Not all comments are equally helpful.
All animals are equal, but some animals are more equal than others. Animal Farm, George Orwell ( original ).
Quite a lot of articles on Habré is gaining a significant amount of comments, eg in the articles " best for the month " there are usually more than a hundred. Over the years of reading Habr, the impression was created that in about half of the cases, for comments of the first level, we get this picture
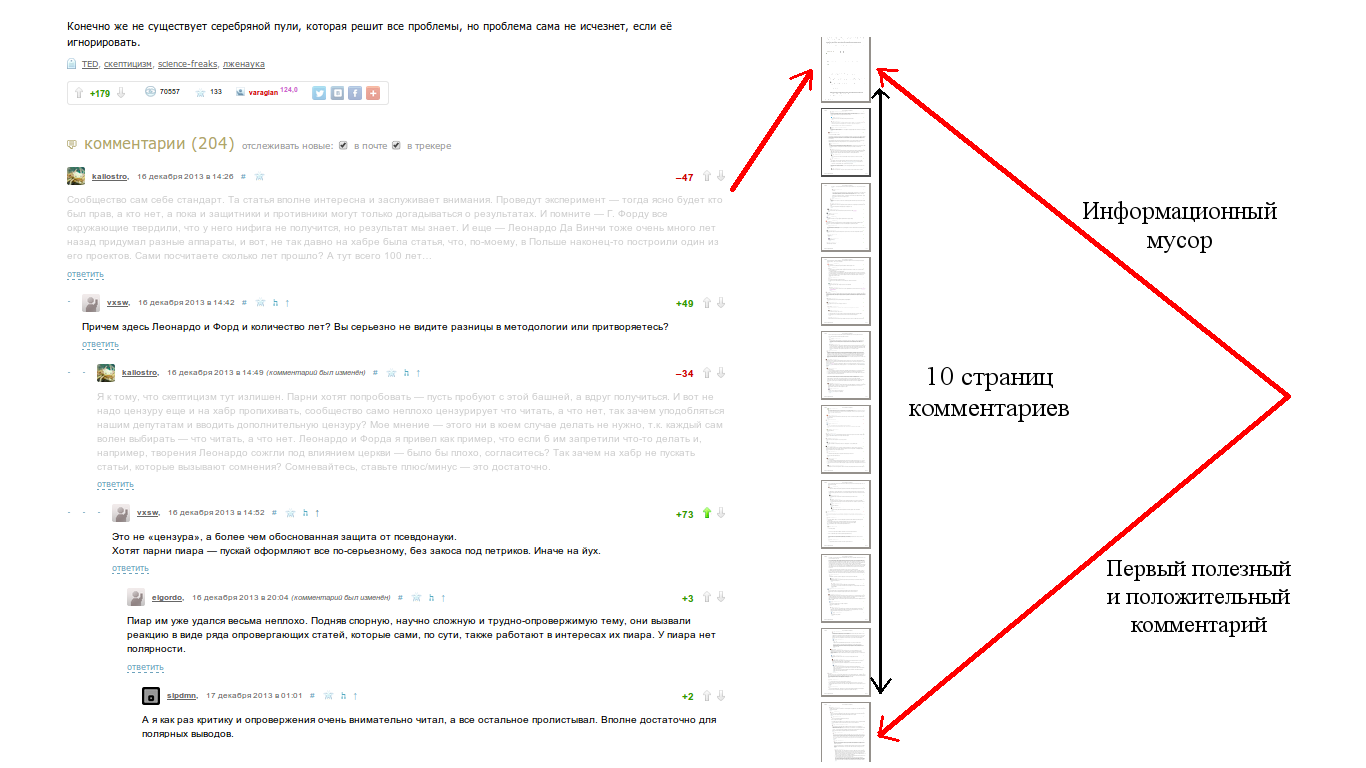
(The picture is made on the basis of the habra-article "List of the skeptic" ).
Under the cat a story, what sorting of comments can be, where they are used and a brief discussion about how comments can be sorted at all (and why).
Generally speaking, the problem of sorting comments, posts and everything else is not new: infographics from Facebook, sorting comments on reddit here and here and a brief description of the parameters of the algorithm from digg.
Basic methods for sorting first level comments
Let's go from simple to complex, briefly describing and characterizing methods. Let's start with the most simple and naive methods: averaging and its variations (details are described here ).
')
Hereinafter, except for separately stated cases, by comment we mean the “top-level commentary”. The meaning is approximately as follows, the top-level comments are addressed to the article itself, while the comments of the second, third, etc. are discussions around the commentary. Methods that take into account the entire comment thread will be briefly discussed at the end of the article.
The task is to assign some number of scores (comments weight) to the comments and sort the entire list by this parameter.
The number of pluses minus the number of minuses

This is used in the online dictionary urbandictionary .
This method is the simplest, but far from the most appropriate user expectations. For example, in the picture above, we see that the description of which is 72% percent of positive ratings is lower than the description of which 70% percent of positive ratings.
Relative average rating: the number of pluses to the total number of assessments
One of the sorting options on Amazon is the relative average score. Suppose we are looking for a toaster and enabled sorting according to user feedback:
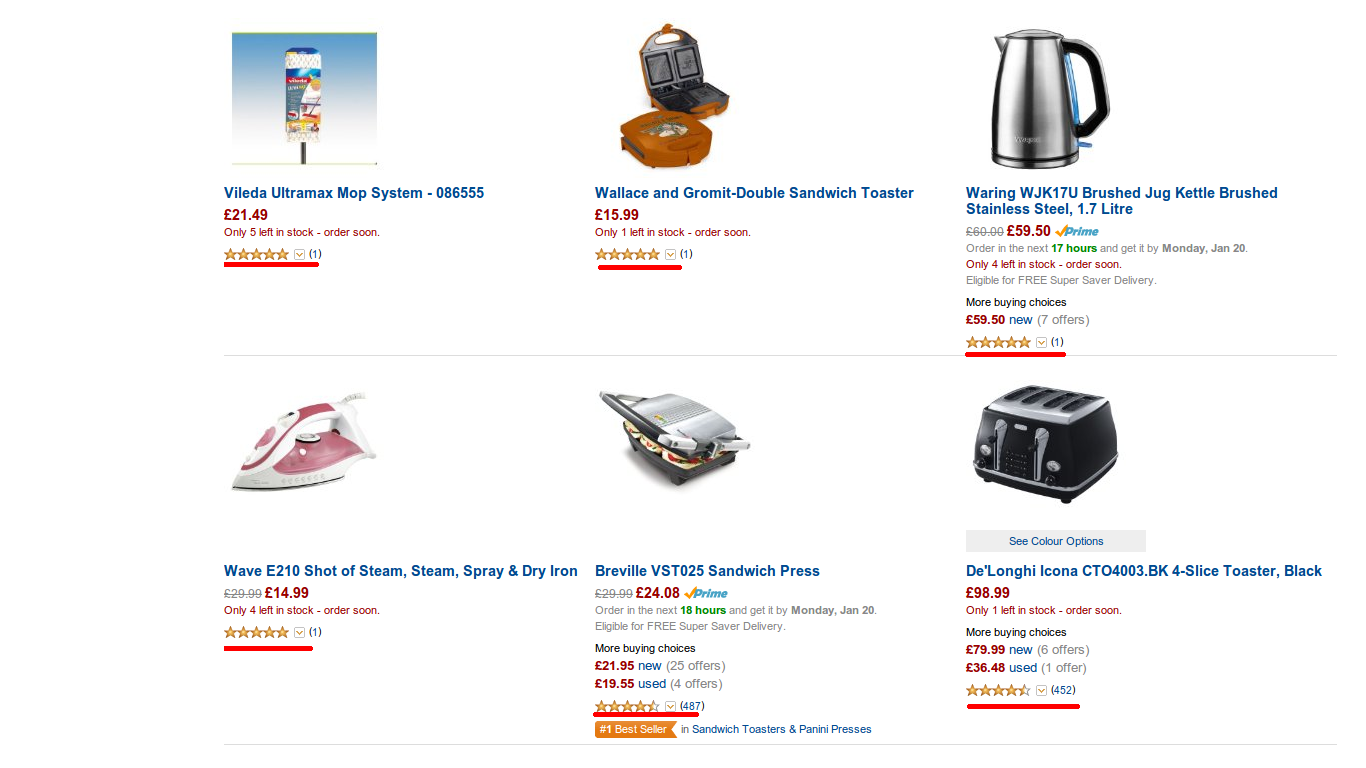
It turns out that an element with a single voice in 5 * will always be above any element that has at least one other rating (4 *, 3 *, 2 *, 1 *), regardless of the number of these estimates. Simply put, if we have a product that has 9999 ratings of 5 * and one in 4 *, then this product will be lower than the product with a single rating of 5 *.
The probability of waiting for a positive assessment
Before the elections, public opinion polls always take place, where they try to restore the general picture of the world by a small number of simplified ones. For the small number of measurements available to us, we are trying to understand the following, having an observable number of assessments (pros and cons of the product), with a probability of at least 0.85, what is the “real share” of positive ratings?
As usual, such things are calculated in an accessible language written in the book:
Probabilistic Programming & Bayesian Methods for Hackers
In short, such calculations are too laborious, so they use the formula for the lower limit of the Wilson confidence interval (that is, you have to use the estimated value):
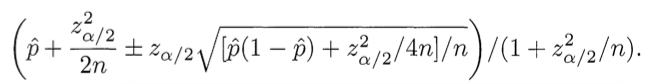
p̂ is the observed relative number of pluses, n is the total number of estimates, z α / 2 is taken from the tables, it is the quantile (1 - α / 2) of the standard normal distribution (for 15% z = 1 - 85% confidence, for 5% z = 1.6 - 95% confidence)
If it seems to you that something is written above like this:

That in understandable language and in detail it is described here , at the end here and it is best described here . You can also find short and understandable implementations of the described method (and many other clarifying pictures).
In various variations, this method, as part of the ranking algorithm, uses reddit, digg and yelp.
An explanation and an example from Randal Munroe (author of xkcd, he also implemented this algorithm in reddit):
If a comment has only one plus and zero minuses, then the relative number of pluses is 1.0, but since there is little data [n - approx. author], the system will place it at the end of the list. And if he has 10 pluses and one minus, then the system will have enough confidence [within the meaning of evidence; confirming data] that placing this comment is higher than the comment with 40 pluses and 20 minuses - considering that by the time the comment has received 40 pluses, it will almost certainly have less than 20 minuses. And the main charm of the system is that if it makes mistakes (in 15% of cases), it will quickly get enough data so that a comment with less data will be at the top.
In general, intuition, for such methods of Bayesian inference, is as follows: we have some insight into how people vote for posts, for example, you can get a plus with a probability of 0.7, and a minus with a probability of 0.3 is a sort of spoiled coin. Having received a new piece of information on a specific coin, we adjust our understanding of it according to Bayes' rule:
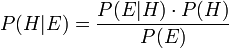
where H is a hypothesis (Hypothesis), E is a surveyed data (Evidence), P (E | H) = the probability to get the result E, if the hypothesis H is true, together they give us the opportunity to say what the probability of the hypothesis H is with the result E.
New parameters in sorting
The above algorithms use only the number of pros and cons. In this part we will understand, and what other parameters may affect the ranking of comments.
The main sources will serve the following articles:
Reddit, Stumbleupon, Del.icio.us and Hacker News Algorithms Exposed!
How Hacker News ranking algorithm
How Reddit ranking algorithms work
Time
Why would anyone even need to use time, except in chronological sorting? Imagine that we are moving to articles by reference from “What is being discussed?” Quite logical (although of course, like other value judgments, it is debatable) that the user expects discussion and fresh comments, it is thanks to them that the articles fall into this section.
How is this with other large sites with custom content? We'll look at reddit and hacker news.
Reddit algorithm for posts
Reddit uses two different ranking algorithms: one for posts, the second for comments. For comments, use the option described above with the lower limit of the Wilson confidence interval, but for posts, time is taken into account:
briefly describe the algorithm
Let A be the time in seconds when the post was published, B the time to create the reddit resource in seconds, then t
t = A - B
those. relative lifetime of a post in seconds.
x = difference between the number of pros and cons of the post.
z = | x | if x! = 0, otherwise z = 1.
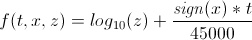
Algorithm hacker news
This resource uses the same algorithm to sort comments and posts.
Let t be the number of hours since publication, v is the number of votes, G is a constant (they say, it is 1.8 by default):
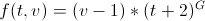
And why goat bayan?
It would seem that in the case of commentary ratings should be enough and time should not play a significant role. On the other hand, when the number of comments grows, many users simply do not get to the very end (try scrolling through 300-400 comments). A possible alternative is to sort not by one, but by several parameters, i.e. take into account the time For example, if all comments have 0 votes, then “fresh comments” are preferable to the old ones, since the old ones had time to collect a certain number of advantages, and if they did not collect them, then it may be better to give preference to new comments.
Alternatively, we can use time as a small decay element (weight decay) in the ranking function, for example, as in reddit posts or hacker news comments.
Ranking based on the entire branch
The natural assumption will take into account comments in one branch with some weight depending on their level \ position in the branch (in the trivial case, we can consider the entire branch as a set of equal comments, that is, with the same weight). Suppose that v i + is the number of pluses for comment i (the same notation for minuses), and l i is the nesting level of comment i, and I is the set of all indices of a comment in a branch, then we can offer the simplest generalization of the first method including all branches:

(here we mean that v i + , l i are actually functions that return a scolar on the comment index, so they are not in the input data).
In a similar (naive) way, other methods of ranking comments can be generalized. Why do you need it? If we believe that not only the first level comment is important when ranking, but, for example, the whole discussion matters, then it is really important to rank the entire thread. If we pay attention to the picture at the beginning of the article, then despite the “very minded” first comment (and I think it's for the cause), quite an interesting discussion has grown around it in the first branch.
Weight and user profile (s)
The exact digg algorithm is not known to the general public, but at least we know what roughly the parameters come in ( source according to the algorithm):
- The number of votes given the time window: a lot of votes for a short period, better than a lot of votes for a long period
- Source of the link (this is specific to digg, news points to a specific site with a source): how often articles from this source get into the top? (get pluses)
- Author profile
- Departure time: if a lot of people at the same time add an article at three in the morning, something might not be right here [controversial parameter, isn't it? - approx. author's]
- The presence of similar links on the digg (duplicates)
- Voting Profiles
- Number of comments
- Number of views
- ....
In general, they have a complicated algorithm. But what can we basically learn from it? You can take different comments and weight of votes to posts depending on various parameters and a sufficient number of these parameters are already known from the algorithms of other resources.
Much the same idea with time, as with an additional parameter: all other things being equal, when ranking comments, we can take into account the user's weight (or even his contribution to a certain hub), so if there are many comments to the article, the “authoritative opinion” rises above the rest will be readable.
Conclusion
Commenting rankings are a popular and often useful element of many resources. Whether this is a question at all is ambiguous, but quite worthy of discussion and possibly experimentation. Is there really a problem with the abundance of comments on certain articles? If not, will it appear in the future? Are any other sorting tools needed?
But it is always worth remembering that for any resource the main thing is not the sorting of comments, but the quality of the content.
Source: https://habr.com/ru/post/209552/
All Articles