The movement of attention based on the continuously accumulated experience of perception, as the basis of the proposed approach to the design of a strong AI
Directional movement of attention - as the main function of consciousness
In this article we will not go into the global problems of strong artificial intelligence, but only demonstrate some of the basics of our approach to its design.
Consider, perhaps, one of the most famous illustrations of how vision works by exploring visual objects.

')
We see that visual attention is moving.
What if the very movement of attention is the key to understanding it?
We hypothesized that consciousness directs the movement of attention, and imagined the following image of the algorithm of conscious visual perception

How could such an algorithm work?
Important Concepts
We have introduced definitions of two concepts for our algorithm: a sign and a generalization.
What is a sign, the easiest way to illustrate the above image of a lady with a cat.
Take an area of the image and calculate its integral characteristics, for example, the size of the area (in the case of a circle, it will be its diameter), average chromaticity, brightness, contrast and fractal dimension.
Now, in a certain direction and at some distance, choose another area of the image and calculate its integral characteristics.
Now we calculate the relative changes in the transition from the first to the second region, in order to get rid of the absolute values and not to depend on changes in scale, rotation, shift, total illumination or tonality of the image. Ordinary affine transformations also allow you to get rid of the change in perspective of the image plane.
We will call such a transition a sign.

Further, by linking such signs in chains, we will receive generalizations of signs.
This is somewhat arbitrary, but the definition of key concepts of the proposed approach.
I want the picture come to life!
Good, but so far there is no directional movement of attention. If we randomly form such chains of transitions, our database will be immense and it will be absolutely impossible to distinguish something useful from the trash in it.
Therefore, we define a few more concepts.
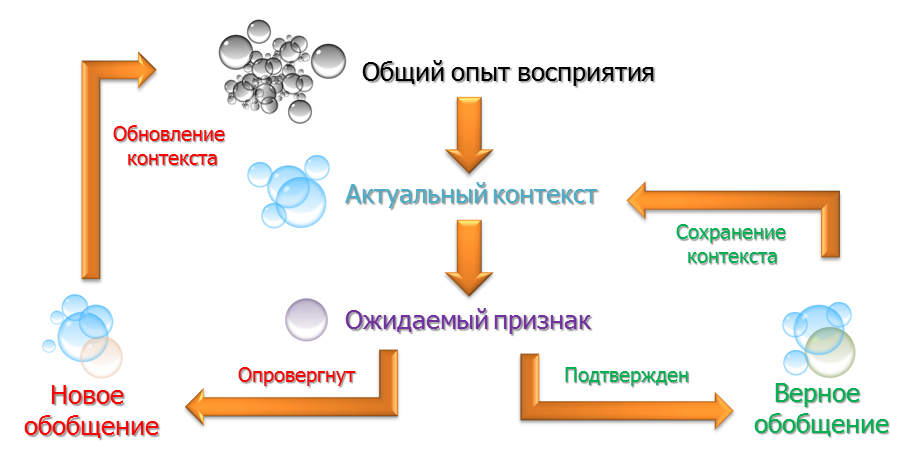
The key concept is experience. The aggregate ranked by significance (frequency of confirmations) generalizations.
At the same time, each time in the vicinity of the current direction of attention, we determine the current context of generalizations - those that would have been confirmed and still not disproved.
This actual context of generalizations is also ranked by the likelihood of the most expected features in the stream.
The central element of the algorithm is the current expected feature, which we can check. The transition from the current area (focus of attention) to the area defined by the expected transition directs the system to the calculation of characteristics in a particular area and comparing them with the expected ones.
If the sign is confirmed, we get the next expected sign from the current context.
If the sign is not confirmed, we form a new generalization and remove from the current context generalizations that have not been confirmed.
What to do if the context is empty or fully confirmed and there are no new expected signs?
We assume that the natural consciousness in this situation explores the environs of what is already known, but still little explored. That is, attention shifts to what regularly turns out to be in a relevant context, but the level of generalization is low (i.e., the chains of generalizations are rather short)
Well, now we come?
It is very early to draw conclusions about the practical usefulness of the proposed approach. Research only at the beginning.
The first experiments showed that the implementation of the algorithm "in the forehead", without any special optimizations, in C #, in one thread on one core generates about 50 thousand generalizations per second, with a million generated generalizations being repeated at least once less than 1%, and more once about 0.2%
Quite a lot of calculations are performed “just in case” and a significant amount of the database is occupied by still unconfirmed generalizations of the shortest chains of two transitions (features).
In the near future, the formation of attractors of system behavior (movement of attention of AI) on training samples, the study of their parameters and publication of results.
Source: https://habr.com/ru/post/209472/
All Articles