Yandex cloud platform. Cocaine
Some time ago we began to talk in some detail about one of the basic cloud technologies of Yandex - Elliptics. Today it is the turn to talk about the other - the one under which the "elves" work and which makes the dream of their cloud a little closer to reality. It's about Cocaine.
Cocaine (Configurable Omnipotent Custom Applications Integrated Network Engine) is an open source PaaS system (Platform-as-a-Service), which is essentially an app engine and allows you to create your own cloud application hosting services - such as Google AppEngine, OpenShift, CloudFoundry or Heroku.

')
Everyone knows that clouds can solve all the infrastructural problems, turn costs into profits and saturate your life with endless joy and happiness for ever and ever. The only obstacle to these goals are, in fact, the clouds. IaaS , PaaS , SaaS ? Whatever-as-a-Service? What kind of mysterious set of letters you need to choose, so that everything finally becomes good?
We spent a lot of time studying these issues, selecting the best, in our opinion, ideas and concepts in order to build such a cloud platform that we would like to immediately install, configure and successfully use.
The history of the birth of this technology is closely connected with Heroku. Long ago, when cloud technologies were not so popular, but Heroku was already, the founder of our project, Andrei Sibiryov, became interested in it.

Heroku at that time was an app engine that supported only Ruby, but the idea itself was revolutionary. Just think: you could write your own rail application, pour it into the cloud and not think at all about infrastructure problems. Need a database? No problem - there are add-ons! Pull the logs? Again, no problem! Also in a magical way solved the problem of load balancing. Is the site young and evolving? Well, he has resources. Is the site already popular? Well, the cloud will help it “swell” under load and survive. In addition, fast deploy through git already from the earliest time taught to join the beautiful.
It sounds cool. In any case, this is how Heroku positioned himself. In reality, everything was, of course, darker.
They had a great idea, there was an implementation, but almost nowhere was it described how it works at all. As you know, if you want to understand something unknown, new, put yourself in the developer’s place. How would you write taking into account the seen buns and flaws? This is how the open-source cloud app engine project was launched. Looking ahead, I will say that, apparently, the same logic guided foreign developers, which gave impetus to the development of several more similar products: OpenShift and CloudFoundry. About them will be discussed a little later.
Cocaine was originally a garage just-for-fun project, but everything changed when Yandex needed some kind of inflatable application platform that could handle the load “maybe 10, or maybe 100,000 RPS” for internal goals. Meanwhile, J. Browser was on the way with the same needs, and it became clear that it was time for the project to get out of the garage.
For the time being, let's leave the story aside and plunge into the world of dry statistics and undeniable statements.
Yandex.Browser - the entire browser backend works via Cocaine. For example, “Smart String”, “Quick Links”, “Favorite Sites”. Yandex internal infrastructure.
Currently, Cocaine can be deployed from packages on the following Linux distributions:
Windows support, unfortunately, is not, and is not planned, but this does not mean that users, for example, C # will not be able to use cloud services that are spinning somewhere else - just write a suitable framework (what it will be described later) .
Cocaine sources can be compiled on almost any * nix system that has boost 1.46+ and a compiler with C ++ 11 support for the GCC 4.4 level standard (that is, virtually none).
As a bonus, Cocaine is successfully built from source on Mac OS X. Support for the Docker technology (to be discussed later) requires a Linux kernel not younger than 3.8.
Let's take a closer look at how Cocaine differs from its main competitors.
Let's start with Heroku.
Heroku, first of all, is not an open-source technology with its price policy, which may scare some customers. But due to explicit monetization, Heroku has more developed support, there is good (now) documentation with pictures. The most convenient application deployment system based on git, from the very beginning, forces to clean up the code and makes it possible to roll back in the case of a fakap.
A bunch of addons allows you to easily meet the needs of your applications in various databases, caching, queues, synchronization, logging and much more.
Applications themselves at startup are completely isolated from each other in processes called dyno, which are distributed over a special dyno grid, which consists of several servers. Dyno are started as needed depending on the load and are killed in the absence of one - in this way load balancing and fault tolerance are performed in Heroku.
Despite the initial support of Ruby alone, Heroku now provides the ability to write applications in languages such as Java, Closure, Node.js, Scala, Python, and (suddenly) PHP.
The development of CloudFoundry and OpenShift began almost simultaneously with Cocaine. Both are open-source projects with strong support from large companies - VMware and RedHat, respectively. CloudFoundry at the moment has already experienced one rebirth. However, language support is limited to Java, Scala, Groovy, Ruby, and JavaScript.
With OpenShift, this is better — Python is supported in addition, Perl has the ability to support the required languages yourself. Unfortunately, applications can communicate with each other only via http, which somewhat limits the scope of the Cloud.
Cocaine at the same time compares favorably with them:
Now let's take a look at how our cloud actually works by discussing at the same time the reasons that influenced the choice of a particular decision.
We postulate the following indisputable statement: clouds are designed to solve infrastructure problems.
One of these tasks is to provide fault tolerance. Hardly anyone would be greatly impressed by the cloud platform that runs on only one machine. In this case, the cloud dies with the machine. A Cocaine cloud consists of one or more independent machines on which the “cocaine-runtime” server is installed. In fact, this is all that is needed for minimal platform operation.

We decided not to go through CloudFoundry and start a separate program for each logical part of the cloud. For example, the fact that in other clouds is called HealthManager - control of the life of running applications - we have merged into a single entity. Such a solution, on the one hand, simplifies node administration and reduces the number of points of failure, but on the other hand, if cocaine-runtime “falls”, then the whole node drops out of the list for a while. But the test of time and loads showed that the choice of such a decision was successful.
Imagine you have a dozen machines, each of which runs cocaine-runtime. But these cars do not know anything about each other. When considering the options for choosing a cloud topology design scheme, two options were considered: everyone knows about all and several knows about all. In the first case, the identity of all the nodes would be guaranteed: if a node dies, nothing significant will change. But at the same time there is a mixture of logic, since here essentially two entities are involved: the first is aggregation of nodes and their management; the second is managing your site. In the second case, the logic of cocaine-runtime aggregating nodes from the rest is completely separated, but this node would need to be configured in a special way. In the end, the second option was chosen.
Users do not know anything about the location of the services or applications to which they are accessing - only the address of the aggregating node and the name of the application are known. Noda chooses the optimal machine for the request, on which it is executed.
The cloud app engine would not be called this if it were not able to run applications. Actually, cocaine-runtime is just the same as running. The only requirement is that the file is executable. Another thing is that this application will be killed almost immediately, because will not be able to respond to a simple handshake message and, in principle, there are no general means to control the application from the outside. If it works, it does not mean that it is not stuck, for example. And here we come close to the topic of monitoring the life of applications (or workers).
A running application must be somehow controlled. In fact, the bare minimum is needed: the application must from time to time notify the server that it is alive by heartbeat commands and die nicely when terminate the command. If the application does not respond for too long, then it is considered dead and SIGKILL is sent to it to finish it off. In other words, the worker must implement a special, uncomplicated protocol . For ease of application development, adapters have been made for various languages, which we call frameworks .
Frames are a special API that implements the most native for a particular language method of communication with the cloud. For example, the implementation of an internal protocol is hidden under the framework, which makes it very easy to make a cloud service call and work with it. Also implemented tools to simplify the work with asynchronous calls. At the moment, support has already been implemented:
There are tools to manage all this cloud wealth through both the console interface and the web . Their implementation is very similar in many respects to similar tools of Heroku or CloudFoundry - applications can be deployed, started, stopped, managed and configured, as well as collecting statistics and watching logs. It’s really hard to come up with something new, although Amazon EC2 tools are an example for us in terms of simplicity and convenience, we are striving for it.
Let's take a step back and look down on the cloud infrastructure. What is a cloud? Usually there are several machines that provide resources. These machines are connected in some way into a single entity by some control element. The shared resources provided are used to organize various services and user applications. Nothing like?
There is a category of software that includes programs that manage the infrastructure of a single (usually) computer and provide its resources to the user. They have a clear division into modules, there is a controlling entity, there is a user space. It is, of course, about operating systems . We thought, why not do something similar, but in the case of cloud infrastructure?
That is how Cocaine is built.
At the center of everything is the core, which includes the main hierarchies of services , drivers, and APIs . The service is essentially a kind of library written in C ++ that connects to the kernel, which provides the Cloud with some service. Services run simultaneously with cocaine-runtime and live in a separate thread in a single copy all the time it is running.
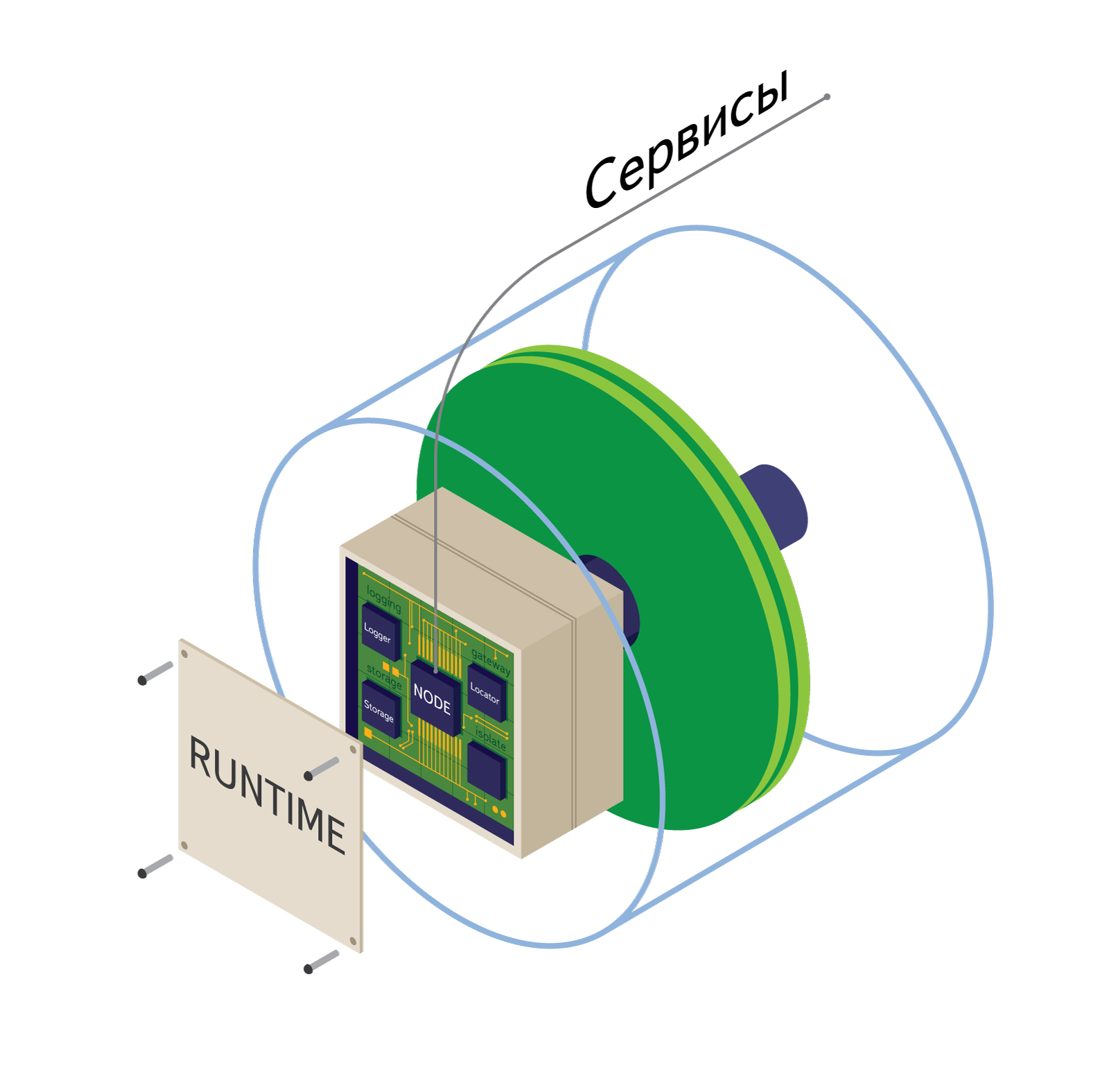
The main service is the Node service, which allows you to control the start, stop and operation of applications . Initially launched application does not have workers - instances of this application - they will begin to spawn at the time of submission and increase the load on the application.
Each application has an Engine that deals with dispatching a message queue between workers and clients, managing and balancing the number of these workers .
The Locator service allows you to connect independent nodes into a single cluster, as well as to search for the application or service requested by the client in the Cloud. For example, if some application requests the Logger service, then it is the Locator that decides which endpoint to give to it. Along with endpoint, a dispatch table for service methods is also given. Speaking of it: unlike the CORBA or Thrift RPC mechanism, we decided to get rid of the mandatory interface description (IDL) of services (and applications). Instead, we load the table of methods for each rezolving, and then the frameworks implement the native way of working with it for each language. All that is needed for this is only the name of the requested service and, possibly, the version.
Did we win from this? Definitely yes! By removing the need to define IDL for each application, we have seriously facilitated their development for dynamic languages such as Ruby or Python. If an application has an API changed, there is no need to rewrite stubs for all frameworks - in the case of dynamically typed languages, methods are generally created dynamically.
It is unlikely that there is at least one cloud without logging tools - we have implemented it as a Logger service, which is a single point of log transport from the entire node.
Finally, the Storage service is an abstract interface for storing anything — for example, the applications themselves, manifests, profiles, and other information required by the applications themselves.
The services architecture is open for expansion and is similar to linux kernel modules. You can write your own services, as well as expand the existing hierarchy.

Stand alone are the drivers , the purpose of which is to generate events processed by the cloud. For example, such an event may be a change in a file or directory, a timeout or other event. It is possible (as an option) to write a driver to the ADC, which will reset the signals for processing as they arrive.
Unlike many similar PaaS, in which applications and services can communicate with each other only via HTTP, Cocaine communicates via the RPC mechanism over a binary HTTP / 2.0-like protocol. This enables us, for example, to interact between different applications directly, using the tools provided by the frameworks. Read more about this here . Of course, the HTTP interface itself has not gone anywhere. For each framework, native tools are provided that simplify the development of HTTP applications. For example, in the case of Python, there are flask-like decorators.
Outside, applications can also be reached not only via the HTTP interface (although this option is provided), but, for example, through ZeroMQ or its own extensions.
Let's take a closer look at how the distribution of the Cloud is actually implemented and how it tries to live under load.
When starting a cluster, individual nodes (machines running cocaine-runtime) learn about each other using the internal Locator service, which registers each machine in a multicast group, thereby organizing communication between all nodes and a separate node configured under Metalocator , which is the entry point for clouds and performing basic load balancing. If a new application appears on a separate machine or an existing one multiplies, the metalocator will immediately find out about it and direct the load to it.
Cloud using the above Engine also monitors the message queue and load control. As the load on the application increases, the platform will automatically launch the required number of instances of this application, guided by its internal ideas about the load on the nodes and the availability of slots on various machines. In this situation, slots are understood to be some kind of unified machine resource.
The system of spawning and isolating applications is rendered into a separate entity called Isolate . In the standard configuration, the cloud will launch new application instances using normal processes. If Docker support is installed as a plug-in, the cloud will launch new applications in a separate isolated container.
Docker is an open-source technology that provides a simple and efficient way to create lightweight, portable, and self-contained containers from any application. Once created, such a container will work equally well in almost any environment, from developer and tester notebooks to clusters of thousands of servers. This, for example, allows you to isolate applications along with their binary dependencies and no longer think that your application will start behaving differently in the cloud due to other versions of libraries, or will not rise at all.
Docker technology is based on the usual Linux Containers (LXC), which provide the ability to run an application in an isolated environment through the use of namespaces and cgroups. Unlike environments with full virtualization, such as Xen or KVM, containers use a common core and do not provide the ability to emulate devices, but their use does not entail additional overhead and they run almost instantly. In addition to containerization itself, Docker provides tools that simplify network configuration, distribution and deployment of application images. One such tool is the creation of images of applications from several independent layers.
When developing applications for Cocaine that involve binary dependencies (for example, C ++ or Python applications), Docker technology can be very useful for isolating these binary dependencies.
Imagine that you created an application, uploaded it to a server, set it up and left it to fend for yourself. After a week, you decide to check how it works and find out with sadness that the application crashed a long time ago for completely different reasons:
These effects are known as “ Software erosion ”.
Cocaine is an erosion-resistant technology. The system of isolation saves you from spontaneous updates of libraries and OS. In the event of an application crashing or freezing, it will be automatically restarted by the cloud itself, or rather, by a system called in other cloud platforms as a health manager . Problems with the iron itself are leveled by the cloudiness itself.
About plugins and services have already been briefly discussed earlier in the context of the platform core. Plugins are extensible architecture modules. For example, Docker support is implemented using a plugin. They are divided into:
With the help of plug-ins, you can change the implementation of the above parts of the system, making only a change in the configuration file. Want to replace logging systems with Syslog with Logstash ? Well, we change three lines in the config, while the code remains the same. Maybe the default balancing system is not comfortable and you want IPVS? Easily! Well, what if there are not enough pre-installed plug-ins and you want to implement something new? Well, it is completely easy to write them, and we will be very pleased with the pool of requests.
The latest item in the plugins are services. If strictly, then services are abstract frontends to different parts of the infrastructure.
For example, the UrlFetch service allows applications to make http requests and organize control over these requests, because in the general case applications are not allowed to go outside the container for security reasons.
With the help of the Logstash plugin, you can configure the aggregation of logs from the entire cluster, their unified processing, indexing and storage in the same Elasticsearch followed by a convenient display in Kibana (which we do in Yandex).
Using the Elliptics plugin, you can store all the information in our system of the same name. Alternatively, the MongoDB plugin and Elasticsearch service are implemented, which allow using this technology as an information storage system.
This introductory article begins a series of articles on Cocaine's cloud platform. In the future, the platform architecture, its advantages and disadvantages will be discussed in more detail (so far without them?).
We will show you how to deploy your own cloud from source or packages and how to configure it. This is followed by a description of the frameworks with examples of real-world applications written with their help. A description of the already written plugins and services will follow, and an example of writing your own plug-in or service (or both) will be considered. In conclusion, we will take a closer look at the Cocaine protocol and how you can add support for another language, that is, write your own framework.
We are developing on github. All the latest information is available here . In the Wiki section there is documentation on how to quickly assemble Cocaine from source, there is a description of internal details. If you are interested in the platform, you can try it in practice through a ready-made vagrant image. If you have questions, ask.
Cocaine (Configurable Omnipotent Custom Applications Integrated Network Engine) is an open source PaaS system (Platform-as-a-Service), which is essentially an app engine and allows you to create your own cloud application hosting services - such as Google AppEngine, OpenShift, CloudFoundry or Heroku.
')
Everyone knows that clouds can solve all the infrastructural problems, turn costs into profits and saturate your life with endless joy and happiness for ever and ever. The only obstacle to these goals are, in fact, the clouds. IaaS , PaaS , SaaS ? Whatever-as-a-Service? What kind of mysterious set of letters you need to choose, so that everything finally becomes good?
We spent a lot of time studying these issues, selecting the best, in our opinion, ideas and concepts in order to build such a cloud platform that we would like to immediately install, configure and successfully use.
Story
The history of the birth of this technology is closely connected with Heroku. Long ago, when cloud technologies were not so popular, but Heroku was already, the founder of our project, Andrei Sibiryov, became interested in it.
Heroku at that time was an app engine that supported only Ruby, but the idea itself was revolutionary. Just think: you could write your own rail application, pour it into the cloud and not think at all about infrastructure problems. Need a database? No problem - there are add-ons! Pull the logs? Again, no problem! Also in a magical way solved the problem of load balancing. Is the site young and evolving? Well, he has resources. Is the site already popular? Well, the cloud will help it “swell” under load and survive. In addition, fast deploy through git already from the earliest time taught to join the beautiful.
It sounds cool. In any case, this is how Heroku positioned himself. In reality, everything was, of course, darker.
They had a great idea, there was an implementation, but almost nowhere was it described how it works at all. As you know, if you want to understand something unknown, new, put yourself in the developer’s place. How would you write taking into account the seen buns and flaws? This is how the open-source cloud app engine project was launched. Looking ahead, I will say that, apparently, the same logic guided foreign developers, which gave impetus to the development of several more similar products: OpenShift and CloudFoundry. About them will be discussed a little later.
Cocaine was originally a garage just-for-fun project, but everything changed when Yandex needed some kind of inflatable application platform that could handle the load “maybe 10, or maybe 100,000 RPS” for internal goals. Meanwhile, J. Browser was on the way with the same needs, and it became clear that it was time for the project to get out of the garage.
For the time being, let's leave the story aside and plunge into the world of dry statistics and undeniable statements.
Where Yandex uses Cocaine
Yandex.Browser - the entire browser backend works via Cocaine. For example, “Smart String”, “Quick Links”, “Favorite Sites”. Yandex internal infrastructure.
Supported Platforms
Currently, Cocaine can be deployed from packages on the following Linux distributions:
- Ubuntu 12.04 (Precise Pangolin) and older
- RHEL 6 and derivatives.
Windows support, unfortunately, is not, and is not planned, but this does not mean that users, for example, C # will not be able to use cloud services that are spinning somewhere else - just write a suitable framework (what it will be described later) .
Cocaine sources can be compiled on almost any * nix system that has boost 1.46+ and a compiler with C ++ 11 support for the GCC 4.4 level standard (that is, virtually none).
As a bonus, Cocaine is successfully built from source on Mac OS X. Support for the Docker technology (to be discussed later) requires a Linux kernel not younger than 3.8.
Why so Cocainy?
Let's take a closer look at how Cocaine differs from its main competitors.
Let's start with Heroku.
Heroku, first of all, is not an open-source technology with its price policy, which may scare some customers. But due to explicit monetization, Heroku has more developed support, there is good (now) documentation with pictures. The most convenient application deployment system based on git, from the very beginning, forces to clean up the code and makes it possible to roll back in the case of a fakap.
A bunch of addons allows you to easily meet the needs of your applications in various databases, caching, queues, synchronization, logging and much more.
Applications themselves at startup are completely isolated from each other in processes called dyno, which are distributed over a special dyno grid, which consists of several servers. Dyno are started as needed depending on the load and are killed in the absence of one - in this way load balancing and fault tolerance are performed in Heroku.
Despite the initial support of Ruby alone, Heroku now provides the ability to write applications in languages such as Java, Closure, Node.js, Scala, Python, and (suddenly) PHP.
The development of CloudFoundry and OpenShift began almost simultaneously with Cocaine. Both are open-source projects with strong support from large companies - VMware and RedHat, respectively. CloudFoundry at the moment has already experienced one rebirth. However, language support is limited to Java, Scala, Groovy, Ruby, and JavaScript.
With OpenShift, this is better — Python is supported in addition, Perl has the ability to support the required languages yourself. Unfortunately, applications can communicate with each other only via http, which somewhat limits the scope of the Cloud.
Cocaine at the same time compares favorably with them:
- the presence of adapters to different languages (frameworks), which greatly simplifies working with the Cloud;
- the ability of applications to communicate with each other not only via http, which, for example, makes it possible to build their own cloud computing platform;
- Strong support for application isolation - Docker technology, except for us, officially supports only OpenShift.
Short working principle
Now let's take a look at how our cloud actually works by discussing at the same time the reasons that influenced the choice of a particular decision.
We postulate the following indisputable statement: clouds are designed to solve infrastructure problems.
One of these tasks is to provide fault tolerance. Hardly anyone would be greatly impressed by the cloud platform that runs on only one machine. In this case, the cloud dies with the machine. A Cocaine cloud consists of one or more independent machines on which the “cocaine-runtime” server is installed. In fact, this is all that is needed for minimal platform operation.
We decided not to go through CloudFoundry and start a separate program for each logical part of the cloud. For example, the fact that in other clouds is called HealthManager - control of the life of running applications - we have merged into a single entity. Such a solution, on the one hand, simplifies node administration and reduces the number of points of failure, but on the other hand, if cocaine-runtime “falls”, then the whole node drops out of the list for a while. But the test of time and loads showed that the choice of such a decision was successful.
Imagine you have a dozen machines, each of which runs cocaine-runtime. But these cars do not know anything about each other. When considering the options for choosing a cloud topology design scheme, two options were considered: everyone knows about all and several knows about all. In the first case, the identity of all the nodes would be guaranteed: if a node dies, nothing significant will change. But at the same time there is a mixture of logic, since here essentially two entities are involved: the first is aggregation of nodes and their management; the second is managing your site. In the second case, the logic of cocaine-runtime aggregating nodes from the rest is completely separated, but this node would need to be configured in a special way. In the end, the second option was chosen.
Users do not know anything about the location of the services or applications to which they are accessing - only the address of the aggregating node and the name of the application are known. Noda chooses the optimal machine for the request, on which it is executed.
The cloud app engine would not be called this if it were not able to run applications. Actually, cocaine-runtime is just the same as running. The only requirement is that the file is executable. Another thing is that this application will be killed almost immediately, because will not be able to respond to a simple handshake message and, in principle, there are no general means to control the application from the outside. If it works, it does not mean that it is not stuck, for example. And here we come close to the topic of monitoring the life of applications (or workers).
A running application must be somehow controlled. In fact, the bare minimum is needed: the application must from time to time notify the server that it is alive by heartbeat commands and die nicely when terminate the command. If the application does not respond for too long, then it is considered dead and SIGKILL is sent to it to finish it off. In other words, the worker must implement a special, uncomplicated protocol . For ease of application development, adapters have been made for various languages, which we call frameworks .
Five minutes of history
Frames are a special API that implements the most native for a particular language method of communication with the cloud. For example, the implementation of an internal protocol is hidden under the framework, which makes it very easy to make a cloud service call and work with it. Also implemented tools to simplify the work with asynchronous calls. At the moment, support has already been implemented:
- C ++
- Java
- Python
- Ruby
- Node.js
- Go
There are tools to manage all this cloud wealth through both the console interface and the web . Their implementation is very similar in many respects to similar tools of Heroku or CloudFoundry - applications can be deployed, started, stopped, managed and configured, as well as collecting statistics and watching logs. It’s really hard to come up with something new, although Amazon EC2 tools are an example for us in terms of simplicity and convenience, we are striving for it.
Architecture
Let's take a step back and look down on the cloud infrastructure. What is a cloud? Usually there are several machines that provide resources. These machines are connected in some way into a single entity by some control element. The shared resources provided are used to organize various services and user applications. Nothing like?
There is a category of software that includes programs that manage the infrastructure of a single (usually) computer and provide its resources to the user. They have a clear division into modules, there is a controlling entity, there is a user space. It is, of course, about operating systems . We thought, why not do something similar, but in the case of cloud infrastructure?
That is how Cocaine is built.
At the center of everything is the core, which includes the main hierarchies of services , drivers, and APIs . The service is essentially a kind of library written in C ++ that connects to the kernel, which provides the Cloud with some service. Services run simultaneously with cocaine-runtime and live in a separate thread in a single copy all the time it is running.
The main service is the Node service, which allows you to control the start, stop and operation of applications . Initially launched application does not have workers - instances of this application - they will begin to spawn at the time of submission and increase the load on the application.
Each application has an Engine that deals with dispatching a message queue between workers and clients, managing and balancing the number of these workers .
The Locator service allows you to connect independent nodes into a single cluster, as well as to search for the application or service requested by the client in the Cloud. For example, if some application requests the Logger service, then it is the Locator that decides which endpoint to give to it. Along with endpoint, a dispatch table for service methods is also given. Speaking of it: unlike the CORBA or Thrift RPC mechanism, we decided to get rid of the mandatory interface description (IDL) of services (and applications). Instead, we load the table of methods for each rezolving, and then the frameworks implement the native way of working with it for each language. All that is needed for this is only the name of the requested service and, possibly, the version.
Did we win from this? Definitely yes! By removing the need to define IDL for each application, we have seriously facilitated their development for dynamic languages such as Ruby or Python. If an application has an API changed, there is no need to rewrite stubs for all frameworks - in the case of dynamically typed languages, methods are generally created dynamically.
We continue about services
It is unlikely that there is at least one cloud without logging tools - we have implemented it as a Logger service, which is a single point of log transport from the entire node.
Finally, the Storage service is an abstract interface for storing anything — for example, the applications themselves, manifests, profiles, and other information required by the applications themselves.
The services architecture is open for expansion and is similar to linux kernel modules. You can write your own services, as well as expand the existing hierarchy.
Stand alone are the drivers , the purpose of which is to generate events processed by the cloud. For example, such an event may be a change in a file or directory, a timeout or other event. It is possible (as an option) to write a driver to the ADC, which will reset the signals for processing as they arrive.
Unlike many similar PaaS, in which applications and services can communicate with each other only via HTTP, Cocaine communicates via the RPC mechanism over a binary HTTP / 2.0-like protocol. This enables us, for example, to interact between different applications directly, using the tools provided by the frameworks. Read more about this here . Of course, the HTTP interface itself has not gone anywhere. For each framework, native tools are provided that simplify the development of HTTP applications. For example, in the case of Python, there are flask-like decorators.
Outside, applications can also be reached not only via the HTTP interface (although this option is provided), but, for example, through ZeroMQ or its own extensions.
Scaling and isolation
Let's take a closer look at how the distribution of the Cloud is actually implemented and how it tries to live under load.
When starting a cluster, individual nodes (machines running cocaine-runtime) learn about each other using the internal Locator service, which registers each machine in a multicast group, thereby organizing communication between all nodes and a separate node configured under Metalocator , which is the entry point for clouds and performing basic load balancing. If a new application appears on a separate machine or an existing one multiplies, the metalocator will immediately find out about it and direct the load to it.
Cloud using the above Engine also monitors the message queue and load control. As the load on the application increases, the platform will automatically launch the required number of instances of this application, guided by its internal ideas about the load on the nodes and the availability of slots on various machines. In this situation, slots are understood to be some kind of unified machine resource.
The system of spawning and isolating applications is rendered into a separate entity called Isolate . In the standard configuration, the cloud will launch new application instances using normal processes. If Docker support is installed as a plug-in, the cloud will launch new applications in a separate isolated container.
Insulation? Easy!
Docker is an open-source technology that provides a simple and efficient way to create lightweight, portable, and self-contained containers from any application. Once created, such a container will work equally well in almost any environment, from developer and tester notebooks to clusters of thousands of servers. This, for example, allows you to isolate applications along with their binary dependencies and no longer think that your application will start behaving differently in the cloud due to other versions of libraries, or will not rise at all.
Docker technology is based on the usual Linux Containers (LXC), which provide the ability to run an application in an isolated environment through the use of namespaces and cgroups. Unlike environments with full virtualization, such as Xen or KVM, containers use a common core and do not provide the ability to emulate devices, but their use does not entail additional overhead and they run almost instantly. In addition to containerization itself, Docker provides tools that simplify network configuration, distribution and deployment of application images. One such tool is the creation of images of applications from several independent layers.
When developing applications for Cocaine that involve binary dependencies (for example, C ++ or Python applications), Docker technology can be very useful for isolating these binary dependencies.
Erosion resistance
Imagine that you created an application, uploaded it to a server, set it up and left it to fend for yourself. After a week, you decide to check how it works and find out with sadness that the application crashed a long time ago for completely different reasons:
- spontaneous updates of the operating system or dependent libraries;
- disk overflow logs;
- hang or fall of the application itself;
- problems with the server hardware itself.
These effects are known as “ Software erosion ”.
Cocaine is an erosion-resistant technology. The system of isolation saves you from spontaneous updates of libraries and OS. In the event of an application crashing or freezing, it will be automatically restarted by the cloud itself, or rather, by a system called in other cloud platforms as a health manager . Problems with the iron itself are leveled by the cloudiness itself.
Plugins and services
About plugins and services have already been briefly discussed earlier in the context of the platform core. Plugins are extensible architecture modules. For example, Docker support is implemented using a plugin. They are divided into:
- Isolate - application isolation system
- Driver - system for generating external events for applications
- Storage - storage system.
- Logging is a logging system.
- Gateway - balancing system
- Services - other custom services
With the help of plug-ins, you can change the implementation of the above parts of the system, making only a change in the configuration file. Want to replace logging systems with Syslog with Logstash ? Well, we change three lines in the config, while the code remains the same. Maybe the default balancing system is not comfortable and you want IPVS? Easily! Well, what if there are not enough pre-installed plug-ins and you want to implement something new? Well, it is completely easy to write them, and we will be very pleased with the pool of requests.
The latest item in the plugins are services. If strictly, then services are abstract frontends to different parts of the infrastructure.
For example, the UrlFetch service allows applications to make http requests and organize control over these requests, because in the general case applications are not allowed to go outside the container for security reasons.
With the help of the Logstash plugin, you can configure the aggregation of logs from the entire cluster, their unified processing, indexing and storage in the same Elasticsearch followed by a convenient display in Kibana (which we do in Yandex).
Using the Elliptics plugin, you can store all the information in our system of the same name. Alternatively, the MongoDB plugin and Elasticsearch service are implemented, which allow using this technology as an information storage system.
Conclusion
This introductory article begins a series of articles on Cocaine's cloud platform. In the future, the platform architecture, its advantages and disadvantages will be discussed in more detail (so far without them?).
We will show you how to deploy your own cloud from source or packages and how to configure it. This is followed by a description of the frameworks with examples of real-world applications written with their help. A description of the already written plugins and services will follow, and an example of writing your own plug-in or service (or both) will be considered. In conclusion, we will take a closer look at the Cocaine protocol and how you can add support for another language, that is, write your own framework.
We are developing on github. All the latest information is available here . In the Wiki section there is documentation on how to quickly assemble Cocaine from source, there is a description of internal details. If you are interested in the platform, you can try it in practice through a ready-made vagrant image. If you have questions, ask.
Source: https://habr.com/ru/post/209324/
All Articles