Module for determining the sources of site visitors for Ruby on Rails
This post is mainly about web analytics: how to correctly identify the sources of visitors to your site, and about my module for Ruby on Rails, which helps in this difficult matter. In the end there is a small part that I ask to draw the attention of members of the Rails community: it is about me and Rails. But let's order.
There is a rather trivial task: to determine the source of the visitor who came to our site. I don’t know about you, but we parasitized on the body of Google Analytics for quite a long time: they took utmz, gutted it on the sors and mediums, and didn’t live. Analytics for us solved the issues of rewriting sources, recording sessions, and in general eliminated the paring of referrers from all sorts of buzzwords. But all good things come to an end.
When Google rolled out the beta of Universal, it became clear that sooner or later, the Google cookie would have to say goodbye and learn how to do everything yourself. But since then he declared the incompatibility of Classic and Universal, so far it was possible to sit exactly: Classic will be maintained for a long time.
But recently, Google began to gently poke users with a stick: he rolled out the profile converter - Classic → Universal. And here you have to start moving the rolls: the classic Analytics will receive the final Reader at the moment when remarketing lists will come to Universal. And this, I think, is not far off.
')
In this regard, I was delivered to the utmz self-made cookie generator. And called it sourcebuster .
The generator is made in the format Mountable engine for Ruby on Rails . It can be quite quickly adapted to all your Rails applications as a gem and updated with a single command from the console. The module is independent and does everything by itself. Data on the source can be used to substitute phone numbers, content on the site, save them with applications and use for further analytics. According to certain rules, the module calculates the source (and a number of parameters) and stores them in the visitor’s cookies.
Immediately link to GitHub: https://github.com/alexfedoseev/sourcebuster
I have not yet figured out the design of README.rdoc, in the process, I will soon be fixed.
Most of the logic repeats the logic of GA, but there are some differences.
Let's start with the data structure.
In total, we have 4 main types of traffic:
The filtering logic in the image below:
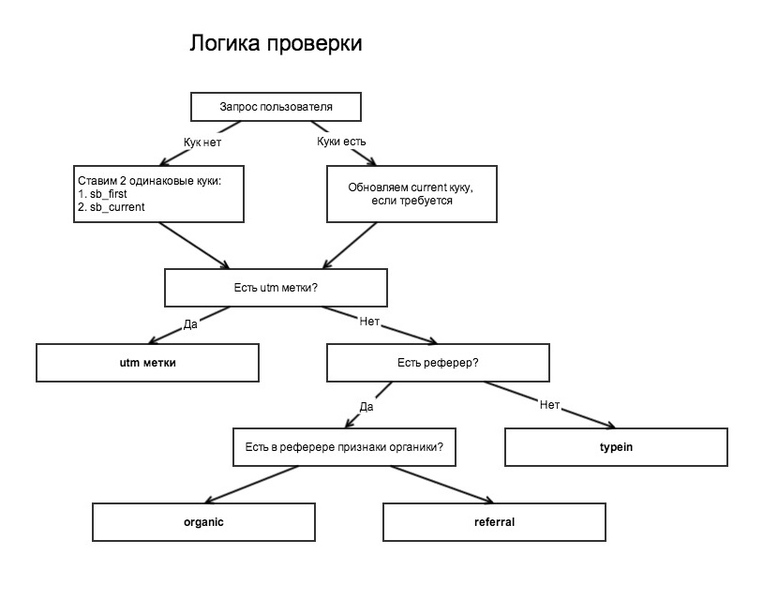
This way we pack our visitors in these 4 baskets.
Next, we need to create a rewrite of the source rules, since one visitor can go to the site at different times from different sources.
The rewrite logic follows the logic of Google Analytics:
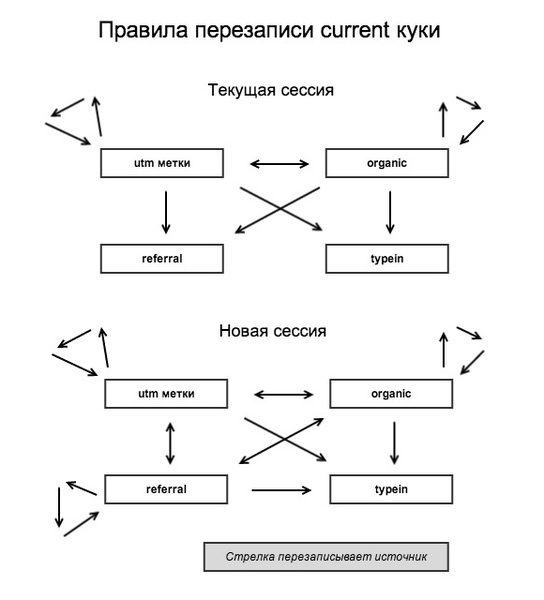
Please note that in the current session referral referrals do not overwrite anything. Why - I will explain with an example: a visitor often goes to a site from a third-party resource that is not a real source — for example, from a postal service, where he had a link to activate registration.
In this system, I decided in addition to overwritten data on the current visit to store data on the very first visit. That is, at the time of conversion, we will have data on the first and current sources of the visitor.
What specifically can be pulled out using the module:
The module gives the following methods (more precisely, the method is one, but pulls out different data):
Test module page: http://sandbox.alexfedoseev.com/sourcebuster/showoff
You can go to it from different sources and see what the module is.
The module also allows you to configure a number of additional parameters.
Interface: http://sandbox.alexfedoseev.com/sourcebuster/settings
Session duration
After what time after the last activity of the user his visit is considered completed. Specified in minutes, the default is 30 minutes.
Subdomain processing
This is essentially an analogue of _setDomainName in GA. Let me explain by example.
Suppose you have a website that has subdomains:
And you want the transitions from the site.com pages to blog.site.com to be considered internal non-referral transitions (that is, when switching from one subdomain to another source is not overwritten). To do this, in the settings you need to tick off "I have subdomains and traffic" and in the "Main host" field add the root host of the site, all subdomains of which will be regarded by the module as one site. In our case, it indicates "site.com" .
If you specify blog.site.com in the field, then the transition from alex.blog.site.com to blog.site.com will be non-referral, and the transition from alex.blog.site.com to shop.site.com will already be referral traffic.
Interface: http://sandbox.alexfedoseev.com/sourcebuster/custom_sources
The system has the ability to customize the processing of a number of additional sources.
Setup is made by the following parameters:
What for this table is needed the easiest way to explain with examples.
Example 1
You want the system to count Bing search transitions as organic traffic (which is quite true).
If you go to bing.com and enter the query “apple” into the search box, you will be taken to the issuing page with the address of the form:
www.bing.com/search ? q = apple & go = & qs = n & form = QBLH & pq = apple & sc = 8-5 & sp = -1 & sk = & cvid = 718ad07527244c319ecebf44aa261f64
On its basis we create a new special source:
Now everything that comes from such pages will be considered organic traffic.
Example 2
You want to highlight the transitions from the social. networks in a separate group.
We act according to a similar scheme:
Is done. Now all clicks on links from facebook (except those marked with utm-tags) will be with the value of the social channel.
Sources: https://github.com/alexfedoseev/sourcebuster/blob/master/test/integration/navigation_test.rb
The lion's share of tests is Selenium tests to verify the definition and rewrite of sources. They are written in Ruby, but implemented in such a way that you can check not only the code of my module, but in principle any implementation (for example, if someone will port it to php or js). That is, they are testing not the methods, but the result of their work. In addition, surrogate referrers are not used here, but real transitions from real resources are tested. And if Yandex changes something in the output (for example, it switches to https, which will kill the referrer), then the tests will show it. Everything is really shorter.
Now the tests are pretty meat and they are written rather for themselves, but if you want you can figure it out.
In order to test the rewritten code, you need to have:
The top block of code contains constants that need to be configured before running the tests. Of these, it is clear what needs to be prepared.
And yes, the test run takes about 20-30 minutes.
For 3.5 years now I have been doing internet marketing, and not so long ago I came to the conclusion that traffic generation is not mine. I want to generate meaning, not traffic. And I started writing code. It happened about 9 months ago. I have no mathematical and mathematical background, I had to understand everything from scratch and myself. The books of Chris Pine, Michael Hartl and other Internet services helped me in this.
As a result, I wrote a blog for myself, but about 5 months ago I had to take a break, and this module is the first thing I wrote after being idle. I ask the members of the Rails community to criticize the implementation and point out explicit and not very jambs. For all this time, I never managed to meet a living person who writes in Ruby, and it’s rather hard to comprehend anything and everything.
Thanks in advance for your criticism and I hope this post will be useful to someone. Good luck.
Part one. About web analytics and visitor sourcing
Problem
There is a rather trivial task: to determine the source of the visitor who came to our site. I don’t know about you, but we parasitized on the body of Google Analytics for quite a long time: they took utmz, gutted it on the sors and mediums, and didn’t live. Analytics for us solved the issues of rewriting sources, recording sessions, and in general eliminated the paring of referrers from all sorts of buzzwords. But all good things come to an end.
When Google rolled out the beta of Universal, it became clear that sooner or later, the Google cookie would have to say goodbye and learn how to do everything yourself. But since then he declared the incompatibility of Classic and Universal, so far it was possible to sit exactly: Classic will be maintained for a long time.
In the new version of GA, there was only one cookie left - with the user id. Analytics sends it to your server and already does all the calculations there. And neither through cookies, nor through js can you extract information about the source from it now.
But recently, Google began to gently poke users with a stick: he rolled out the profile converter - Classic → Universal. And here you have to start moving the rolls: the classic Analytics will receive the final Reader at the moment when remarketing lists will come to Universal. And this, I think, is not far off.
')
In this regard, I was delivered to the utmz self-made cookie generator. And called it sourcebuster .
First about the form
The generator is made in the format Mountable engine for Ruby on Rails . It can be quite quickly adapted to all your Rails applications as a gem and updated with a single command from the console. The module is independent and does everything by itself. Data on the source can be used to substitute phone numbers, content on the site, save them with applications and use for further analytics. According to certain rules, the module calculates the source (and a number of parameters) and stores them in the visitor’s cookies.
Immediately link to GitHub: https://github.com/alexfedoseev/sourcebuster
I have not yet figured out the design of README.rdoc, in the process, I will soon be fixed.
Now about the content
Most of the logic repeats the logic of GA, but there are some differences.
Let's start with the data structure.
Data structure
In total, we have 4 main types of traffic:
- utm - traffic marked by utm-tags
- organic - traffic from organic search engines
- referral - referral traffic (links from third-party resources)
- typein - direct transitions
The filtering logic in the image below:
This way we pack our visitors in these 4 baskets.
Next, we need to create a rewrite of the source rules, since one visitor can go to the site at different times from different sources.
Source rewriting logic
The rewrite logic follows the logic of Google Analytics:
Please note that in the current session referral referrals do not overwrite anything. Why - I will explain with an example: a visitor often goes to a site from a third-party resource that is not a real source — for example, from a postal service, where he had a link to activate registration.
In this system, I decided in addition to overwritten data on the current visit to store data on the very first visit. That is, at the time of conversion, we will have data on the first and current sources of the visitor.
What specifically can be pulled out using the module:
- Information about the very first source:
utm_source, utm_medium, utm_campaign, utm_content, utm_term - The same data about the current source
(if the user made a second transition from another source) - Date of first visit
- Point of entry
- Full referrer at which source rewriting occurred
- user ip and user agent
Module installation
It's laying in, that you already have a rails application to which you want to screw the module.
Add to gemfile applications:
Install:
Since this is a mountable engine, it exists in an isolated namespace.
We mount it in the application, adding to routes.rb :
Next we need to copy and complete all the migrations.
We copy:
And we execute:
There are 3 new tables in your database:
You don’t need to do anything with them, there is already data out of the box and there are interfaces for them.
For more information about Mountable engines - http://guides.rubyonrails.org
The module is almost connected, the final touch remains: to allow it to set cookies anywhere in your application. To do this, add the following to your application_controller.rb:
It seems ready. The engine uses the main application templates, so you can customize the styles yourself (perhaps I will change this). I could miss something, if something does not work - write.
Add to gemfile applications:
gem 'sourcebuster', :git => "git@github.com:alexfedoseev/sourcebuster.git" Install:
bundle install Since this is a mountable engine, it exists in an isolated namespace.
We mount it in the application, adding to routes.rb :
mount Sourcebuster::Engine => "/sourcebuster" Next we need to copy and complete all the migrations.
We copy:
bundle exec rake sourcebuster:install:migrations And we execute:
bundle exec rake db:migrate There are 3 new tables in your database:
- sourcebuster_referer_sources
Data about customizable sources. - sourcebuster_referer_types
Data on the types of referrals (essentially utm_medium for referral traffic). - sourcebuster_settings
Application settings (session duration and subdomain processing).
You don’t need to do anything with them, there is already data out of the box and there are interfaces for them.
For more information about Mountable engines - http://guides.rubyonrails.org
The module is almost connected, the final touch remains: to allow it to set cookies anywhere in your application. To do this, add the following to your application_controller.rb:
class ApplicationController < ActionController::Base include Sourcebuster::CookieSettersHelper before_filter :set_sourcebuster_data helper_method :extract_sourcebuster_data # some code private def set_sourcebuster_data set_sourcebuster_cookies end end It seems ready. The engine uses the main application templates, so you can customize the styles yourself (perhaps I will change this). I could miss something, if something does not work - write.
Using
When using the module, please note that this is a beta and was written by a person with rather little development experience (which is a couple of paragraphs at the end of the post).
The module gives the following methods (more precisely, the method is one, but pulls out different data):
Module methods
# C (utm / organic / referral / typein) extract_sourcebuster_data(:sb_first, :typ) # C utm_source extract_sourcebuster_data(:sb_first, :src) # C utm_medium extract_sourcebuster_data(:sb_first, :mdm) # C utm_campaign extract_sourcebuster_data(:sb_first, :cmp) # C utm_content extract_sourcebuster_data(:sb_first, :cnt) # C utm_term extract_sourcebuster_data(:sb_first, :trm) # (utm / organic / referral / typein) extract_sourcebuster_data(:sb_current, :typ) # utm_source extract_sourcebuster_data(:sb_current, :src) # utm_medium extract_sourcebuster_data(:sb_current, :mdm) # utm_campaign extract_sourcebuster_data(:sb_current, :cmp) # utm_content extract_sourcebuster_data(:sb_current, :cnt) # utm_term extract_sourcebuster_data(:sb_current, :trm) # extract_sourcebuster_data(:sb_first_add, :fd) # extract_sourcebuster_data(:sb_first_add, :ep) # , extract_sourcebuster_data(:sb_referer, :ref) # ip extract_sourcebuster_data(:sb_udata, :uip) # user agent extract_sourcebuster_data(:sb_udata, :uag) Test module page: http://sandbox.alexfedoseev.com/sourcebuster/showoff
You can go to it from different sources and see what the module is.
The module also allows you to configure a number of additional parameters.
Default settings
Interface: http://sandbox.alexfedoseev.com/sourcebuster/settings
Session duration
After what time after the last activity of the user his visit is considered completed. Specified in minutes, the default is 30 minutes.
Subdomain processing
This is essentially an analogue of _setDomainName in GA. Let me explain by example.
Suppose you have a website that has subdomains:
- site.com
- blog.site.com
- shop.site.com
And you want the transitions from the site.com pages to blog.site.com to be considered internal non-referral transitions (that is, when switching from one subdomain to another source is not overwritten). To do this, in the settings you need to tick off "I have subdomains and traffic" and in the "Main host" field add the root host of the site, all subdomains of which will be regarded by the module as one site. In our case, it indicates "site.com" .
If you specify blog.site.com in the field, then the transition from alex.blog.site.com to blog.site.com will be non-referral, and the transition from alex.blog.site.com to shop.site.com will already be referral traffic.
Additional sources
Interface: http://sandbox.alexfedoseev.com/sourcebuster/custom_sources
The system has the ability to customize the processing of a number of additional sources.
Setup is made by the following parameters:
- Domain
According to it, the source that will be processed is played. - Alias
Beautiful / friendly source name. - Channel
You can set the referral , organic or social . - Request parameter
Keyword parameter in search engine url.
What for this table is needed the easiest way to explain with examples.
Example 1
You want the system to count Bing search transitions as organic traffic (which is quite true).
If you go to bing.com and enter the query “apple” into the search box, you will be taken to the issuing page with the address of the form:
www.bing.com/search ? q = apple & go = & qs = n & form = QBLH & pq = apple & sc = 8-5 & sp = -1 & sk = & cvid = 718ad07527244c319ecebf44aa261f64
On its basis we create a new special source:
- Domain: bing.com
- Alias: bing
Or, as you wish, you can just do not write anything, then the referrer host will be substituted. - Channel: organic
- Keyword parameter: q
This is a symbol between the “?” And “= your_query” constructs in the search results URL.
Now everything that comes from such pages will be considered organic traffic.
Example 2
You want to highlight the transitions from the social. networks in a separate group.
We act according to a similar scheme:
- Domain: facebook.com
- Alias: facebook
- Channel: social
- Keyword parameter: not needed
Is done. Now all clicks on links from facebook (except those marked with utm-tags) will be with the value of the social channel.
In the domain field, you must fully specify the zone (.com, .com.ru, etc.). If you specify the value of facebook.com, then this filter will not get traffic from the domain facebook.com.ru. And from the domain m.facebook.com - will fall.
Tests
Sources: https://github.com/alexfedoseev/sourcebuster/blob/master/test/integration/navigation_test.rb
The lion's share of tests is Selenium tests to verify the definition and rewrite of sources. They are written in Ruby, but implemented in such a way that you can check not only the code of my module, but in principle any implementation (for example, if someone will port it to php or js). That is, they are testing not the methods, but the result of their work. In addition, surrogate referrers are not used here, but real transitions from real resources are tested. And if Yandex changes something in the output (for example, it switches to https, which will kill the referrer), then the tests will show it. Everything is really shorter.
Now the tests are pretty meat and they are written rather for themselves, but if you want you can figure it out.
In order to test the rewritten code, you need to have:
- page folded by certain rules
(see the code of the test page , find the id of the data blocks, if anything - ask questions) - indexed in search engines
(Yandex, Google, the third additional (for example, Rambler)) - and being in the top 5 on a specific request
- + links to this page from the social. network and third-party (referral) site
The top block of code contains constants that need to be configured before running the tests. Of these, it is clear what needs to be prepared.
And yes, the test run takes about 20-30 minutes.
I repeat: when using the module, please note that this is a beta, and it was written by a person with rather little development experience (which is a couple of paragraphs below).
Part two. About me and Rails
For 3.5 years now I have been doing internet marketing, and not so long ago I came to the conclusion that traffic generation is not mine. I want to generate meaning, not traffic. And I started writing code. It happened about 9 months ago. I have no mathematical and mathematical background, I had to understand everything from scratch and myself. The books of Chris Pine, Michael Hartl and other Internet services helped me in this.
As a result, I wrote a blog for myself, but about 5 months ago I had to take a break, and this module is the first thing I wrote after being idle. I ask the members of the Rails community to criticize the implementation and point out explicit and not very jambs. For all this time, I never managed to meet a living person who writes in Ruby, and it’s rather hard to comprehend anything and everything.
Thanks in advance for your criticism and I hope this post will be useful to someone. Good luck.
Source: https://habr.com/ru/post/208112/
All Articles