Procurement for data schema with tests, CI, without preference
A relational database is a comparatively unknown beast, and has a reputation for generating problems. Not that there were no problems, but as with other tools, most often difficulties arise from their inability (RDBMS) to prepare.
Cooking from one article can not be learned, but one dish sdyuzhim.
I tried to select a skeleton, a set of scripts, on the basis of which you can make your PostgreSQL data schemes and test them with pgTAP: github.com/C-Pro/pg_skeleton
And as a nice bonus, I screwed this case to Travis so that you also had CI at the start :)
For installation we will need:
')
So, in order:
If PostgreSQL is not installed yet - set. If you have Ubuntu or Debian, I recommend connecting their apt.postgresql.org repository (see the installation instructions here: wiki.postgresql.org/wiki/Apt ). Immediately I warn you - they have no packages on Ubuntu 13, they are guided by LTS releases.
Download and install the latest version of pgTAP - a framework for testing everything in PostgreSQL: pgtap.org
Archive unpack, further as usual:
The pgtap extension should now be available to the postgres server.
Install the pg_prove - perl utility to run pgTAP tests
Everything, you can download and install pg_skeleton:
It will ask you to enter the desired password for the user who owns the created database and the postgres user.
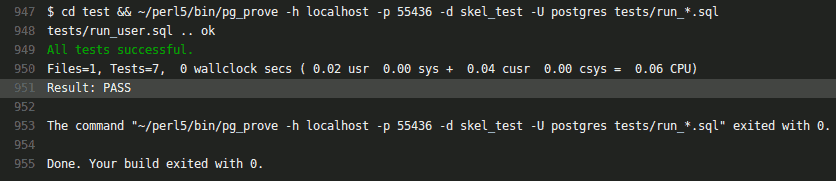
Now run the tests:
If you saw the magic word PASS - everything is great, you can disassemble the skeleton of the bones. That is, by file.
Each subfolder is named for the schema name that it contains.
The test_user folder contains scripts for creating a test_user schema (this is just an example of a schema) with one table and several examples of functions.
Such a splitting into separate files will save your nerves in the future. By separating the creation of tables, foreign constraints, functions, views, etc., in different files, you can include them in install.sql in the correct order, without falling into the trap of interdependencies such as:
The test folder also creates a schema, but this is a special schema, and it lives only as long as the tests go.
setup.sql is designed to load the fnd and test data into the temporary test scheme before running the tests. (phew how many words is the test :)
run_tests.sh with pg_prove executes the ./tests/run_<name>.sh files one by one
run_ <name> .sh are created one per scheme.
First, the setup.sql file is included in them - which loads test function definitions, auxiliary test-test.test_scheme_check_func and test data from the test_data.sh file. Then tests are run, which may be in several files that simply connect to run_ <name> .sh. After all the tests in the schema, the function “test.test_scheme_check_func” is executed. This function itself is a pgTAP test, which fails if there are functions not covered in tests in the scheme. The determination takes place by a comment to the test. The comment should begin with the name of the tested f-ii. Of course there may be uncovered overloaded functions with the same name, but this is better than no control over test coverage. After the tests are executed, rollback occurs - all created objects and loaded test data are deleted.
Well, that's probably all for now.
I repent, it turned out messy - ask what is not clear.
Use, understand, fork!
Cooking from one article can not be learned, but one dish sdyuzhim.
I tried to select a skeleton, a set of scripts, on the basis of which you can make your PostgreSQL data schemes and test them with pgTAP: github.com/C-Pro/pg_skeleton
And as a nice bonus, I screwed this case to Travis so that you also had CI at the start :)
For installation we will need:
- PostgreSQL> = 9.2 with dev heders (you have to compile the postgres extension)
- pgTAP (self extension)
- pg_prove to run tests
')
So, in order:
If PostgreSQL is not installed yet - set. If you have Ubuntu or Debian, I recommend connecting their apt.postgresql.org repository (see the installation instructions here: wiki.postgresql.org/wiki/Apt ). Immediately I warn you - they have no packages on Ubuntu 13, they are guided by LTS releases.
Download and install the latest version of pgTAP - a framework for testing everything in PostgreSQL: pgtap.org
Archive unpack, further as usual:
make && sudo make install The pgtap extension should now be available to the postgres server.
Install the pg_prove - perl utility to run pgTAP tests
sudo cpan TAP::Parser::SourceHandler::pgTAP Everything, you can download and install pg_skeleton:
git clone https://github.com/C-Pro/pg_skeleton.git cd pg_skeleton cp install.cfg.example install.cfg ./install.sh It will ask you to enter the desired password for the user who owns the created database and the postgres user.
Now run the tests:
cd test ./run_tests.sh If you saw the magic word PASS - everything is great, you can disassemble the skeleton of the bones. That is, by file.
- .gitignore - as you probably already guessed - a list of file masks ignored by git
- .travis.yml - configuration file for travis, which describes how to install the project and run the tests. When I do git push to this repository, travis runs the tests and checks if anything has broken. Build travis looks like this: travis-ci.org/C-Pro/pg_skeleton# As you can see from the history of builds and commits in the gita, you had to struggle to deploy the desired postgres to travis, install the extension, pg_prove and run the tests.
- create_db.sql - parameterized user creation script and database
- drop_db.sql - parameterized script for deleting the database and user
- extensions.sql - a script to install the required extensions when installing the schema
- install.cfg - settings: the address of the postgres server, the names of the created base and the user. Git is ignored so that you can have different settings when deployed on your machine and different servers without conflicts in git.
- install.cfg.example - setup file template
- install.sql - sql base installation script. It includes all other sql scripts to create a data schema.
- uninstall.sh - executable script to remove the database and user
Each subfolder is named for the schema name that it contains.
The test_user folder contains scripts for creating a test_user schema (this is just an example of a schema) with one table and several examples of functions.
- create_tables.sql - there is such a file in each schema folder. It contains DDL for creating schema objects.
- create_functions.sql is a script containing f-s schemas.
- users_crud.sql - there can be a lot of functions, so they are separated into different files that are included in the create_functions.sql file with the \ i command (of type include).
Such a splitting into separate files will save your nerves in the future. By separating the creation of tables, foreign constraints, functions, views, etc., in different files, you can include them in install.sql in the correct order, without falling into the trap of interdependencies such as:
create table a (x int references by); create table b (y int references ax); The test folder also creates a schema, but this is a special schema, and it lives only as long as the tests go.
setup.sql is designed to load the fnd and test data into the temporary test scheme before running the tests. (phew how many words is the test :)
run_tests.sh with pg_prove executes the ./tests/run_<name>.sh files one by one
run_ <name> .sh are created one per scheme.
First, the setup.sql file is included in them - which loads test function definitions, auxiliary test-test.test_scheme_check_func and test data from the test_data.sh file. Then tests are run, which may be in several files that simply connect to run_ <name> .sh. After all the tests in the schema, the function “test.test_scheme_check_func” is executed. This function itself is a pgTAP test, which fails if there are functions not covered in tests in the scheme. The determination takes place by a comment to the test. The comment should begin with the name of the tested f-ii. Of course there may be uncovered overloaded functions with the same name, but this is better than no control over test coverage. After the tests are executed, rollback occurs - all created objects and loaded test data are deleted.
Well, that's probably all for now.
I repent, it turned out messy - ask what is not clear.
Use, understand, fork!
Source: https://habr.com/ru/post/209584/
All Articles