Replacing ctags for perl in mooedit
In the mooedit editor there is a plugin for outputting source names. It uses the standard ctags , which with Perl work, to put it mildly, is not a fountain. Ctags only finds function names, but I would like more:
First, let's try to see how the ctags call for Perl happens and think about how to replace the utility for this case. After looking at moo / plugins / ctags / ctags-doc.c , it becomes clear that the call in our case is this:
')
There is no explicit indication that Perl is here. Therefore, we will catch the situation using the file utility. Create a file ~ / bin / ctags , which will be called instead of the system ctags :
Now you need to think what it will be like ~ / bin / perltags . In principle, the pltags and perltags utilities are familiar to vim users, but they also did not satisfy me at all. Perl-tags utility was found in CPAN. But to be used with mooedit, you would still have to modify it with a file, so (and just for fun) decided to write your own .
First, let's deal with the format. After running ctags, the editor expects these lines:
kind (in the terminology of offal mooedit) is a type of name ( f is a function, v is a variable, etc).
Two characters ( ; " ) are added to the tail of the line number - this is not a typo; without them, the editor simply drops (apparently, a bit after --excmd = number ).
With this like everything, now you need to understand what exactly is parsit. We don’t need a deep analysis of the source code, but we don’t need to disassemble the source code - not comme il faut. Therefore we take PPI , and after some time appears
What he can do:
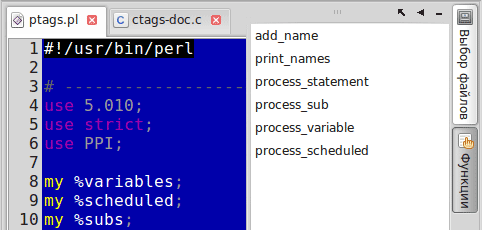
Each name is appended with the number of the found string (for orientation), and from the window of the plug-in you can go through all the entries of the tags, and not just the first one. Moreover, functions, variables and blocks do not fall into the general list, but are grouped together:
First, let's try to see how the ctags call for Perl happens and think about how to replace the utility for this case. After looking at moo / plugins / ctags / ctags-doc.c , it becomes clear that the call in our case is this:
')
ctags -u --fields=afksS --excmd=number -f '_' ' ' There is no explicit indication that Perl is here. Therefore, we will catch the situation using the file utility. Create a file ~ / bin / ctags , which will be called instead of the system ctags :
#!/bin/bash FILE=`file $6 2>&1` RX='Perl.*' if [[ "$FILE" =~ $RX ]] ; then ~/bin/perltags $6 > $5 else /usr/bin/ctags "$@" fi Now you need to think what it will be like ~ / bin / perltags . In principle, the pltags and perltags utilities are familiar to vim users, but they also did not satisfy me at all. Perl-tags utility was found in CPAN. But to be used with mooedit, you would still have to modify it with a file, so (and just for fun) decided to write your own .
First, let's deal with the format. After running ctags, the editor expects these lines:
_;" kind kind (in the terminology of offal mooedit) is a type of name ( f is a function, v is a variable, etc).
Two characters ( ; " ) are added to the tail of the line number - this is not a typo; without them, the editor simply drops (apparently, a bit after --excmd = number ).
With this like everything, now you need to understand what exactly is parsit. We don’t need a deep analysis of the source code, but we don’t need to disassemble the source code - not comme il faut. Therefore we take PPI , and after some time appears
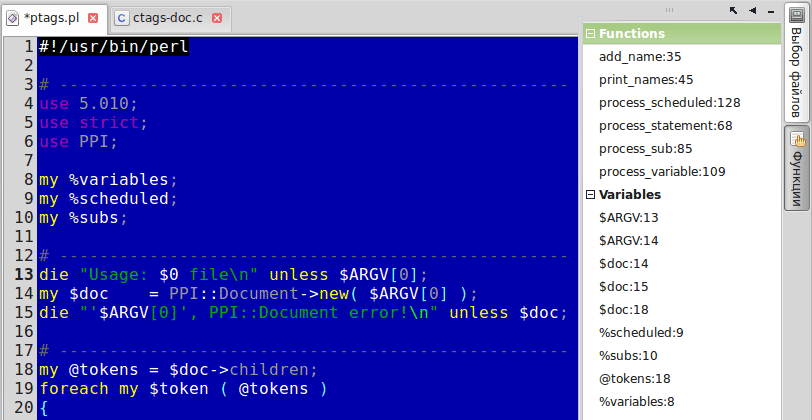
Here is such a script:
#!/usr/bin/perl # ------------------------------------------------------------------------------ use 5.010; use strict; use PPI; my %variables; my %scheduled; my %subs; # ------------------------------------------------------------------------------ die "Usage: $0 file\n" unless $ARGV[0]; my $doc = PPI::Document->new( $ARGV[0] ); die "'$ARGV[0]', PPI::Document error!\n" unless $doc; # ------------------------------------------------------------------------------ my @tokens = $doc->children; foreach my $token ( @tokens ) { given ( $token->class ) { process_statement( $token ) when 'PPI::Statement'; process_variable( $token ) when 'PPI::Statement::Variable'; process_sub( $token ) when 'PPI::Statement::Sub'; process_scheduled( $token ) when 'PPI::Statement::Scheduled'; } } print_names( \%variables, 'v' ); print_names( \%subs, 'f' ); print_names( \%scheduled, 'p' ); # ------------------------------------------------------------------------------ sub add_name { my ( $list, $token, $content ) = @_; # $content , -, , my $name = $token->content; $list->{$name} = () unless exists $list->{$name}; $list->{$name}->{ $token->line_number } = $content; } # ------------------------------------------------------------------------------ sub print_names { my ( $list, $type ) = @_; foreach my $name ( sort { my $an = $a =~ /^[\$\%\@](.+)$/ ? $1 : $a; my $bn = $b =~ /^[\$\%\@](.+)$/ ? $1 : $b; lc $an cmp lc $bn; } keys $list ) { foreach my $line ( sort { $a <=> $b } keys $list->{$name} ) { print "$name:$line\t$ARGV[0]\t$line;\"\t$type\n"; } } } # ------------------------------------------------------------------------------ # @EXPORT = qw(aaa), @EXPORT_OK = qw(bbb); # ------------------------------------------------------------------------------ sub process_statement { my ( $tok ) = @_; my @tokens = $tok->children; return unless $#tokens > 0; foreach my $token ( @tokens ) { add_name( \%variables, $token, $tok->content ) if $token->class eq 'PPI::Token::Symbol'; } } # ------------------------------------------------------------------------------ # sub aaa($$$); # sub aaa{}; # ------------------------------------------------------------------------------ sub process_sub { my ( $tok ) = @_; my @tokens = $tok->children; return unless $#tokens > 1; shift @tokens; foreach my $token ( @tokens ) { next if $token->class eq 'PPI::Token::Whitespace' or $token->class eq 'PPI::Token::Comment' or $token->class eq 'PPI::Token::Pod'; # 'sub' PPI::Token::Word: return unless $token->class eq 'PPI::Token::Word'; add_name( \%subs, $token, $tok->content ); last; } } # ------------------------------------------------------------------------------ # my $aaa; # our ($aaa, $bbb); # ------------------------------------------------------------------------------ sub process_variable { my ( $tok ) = @_; my @tokens = $tok->children; foreach my $token ( @tokens ) { # - : process_variable( $token ), next if $token->class eq 'PPI::Structure::List'; process_variable( $token ), next if $token->class eq 'PPI::Statement::Expression'; add_name( \%variables, $token, $tok->content ) if $token->class eq 'PPI::Token::Symbol'; } } # ------------------------------------------------------------------------------ # BEGIN {}; CHECK, UNITCHECK, INIT, END # ------------------------------------------------------------------------------ sub process_scheduled { my ( $tok ) = @_; my @tokens = $tok->children; return unless $#tokens > 0; add_name( \%scheduled, $tokens[0], $tok->content ); } # ------------------------------------------------------------------------------ What he can do:
- Finding function names, including ads
- Find the names of global variables, including their occurrences in expressions
- Find blocks BEGIN, END etc
Each name is appended with the number of the found string (for orientation), and from the window of the plug-in you can go through all the entries of the tags, and not just the first one. Moreover, functions, variables and blocks do not fall into the general list, but are grouped together:
Source: https://habr.com/ru/post/208754/
All Articles