Test boost :: lockfree on the speed and delay of message transmission
Not so long ago in boost-1.53 a whole new section appeared - lockfree implementing non-blocking queues and a stack.
For the past few years I have been working with so-called non-blocking algorithms (lock-free data structures), we wrote them ourselves, tested them ourselves, used themand were secretly proud of them . Naturally, we immediately had a question, whether to switch from self-made libraries to boost, and if to switch, when?
That's when I came up with the idea for the first time to apply to boost :: lockfree some of the techniques we used to try our own code. Fortunately, we will not have to test the algorithm itself, and we can focus on measuring performance.
I will try to make the article interesting for everyone. Those who have not yet encountered such problems will be useful to look at the fact that such algorithms are capable, and most importantly, where and how they should or should not be used. For those who have experience in developing non-blocking queues, it may be interesting to compare quantitative measurement data. At least I have not yet seen such publications myself.
The concept of multithreading has become firmly established in modern programming, but working with threads is impossible without synchronization tools, this is how mutex, semaphore, condition variable and their subsequent descendants appeared. However, the first standard functions were rather heavy and slow, moreover, they were implemented inside the kernel, that is, they required context switching for each call. The switching time is weakly dependent on the CPU, so the faster the processors became, the more relative time was required to synchronize the threads. Then the idea emerged that, with minimal hardware support, it would be possible to create data structures invariant when working simultaneously with several threads. For those who would like to know more about this, I recommend this series of publications .
The main algorithms have been developed and put on the back burner, their time has not come yet. They got a second life when the concept of message processing time (latency) became almost more important than the usual CPU speed. What is it all about?
You can read more in the interview with Herb Sutter , he is in a slightly different context, but he is very temperamental in discussing this problem. Intuitively, it seems that the concepts of speed and latency are identical - the larger the first, the smaller the second. On closer examination, it turns out, however, that they are independent and even anti-correlated.
What does this have to do with non-blocking structures? The most direct, the fact is that for latency any attempt to slow down or stop the flow is destructive. It is easy to put the stream to sleep, but it is impossible to wake it up. It can be awakened with atender kiss only by the core of the operating system, and it does this strictly on schedule and with lunch breaks . Try to explain to someone that your program, which pledged on those. the task to respond within 200 nanoseconds , currently falls asleep for 10 milliseconds (typical time for * nix systems) and it is better not to disturb her. Lock-free data structures that do not require stopping the stream for synchronization with other threads come to the rescue.
Here we will talk about one such structure.
I will work only with one of the structures - boost :: lockfree :: queue that implements a unidirectional queue with an arbitrary number of writing and reading threads. This structure exists in two versions - allocating memory as needed and having an infinite capacity, and a variant with a fixed buffer. Strictly speaking, both of them are not non-blocking, the first because the system memory allocation is not lock-free, the second because sooner or later the buffer will overflow and the writing streams will have to wait indefinitely until the recording space appears. Let's start with the first option, and closer to the end I will compare with the results for a fixed buffer.
I will add that I have a 4-core Linux Mint-15.
Take the code right from here and try to run it, here’s what happens:
That is, if you approach the case on a simple, about 400 ns per message, it is quite satisfactory. This implementation transmits an int and starts 4 reading and writing streams.
Let's modify the code a bit, I want to run an arbitrary number of threads, and I also like to see statistics. What will be the distribution if you run the test 100 times in a row?
')
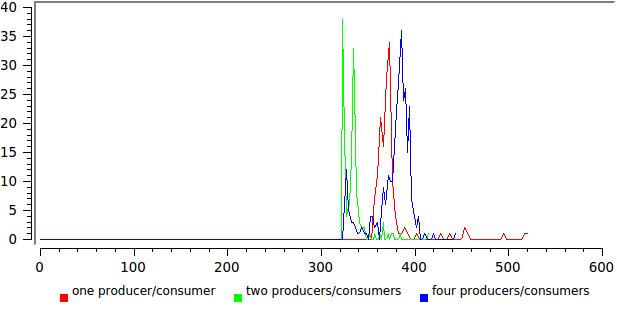
Here you are, it looks quite reasonable. On the X axis, the total execution time in nanoseconds divided by the number of transmitted messages, on the Y axis the number of such events.
But the result for a different number of writers / readers:
Here everything is not so rosy, any broadening of the distribution speaks from the fact that something is not optimally working. In this case, it is approximately clear that the reading threads in this test never give up control, and when their number approaches the number of cores, the system simply has to suspend them.
Let's make one more improvement in the test, instead of transmitting a useless int , let the writing thread send the current time to the nearest nanosecond. Then the recipient will be able to calculate the latency for each message. We do, run:
We are now also counting the number of unsuccessful attempts to read a message from the queue and write to the queue (the first one here will of course always be zero, this is the allotment option).
However, what else is this? The delay, which we intuitively assumed the same order - 200 ns, suddenly exceeds 100 milliseconds, half a million times more! It just can't be.
But after all, we now know the delay of each message, so go ahead and see how it looks in real time, here are the results of several identical launches so that you can see how random the process is:
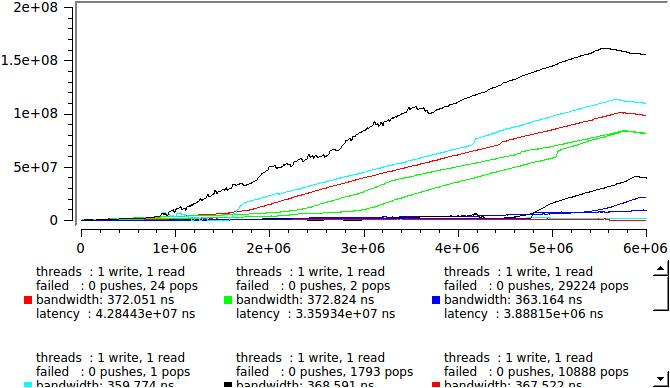
that is, if we write and read one stream at a time, and if we have four then:
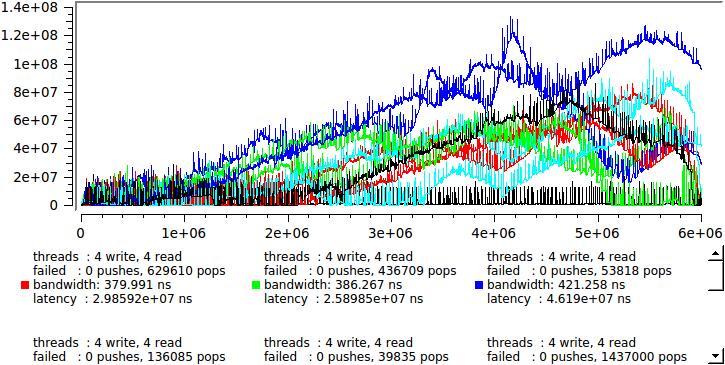
What is going on? At some arbitrary moment, some of the reading threads are sent by the system to rest. The queue begins to grow rapidly, messages sit in it and wait for processing. After some time, the situation changes, the number of writing streams becomes less than the reading and the queue slowly resolves. Such fluctuations occur with a period from milliseconds to seconds and the queue works in batch mode — one million messages were recorded, one million were read. The speed remains very high, but each individual message can spend several milliseconds in the queue.
What do we do? First of all, let's think about it, the test in this form is clearly inadequate. In our country, half of the active threads are occupied only by inserting messages into the queue, this simply cannot happen on a real system, in other words, the test is designed so that traffic generates a deliberately rising power of the machine.
We'll have to limit the input traffic, just insert usleep (0) after each entry into the queue. On my machine, this gives a delay of 50 µs with good accuracy. We'll see:
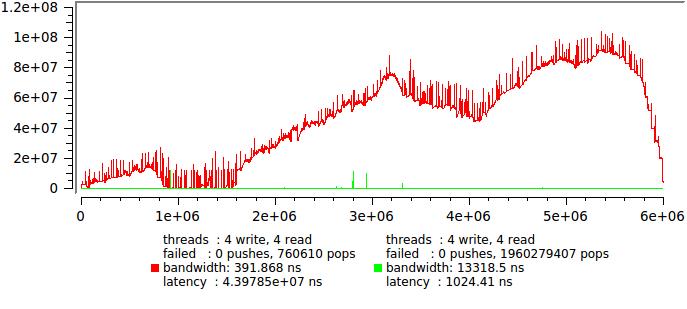
The red line - the original test without delay, green - with a delay.
It is quite another thing, now you can count the statistics.
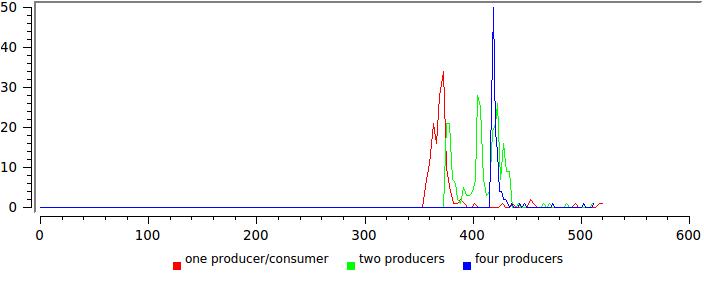
Here is the result for several combinations of the number of writing and reading streams, to maintain an acceptable X scale, 1% of the largest counts dropped:
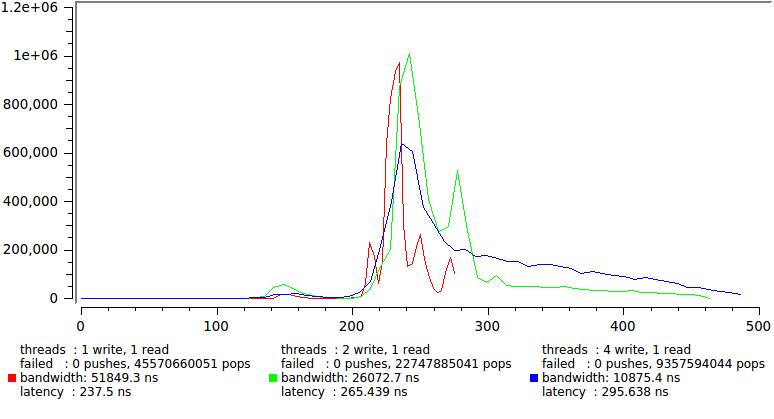
Note that latency remains confidently within 300 ns and only the distribution tail is pulled further and further.
But the results for one and four write threads, respectively.
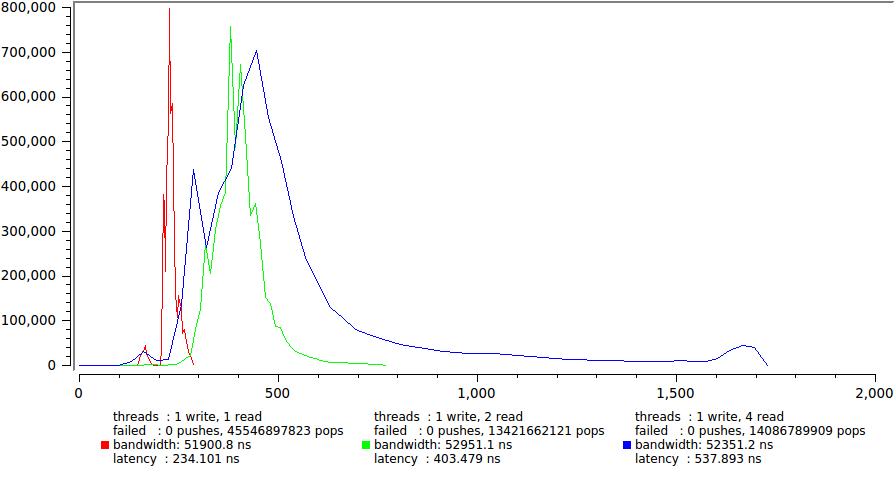
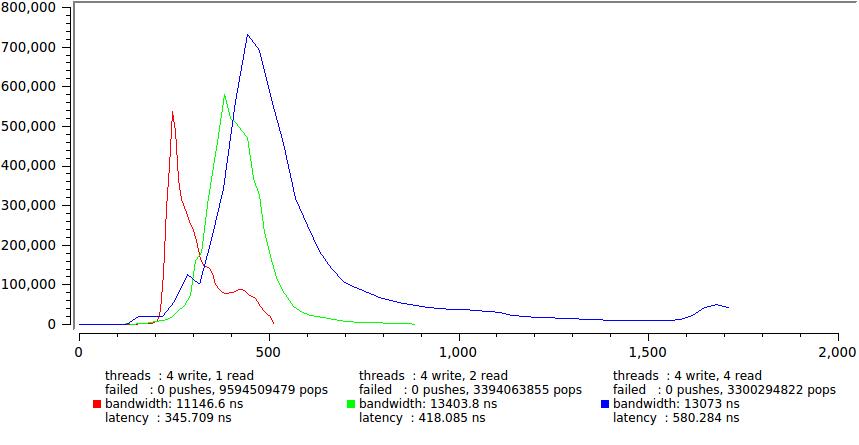
Here, a significant increase in the delay is evident, mainly due to the sharp growth of the tail. Again, we see that four (== CPU) streams that continuously thrash idly by generating their own quantum of time, which causes a large number of uncontrolled slowdowns. Although the average delay surely remains within 600 ns, for some tasks it is already on the verge of permissible, for example, if you have a TK clearly stipulating that 99.9% of messages must be delivered within a certain time (this happened to me).
Note also how much the total execution time has grown, once in 150. This is a demonstration of the statement I made at the very beginning - minimum latency and maximum speed are not achieved at the same time. A sort of peculiar principle of uncertainty.
That's actually all that we could get out of the tests, not so little. We measured the delay with good accuracy, showed that in a number of modes the average latency grows by many orders or, more precisely, the concept of average for it loses its meaning.
Let's finally consider the last question.
fixed capacity is another option of boost :: lockfree :: queue built on a fixed-size internal buffer. On the one hand, this allows avoiding a call to the system allocator, on the other hand, if the buffer is full, the writing thread will also have to wait. For some types of tasks this is completely excluded.
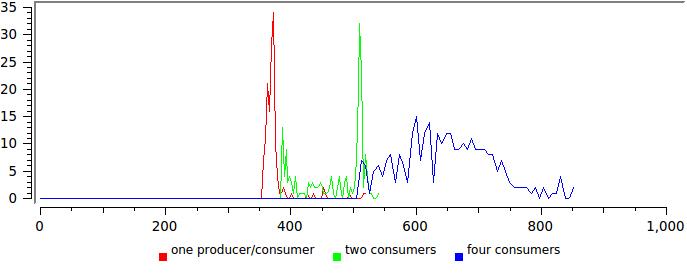
We will work on the same method here. First, by learning from experience, we will look at the dynamics of delays:

The red graph corresponds to the 128 bytes used in the example from the boost, the green to the maximum possible 65534 bytes.
We did not insert an artificial delay, therefore it is natural that the queue works in batch mode, it is filled and released in large chunks. However, the fixed buffer capacity introduces a certain order and it is clearly seen that the average for the delay at least exists. Another unexpected conclusionfor fans of huge buffers is that the buffer size does not affect the overall execution speed. That is, if you are satisfied with latency of 32 μs (which is quite enough for many applications, by the way), you can use fixed_capacity lockfree :: queue with tiny memory usage and get extra speed.
But nevertheless, let's evaluate how this option behaves in a multi-threaded program:
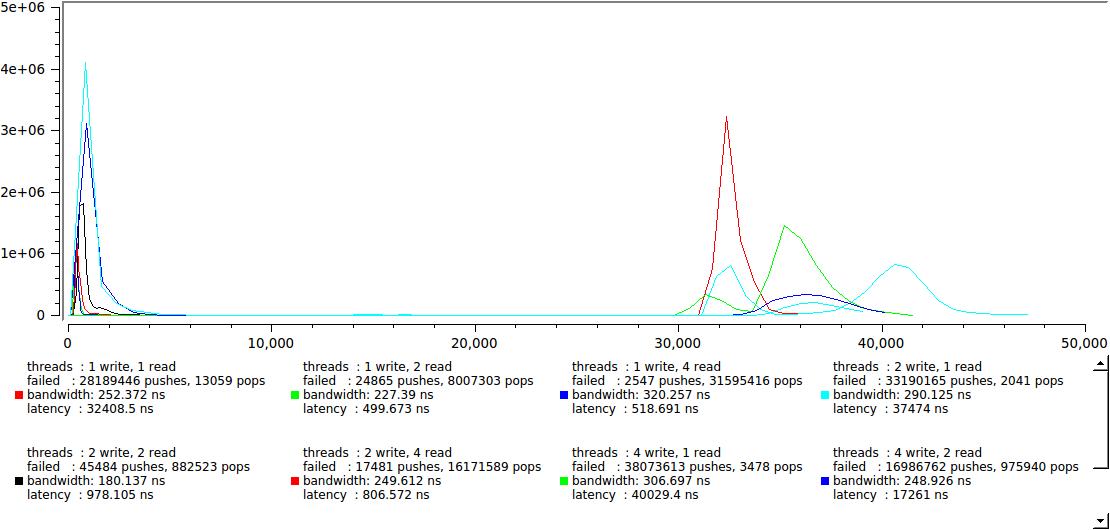
it was a little unexpected to see such a clear division into two groups, where the speed of the readers exceeds the speed of the writers, we get our desired hundreds of nanoseconds, where, on the contrary, it rises abruptly to 30-40 microseconds, it looks like this is a context switch on my machine. This is the result for a 128-byte buffer, and 64K looks very similar, only the right-hand group crawls far, for tens of milliseconds.
Is it good or bad? Depends on the task, on the one hand, we can confidently guarantee that the delay will never exceed 40 μs under any conditions, and this is good; on the other hand, if we need to guarantee some maximum delay less than this value, then we will have a hard time. Any change in the balance of readers / writers, for example, due to a slight change in the processing of messages, can lead to an abrupt change in the delay.
Recall, however, that we are generating messages that are known to be faster than our system can handle (see above, in the section about dynamically queues) and try to insert a plausible delay:
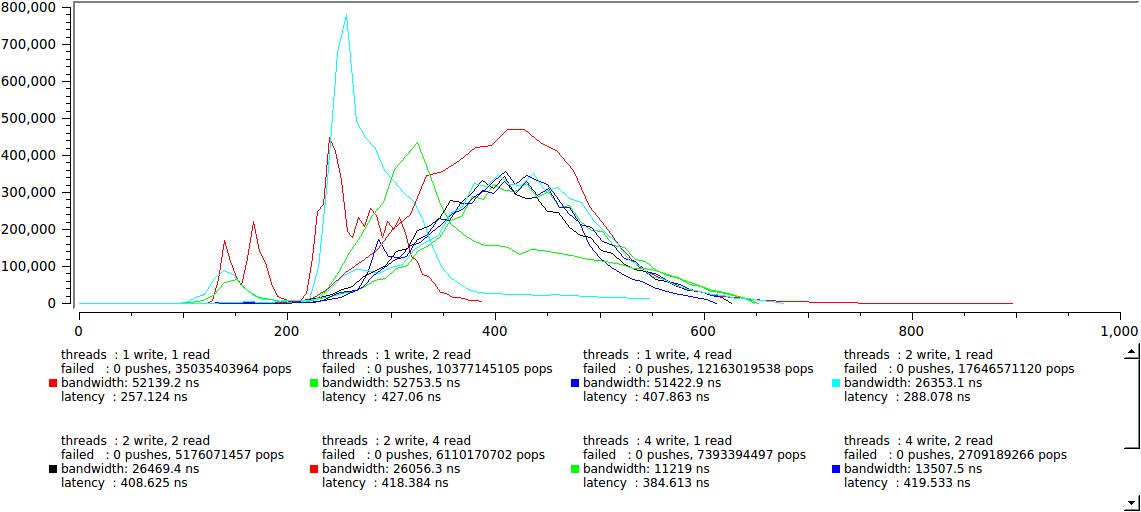
This is already quite good, the two groups did not merge completely, but the right one approached so that the maximum latency does not exceed 600 ns. Take my word for it, the statistics for a large buffer is 64K, it looks exactly the same, not the slightest difference.
I hope that those who have experience will be able to extract something useful from the test results themselves. This is what I think myself:
For the past few years I have been working with so-called non-blocking algorithms (lock-free data structures), we wrote them ourselves, tested them ourselves, used them
That's when I came up with the idea for the first time to apply to boost :: lockfree some of the techniques we used to try our own code. Fortunately, we will not have to test the algorithm itself, and we can focus on measuring performance.
I will try to make the article interesting for everyone. Those who have not yet encountered such problems will be useful to look at the fact that such algorithms are capable, and most importantly, where and how they should or should not be used. For those who have experience in developing non-blocking queues, it may be interesting to compare quantitative measurement data. At least I have not yet seen such publications myself.
Introduction: What are non-blocking data structures and algorithms?
The concept of multithreading has become firmly established in modern programming, but working with threads is impossible without synchronization tools, this is how mutex, semaphore, condition variable and their subsequent descendants appeared. However, the first standard functions were rather heavy and slow, moreover, they were implemented inside the kernel, that is, they required context switching for each call. The switching time is weakly dependent on the CPU, so the faster the processors became, the more relative time was required to synchronize the threads. Then the idea emerged that, with minimal hardware support, it would be possible to create data structures invariant when working simultaneously with several threads. For those who would like to know more about this, I recommend this series of publications .
The main algorithms have been developed and put on the back burner, their time has not come yet. They got a second life when the concept of message processing time (latency) became almost more important than the usual CPU speed. What is it all about?
Here is a simple example:
Suppose I have a server that receives messages, processes and sends a response. Suppose that I received 1 million messages and the server handled them in 2 seconds, that is, 2 μs per transaction and it suits me. This is what is called bandwidth and is not a correct measure when processing messages . Later, I was surprised to learn that every client sent me a message, the client received an answer no earlier than in 1 second, that they are not satisfied with it at all. What's the matter? One possible scenario: the server quickly receives all messages and puts them into a buffer; then processes them in parallel, spending every 1 second, but manages to process everything together in just 2 seconds; and quickly sends back. This is an example of a good speed system as a whole and at the same time unacceptably high latency.
You can read more in the interview with Herb Sutter , he is in a slightly different context, but he is very temperamental in discussing this problem. Intuitively, it seems that the concepts of speed and latency are identical - the larger the first, the smaller the second. On closer examination, it turns out, however, that they are independent and even anti-correlated.
What does this have to do with non-blocking structures? The most direct, the fact is that for latency any attempt to slow down or stop the flow is destructive. It is easy to put the stream to sleep, but it is impossible to wake it up. It can be awakened with a
Here we will talk about one such structure.
The first approach to the platform
I will work only with one of the structures - boost :: lockfree :: queue that implements a unidirectional queue with an arbitrary number of writing and reading threads. This structure exists in two versions - allocating memory as needed and having an infinite capacity, and a variant with a fixed buffer. Strictly speaking, both of them are not non-blocking, the first because the system memory allocation is not lock-free, the second because sooner or later the buffer will overflow and the writing streams will have to wait indefinitely until the recording space appears. Let's start with the first option, and closer to the end I will compare with the results for a fixed buffer.
I will add that I have a 4-core Linux Mint-15.
Take the code right from here and try to run it, here’s what happens:
boost :: lockfree :: queue is lockfree produced 40,000,000 objects. consumed 40,000,000 objects. real 0m15.332s user 1m0.376s sys 0m0.064s
That is, if you approach the case on a simple, about 400 ns per message, it is quite satisfactory. This implementation transmits an int and starts 4 reading and writing streams.
Let's modify the code a bit, I want to run an arbitrary number of threads, and I also like to see statistics. What will be the distribution if you run the test 100 times in a row?
')
Here you are, it looks quite reasonable. On the X axis, the total execution time in nanoseconds divided by the number of transmitted messages, on the Y axis the number of such events.
But the result for a different number of writers / readers:
Here everything is not so rosy, any broadening of the distribution speaks from the fact that something is not optimally working. In this case, it is approximately clear that the reading threads in this test never give up control, and when their number approaches the number of cores, the system simply has to suspend them.
The second approach to the platform
Let's make one more improvement in the test, instead of transmitting a useless int , let the writing thread send the current time to the nearest nanosecond. Then the recipient will be able to calculate the latency for each message. We do, run:
threads: 1 write, 1 read failed: 0 pushes, 3267 pops bandwidth: 177.864 ns latency: 1.03614e + 08 ns
We are now also counting the number of unsuccessful attempts to read a message from the queue and write to the queue (the first one here will of course always be zero, this is the allotment option).
However, what else is this? The delay, which we intuitively assumed the same order - 200 ns, suddenly exceeds 100 milliseconds, half a million times more! It just can't be.
But after all, we now know the delay of each message, so go ahead and see how it looks in real time, here are the results of several identical launches so that you can see how random the process is:
that is, if we write and read one stream at a time, and if we have four then:
What is going on? At some arbitrary moment, some of the reading threads are sent by the system to rest. The queue begins to grow rapidly, messages sit in it and wait for processing. After some time, the situation changes, the number of writing streams becomes less than the reading and the queue slowly resolves. Such fluctuations occur with a period from milliseconds to seconds and the queue works in batch mode — one million messages were recorded, one million were read. The speed remains very high, but each individual message can spend several milliseconds in the queue.
What do we do? First of all, let's think about it, the test in this form is clearly inadequate. In our country, half of the active threads are occupied only by inserting messages into the queue, this simply cannot happen on a real system, in other words, the test is designed so that traffic generates a deliberately rising power of the machine.
We'll have to limit the input traffic, just insert usleep (0) after each entry into the queue. On my machine, this gives a delay of 50 µs with good accuracy. We'll see:
The red line - the original test without delay, green - with a delay.
It is quite another thing, now you can count the statistics.
Here is the result for several combinations of the number of writing and reading streams, to maintain an acceptable X scale, 1% of the largest counts dropped:
Note that latency remains confidently within 300 ns and only the distribution tail is pulled further and further.
But the results for one and four write threads, respectively.
Here, a significant increase in the delay is evident, mainly due to the sharp growth of the tail. Again, we see that four (== CPU) streams that continuously thrash idly by generating their own quantum of time, which causes a large number of uncontrolled slowdowns. Although the average delay surely remains within 600 ns, for some tasks it is already on the verge of permissible, for example, if you have a TK clearly stipulating that 99.9% of messages must be delivered within a certain time (this happened to me).
Note also how much the total execution time has grown, once in 150. This is a demonstration of the statement I made at the very beginning - minimum latency and maximum speed are not achieved at the same time. A sort of peculiar principle of uncertainty.
That's actually all that we could get out of the tests, not so little. We measured the delay with good accuracy, showed that in a number of modes the average latency grows by many orders or, more precisely, the concept of average for it loses its meaning.
Let's finally consider the last question.
What about fixed capacity queue?
fixed capacity is another option of boost :: lockfree :: queue built on a fixed-size internal buffer. On the one hand, this allows avoiding a call to the system allocator, on the other hand, if the buffer is full, the writing thread will also have to wait. For some types of tasks this is completely excluded.
We will work on the same method here. First, by learning from experience, we will look at the dynamics of delays:
The red graph corresponds to the 128 bytes used in the example from the boost, the green to the maximum possible 65534 bytes.
By the way
The documentation says that the maximum size is 65535 bytes - do not believe, get a core dump
We did not insert an artificial delay, therefore it is natural that the queue works in batch mode, it is filled and released in large chunks. However, the fixed buffer capacity introduces a certain order and it is clearly seen that the average for the delay at least exists. Another unexpected conclusion
But nevertheless, let's evaluate how this option behaves in a multi-threaded program:
it was a little unexpected to see such a clear division into two groups, where the speed of the readers exceeds the speed of the writers, we get our desired hundreds of nanoseconds, where, on the contrary, it rises abruptly to 30-40 microseconds, it looks like this is a context switch on my machine. This is the result for a 128-byte buffer, and 64K looks very similar, only the right-hand group crawls far, for tens of milliseconds.
Is it good or bad? Depends on the task, on the one hand, we can confidently guarantee that the delay will never exceed 40 μs under any conditions, and this is good; on the other hand, if we need to guarantee some maximum delay less than this value, then we will have a hard time. Any change in the balance of readers / writers, for example, due to a slight change in the processing of messages, can lead to an abrupt change in the delay.
Recall, however, that we are generating messages that are known to be faster than our system can handle (see above, in the section about dynamically queues) and try to insert a plausible delay:
This is already quite good, the two groups did not merge completely, but the right one approached so that the maximum latency does not exceed 600 ns. Take my word for it, the statistics for a large buffer is 64K, it looks exactly the same, not the slightest difference.
It's time to go to the conclusion
I hope that those who have experience will be able to extract something useful from the test results themselves. This is what I think myself:
- If you are only interested in speed, all options are roughly equivalent and give an average time of the order of hundreds of nanoseconds per message. In this fixed_capacity queue is more lightweight, since it takes a fixed amount of memory. However, there are applications, for example, where it is critically important to “release” the reading thread as quickly as possible, in which case the allotted queue is better suited, on the other hand, it can consume memory indefinitely.
- If minimization of latency is required, the processing time of each message separately, the situation is complicated. For applications where it is necessary not to block the writing stream (loggers), it is certainly worth choosing the allotment option. For the case of limited memory, fixed_capacity is definitely suitable, the buffer sizes will have to be selected based on the signal statistics.
- In any case, the algorithm is unstable relative to the intensity of the data stream. When a certain critical threshold is exceeded, the delay abruptly increases by several orders of magnitude and then actually (but not formally) becomes blocking. As a rule, fine tuning is required to make the system work without falling into blocking mode.
- Full isolation of the input and output streams is possible only in the allocating version; this is achieved, however, due to uncontrolled memory consumption and an uncontrollably large delay.
- Fixed_capacity allows you to achieve fast data transfer while simultaneously limiting the maximum latency to some reasonable limit. The fixed_capacity queue itself is essentially a very lightweight structure. The main disadvantage is that writing streams are blocked if the readers do not cope or hang for any reason. Large buffer sizes, in my opinion, are rarely needed, they allow to achieve transient dynamics, something approaching the allotting queue.
- A very unpleasant surprise for me was the great negative impact of continuous idle reading threads on the dynamics. Even in the case when the total number of threads <= CPU, the addition of another stream that consumes 100% does not improve, but worsens the dynamics. It seems that the strategy of “large servers”, when a separate core is assigned to each important thread, does not always work.
- In this regard, one unresolved and still unsolved problem is how to efficiently use a thread waiting for an event. If you put him to sleep - the
karma oflatency is fatally spoiled; if you use it for other tasks - the problem arises of quickly switching from task to task. I think a good approximation to the ideal would be to enable the reading stream to be added to boost :: io_service, so as to effectively serve at least rare events. Would love to hear if anyone has any ideas.
For those who need to - code
#include <boost/thread/thread.hpp> #include <boost/lockfree/queue.hpp> #include <time.h> #include <atomic> #include <iostream> std::atomic<int> producer_count(0); std::atomic<int> consumer_count(0); std::atomic<unsigned long> push_fail_count(0); std::atomic<unsigned long> pop_fail_count(0); #if 1 boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<true>> queue(65534); #else boost::lockfree::queue<timespec, boost::lockfree::fixed_sized<false>> queue(128); #endif unsigned stat_size=0, delay=0; std::atomic<unsigned long>* stat=0; std::atomic<int> idx(0); void producer(unsigned iterations) { timespec t; for (int i=0; i != iterations; ++i) { ++producer_count; clock_gettime(CLOCK_MONOTONIC, &t); while (!queue.push(t)) ++push_fail_count; if(delay) usleep(0); } } boost::atomic<bool> done (false); void consumer(unsigned iterations) { timespec t, v; while (!done) { while (queue.pop(t)) { ++consumer_count; clock_gettime(CLOCK_MONOTONIC, &v); unsigned i=idx++; v.tv_sec-=t.tv_sec; v.tv_nsec-=t.tv_nsec; stat[i]=v.tv_sec*1000000000+v.tv_nsec; } ++pop_fail_count; } while (queue.pop(t)) { ++consumer_count; clock_gettime(CLOCK_MONOTONIC, &v); unsigned i=idx++; v.tv_sec-=t.tv_sec; v.tv_nsec-=t.tv_nsec; stat[i]=v.tv_sec*1000000000+v.tv_nsec; } } int main(int argc, char* argv[]) { boost::thread_group producer_threads, consumer_threads; int indexed=0, quiet=0; int producer_thread=1, consumer_thread=1; int opt; while((opt=getopt(argc,argv,"idqr:w:")) !=-1) switch(opt) { case 'r': consumer_thread=atol(optarg); break; case 'w': producer_thread=atol(optarg); break; case 'd': delay=1; break; case 'i': indexed=1; break; case 'q': quiet=1; break; default : return 1; } int iterations=6000000/producer_thread/consumer_thread; unsigned stat_size=iterations*producer_thread*consumer_thread; stat=new std::atomic<unsigned long>[stat_size]; timespec st, fn; clock_gettime(CLOCK_MONOTONIC, &st); for (int i=0; i != producer_thread; ++i) producer_threads.create_thread([=](){ producer(stat_size/producer_thread); }); for (int i=0; i != consumer_thread; ++i) consumer_threads.create_thread([=]() { consumer(stat_size/consumer_thread); }); producer_threads.join_all(); done=true; consumer_threads.join_all(); clock_gettime(CLOCK_MONOTONIC, &fn); std::cerr << "threads : " << producer_thread <<" write, " << consumer_thread << " read" << std::endl; std::cerr << "failed : " << push_fail_count << " pushes, " << pop_fail_count << " pops" << std::endl; fn.tv_sec-=st.tv_sec; fn.tv_nsec-=st.tv_nsec; std::cerr << "bandwidth: " << (fn.tv_sec*1e9+fn.tv_nsec)/stat_size << " ns"<< std::endl; double ct=0; for(auto i=0; i < stat_size; ++i) ct+=stat[i]; std::cerr << "latency : "<< ct/stat_size << " ns"<< std::endl; if(!quiet) { if(indexed) for(auto i=0; i < stat_size; ++i) std::cout<<i<<" "<<stat[i]<<std::endl; else for(auto i=0; i < stat_size; ++i) std::cout<<stat[i]<<std::endl; } return 0; } Source: https://habr.com/ru/post/209824/
All Articles