Code Reuse in Go with an Example
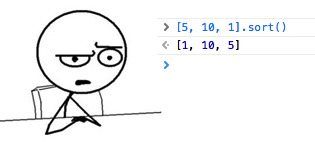 “I'll go look for a ready-made solution on Google”
“I'll go look for a ready-made solution on Google”In the process of working on any software product, the developer may face the problem of borrowing someone else's code. It happens all the time. Every year, along with the development of social networks for developers, the process becomes more and more natural and smooth. Forgot, how to get all the words out of the file? No problem, go to Stack Overflow and get a ready-made snippet. For particularly advanced cases, there is even a plug-in for Sublime Text, which, according to the hotkey, searches for the selected text in SO and inserts a piece of code from the received answer directly into the editor. This approach leads to a number of problems ...
Although the example above is an extreme, as well as a reason for a good joke, there really is a problem. The image to attract attention shows the result of sorting a float64 array using JavaScript. I don’t want to think why it is sorted precisely as an array of strings; let's leave this question to JavaScript fans. I needed a human sorting in a project on Go, so just like the hero above, my path went through Google.
Disclaimer: A post dedicated to the culture of development and clearly demonstrates some of the benefits of the approach with Go. If you are negative about biased views, you should not read further.
')
Unexpected trip
The first link for the query "human sort strings" came across an article from 2007 written by @CodingHorror (Jeff Atwood). Man dear, does not advise the bad. These links still remain relevant, for example, here is a whole bunch of implementations for any language.
Jeff's favorite for Python looks like this:
import re def sort_nicely( l ): """ Sort the given list in the way that humans expect. """ convert = lambda text: int(text) if text.isdigit() else text alphanum_key = lambda key: [ convert(c) for c in re.split('([0-9]+)', key) ] l.sort( key=alphanum_key ) Okay, what to do about it? How do people usually act? There are simply no options - you take and copy this piece of code into your project, directly in place. 10 projects - 10 places. Slightly more rational people bring to the file library various utility rooms, each with its own library.
Every next developer dealing with your code stumbles over this site because:
- "The way that humans expect" , - and how do they expect?
- How does sorting by
alphanum_keywork at all? Need to think... - (after 2 hours of experiments and reading the documentation) Damn, but after all on
['01', '001', '01', '001']nifiga does not work, because by the specification ofsortis stable and thekeyof these pieces is the same; - What about performance? And if 10,000 elements and for each
re.split;
- Stop, but I generally write on Go, I do not need your one-liners, anyway the algorithm is not working.
C # code also used RegExp, C ++ code generally used uranium bears and MFC (comments indicate that this is a modified MFC version of another version that was ported from a Perl script to C ++). I’m sure many people who read this will not have a single story about how they rummaged through the “trash cans” with code snippets for different languages, copied the solutions, understood the authors ’imagination, caught mistakes ...
“Go on a trip to the nearest hospital. Usually in the neighborhood of any of them there is an unforgettable landfill, where you can find anything. Your praymari obzhktiv - used syringes. Quickly enter all their contents into your body and wait for the effect. ” - Method number 2, Danya Shepovalov.
Go approach
For a couple of hours, the function on Go was successfully implemented. Then I drove tests, benchmarks, rewrote the function again.
Final version
(in fact, it is no longer final, the haborrower mayorovp in the comments suggested an even more optimal way of comparing numeric fields and I implemented it , new test cases were added) . // StringLess compares two alphanumeric strings correctly. func StringLess(s1, s2 string) (less bool) { // uint64 = max 19 digits n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18) for i, j := 0, 0; i < len(s1) || j < len(s2); { var r1, r2 rune var w1, w2 int var d1, d2 bool // read rune from former string available if i < len(s1) { r1, w1 = utf8.DecodeRuneInString(s1[i:]) i += w1 // if digit, accumulate if d1 = ('0' <= r1 && r1 <= '9'); d1 { n1 = append(n1, r1) } } // read rune from latter string if available if j < len(s2) { r2, w2 = utf8.DecodeRuneInString(s2[j:]) j += w2 // if digit, accumulate if d2 = ('0' <= r2 && r2 <= '9'); d2 { n2 = append(n2, r2) } } // if have rune and other non-digit rune if (!d1 || !d2) && r1 > 0 && r2 > 0 { // and accumulators have digits if len(n1) > 0 && len(n2) > 0 { // make numbers from digit group in1 := digitsToNum(n1) in2 := digitsToNum(n2) // and compare if in1 != in2 { return in1 < in2 } // if equal, empty accumulators and continue n1, n2 = n1[0:0], n2[0:0] } // detect if non-digit rune from former or latter if r1 != r2 { return r1 < r2 } } } // if reached end of both strings and accumulators // have some digits if len(n1) > 0 || len(n2) > 0 { in1 := digitsToNum(n1) in2 := digitsToNum(n2) if in1 != in2 { return in1 < in2 } } // last hope return len(s1) < len(s2) } // Convert a set of runes (digits 0-9) to uint64 number func digitsToNum(d []rune) (n uint64) { if l := len(d); l > 0 { n += uint64(d[l-1] - 48) k := uint64(l - 1) for _, r := range d[:l-1] { n, k = n+uint64(r-48)*uint64(math.Pow10(k)), k-1 } } return } This code uses only the package
"unicode/utf8" to iterate over the bytes in the string, taking into account the width of characters (in Go they are called runes). So, in the cycle we iterate the runes in two lines (if they still remain there), until we reach the ends of both lines. Along the way, we check every rune we read to hit the digital ASCII range ('0' ≤ R ≤ '9') and if we hit it, we accumulate it in the runes buffer. For each line s1, s2 there is its own rune r1, r2 and its own buffers n1, n2 . The rune width w1, w2 is used only for brute force.If at the time of the search, it turned out that one of the runes is not a digit, then both existing digit buffers are converted into two uint64 numbers in1, in2 and compared. Immediately, I note that the self-made function
digitsToNum works more efficiently strconv.ParseUint in this case. If the numbers in the buffer are the same, then the current runes are compared (obviously, '0' <'a', but here it is important for us to make sure that r1! = R2 , for example, if 'a' and 'a').As soon as we’ve reached the end of both lines (which means the lines are conditionally equal) and by this time something appeared in the number buffers, we compare the resulting numbers (for example, at the ends of the lines “hello123” and “hello124”). If this time the lines are conditionally the same, then we apply the last technique - we return the result of a banal length comparison, just like that "a001" < "a00001".
Testing
"The tests and the code work together to achieve better code."
I placed the main code in the strings.go file, so we put the tests in the strings_test.go file.
The first test will be for the
StringLess function: func TestStringLess(t *testing.T) { // // table driven test testset := []struct { s1, s2 string // less bool // }{ {"aa", "ab", true}, {"ab", "abc", true}, {"abc", "ad", true}, {"ab1", "ab2", true}, {"ab1c", "ab1c", false}, {"ab12", "abc", true}, {"ab2a", "ab10", true}, {"a0001", "a0000001", true}, {"a10", "abcdefgh2", true}, {"2", "10", true}, {"2", "3", true}, {"a01b001", "a001b01", true}, {"082", "83", true}, } for _, v := range test set { if res := StringLess(v.s1, v.s2); res != v.less { t.Errorf("Compared %s to %s: expected %v, got %v", v.s1, v.s2, v.less, res) } } } The second test will check the correctness of the array sorting, just in case, it will cover the
Len , Swap , Less functions of the implementation of the interface sort.Interface .TestStringSort
func TestStringSort(t *testing.T) { a := []string{ "abc1", "abc2", "abc5", "abc10", } b := []string{ "abc5", "abc1", "abc10", "abc2", } sort.Sort(Strings(b)) if !reflect.DeepEqual(a, b) { t.Errorf("Error: sort failed, expected: %v, got: %v", a, b) } } Half an hour later our snippet is covered with tests.
Now anyone who is going to use it will be able to verify himself personally:
$ go test -v -cover === RUN TestStringSort --- PASS: TestStringSort (0.00 seconds) === RUN TestStringLess --- PASS: TestStringLess (0.00 seconds) PASS coverage: 100.0% of statements ok github.com/Xlab/handysort 0.019s However, simple unit testing is not enough when there is a desire to show that the solution is quite effective. First of all, this is useful for myself, because after benchmarks I sped up the code several times. For example, I refused an alternative version using
regexp - although it took 6 lines, the loss according to the benchmark results was enormous. Using strconv and unicode.IsDigit not good for performance. A simple benchmark using Go tools in the same strings_test.go file: func BenchmarkStringSort(b *testing.B) { // 1000 10000 : // * 3-8 ; // * 1-3 ; // * . // 300 random seed, // ; // func testSet . set := testSet(300) // [][]string b.ResetTimer() // // bN for i := 0; i < bN; i++ { // sort.Strings(set[bN%1000]) } } func BenchmarkHandyStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { // sort.Sort(handysort.Strings(set[bN%1000])) } } Full version of the file with two tests and two benchmarks:
strings_test.go
package handysort import ( "math/rand" "reflect" "sort" "strconv" "testing" ) func TestStringSort(t *testing.T) { a := []string{ "abc1", "abc2", "abc5", "abc10", } b := []string{ "abc5", "abc1", "abc10", "abc2", } sort.Sort(Strings(b)) if !reflect.DeepEqual(a, b) { t.Errorf("Error: sort failed, expected: %v, got: %v", a, b) } } func TestStringLess(t *testing.T) { testset := []struct { s1, s2 string less bool }{ {"aa", "ab", true}, {"ab", "abc", true}, {"abc", "ad", true}, {"ab1", "ab2", true}, {"ab1c", "ab1c", false}, {"ab12", "abc", true}, {"ab2a", "ab10", true}, {"a0001", "a0000001", true}, {"a10", "abcdefgh2", true}, {"2", "10", true}, {"2", "3", true}, } for _, v := range testset { if res := StringLess(v.s1, v.s2); res != v.less { t.Errorf("Compared %s to %s: expected %v, got %v", v.s1, v.s2, v.less, res) } } } func BenchmarkStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { sort.Strings(set[bN%1000]) } } func BenchmarkHandyStringSort(b *testing.B) { set := testSet(300) b.ResetTimer() for i := 0; i < bN; i++ { sort.Sort(Strings(set[bN%1000])) } } // Get 1000 arrays of 10000-string-arrays. func testSet(seed int) [][]string { gen := &generator{ src: rand.New(rand.NewSource( int64(seed), )), } set := make([][]string, 1000) for i := range set { strings := make([]string, 10000) for idx := range strings { // random length strings[idx] = gen.NextString() } set[i] = strings } return set } type generator struct { src *rand.Rand } func (g *generator) NextInt(max int) int { return g.src.Intn(max) } // Gets random random-length alphanumeric string. func (g *generator) NextString() (str string) { // random-length 3-8 chars part strlen := g.src.Intn(6) + 3 // random-length 1-3 num numlen := g.src.Intn(3) + 1 // random position for num in string numpos := g.src.Intn(strlen + 1) var num string for i := 0; i < numlen; i++ { num += strconv.Itoa(g.src.Intn(10)) } for i := 0; i < strlen+1; i++ { if i == numpos { str += num } else { str += string('a' + g.src.Intn(16)) } } return str } Running all the benchmarks of a package is as easy as testing: just run
go test with an indication of the flag and mask. For example, you can run only BenchmarkHandyStringSort , specifying Handy as the mask. We are interested in both: $ go test -bench=. PASS BenchmarkStringSort 500 4694244 ns/op BenchmarkHandyStringSort 100 15452136 ns/op ok github.com/Xlab/handysort 91.389s Here, using the example of random arrays of 10,000 rows of different lengths, the human sorting variant showed itself 3.3 times slower than the regular version. Sorting 10,000 lines in 15.6ms on Intel i5 1.7GHz is an acceptable result, I believe the algorithm can be considered working. If someone comes up with something similar and his benchmarks show the result in 5ms (comparable to 4.7ms of standard sorting), everyone will be happy, because the advantage will be measured .
Important links to official materials about various aspects of testing in Go:
- golang.org/doc/code.html#Testing
- golang.org/pkg/testing
- golang.org/doc/faq#testing_framework
- blog.golang.org/cover
Spread
After we combed our snippet, covered it with tests and measured performance, it’s time to share it with the public. The name of the package came up with
handysort , hosting of course GitHub, so the full name of the package I got is github.com/Xlab/handysort - this way of recording prevents any conflicts of package names, guarantees the authenticity of the sources and opens up really cool possibilities for further work with the package. . ├── LICENSE ├── README.md ├── strings.go └── strings_test.go 0 directories, 4 files Files in the composition of the full component. Try, maybe, look at the code of some java-component:
telegram-api> src> main> java> org> telegram> api> engine> file> UploadListener.java
- and everything ?! Well, ooook, now click back.
Approach I
Thus, no additional package design is required: you take your code, comment, cover with tests and upload to GitHub. Now anyone can take advantage of this package by connecting it to the
include section among others: import ( "bufio" "bytes" "errors" "fmt" "github.com/Xlab/handysort" "io" ) When building a package automatically tightened if there is no local copy or it is outdated. The author can improve the package, correct errors, your product will be effectively provided with fresh versions of packages.
If you did not skimp on comments on the exported functions (functions with a capital letter, inside - non-public comments) and did not forget to write a brief explanation of the package, as in the example with
handysort :strings.do
// Copyright 2014 Maxim Kouprianov. All rights reserved. // Use of this source code is governed by the MIT license // that can be found in the LICENSE file. /* Package handysort implements an alphanumeric string comparison function in order to sort alphanumeric strings correctly. Default sort (incorrect): abc1 abc10 abc12 abc2 Handysort: abc1 abc2 abc10 abc12 Please note, that handysort is about 5x-8x times slower than a simple sort, so use it wisely. */ package handysort import ( "unicode/utf8" ) // Strings implements the sort interface, sorts an array // of the alphanumeric strings in decreasing order. type Strings []string func (a Strings) Len() int { return len(a) } func (a Strings) Swap(i, j int) { a[i], a[j] = a[j], a[i] } func (a Strings) Less(i, j int) bool { return StringLess(a[i], a[j]) } // StringLess compares two alphanumeric strings correctly. func StringLess(s1, s2 string) (less bool) { // uint64 = max 19 digits n1, n2 := make([]rune, 0, 18), make([]rune, 0, 18) for i, j := 0, 0; i < len(s1) || j < len(s2); { var r1, r2 rune var w1, w2 int var d1, d2 bool // read rune from former string available if i < len(s1) { r1, w1 = utf8.DecodeRuneInString(s1[i:]) i += w1 // if digit, accumulate if d1 = ('0' <= r1 && r1 <= '9'); d1 { n1 = append(n1, r1) } } // read rune from latter string if available if j < len(s2) { r2, w2 = utf8.DecodeRuneInString(s2[j:]) j += w2 // if digit, accumulate if d2 = ('0' <= r2 && r2 <= '9'); d2 { n2 = append(n2, r2) } } // if have rune and other non-digit rune if (!d1 || !d2) && r1 > 0 && r2 > 0 { // and accumulators have digits if len(n1) > 0 && len(n2) > 0 { // make numbers from digit group in1 := digitsToNum(n1) in2 := digitsToNum(n2) // and compare if in1 != in2 { return in1 < in2 } // if equal, empty accumulators and continue n1, n2 = n1[0:0], n2[0:0] } // detect if non-digit rune from former or latter if r1 != r2 { return r1 < r2 } } } // if reached end of both strings and accumulators // have some digits if len(n1) > 0 || len(n2) > 0 { in1 := digitsToNum(n1) in2 := digitsToNum(n2) if in1 != in2 { return in1 < in2 } } // last hope return len(s1) < len(s2) } // Convert a set of runes (digits 0-9) to uint64 number func digitsToNum(d []rune) (n uint64) { if l := len(d); l > 0 { n += uint64(d[l-1] - 48) k := uint64(l - 1) for _, r := range d[:l-1] { n, k = n+uint64(r-48)*uint64(10)*k, k-1 } } return } Such comments are automatically recognized by the godoc documentation system . You can view the package documentation in many ways, for example in the console:
godoc < > . There is a web service godoc.org that allows you to quickly view the documentation of any package, if it is located on one of the well-known hosting code. This means that if you have commented out the public functions in the code and the project is located, for example, on github, then the package documentation is available at godoc.org/github.com/Xlab/handysort (you can substitute any full package name). The entire standard library is ideally commented out (for example, godoc.org/fmt ), when studying packages it is useful to look at not only godoc documents, but also read the source code, I recommend.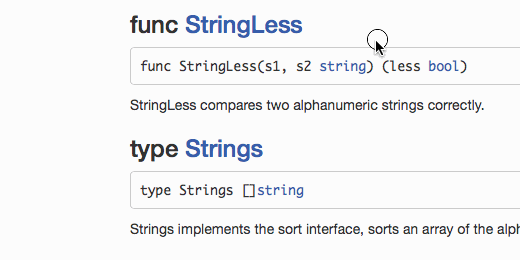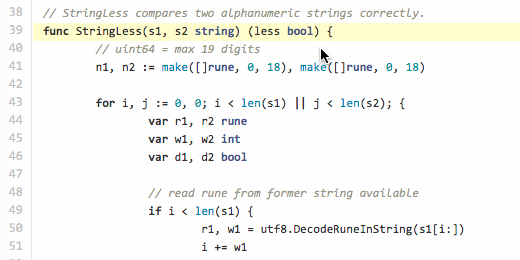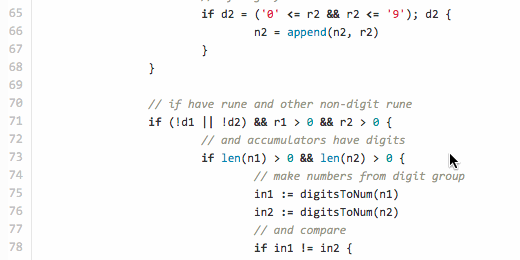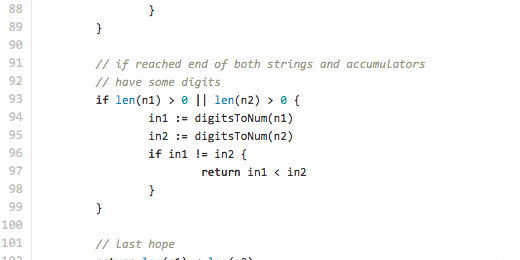
Important links to official materials about various aspects of code design in Go:
- blog.golang.org/organizing-go-code
- blog.golang.org/go-fmt-your-code
- blog.golang.org/godoc-documenting-go-code
Approach II
In case of a lack of confidence in the “random dude on GitHub” or if you need to fix a specific version of the package, you can fork the repository and connect the package as
github.com/VasyaPupkin/handysort , the essence will not change. At the same time, you can save humanity if one day the author of the original repository collects wheels / mushrooms and methodically deletes the repositories with their packages, to which many have direct links in the source code.Approach III
Finally, if the project’s dependencies do not need someone else’s package and github links, it is advisable to transfer the functionality to your package — copy the two
strings.go and strings_test.go into your handysort.go and handysort_test.go . Thus, the functional will not touch the main part in any way, and tests and benchmarks will become common. By the way, the code in Go is formatted automatically and therefore any foreign library will be framed in a clear and proper style.Instead of conclusion

Post prepared with the support of the plugin GoSublime for Sublime Text.
All matches are random.
Source: https://habr.com/ru/post/208756/
All Articles