Scaling is simple. Part Three - Strategies
In the previous parts ( here and here ) we talked about the basic architectural principles of building scalable portals. Today we will continue to talk about optimizing a properly built portal. So, scaling strategies.
Caches are a good thing to enhance the impact force of an individual component or service. But each optimization once comes to an end. This is the latest moment when it is worth thinking about how to maintain multiple instances of your services, in other words, how to scale your architecture. Different types of nodes can be scaled differently. The general rule is as follows: the closer the component is to the user, the easier it is to scale it.
Performance is not the only reason to work on scaling. The availability of the system to a large extent also depends on whether we can run several instances of each component in parallel, and, therefore, be able to transfer the loss of any part of the system. The top of perfection of scaling is to be able to administer the system in an elastic way , that is, to adjust the use of resources to traffic.
')
Scaling the presentation layer is usually easy. This is the level to which web applications run in a web server or servlet container (for example, tomcat or jetty) and are responsible for generating a markup, that is, HTML, XML, or JSON.
You can simply add and remove new servers as needed - as long as a single web server:
It is more difficult to scale the application level (application tier) - the level where services run. But before moving on to the application level, let's look at the level behind it — the database.
The sad truth about scaling through the database is that it does not work. And although from time to time representatives of various database vendors are trying to convince us again that they can scale precisely this time - at the most crucial moment they will leave us. Little disclaimer: I'm not saying that you should not do database clusters or replication a la master / slave. There are many reasons for using clusters and replicas, but performance is not one of them.
This is the main reason why applications scale so poorly through databases: the main task of the database is only reliable data storage (ACID and all that). Reading the data is much harder for them (before shouting “how” and “why”, think: why do you need such a number of indexers like lucene / solar / elastic search?). Since we cannot scale through the base, we need to scale through the application tier. There are many reasons why this works perfectly, I will mention two:
There are different strategies for scaling services.
First you need to determine what the state of the service (state). The state of one instance of the service is that information that is known only to him and which, accordingly, distinguishes it from other instances.
A service instance is usually a JavaVM in which one copy of this service runs. Information that defines its state is usually data that goes into the cache. If the service has no own data at all, it is stateless (stateless). In order to reduce the load on any service, you can run multiple instances of this service. Strategies for allocating traffic to these instances are, in general, scaling strategies.
The simplest strategy is Round-Robin. In addition, each client "talking" with each instance of the service, which are used in turn, that is, one after another, in a circle. This strategy works well as long as the services do not have a stateless state and perform simple tasks, such as sending emails through the external interface.
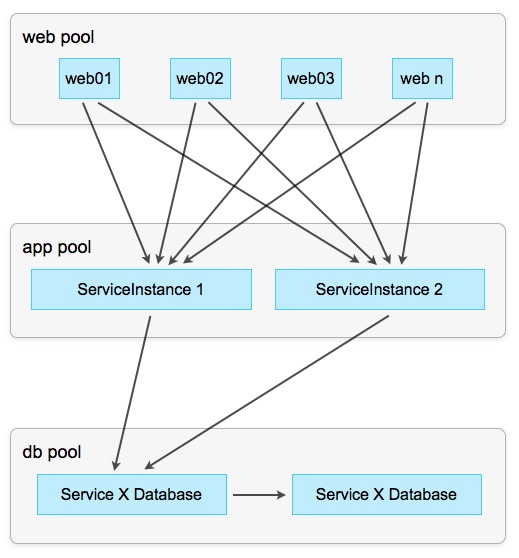
Scheme 5: Distribute calls to services on the principle of Round-Robin
When instances of services have states, they should be synchronized with each other, for example, by announcing changes in state via EventChannel or another Publish / Subscriber version:

Scheme 6: Round-Robin with state synchronization
In addition, each instance informs the other instances of all changes that it makes to each saved object. In turn, the remaining instances repeat the same operation locally, changing their private state (state), and thereby maintaining the state of the service consistent (consistent) across all instances.
This strategy works well with little traffic. However, with its increase, there are problems with the ability to simultaneously change the same object in several instances.
Routing is used to combat this. In this case, routing means that the service instance is selected depending on the context. The context can be a client, an operation or data. Data routing, sharding , is the most powerful routing tool: it refers to the routing algorithm that selects the target instance of the service based on the parameters of the operation (that is, data).
Ideally, we have a unique parameter, such as UserId, which can be easily converted to numerical form and divide with the remainder. Separating by the number of working instances, the remainder points to the target instance of the request: all queries with the remainder 0 go to the first instance, with the remainder 1 to the second instance, and so on.
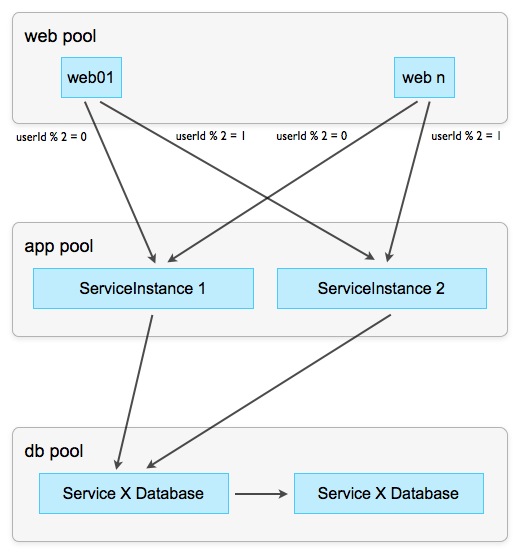
Scheme 7: Sharding Remaining
This strategy has a useful side effect: due to the fact that all requests according to the same user always fall on the same instance, the data is fragmented. This means smaller caches, if desired, fragmented databases (that is, each instance or their group has its own database) and other optimization tastes.
With the presence of an appropriate middleware, you can step one step further and combine different strategies. For example, you can group several instances into groups into which to distribute requests by sharding, and inside groups use Round-Robin for elasticity. The number of such combined strategies is too large ( another example ) to describe them all in one post, and depends on the specific problem.
Not always and not any data can be segmented, especially when one operation simultaneously changes two data sets in different contexts. A classic example is the delivery of a message from user A to user B, in which both mailboxes change simultaneously. It is impossible to find an algorithm for distributing data across instances (sharding), which ensures that user A and B boxes are in one instance of the service. Butthere is a ruin to the old woman and there are solutions for this situation. The simplest thing is to implicitly divide the service (ideally through middleware) so that the client knows nothing about it. For example:
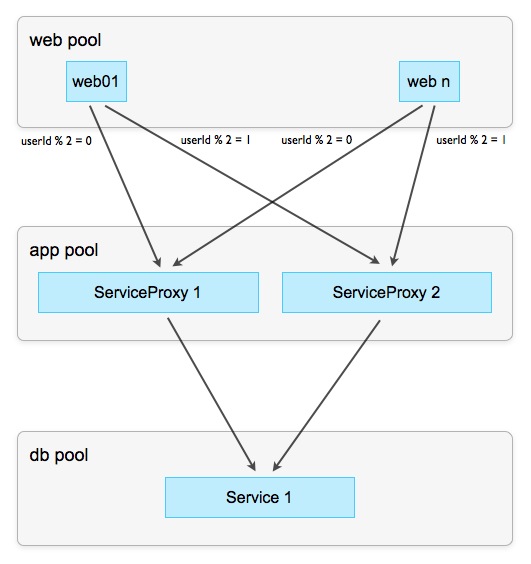
Scheme 8: Proxy Services
The task of instances of proxy services is to process and respond to reading requests, not bringing them to the master service. Since we have much more reading than writing operations (remember the initial installation ), having saved the master service from them, we will make his life much easier. Reading operations usually take place in the context of one (active) user and, therefore, can be “extended”, as described above. The remaining writing operations go through a proxy to the master, but, due to the fact that the bulk of the load remained on the proxy, much less hemorrhoids are already delivered.
Within the framework of this series ( here , here and, in fact, here) we talked about how to find the right architecture and with what tools to scale it. I hope I convinced the reader that the time spent searching and following architectural paradigms is an investment that pays off many times in difficult times. Slave-Proxies, Round-Robin routing or zero-cache is not what we think about first of all, starting to work on a new portal. Yes, and do not embed them "just in case" - it is important to know how to use them and have an architecture that allows the use of such tools.
Not every portal should scale, but those that should be able to do it quickly. At the same time, relying solely on technology (NoSQL, etc.) means putting the steering wheel in the wrong hands, and if the choice of technology is wrong, collect fragments of your system with a broom.
If from the very beginning you choose the right architecture, find your principles and paradigms and adhere to them, then the answer to the difficulties and challenges that arise can always be found.
Good luck!
The potential of local optimization is very limited.
Caches are a good thing to enhance the impact force of an individual component or service. But each optimization once comes to an end. This is the latest moment when it is worth thinking about how to maintain multiple instances of your services, in other words, how to scale your architecture. Different types of nodes can be scaled differently. The general rule is as follows: the closer the component is to the user, the easier it is to scale it.
Performance is not the only reason to work on scaling. The availability of the system to a large extent also depends on whether we can run several instances of each component in parallel, and, therefore, be able to transfer the loss of any part of the system. The top of perfection of scaling is to be able to administer the system in an elastic way , that is, to adjust the use of resources to traffic.
')
Scaling the presentation layer is usually easy. This is the level to which web applications run in a web server or servlet container (for example, tomcat or jetty) and are responsible for generating a markup, that is, HTML, XML, or JSON.
You can simply add and remove new servers as needed - as long as a single web server:
- stateless, or
- its state is recoverable — for example, because it consists entirely of caches, or
- their (caches) state refers to specific users and there is a guarantee that the same user will always get on the same server (session stickiness).
It is more difficult to scale the application level (application tier) - the level where services run. But before moving on to the application level, let's look at the level behind it — the database.
The sad truth about scaling through the database is that it does not work. And although from time to time representatives of various database vendors are trying to convince us again that they can scale precisely this time - at the most crucial moment they will leave us. Little disclaimer: I'm not saying that you should not do database clusters or replication a la master / slave. There are many reasons for using clusters and replicas, but performance is not one of them.
This is the main reason why applications scale so poorly through databases: the main task of the database is only reliable data storage (ACID and all that). Reading the data is much harder for them (before shouting “how” and “why”, think: why do you need such a number of indexers like lucene / solar / elastic search?). Since we cannot scale through the base, we need to scale through the application tier. There are many reasons why this works perfectly, I will mention two:
- At this level, a large part of the treatise "Knowledge of the application and its data." We can scale, knowing what the application does and how it is used.
- Here you can work with the help of programming language tools that are much more powerful than the tools provided to us by the database level.
There are different strategies for scaling services.
Scaling strategies.
First you need to determine what the state of the service (state). The state of one instance of the service is that information that is known only to him and which, accordingly, distinguishes it from other instances.
A service instance is usually a JavaVM in which one copy of this service runs. Information that defines its state is usually data that goes into the cache. If the service has no own data at all, it is stateless (stateless). In order to reduce the load on any service, you can run multiple instances of this service. Strategies for allocating traffic to these instances are, in general, scaling strategies.
The simplest strategy is Round-Robin. In addition, each client "talking" with each instance of the service, which are used in turn, that is, one after another, in a circle. This strategy works well as long as the services do not have a stateless state and perform simple tasks, such as sending emails through the external interface.
Scheme 5: Distribute calls to services on the principle of Round-Robin
When instances of services have states, they should be synchronized with each other, for example, by announcing changes in state via EventChannel or another Publish / Subscriber version:
Scheme 6: Round-Robin with state synchronization
In addition, each instance informs the other instances of all changes that it makes to each saved object. In turn, the remaining instances repeat the same operation locally, changing their private state (state), and thereby maintaining the state of the service consistent (consistent) across all instances.
This strategy works well with little traffic. However, with its increase, there are problems with the ability to simultaneously change the same object in several instances.
Routing is used to combat this. In this case, routing means that the service instance is selected depending on the context. The context can be a client, an operation or data. Data routing, sharding , is the most powerful routing tool: it refers to the routing algorithm that selects the target instance of the service based on the parameters of the operation (that is, data).
Ideally, we have a unique parameter, such as UserId, which can be easily converted to numerical form and divide with the remainder. Separating by the number of working instances, the remainder points to the target instance of the request: all queries with the remainder 0 go to the first instance, with the remainder 1 to the second instance, and so on.
Scheme 7: Sharding Remaining
This strategy has a useful side effect: due to the fact that all requests according to the same user always fall on the same instance, the data is fragmented. This means smaller caches, if desired, fragmented databases (that is, each instance or their group has its own database) and other optimization tastes.
With the presence of an appropriate middleware, you can step one step further and combine different strategies. For example, you can group several instances into groups into which to distribute requests by sharding, and inside groups use Round-Robin for elasticity. The number of such combined strategies is too large ( another example ) to describe them all in one post, and depends on the specific problem.
Not always and not any data can be segmented, especially when one operation simultaneously changes two data sets in different contexts. A classic example is the delivery of a message from user A to user B, in which both mailboxes change simultaneously. It is impossible to find an algorithm for distributing data across instances (sharding), which ensures that user A and B boxes are in one instance of the service. But
Scheme 8: Proxy Services
The task of instances of proxy services is to process and respond to reading requests, not bringing them to the master service. Since we have much more reading than writing operations (remember the initial installation ), having saved the master service from them, we will make his life much easier. Reading operations usually take place in the context of one (active) user and, therefore, can be “extended”, as described above. The remaining writing operations go through a proxy to the master, but, due to the fact that the bulk of the load remained on the proxy, much less hemorrhoids are already delivered.
Epilogue
Within the framework of this series ( here , here and, in fact, here) we talked about how to find the right architecture and with what tools to scale it. I hope I convinced the reader that the time spent searching and following architectural paradigms is an investment that pays off many times in difficult times. Slave-Proxies, Round-Robin routing or zero-cache is not what we think about first of all, starting to work on a new portal. Yes, and do not embed them "just in case" - it is important to know how to use them and have an architecture that allows the use of such tools.
Not every portal should scale, but those that should be able to do it quickly. At the same time, relying solely on technology (NoSQL, etc.) means putting the steering wheel in the wrong hands, and if the choice of technology is wrong, collect fragments of your system with a broom.
If from the very beginning you choose the right architecture, find your principles and paradigms and adhere to them, then the answer to the difficulties and challenges that arise can always be found.
Good luck!
Source: https://habr.com/ru/post/209758/
All Articles