Why are there so many Pythons?
Python is amazing.
Surprisingly, this is a rather ambiguous statement. What do I mean by “Python”? Maybe an abstract Python interface? Or CPython, a common implementation of Python (not to be confused with a similar Cython name)? Or do I mean something completely different? Maybe I indirectly refer to Jython, or IronPython, or PyPy. Or maybe I digress so much that I’m talking about RPython or RubyPython (which are very different).
Despite the similarity in the names of the above technologies, some of them have completely different tasks (or, at least, work in completely different ways)
')
When working with Python, I encountered a bunch of such technologies. * Ython tools. But only recently I took the time to figure out what they are, how they work and why they (each in its own way) are necessary.
In this post, I'll start from scratch and go through the different implementations of Python, and finish with a detailed introduction to PyPy, which, in my opinion, is the future of the language.
It all starts with an understanding of what “Python” really is.
If you have a good understanding of machine code, virtual machines, and so on, you can skip this section.
This is a common source of misunderstanding among newcomers Python.
The first thing you need to understand: “Python” is an interface. There is a specification that describes what Python should do and how it should behave (which is true for any interface). And there are several implementations (which is also true for any interface).
Second: “interpretable” and “compiled” are implementation properties, but not interface.
So the question itself is not entirely correct.
In the case of the most common implementation (CPython: written in C, often simply called “Python”, and, of course, the one that you use if you have no idea what I'm talking about) the answer: interpreted, with some compilation. CPython compiles * source code on Python into bytecode, and then interprets this bytecode by running it in the process.
* Note: this is not exactly “compilation” in the traditional sense. Usually, we think that “compilation” is a conversion from a high-level language to machine code. However, in some way it is “compilation”.
Let's explore this answer better, as it will help us understand some of the concepts that await us in this article.
It is very important to understand the difference between bytecode and machine (or native) code. Perhaps the easiest way to understand it is by example:
- C is compiled into machine code, which is subsequently run directly by the processor. Each instruction causes the processor to perform different actions.
- Java is compiled into bytecode, which subsequently runs on a Java Virtual Machine (JVM), an abstract computer that runs programs. Each instruction is processed by a JVM that interacts with the computer.
Strongly simplifying: machine code is much faster, but bytecode is better portable and protected.
The machine code may vary depending on the machine, while the bytecode is the same on all machines. We can say that the machine code is optimized for your configuration.
Returning to CPython, the chain of operations looks like this:
1. CPython compiles your Python source code into bytecode.
2. This bytecode runs on the CPython virtual machine.
As I said above, Python has several implementations. Again, as mentioned above, CPython is the most popular. This version of Python is written in C and is considered the default implementation.
But what about alternatives? One of the most prominent is Jython , a Java Python implementation that uses the JVM. While CPython generates bytecode to run on a CPython VM, Jython generates Java bytecode to run on a JVM (this is the same that is generated when compiling a Java program).

“Why might you need to use an alternative implementation?”, You ask. Well, for starters, different implementations get along well with different sets of technologies .
CPython makes it easier to write C extensions for Python code because at the end it is started by the C interpreter. Jython, in turn, makes it easy to work with other Java programs: you can import any Java classes without any extra effort by invoking and using your Java classes from Jython programs. (Note: if you haven’t seriously thought about it yet, it’s pretty crazy. We have lived up to the time when you can mix different languages and compile them into one entity. As Rostin noted, programs mixing code in Fortran with C appeared a long time ago, so it's not entirely new. But it's still cool.)
As an example, here is the correct jython code:
IronPython is another popular Python implementation, written entirely in C # and intended for .NET. In particular, it runs on a .NET virtual machine, if you can call it that, on Microsoft's Common Language Runtime (CLR) , comparable to the JVM.
Jython can be said to be: Java :: IronPython: C #. They run on the appropriate virtual machines, it is possible to import C # classes into IronPython code and Java classes into Jython code, and so on.
Quite really survive without touching anything except CPython. But, moving to other implementations, you get an advantage, mainly because of the stack of technologies used. Do you use many languages based on JVM? Jython might suit you. All on .NET? Perhaps you should try IronPython (and, perhaps, you already did).

By the way, although this will not be a reason for switching to another implementation, it is worth mentioning that these implementations are actually different in behavior. This concerns not only the methods of interpreting Python code. However, these differences are usually not-significant, they disappear and appear over time due to active development. For example, IronPython uses Unicode strings by default ; however, CPython uses ASCII in versions 2.x (yielding a UnicodeEncodeError error for non-ASCII characters), and supports default Unicode characters in versions 3.x.
So, we have a Python implementation written in C, another one in Java, and a third in C #. The next logical step: the implementation of Python, written in ... Python. (A prepared reader will notice that this statement is a bit deceptive).
That is why it can be confusing. To begin with, let's discuss on-the-fly compilation (just-in-time or JIT).
Let me remind you that native native code is much faster than bytecode. Well, what if it were possible to compile part of the bytecode and run it as native code? I would have to “pay” some price (in other words: time) for compiling the bytecode, but if the result is faster, then this is great! This is what motivates JIT compilation, a hybrid technique that combines the advantages of interpreters and compilers. In a nutshell, JIT tries to use compilation to speed up the interpretation system.
For example, here’s a common JIT approach:
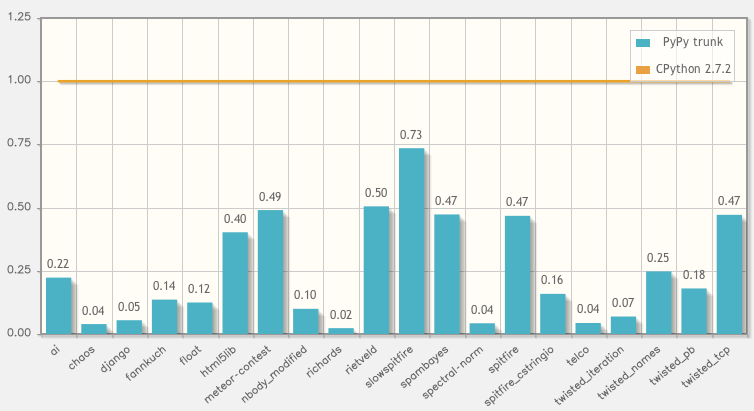
This is the whole point of PyPy: use JIT in Python (in addition, you can find previous attempts). Of course, there are other goals: PyPy aims to be cross-platform, work with a small amount of memory and support for stackless (abandoning the stack of C calls in favor of its own stack). But JIT is a major advantage. On average, based on time tests, the acceleration factor is 6.27 . More detailed data can be obtained from the PyPy Speed Center scheme:
PyPy has a huge potential, and at the moment it is well compatible with CPython (so you can run Flask, Django , etc. on it).
But with PyPy there is a lot of confusion. (appreciate, for example, this meaningless suggestion to create PyPyPy ...). In my opinion, the main reason is that PyPy is also:
1. The Python interpreter written in RPython (not Python (I lied to you before)). RPython is a subset of Python with static typing. In Python, having a thorough conversation about types is “ generally impossible ” why is it so difficult? Consider the following:
This is the correct Python code (thanks to Ademan 's). What type of x? How can we discuss variable types when types are not even forced?). In RPython, we sacrifice some flexibility, but in return we can make it much easier to manage memory and much more, which helps with optimization.
2. A compiler that compiles RPython code into different formats and supports JIT. The default platform is C, that is, the RPython-in-C compiler, but you can also choose JVM and others as the target platform.
For ease of description, I will call them PyPy (1) and PyPy (2).
Why may need these two things, and why - in one set? Think of it this way: PyPy (1) is an interpreter written in RPython. That is, it takes the user code on Python and compiles it into bytecode. But for the interpreter itself (written in RPython) to work, it must be interpreted by another implementation of Piton, right?
So, you can just use CPython to run the interpreter. But it will not be too fast.
Instead, we use PyPy (2) (called the RPython Toolchain ) to compile the PyPy interpreter into code for another platform (for example, C, JVM, or CLI) to run on the target machine, with the addition of JIT. It's magical: PyPy dynamically adds JIT to the interpreter, generating its own compiler! (Again, this is insane: we compile the interpreter by adding another separate, independent compiler).
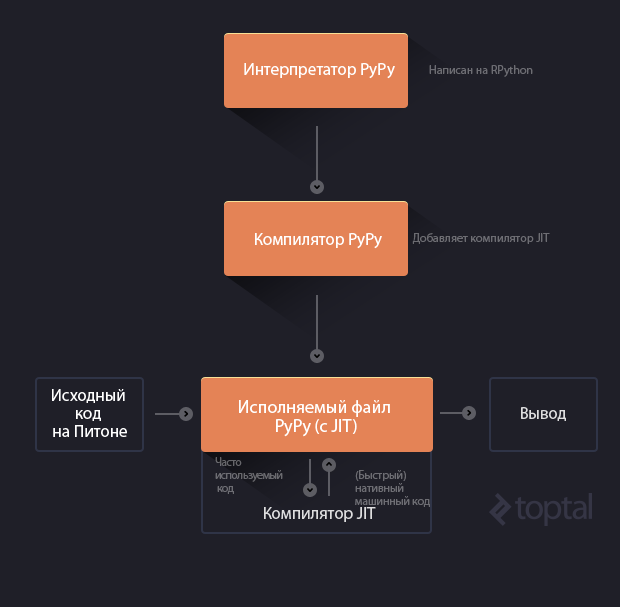
In the end, the result will be a standalone executable file that interprets the source code on Python and uses JIT optimization. Exactly what is needed! It’s hard to understand, but perhaps this scheme will help:
To repeat: the real beauty of PyPy is that we can write a bunch of different Python interpreters in RPython without worrying about JIT (not counting a couple of details ). PyPy then implements JIT for us using the RPython Toolchain / PyPy (2).
In fact, if you dig deeper into the abstraction, you can theoretically write an interpreter of any language, send it to PyPy and get a JIT for that language. This is possible because PyPy concentrates on optimizing the interpreter itself, rather than the details of the language that it interprets.
As a digression, I would like to point out that JIT itself is absolutely amazing. He uses a technique called “tracing”, which works as follows :
You can learn more from this easily accessible and very interesting publication .
To summarize, we use the RPython-in-C PyPy compiler (or another target plat form) to compile the PyP interpreter implemented in RPython.
Why is it all so amazing? Why is it worth chasing this crazy idea? In my opinion, Alex Gaynor explained it very well on his blog : “[For the PyPy future] because [he] is faster, more flexible and is the best platform for Python development”.
In short:
Python 3000 (Py3k) : the alternative name for Python 3.0, the main release of Python with backward compatibility , which appeared in 2008 . year The Py3k team predicted that it would take about five years for the new version to take root completely. And while most (attention: far-fetched statement) Python developers continue to use Python 2.x, people are increasingly thinking about Py3k.
Cython : a Python superset that includes the ability to call C functions.
Numba : “a specialized just-in-time compiler,” which adds JIT to the annotated Python code. Simply put, you give him clues, and he speeds up some parts of your code. Numba is part of the Anaconda distribution of a set of packages for analyzing and managing data.
IPython : is very different from everything we discussed. Computing environment for Python. Interactive, with support for GUI packages, browsers, and so on.
Psyco : Python expansion module , one of the first attempts of Python in the JIT area. Long marked as “unsupported and dead” . Psyco's lead developer Armin Rigo is currently working on PyPy .
Surprisingly, this is a rather ambiguous statement. What do I mean by “Python”? Maybe an abstract Python interface? Or CPython, a common implementation of Python (not to be confused with a similar Cython name)? Or do I mean something completely different? Maybe I indirectly refer to Jython, or IronPython, or PyPy. Or maybe I digress so much that I’m talking about RPython or RubyPython (which are very different).
Despite the similarity in the names of the above technologies, some of them have completely different tasks (or, at least, work in completely different ways)
')
When working with Python, I encountered a bunch of such technologies. * Ython tools. But only recently I took the time to figure out what they are, how they work and why they (each in its own way) are necessary.
In this post, I'll start from scratch and go through the different implementations of Python, and finish with a detailed introduction to PyPy, which, in my opinion, is the future of the language.
It all starts with an understanding of what “Python” really is.
If you have a good understanding of machine code, virtual machines, and so on, you can skip this section.
Python interpretable or compiled?
This is a common source of misunderstanding among newcomers Python.
The first thing you need to understand: “Python” is an interface. There is a specification that describes what Python should do and how it should behave (which is true for any interface). And there are several implementations (which is also true for any interface).
Second: “interpretable” and “compiled” are implementation properties, but not interface.
So the question itself is not entirely correct.
In the case of the most common implementation (CPython: written in C, often simply called “Python”, and, of course, the one that you use if you have no idea what I'm talking about) the answer: interpreted, with some compilation. CPython compiles * source code on Python into bytecode, and then interprets this bytecode by running it in the process.
* Note: this is not exactly “compilation” in the traditional sense. Usually, we think that “compilation” is a conversion from a high-level language to machine code. However, in some way it is “compilation”.
Let's explore this answer better, as it will help us understand some of the concepts that await us in this article.
Bytecode or machine code
It is very important to understand the difference between bytecode and machine (or native) code. Perhaps the easiest way to understand it is by example:
- C is compiled into machine code, which is subsequently run directly by the processor. Each instruction causes the processor to perform different actions.
- Java is compiled into bytecode, which subsequently runs on a Java Virtual Machine (JVM), an abstract computer that runs programs. Each instruction is processed by a JVM that interacts with the computer.
Strongly simplifying: machine code is much faster, but bytecode is better portable and protected.
The machine code may vary depending on the machine, while the bytecode is the same on all machines. We can say that the machine code is optimized for your configuration.
Returning to CPython, the chain of operations looks like this:
1. CPython compiles your Python source code into bytecode.
2. This bytecode runs on the CPython virtual machine.
Newbies often assume that Python is compiled due to the presence of .pyc files. This is partly true: .pyc files are compiled bytecode, which is subsequently interpreted. So if you run your code on Python, and you have a .pyc file, then it will work faster the second time, because it won't need to be recompiled into bytecode again.
Alternative virtual machines: Jython, IronPython, and others
As I said above, Python has several implementations. Again, as mentioned above, CPython is the most popular. This version of Python is written in C and is considered the default implementation.
But what about alternatives? One of the most prominent is Jython , a Java Python implementation that uses the JVM. While CPython generates bytecode to run on a CPython VM, Jython generates Java bytecode to run on a JVM (this is the same that is generated when compiling a Java program).
“Why might you need to use an alternative implementation?”, You ask. Well, for starters, different implementations get along well with different sets of technologies .
CPython makes it easier to write C extensions for Python code because at the end it is started by the C interpreter. Jython, in turn, makes it easy to work with other Java programs: you can import any Java classes without any extra effort by invoking and using your Java classes from Jython programs. (Note: if you haven’t seriously thought about it yet, it’s pretty crazy. We have lived up to the time when you can mix different languages and compile them into one entity. As Rostin noted, programs mixing code in Fortran with C appeared a long time ago, so it's not entirely new. But it's still cool.)
As an example, here is the correct jython code:
[Java HotSpot(TM) 64-Bit Server VM (Apple Inc.)] on java1.6.0_51
>>> from java.util import HashSet
>>> s = HashSet(5)
>>> s.add("Foo")
>>> s.add("Bar")
>>> s
[Foo, Bar]IronPython is another popular Python implementation, written entirely in C # and intended for .NET. In particular, it runs on a .NET virtual machine, if you can call it that, on Microsoft's Common Language Runtime (CLR) , comparable to the JVM.
Jython can be said to be: Java :: IronPython: C #. They run on the appropriate virtual machines, it is possible to import C # classes into IronPython code and Java classes into Jython code, and so on.
Quite really survive without touching anything except CPython. But, moving to other implementations, you get an advantage, mainly because of the stack of technologies used. Do you use many languages based on JVM? Jython might suit you. All on .NET? Perhaps you should try IronPython (and, perhaps, you already did).
By the way, although this will not be a reason for switching to another implementation, it is worth mentioning that these implementations are actually different in behavior. This concerns not only the methods of interpreting Python code. However, these differences are usually not-significant, they disappear and appear over time due to active development. For example, IronPython uses Unicode strings by default ; however, CPython uses ASCII in versions 2.x (yielding a UnicodeEncodeError error for non-ASCII characters), and supports default Unicode characters in versions 3.x.
Just-in-Time Compilation: PyPy and the Future
So, we have a Python implementation written in C, another one in Java, and a third in C #. The next logical step: the implementation of Python, written in ... Python. (A prepared reader will notice that this statement is a bit deceptive).
That is why it can be confusing. To begin with, let's discuss on-the-fly compilation (just-in-time or JIT).
Jit Why and how
Let me remind you that native native code is much faster than bytecode. Well, what if it were possible to compile part of the bytecode and run it as native code? I would have to “pay” some price (in other words: time) for compiling the bytecode, but if the result is faster, then this is great! This is what motivates JIT compilation, a hybrid technique that combines the advantages of interpreters and compilers. In a nutshell, JIT tries to use compilation to speed up the interpretation system.
For example, here’s a common JIT approach:
- Determine the bytecode that runs frequently.
- Compile it into native machine code.
- Cache the result.
- Whenever it is necessary to run the same bytecode, use the already compiled machine code and reap the rewards (in particular, the speed increase).
This is the whole point of PyPy: use JIT in Python (in addition, you can find previous attempts). Of course, there are other goals: PyPy aims to be cross-platform, work with a small amount of memory and support for stackless (abandoning the stack of C calls in favor of its own stack). But JIT is a major advantage. On average, based on time tests, the acceleration factor is 6.27 . More detailed data can be obtained from the PyPy Speed Center scheme:
PyPy is hard to figure out
PyPy has a huge potential, and at the moment it is well compatible with CPython (so you can run Flask, Django , etc. on it).
But with PyPy there is a lot of confusion. (appreciate, for example, this meaningless suggestion to create PyPyPy ...). In my opinion, the main reason is that PyPy is also:
1. The Python interpreter written in RPython (not Python (I lied to you before)). RPython is a subset of Python with static typing. In Python, having a thorough conversation about types is “ generally impossible ” why is it so difficult? Consider the following:
x = random.choice([1, "foo"])This is the correct Python code (thanks to Ademan 's). What type of x? How can we discuss variable types when types are not even forced?). In RPython, we sacrifice some flexibility, but in return we can make it much easier to manage memory and much more, which helps with optimization.
2. A compiler that compiles RPython code into different formats and supports JIT. The default platform is C, that is, the RPython-in-C compiler, but you can also choose JVM and others as the target platform.
For ease of description, I will call them PyPy (1) and PyPy (2).
Why may need these two things, and why - in one set? Think of it this way: PyPy (1) is an interpreter written in RPython. That is, it takes the user code on Python and compiles it into bytecode. But for the interpreter itself (written in RPython) to work, it must be interpreted by another implementation of Piton, right?
So, you can just use CPython to run the interpreter. But it will not be too fast.
Instead, we use PyPy (2) (called the RPython Toolchain ) to compile the PyPy interpreter into code for another platform (for example, C, JVM, or CLI) to run on the target machine, with the addition of JIT. It's magical: PyPy dynamically adds JIT to the interpreter, generating its own compiler! (Again, this is insane: we compile the interpreter by adding another separate, independent compiler).
In the end, the result will be a standalone executable file that interprets the source code on Python and uses JIT optimization. Exactly what is needed! It’s hard to understand, but perhaps this scheme will help:
To repeat: the real beauty of PyPy is that we can write a bunch of different Python interpreters in RPython without worrying about JIT (not counting a couple of details ). PyPy then implements JIT for us using the RPython Toolchain / PyPy (2).
In fact, if you dig deeper into the abstraction, you can theoretically write an interpreter of any language, send it to PyPy and get a JIT for that language. This is possible because PyPy concentrates on optimizing the interpreter itself, rather than the details of the language that it interprets.
As a digression, I would like to point out that JIT itself is absolutely amazing. He uses a technique called “tracing”, which works as follows :
- Run the interpreter and interpret everything (without adding a JIT).
- Perform easy profiling of the interpreted code.
- Identify operations that have already been performed.
- Compile these pieces of code into machine code.
You can learn more from this easily accessible and very interesting publication .
To summarize, we use the RPython-in-C PyPy compiler (or another target plat form) to compile the PyP interpreter implemented in RPython.
Conclusion
Why is it all so amazing? Why is it worth chasing this crazy idea? In my opinion, Alex Gaynor explained it very well on his blog : “[For the PyPy future] because [he] is faster, more flexible and is the best platform for Python development”.
In short:
- It is fast because it compiles the source code into native code (using JIT).
- It is flexible - because it adds JIT to the interpreter effortlessly.
- It is flexible (again) - because you can write interpreters in RPython, which subsequently simplifies the extension compared to the same C (in fact, it simplifies so much that even there is an instruction for writing your own interpreters).
Addition: other names you may have heard
Python 3000 (Py3k) : the alternative name for Python 3.0, the main release of Python with backward compatibility , which appeared in 2008 . year The Py3k team predicted that it would take about five years for the new version to take root completely. And while most (attention: far-fetched statement) Python developers continue to use Python 2.x, people are increasingly thinking about Py3k.
Cython : a Python superset that includes the ability to call C functions.
- Task: allow writing C extensions for Python programs.
- It also allows you to add static typing to existing Python code, which, after recompiling, can help achieve C-like performance.
- Reminds PyPy, but it is not the same. In the case of Cython, you force typing in user code before serving to the compiler. In PyPy, you write good old Python, and the compiler is responsible for any optimization.
Numba : “a specialized just-in-time compiler,” which adds JIT to the annotated Python code. Simply put, you give him clues, and he speeds up some parts of your code. Numba is part of the Anaconda distribution of a set of packages for analyzing and managing data.
IPython : is very different from everything we discussed. Computing environment for Python. Interactive, with support for GUI packages, browsers, and so on.
Psyco : Python expansion module , one of the first attempts of Python in the JIT area. Long marked as “unsupported and dead” . Psyco's lead developer Armin Rigo is currently working on PyPy .
Language bindings
- RubyPython : a bridge between Ruby and Python virtual machines. Allows you to embed Python code into Ruby code. You designate where Python begins and ends, and RubyPython provides data transfer between virtual machines.
- PyObjc : a language connection between Python and Objective-C that behaves like a bridge between them. In practice, this means that you can use Objective-C libraries (including everything you need to create an application under OS X) in Python code, and Python modules in Objective-C code. This is convenient because CPython is written in C, which is a subset of Objective-C.
- PyQt : while PyObjc allows you to associate Python with OS X GUI components, PyQt does the same for the Qt framework. This makes it possible to create full-fledged graphical interfaces, access SQL databases, and so on. Another tool aimed at porting the simplicity of Python to other frameworks.
Javascript frameworks
- pyjs (Pajamas) : a framework for creating web and desktop applications on Python. Includes a Python-to-JavaScript compiler, a set of widgets and some other tools.
- Brython : a Python virtual machine written in Javascript. Allows you to run Py3k code in a web browser.
Source: https://habr.com/ru/post/209812/
All Articles