CBOR - New Binary Data Format
Concise Binary Object Representation ( compressed binary representation of an object ) is a data format that has been designed to provide as simple as possible implementation code, generate compact output data and expand the format without the need to exchange version information.
The CBOR format standard was officially announced by the IETF committee in October 2013 in the new RFC 7049 , sponsored by Carsten Bormann and Paul Hoffman . Looking at the name of the first author, we can suggest another reason for the abbreviation for the format name, but perhaps this is just a coincidence. The CBOR format has received the application / cbor MIME type.
At the moment there are probably hundreds of various binary formats for representing structured data, some of which are standardized, popular and widely used (for example, BER and DER for ASN.1, MessagePack and BSON). All existing standards solve their tasks, and the CBOR is no exception. There were seven important requirements for the format, and since none of the existing formats could fully satisfy them, a new one was created (yes, the picture suggests itself).
')
As can be seen from the requirements, CBOR focuses on the JSON data model, but is not limited to it, adding popular data types and allowing the format to expand in the future.
To understand how successfully the format solves the tasks, and to be able to compare it with other formats, consider the process of encoding data into the CBOR format.
Each data element begins with a byte, which contains a description of the main type ( major type ) of data and additional information ( additional info ). The main type takes 3 high bits and can have values from 0 to 7. Additional information can receive values from 0 to 31.
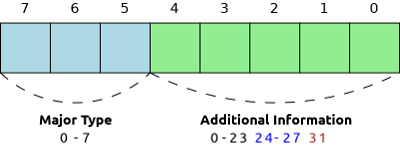
As you can see in the illustration, in the meaning of additional information there are three conditional ranges:
The values 28-30 are reserved for future versions of the standard.
As already shown in the examples, depending on the value of the main type, the meaning of the additional information becomes different. Consider the basic data types.
The additional information contains the values of the number (if it is less than 24), in other cases the additional information indicates the size of the integer number that follows. If 24 is
For example, the number 16 is encoded in
The value is encoded by analogy with type 0, with the only difference that one is subtracted from the absolute value. For example, -16 is encoded in
For a byte string, additional information encodes the length of the string in bytes. For example, in the case of a byte string with a length of 16 bytes, it will be encoded in
The text string is a string consisting of Unicode characters in UTF-8 encoding. As with the byte string, the extra information encodes the length of the string in bytes. Unlike the JSON format, the text string does not need to be escaped by the characters of the carry characters, in the form of
By analogy with the type of the string, the additional information indicates the length of the array, but not in bytes, but in the number of elements. The elements in the array need not be of the same type, it can be a set of strings, numbers, etc. After the header, the elements of the array immediately follow. For example, the array
This type defines a map consisting of pairs of “key” - “value”. Additional information determines the number of such pairs. For example, a map of 9 pairs is encoded as
This type opens wide possibilities for the extension of the standard. Additional information specifies an integer tag number, which specifies a range of tags from 0 to 18446744073709551615. The tag refers to a specific representation of the base types, allowing you to extend the supported data types indefinitely.
For example, the standard specifies that the tag 0 sets the date-time text string in the format described in RFC 3339 (as amended from RFC 4287). For example, when coding time
Note that even if the decoder does not know what the tag 0 means, it will still be able to decode the data, since after the tag there is an element of the basic type 3 - a text string.
Currently, several tags are defined by the standard, the IANA deals with the list of tags, the current distribution can be seen by reference
It is worth mentioning the tag 55799, which means that the data in the CBOR format follow. In fact, it does not carry any payload, but, for example, when saving data in the CBOR format to a file, this tag forms the sequence
This type allows you to describe simple (simple) values, as well as floating-point numbers. Additional information has the following meaning:
This standard defines several codes of simple values:
Other simple values are also registered by IANA, currently a list of simple values is available by reference .
Four basic types: an array, a map, a byte and a text string can have an undefined value of the elements (which is given by the value 31 in the additional information). This allows you to start coding elements whose number is still unknown. This can be claimed in applications that stream data.
In the case of arrays and maps, the elements simply follow one another, and the interrupt stop code is used to indicate completion. Immediately after the last element of an array or map, an element of type 7 follows with additional information 31 — this is a byte
In the case of strings, a different approach is used. Strings are transmitted in parts of finite length, which are later merged into one string (this can be done by both the decoder and the final application). The indicator of the completion of the sequence of parts of lines is also the stop code of the interruption
Example:
After decoding, all fragments are combined into one line:
The CBOR standard defines several rules that should allow different implementations with equal input data to create the same output. However, it is still allowed, if there are certain requirements of the application, to allow a discharge from the standard, if this generally does not violate the validity of the document being created.
The CBOR standard allows for a different approach to handling errors in the format. Errors can be associated with the format itself (unknown values in additional information, simple values, incorrect number of array elements, etc.) or with values (for example, invalid UTF-8 code in a text line or duplicate keys in an associative array ).
The decoder may issue warnings on incorrect data, may perform conversions to correct the error, may ignore errors or stop processing immediately when the first error is detected. The standard proposes the use of strict mode in case data came from an unreliable source, in this case the decoder must reject all data that failed validation or may be perceived differently by different decoders. The non-strict mode is used if the data is from a reliable source and the processing speed is more important (for example, do not check the validity of UTF-8 rows).
The text of the standard provides a comparative table of how arrays are encoded in various existing formats. The first array consists of two elements, with an embedded array. The second array of indefinite length (the conditional symbol
As you can see, the most compact view of the MessagePack and CBOR is, with only BER, UBJSON and CBOR available for encoding infinite sequences.
Immediately after the release of the standard, the first implementations of (de) encoders in various programming languages began to appear. For example, C , Perl , Ruby , Python , Java , Go, and many others (though I’ve looked at github fluently and haven’t found a JavaScript implementation ...).
Not all of these implementations fully support the standard, and there may be many more or maybe more. All this perfectly confirms that the main objective of the standard has been achieved: the implementation of (de) encoder is a task of small complexity. It is likely that soon at the interviews programmers will begin to ask to implement a non-strict CBOR decoder as a test task.
PS If you find errors, typos or inaccuracies in the text, please let me know, I will definitely correct it.
The CBOR format standard was officially announced by the IETF committee in October 2013 in the new RFC 7049 , sponsored by Carsten Bormann and Paul Hoffman . Looking at the name of the first author, we can suggest another reason for the abbreviation for the format name, but perhaps this is just a coincidence. The CBOR format has received the application / cbor MIME type.
At the moment there are probably hundreds of various binary formats for representing structured data, some of which are standardized, popular and widely used (for example, BER and DER for ASN.1, MessagePack and BSON). All existing standards solve their tasks, and the CBOR is no exception. There were seven important requirements for the format, and since none of the existing formats could fully satisfy them, a new one was created (yes, the picture suggests itself).
')
Requirements for a new binary format
- Clearly encoded most common data type standards on the Internet.
The format must be able to encode basic data types and structures using a binary representation. Moreover, there is no requirement for unique coding for absolutely all data types, for example, the number 7 can be represented both as a string and as an integer. - Compact implementation for the encoder / decoder, which would allow to create implementations that are not demanding on the capabilities of the processor and the available memory.
The format should use familiar machine implementations of formats (for example, for integers or floating point numbers - IEEE 754) - Lack of description scheme.
Also, as JSON-format self-describes the data presented (object, array, string, etc.). The absence of a description scheme allows you to create a simple and universal decoder. - Serialization of data should be as compact as possible, but not to the detriment of the ease of writing (de) encoder.
The volume of the representation in JSON format is taken as the top bar of the amount of encoded data. - The format should be equally applicable both in applications on limited resources, and in applications working with huge amounts of data.
This implies that the implementation must be equally thrifty to the CPU when encoding and decoding data. - The format must support all existing types in JSON for converting data from and to JSON.
- The format must be extensible and the extended format must be successfully decoded by earlier versions of the decoder.
It is assumed that the format will be used for decades and at the same time maintain backward compatibility, so that future versions of the format standard can normally be processed by the decoder for earlier versions. So that in case of detection of an unknown extension, you still have the opportunity to decode the message.
As can be seen from the requirements, CBOR focuses on the JSON data model, but is not limited to it, adding popular data types and allowing the format to expand in the future.
CBOR Specification
To understand how successfully the format solves the tasks, and to be able to compare it with other formats, consider the process of encoding data into the CBOR format.
Each data element begins with a byte, which contains a description of the main type ( major type ) of data and additional information ( additional info ). The main type takes 3 high bits and can have values from 0 to 7. Additional information can receive values from 0 to 31.
As you can see in the illustration, in the meaning of additional information there are three conditional ranges:
- If the value is from 0 to 23, then this value is used directly as an integer. For example, if the main type is an integer, then the value of the additional information is the value of the element. If the base type is a string, this number indicates the length of the string.
- If the value is from 24 to 27, then the subsequent bytes contain an integer of variable length, respectively 1, 2, 4, and 8-byte non-negative integers. For example, if the main type is an integer, then the subsequent bytes contain its value, and if the string is its length.
- The value 31 is special and indicates that the element length is not defined. For example, in the case of a string, this means that the length of the string is unknown.
The values 28-30 are reserved for future versions of the standard.
As already shown in the examples, depending on the value of the main type, the meaning of the additional information becomes different. Consider the basic data types.
Type 0: non-negative integer
The additional information contains the values of the number (if it is less than 24), in other cases the additional information indicates the size of the integer number that follows. If 24 is
uint8_t , 25 is uint16_t , 26 is uint32_t and 27 is uint64_t .For example, the number 16 is encoded in
0x10 , and the number 500 in a sequence of three bytes 0x19 , 0x01f4 (500)Type 1: Negative Integer
The value is encoded by analogy with type 0, with the only difference that one is subtracted from the absolute value. For example, -16 is encoded in
0x2F , and the number -500 is 0x39 , 0x01f3 (499)Type 2: byte string
For a byte string, additional information encodes the length of the string in bytes. For example, in the case of a byte string with a length of 16 bytes, it will be encoded in
0x50 (type 2, value 16) followed by 16 bytes containing a byte string. And for a string 500 bytes long - a three-byte header: 0x59 (type 2, value 25), 0x01f4 (500), followed by 500 bytes of string data.Type 3: text string
The text string is a string consisting of Unicode characters in UTF-8 encoding. As with the byte string, the extra information encodes the length of the string in bytes. Unlike the JSON format, the text string does not need to be escaped by the characters of the carry characters, in the form of
\n or \u000a , etc.Type 4: array of elements
By analogy with the type of the string, the additional information indicates the length of the array, but not in bytes, but in the number of elements. The elements in the array need not be of the same type, it can be a set of strings, numbers, etc. After the header, the elements of the array immediately follow. For example, the array
[0,"A"] is encoded as follows: 82 - 2- , 00 - 0, 61 - 1 , 41 - "A" Type 5: pairs map (associative array, hash, dictionary, JSON object ...)
This type defines a map consisting of pairs of “key” - “value”. Additional information determines the number of such pairs. For example, a map of 9 pairs is encoded as
0xa9 (type 5 + value 9), followed by 9 pairs of elements: the first key, the first value, the second key, etc. Keys can be of different types, but as a rule, this is rarely in demand.Type 6: semantic tagging of other basic types
This type opens wide possibilities for the extension of the standard. Additional information specifies an integer tag number, which specifies a range of tags from 0 to 18446744073709551615. The tag refers to a specific representation of the base types, allowing you to extend the supported data types indefinitely.
For example, the standard specifies that the tag 0 sets the date-time text string in the format described in RFC 3339 (as amended from RFC 4287). For example, when coding time
1970-01-01T00:00Z we get: 0 - 0 71 - 17 31 39 37 30 2d 30 31 2d 30 31 54 30 30 3a 30 30 5a - 1970-01-01T00:00Z Note that even if the decoder does not know what the tag 0 means, it will still be able to decode the data, since after the tag there is an element of the basic type 3 - a text string.
Currently, several tags are defined by the standard, the IANA deals with the list of tags, the current distribution can be seen by reference
It is worth mentioning the tag 55799, which means that the data in the CBOR format follow. In fact, it does not carry any payload, but, for example, when saving data in the CBOR format to a file, this tag forms the sequence
0xd9d9f7 at the beginning, which can be used by utilities as a magic value to determine the file type. In addition, this sequence is not found in any of the existing Unicode encodings, so it allows you to quickly distinguish CBOR from text data.Type 7: floating point numbers and other simple data types
This type allows you to describe simple (simple) values, as well as floating-point numbers. Additional information has the following meaning:
- 0..23 - Simple value (code from 0 to 23)
- 24 - Simple value (code from 24 to 255)
- 25 - IEEE 754 half-precision floating point number (16 bits)
- 26 - IEEE 754 single-precision floating point number (32 bits)
- 27 - IEEE 754 double precision floating point number (64 bits)
- 28-30 - undefined
- 31 - Stop code interrupt (break) for items with undefined length
This standard defines several codes of simple values:
- 20 - False
- 21 - True
- 22 - Null
- 23 - Undefined
Other simple values are also registered by IANA, currently a list of simple values is available by reference .
Indefinite length of elements of some basic types
Four basic types: an array, a map, a byte and a text string can have an undefined value of the elements (which is given by the value 31 in the additional information). This allows you to start coding elements whose number is still unknown. This can be claimed in applications that stream data.
In the case of arrays and maps, the elements simply follow one another, and the interrupt stop code is used to indicate completion. Immediately after the last element of an array or map, an element of type 7 follows with additional information 31 — this is a byte
0xFF .In the case of strings, a different approach is used. Strings are transmitted in parts of finite length, which are later merged into one string (this can be done by both the decoder and the final application). The indicator of the completion of the sequence of parts of lines is also the stop code of the interruption
0xFF . In the case of text strings, when transferring fragments, it is important that the string separation does not occur within the Unicode-character code sequence, i.e. all parts of the string must contain valid sequences of Unicode characters.Example:
5F -- 44 -- 4 aabbccdd -- 43 -- 3 eeff99 -- FF -- "break" After decoding, all fragments are combined into one line:
aabbccddeeff99Canonical format implementation
The CBOR standard defines several rules that should allow different implementations with equal input data to create the same output. However, it is still allowed, if there are certain requirements of the application, to allow a discharge from the standard, if this generally does not violate the validity of the document being created.
- Use the most compressed representation for the encoded data. For example, if the integer is coded 500, then the representation of
uint16_tshould be chosen, and not, say,uint64_t. When encoding the number0.0encoder must convert to an integer type, as this will give a more concise representation. If a floating-point number can be represented with single precision without losing significant bits, then the encoder should not use double precision, etc. - The keys of associative arrays must be sorted in ascending order (byte sorting, shorter keys come first)
- If possible, items with an indefinite length are replaced with a fixed length.
- The canonical implementation should not use tags, but when processing data with tags, it should save them
Error processing
The CBOR standard allows for a different approach to handling errors in the format. Errors can be associated with the format itself (unknown values in additional information, simple values, incorrect number of array elements, etc.) or with values (for example, invalid UTF-8 code in a text line or duplicate keys in an associative array ).
The decoder may issue warnings on incorrect data, may perform conversions to correct the error, may ignore errors or stop processing immediately when the first error is detected. The standard proposes the use of strict mode in case data came from an unreliable source, in this case the decoder must reject all data that failed validation or may be perceived differently by different decoders. The non-strict mode is used if the data is from a reliable source and the processing speed is more important (for example, do not check the validity of UTF-8 rows).
Comparison with other binary formats
The text of the standard provides a comparative table of how arrays are encoded in various existing formats. The first array consists of two elements, with an embedded array. The second array of indefinite length (the conditional symbol
_ used for this) also contains an embedded array (of finite length). +---------------+-------------------------+-------------------------+ | Format | [1, [2, 3]] | [_ 1, [2, 3]] | +---------------+-------------------------+-------------------------+ | RFC 713 | c2 05 81 c2 02 82 83 | | | | | | | ASN.1 BER | 30 0b 02 01 01 30 06 02 | 30 80 02 01 01 30 06 02 | | | 01 02 02 01 03 | 01 02 02 01 03 00 00 | | | | | | MessagePack | 92 01 92 02 03 | | | | | | | BSON | 22 00 00 00 10 30 00 01 | | | | 00 00 00 04 31 00 13 00 | | | | 00 00 10 30 00 02 00 00 | | | | 00 10 31 00 03 00 00 00 | | | | 00 00 | | | | | | | UBJSON | 61 02 42 01 61 02 42 02 | 61 ff 42 01 61 02 42 02 | | | 42 03 | 42 03 45 | | | | | | CBOR | 82 01 82 02 03 | 9f 01 82 02 03 ff | +---------------+-------------------------+-------------------------+ As you can see, the most compact view of the MessagePack and CBOR is, with only BER, UBJSON and CBOR available for encoding infinite sequences.
Existing CBOR implementations
Immediately after the release of the standard, the first implementations of (de) encoders in various programming languages began to appear. For example, C , Perl , Ruby , Python , Java , Go, and many others (though I’ve looked at github fluently and haven’t found a JavaScript implementation ...).
Not all of these implementations fully support the standard, and there may be many more or maybe more. All this perfectly confirms that the main objective of the standard has been achieved: the implementation of (de) encoder is a task of small complexity. It is likely that soon at the interviews programmers will begin to ask to implement a non-strict CBOR decoder as a test task.
PS If you find errors, typos or inaccuracies in the text, please let me know, I will definitely correct it.
Source: https://habr.com/ru/post/208690/
All Articles