done
Pay attention to the src attribute of the iframe element:
src="https://wmthighlighter.googleusercontent.com/webmasters/data-highlighter/RenderFrame/007....." - our page is loaded into the admin area from the Google domain. Further, it is even more severe: even scripts and images in the source document are run through a proxy. All src, href ... are replaced in html with proxied ones. Like this:All resources that your page uses are also stored on Google proxy servers. For example, our logo on the proxy server Google .
{kind=link}
CGIProxy?
It immediately seemed that in order to do the same you need to raise a full-fledged proxy like CGIProxy . This proxy server does about the same thing as Google’s wmthighlighter.googleusercontent.com
Visit the script's URL to start a browsing session. Once you've gotten through the proxy page. You can go through your bookmarks through the proxy as they did the first time.
Your proxy!
However, if you narrow down the task, it is much easier to write a simple proxy yourself. The fact is that doing so does Google, driving all the content through a proxy page is not necessary. We just need to give html of any page from our domain, and resources can be uploaded from the original domain. Https we have so far discarded.
The task of super performance or convenience settings is not worth it, and it can be done quickly and on anything, from node.js to php. We wrote a servlet in Java.
Downloading the page
What should the proxy servlet do? Through the get parameter, we get the url of the page you want to load, then download the page.
Be sure to determine the page encoding (via http response or charset in html) - our proxy should respond in the same encoding as the page we downloaded. We will also define the Content-Type just in case, although it is clear that we get the page in text / html and give it the same way.
final String url = request.getParameter("url"); final HttpGet requestApache = new HttpGet(url); final HttpClient httpClient = new DefaultHttpClient(); final HttpResponse responseApache = httpClient.execute(requestApache); final HttpEntity entity = responseApache.getEntity(); final String encoding = EntityUtils.getContentCharSet( entity ); final String mime = EntityUtils.getContentMimeType(entity); String responseText = IOUtils.toString(entity.getContent(), encoding); * For those who like to evaluate someone else's code: in our team we all have the same formatting options for the eclicpse code, and while saving the file, Eclipse itself adds to all final variables if they do not change anywhere else. Which by the way is quite convenient in the end.
Change relative URLs to absolute in the page code
It is necessary to go through all the attributes with src and href in the page (paths of style files, images), and replace the relative URLs with absolute ones. Otherwise, the page will try to download images from some folders on our proxy, which we naturally do not have. In any language there are ready-made classes or you can find code snippets for this case on stackoverflow:
final URI uri = new URI(url); final String host = uri.getHost(); responseText = replaceRelativeLinks(host,responseText); We send html
That's it, the proxy servlet is ready. We send the answer, having set the necessary coding and mime.
protected void sendResponse(HttpServletResponse response, String responseText, String encoding, String mime) throws ServletException, IOException { response.setContentType(mime); response.setCharacterEncoding(encoding); response.setStatus(HttpServletResponse.SC_OK); response.getWriter().print(responseText ); response.flushBuffer(); } Deploy and test
Deploy our proxy servlet on the same address as adminpanel.indexisto.com admin panel , load the proxy webmaster site into our iframe page and all cross-domain problems disappear.
Our proxy works at
http://adminpanel.indexisto.com/highlighter?url=http://habrahabr.ru - that's how Habr will boot from our domain. We give this address in the iframe and try to get access to the DOM tree of the habr through JS in the admin panel - everything works. CSRF naturally does not pass as the page is loaded from our proxy which does not have cookies.
SSRF Problem
Let's load into our iframe site with the address “localhost” - opa, here is the start page of our nginx. Let's try some internal (not visible outside) resource on the same network as our proxy server. For example secured_crm.indexisto.com - everything is in place.
Of course, we are trying to ban these things in our proxy, in case someone tries to proxify localhost, we exit without returning anything:
if (url.contains("localhost")||url.contains("127")||url.contains("highlighter")||url.contains("file")) { LOG.debug("Trying to get local resource. Url = " + url); return; } but we obviously will not list all the resources of the network here. So you need to make a proxy in a completely isolated environment so that the machine can not see anything except the Internet, itself and our proxy. Select the machine, set up and start our servlet there.
XSS Problem
Let's load into our iframe our page on which we will write:
<script>alert('xss')</script> Alert pops up. Sadly This can be bypassed with the iframe sandbox allow-scripts attribute, but what about old browsers that do not really understand this attribute? You can only steal your cookies, but you can’t leave it alone anyway.
We carry out the servlet not only on a separate machine, but also make it a separate subdomain highlighter.indexisto.com .
Sailed, we broke our own solution bypassing cross-domain restrictions. Now we can’t reach the iframe content again.
Interesting idea.
Continuing to reschedule the decision from google, I opened our proxy page in a separate window
and drew attention to a strange error in the console.
CrossPageChannel: Can't connect, peer window-object not set. It became clear that everything is organized more complicated than simply loading the page in the iframe from your domain. Pages communicate with each other. Respectively we move towards window.postMessage
Post Message
To force our script to embed a webmaster into its page that would ensure the selection of page elements with a mouse, and then send xPath of these elements to our parent document via postMessage was not humane. However, no one bothers our proxy to inject any scripts on the page loaded into iFrame.
We save all the necessary scripts to a file, and paste them before the closing body :
final int positionToInsert = responseText.indexOf("</body>"); final InputStream inputStream = getServletContext().getResourceAsStream("/WEB-INF/inject.js"); final StringWriter writer = new StringWriter(); IOUtils.copy(inputStream, writer); final String jsToInsert = writer.toString(); responseText = responseText.substring(0, positionToInsert) + jsToInsert + responseText.substring(positionToInsert, responseText.length()); For the test, we insert an alert - everything works.
JS part - we highlight the house element under the mouse and get xpath
Okay, let's go to JS itself, which we pasted on the webmaster's page.
We need to highlight the dom elements over which a person drives a mouse. It is better to do this with the help of shadow, since then the element will not shift, and the whole page will jump. We hang onmouseover on the body and look at the target of the event. In the same handler, I calculate the element's xpath. It is better to calculate the xPath element per click, but I did not notice any brakes in this implementation.
elmFrame.contentWindow.document.body.onmouseover= function(ev){ ev.target.style.boxShadow = "0px 0px 5px red"; curXpath = getXPathFromElement(ev.target); } I don’t include here an implementation of getting the xPath of a DOM element. There are many snippets of how to do this. These snippets can be modified to suit your needs, for example, you need only tags in xpath. Or you need an id if they are and classes if there is no id - everyone has their own requirements.
Here is an example of a hacked Habr's main page with an embedded script:
http://highlighter.indexisto.com/?md5=6ec7rdHxUfRkrFy55jrJQA==&url=http%3A%2F%2Fhabrahabr.ru&expires=1390468360
JS part - we process click
A person’s click on the page in the iframe is immediately “extinguished” (no link will be followed in the iframe). And also we send the string obtained by xPath to the parent window (we saved it at the stage of driving the mouse over the element)
document.body.onclick = function(ev){ window.parent.postMessage( curXpath, "*"); ev.preventDefault(); ev.stopPropagation(); } Profit!
That's all, now in our admin webmaster can be much easier to quickly get xpath paths to the elements on your pages.
Add more security issues
Okay, everything worked for us, but there is a moment with the fact that our proxy looks into the world completely unprotected. Anyone can log anything.
We put in front of the nginx proxy, it listens to port 80, we remove the proxy itself to another port. All other ports except 80 are closed from the outside world.
Now we will do so that the proxy only works through the admin panel. At the moment when the webmaster enters the URL of your site, we quickly run to the server where we generate the md5 hash from the current TimeStamp + 1 hour, the URL itself and the super secret when:
final String md5Me = timeStampExpires + urlEncoded + "SUPERSECRET"; final MessageDigest md = MessageDigest.getInstance("MD5"); md.reset(); md.update(md5Me.getBytes("UTF-8")); String code = Base64.encodeBase64String(md.digest()); code = code.replaceAll("/", "_"); code = code.replaceAll("\\+","-"); Also note that in the code we get the md5 string not as the usual hex, but in base64 encoding, plus in the resulting md5 we make strange replacements of the slash and plus characters for underscores and dashes.
The fact is that ngnix uses base64 Filename Safe Alphabet tools.ietf.org/html/rfc3548#page-6
And Java gives the canonical base64.
Having received a response from the server with security md5 in our admin panel, we are trying to load this url into the iframe:
highlighter.indexisto.com/?md5=Dr4u2Yeb3NrBQLgyDAFrHg==&url=http%3A%2F%2Fhabrahabr.ru&expires=1389791582
Now we configure the nginx HttpSecureLinkModule module. This module checks the md5 of all the parameters that came to it (the same secret key as in the admin servlet is registered in the module), checks whether the link has been pro-parked, and only in this case sends a request to our proxy servlet.
Now no one can use our proxy from the admin panel, nor can she insert a picture that has been proxied to our server somewhere — she will die in an hour anyway.
That's all folks!
Google in its marker tool naturally went much further. In order to clearly identify an element on a page, you need to mark the same element (for example, the article title) on several pages of the same type so that you can more accurately build xpath and discard different “post-2334” type ids that obviously work only on one page . In our admin, while xpath must be corrected by hand to get an acceptable result
Source: https://habr.com/ru/post/210050/
All Articles