A few words about pattern recognition
I have long wanted to write a general article that contains the very basics of Image Recognition, a guide on basic methods, telling when to use them, what tasks they decide what to do in the evening on their knees, and what is better not to think without having a team in 20.

I have been writing some articles on Optical Recognition for a long time, so a couple of times a month various people write to me with questions on this topic. Sometimes it creates the feeling that you live with them in different worlds. On the one hand, you understand that a person is most likely a professional in a related topic, but he knows very little in OCR methods. And the most annoying thing is that he is trying to apply a method from a nearby area of knowledge, which is logical, but in Image Recognition does not work completely, but does not understand it and is very offended if he starts telling something from the very foundations. And considering that telling from the basics - a lot of time, which is often not there, is still sadder.
This article is designed so that a person who has never worked on image recognition methods, within 10-15 minutes, can create in his head a certain basic picture of the world, relevant to the subject, and understand in which direction to dig. Many of the methods described here are applicable to radar and audio processing.
I will start with a couple of principles that we always begin to tell a potential customer, or a person who wants to start practicing Optical Recognition:
It is very difficult to give some kind of universal advice, or tell you how to create some kind of structure around which you can build a solution to arbitrary computer vision tasks. The purpose of this article is to structure what can be used. I will try to break the existing methods into three groups. The first group is the pre-filtering and image preparation. The second group is the logical processing of filtering results. The third group is decision-making algorithms based on logical processing. The boundaries between the groups are very conditional. To solve a problem, it is not always necessary to apply methods from all groups, it is enough two, and sometimes even one.
The list of methods given here is not complete. I propose in the comments to add critical methods that I have not written and to assign 2-3 to each of the accompanying words.
In this group I put methods that allow you to highlight areas of interest in images, without analyzing them. Most of these methods apply a single transformation to all points in the image. At the filtering level, image analysis is not performed, but the points that pass filtering can be considered as areas with special characteristics.
')
The simplest transformation is the binarization of the image on the threshold. For RGB images and grayscale images, the threshold is the color value. There are ideal problems in which such a transformation is sufficient. Suppose you need to automatically highlight items on a white sheet of paper:


The choice of the threshold by which binarization occurs largely determines the process of binarization itself. In this case, the image was binarized according to the average color. Usually, binarization is performed using an algorithm that adaptively selects a threshold. Such an algorithm can be the choice of expectation or mode . And you can choose the largest peak of the histogram.
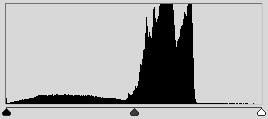
Binarization can give very interesting results when working with histograms, including in a situation if we consider the image not in RGB, but in HSV . For example, segment the colors of interest. On this principle, it is possible to build both a tag detector and a human skin detector.


Classical filtering techniques from radar and signal processing can be successfully applied in a variety of Pattern Recognition tasks. The traditional method in radar, which is almost not used in images in its pure form, is the Fourier transform (more specifically, FFT ). One of the few exceptions in which the one-dimensional Fourier transform is used is image compression . For image analysis, one-dimensional transformation is usually not enough, you need to use a much more resource - intensive two - dimensional transformation .
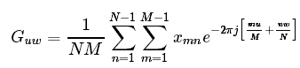
Few people actually count it, usually, where it is much faster and easier to use a convolution of the region of interest with a ready-made filter tuned to high (HPF) or low (LPF) frequencies. This method, of course, does not allow for spectrum analysis, but in a particular video processing task, it is usually not the analysis that is needed, but the result.
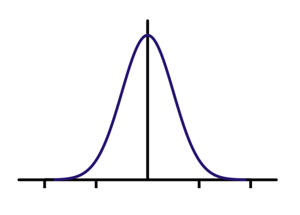
The most simple examples of filters that implement the underscore of low frequencies ( Gaussian filter ) and high frequencies ( Filter Gabor ).
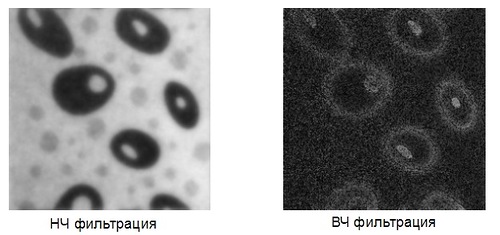
For each point of the image, a window is selected and multiplied with a filter of the same size. The result of such a convolution is a new point value. When implementing a low-pass filter and high-pass filter, images of this type are obtained:

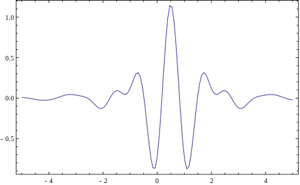
But what if we use for the convolution of a signal with some arbitrary characteristic function? Then it will be called " Wavelet Transformation ". This definition of wavelets is not correct, but it has traditionally been established that in many teams the wavelet analysis is the search for an arbitrary pattern in an image using a convolution with a model of this pattern. There is a set of classical functions used in wavelet analysis. These include the Haar wavelet , Morlah wavelet, Mexican hat wavelet , etc. The Haar primitives, about which there were several of my past articles ( 1 , 2 ), refer to such functions for two-dimensional space.

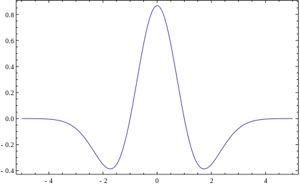
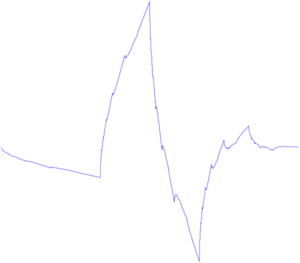
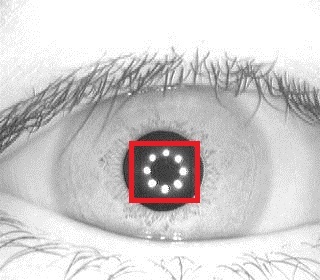
Above are 4 examples of classic wavelets. 3-dimensional Haar wavelet, 2-dimensional Meyer wavelet, Mexican Hat wavelet, Dobeshi wavelet. A good example of the use of extended interpretation of wavelets is the problem of finding the glare in the eye, for which the wavelet is the glare itself:
Classic wavelets are usually used to compress images , or to classify them (described below).
After such a free interpretation of wavelets, on my part, it is worth mentioning the correlation proper, which underlies them. When filtering images it is an indispensable tool. A classic application is the correlation of a video stream for finding shifts or optical flows. The simplest shear detector is also in some sense a difference correlator. Where the images do not correlate - there was movement.



An interesting class of filters is filtering functions. These are purely mathematical filters that allow you to detect a simple mathematical function in an image (direct, parabola, circle). An accumulating image is built, in which for each point of the original image a multitude of functions are generated that generate it. The most classical transformation is the Hough transformation for straight lines. In this transformation, for each point (x; y), the set of points (a; b) of the line y = ax + b, for which equality holds, is drawn. Beautiful pictures turn out:

(the first plus to the one who first finds the catch in the picture and that definition and explains it, the second plus to the one who first says what is shown here)
Hough Transformation allows you to find any parameterizable functions. For example a circle . There is a modified transformation that allows you to search for any shapes . This transformation is terribly fond of mathematics. But when processing images, it unfortunately does not always work. Very slow speed, very high sensitivity to binarization quality. Even in ideal situations, I preferred to use other methods.
An analogue of the Hough transform for straight lines is the Radon transform . It is calculated through the FFT, which gives a performance gain in a situation where there are a lot of points. In addition, it is possible to apply it to a non-binarized image.
A separate class of filters - filtering boundaries and contours . Outlines are very useful when we want to move from working with an image to working with objects in this image. When an object is rather complicated, but well distinguished, then often the only way to work with it is to select its contours. There are a number of algorithms that solve the problem of filtering circuits:
The most commonly used is Kenny, who works well and has an implementation in OpenCV (Sobel is also there, but he is less interested in contours).


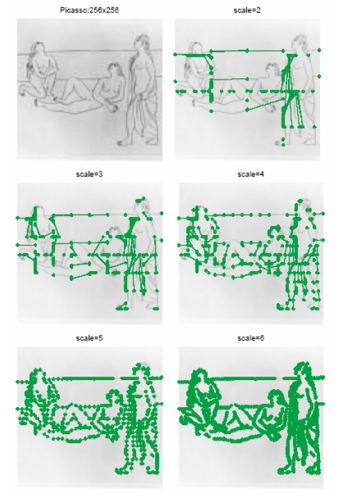
Above are filters whose modifications help solve 80-90% of problems. But besides them there are more rare filters used in local problems. There are dozens of such filters, I will not give them all. Interesting are iterative filters (for example, the active model of appearance ), as well as a ridgelet and a transformation curvelet , which are a fusion of classical wavelet filtering and analysis in the radon transform field. The beamlet transform works beautifully on the border of the wavelet transform and logical analysis, allowing you to select the contours:
But these transformations are very specific and sharpened for rare tasks.
Filtering gives a set of data suitable for processing. But it is often impossible to simply take and use this data without processing it. In this section there will be several classical methods that allow you to move from an image to the properties of objects, or to the objects themselves.
The transition from filtering to logic, in my opinion, are the methods of mathematical morphology ( 1 , 2 , 3 ). In fact, these are the simplest operations for building and eroding binary images. These methods allow you to remove noise from a binary image by increasing or decreasing existing elements. On the basis of mathematical morphology, there are contouring algorithms, but usually some kind of hybrid or combination algorithms are used.

In the section on filtering algorithms for obtaining boundaries have already been mentioned. The resulting bounds are simply converted into contours. For the Kany algorithm, this happens automatically; for the other algorithms, additional binarization is required. You can get a contour for a binary algorithm, for example, a bug algorithm.
The contour is a unique feature of the object. Often this allows you to identify the object on the contour. There is a powerful mathematical tool to do this. The device is called contour analysis ( 1 , 2 ).

To be honest, I never once managed to apply contour analysis in real-world problems. Too perfect conditions are required. That border is not there, the noise is too much. But, if you need to recognize something in ideal conditions, then contour analysis is a great option. It works very fast, beautiful math and understandable logic.
Special points are unique characteristics of an object that allow you to map an object to itself or to similar classes of objects. There are several dozen ways to select such points. Some methods highlight specific points in adjacent frames, some through a long period of time and when lighting changes, some allow you to find special points that remain so even when the object turns. Let's start with the methods that allow you to find special points that are not so stable, but they are quickly calculated, and then we go in increasing complexity:
First grade. Singular points that are stable for seconds. Such points are used to lead the object between adjacent frames of video, or to reduce the image from neighboring cameras. These points include local maxima of the image, angles in the image (the best of the detectors, perhaps, Haris detector), points at which the dispersion maximums are reached, certain gradients, etc.
Second class. Special points that are stable when changing lighting and small movements of the object. Such points serve primarily for learning and the subsequent classification of object types. For example, a pedestrian classifier or a face classifier is a product of a system built on such points. Some of the previously mentioned wavelets may be the basis for such points. For example, Haar primitives, search for glare, search for other specific functions. These points are points found by the histogram method of directional gradients ( HOG ).
Third class. Stable points. I know only about two methods that give complete stability and about their modifications. This is SURF and SIFT . They allow you to find particular points even when you rotate the image. The calculation of such points is longer compared to other methods, but for a rather limited time. Unfortunately, these methods are patented. Although, in Russia, patent the algorithms nizya, so use for the domestic market.
This part of the story will be devoted to methods that do not work directly with the image, but which allow you to make decisions. These are mainly different methods of machine learning and decision making. Recently Yandyks laid out a course on this topic on Habr, there is a very good selection. Here it is in the text version. For serious study topics strongly recommend to see them. Here I will try to identify several basic methods used specifically in pattern recognition.
In 80% of situations, the essence of learning in the recognition problem is as follows:
There is a test sample on which there are several classes of objects. Let it be the presence / absence of a person in the photo. For each image there is a set of features that were highlighted by some feature, be it Haar, HOG, SURF, or any wavelet. The learning algorithm should construct such a model, according to which it will be able to analyze a new image and decide which of the objects is in the image.
How it's done? Each of the test images is a point in the feature space. Its coordinates are the weight of each of the features in the image. Let our signs be: "Presence of eyes", "Presence of nose", "Presence of two hands", "Presence of ears", itd ... All these signs we will highlight with our existing detectors, who are trained in body parts, similar to human For a person in such a space, the point [1; 1; 1; 1; ..] will be correct. For the monkey, the point [1; 0; 1; 0 ...] for the horse [1; 0; 0; 0 ...]. The qualifier is trained in a sample of examples. But not all the photographs stood out hands, others did not have eyes, and on the third, the monkey had a human nose because of a classifier error. A trained person classifier automatically splits the feature space so as to say: if the first sign is in the range 0.5 <x <1, the second is 0.7 <y <1, etc., then this is a person.
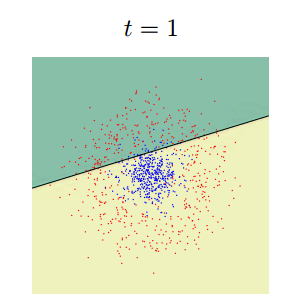
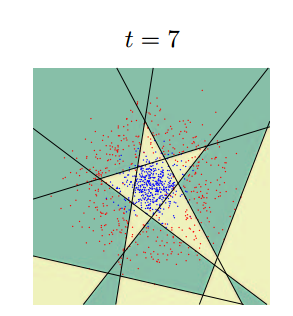
Essentially, the purpose of the classifier is to draw in the feature space the regions characteristic for the objects of classification. This is how a consistent approximation to the answer for one of the classifiers (AdaBoost) in two-dimensional space will look like:

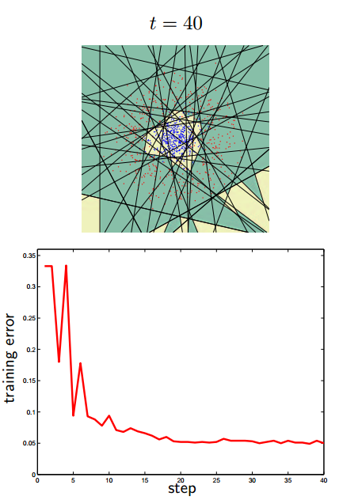
There are so many classifiers. Each of them works better in some of its task. The task of selecting a classifier for a specific task is in many ways an art. Here are a few beautiful pictures on the subject.
Let us analyze by example the simplest case of classification, when the space of a sign is one-dimensional, and we need to separate 2 classes. The situation is more common than can be introduced: for example, when you need to distinguish between two signals, or to compare the pattern with the sample. Suppose we have a training set. This results in an image where the X axis is the measure of similarity, and the Y axis is the number of events with such a measure. When the desired object looks like itself, the left Gaussian is obtained.When not like - right. A value of X = 0.4 divides the samples so that the wrong decision minimizes the likelihood of making any wrong decision. The search for such a separator is the task of classification.

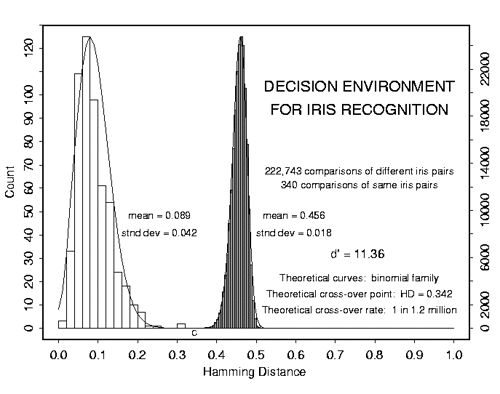
A little remark. Not always the optimal criterion that minimizes the error will be. The next graph is the graph of the real iris recognition system. For such a system, the criterion is chosen such as to minimize the probability of a false pass of an unauthorized person to the object. This probability is called the “first kind error”, “false alarm probability”, “false alarm”. In the English literature "False Access Rate".
There are many algorithms. Even a lot. If you want to know in detail about each of them, read the course of Vorontsov, the link to which is given above, and watch the lectures of Yandyks. To say which algorithm is better for which task is often impossible in advance. Here I will try to identify the main ones, which in 90% will help a beginner with the first task and the implementation of which in your programming language you will reliably find on the Internet.
k-means ( 1 , 2 , 3 ) is one of the simplest learning algorithms. Of course, it is mainly for clustering, but it is also possible to train through it. It works in a situation where groups of objects have a well-spaced center of mass and do not have a large intersection.
AdaBoost ( 1 ,2 , 3 ) AdaBusta is one of the most common classifiers. For example, the Haar cascade is built exactly on it. Usually used when binary classification is needed, but nothing prevents to train for more classes.
SVM ( 1 , 2 , 3 , 4 ) One of the most powerful classifiers, having many implementations. In principle, on the learning tasks that I encountered, he worked in the same way as Adabust. It is considered fast enough, but its learning is more complicated than that of Adabusta and the choice of the correct core is required.
There are also neural networks and regression. But in order to briefly classify them and show how they differ, we need an article much more than this.
________________________________________________
I hope I managed to make a cursory review of the methods used without immersion in math and description. Maybe it will help someone. Although, of course, the article is incomplete and there is not a word about working with stereo images, nor about the MNC with the Kalman filter, nor about the adaptive Bayesian approach.
If you like the article, I will try to make the second part with a selection of examples of how the existing ImageRecognition problems are solved.
What to read?
1) Once I really liked the book “Digital Image Processing” by B. Yana, which was written simply and clearly, but at the same time almost all the mathematics was given. Good for getting familiar with existing methods.
2) The classic of the genre is R Gonzalez, R. Woods "Digital Image Processing". For some reason she gave me more difficult than the first. Much less mathematics, but more methods and pictures.
3) “Processing and analysis of images in computer vision problems” - written on the basis of a course taught at one of the departments of PhysTech. A lot of methods and their detailed description. But in my opinion there are two big drawbacks in the book: the book is strongly focused on the software package that is attached to it, in the book too often the description of a simple method turns into a mathematical jungle from which it is difficult to take a block diagram of the method. But the authors have made a convenient site, where almost all the content is presented - wiki.technicalvision.ru
4) For some reason, it seems to me that a good book that structures and links the picture of the world that occurs during the occupation of Image Recognition and Machine Learning is “On the Intelligence” of Jeff Hawkins. There are no direct methods, but there are many thoughts to think about where direct image processing methods come from. When you read it, you understand that you have already seen the methods of the human brain, but in video processing tasks.
I have been writing some articles on Optical Recognition for a long time, so a couple of times a month various people write to me with questions on this topic. Sometimes it creates the feeling that you live with them in different worlds. On the one hand, you understand that a person is most likely a professional in a related topic, but he knows very little in OCR methods. And the most annoying thing is that he is trying to apply a method from a nearby area of knowledge, which is logical, but in Image Recognition does not work completely, but does not understand it and is very offended if he starts telling something from the very foundations. And considering that telling from the basics - a lot of time, which is often not there, is still sadder.
This article is designed so that a person who has never worked on image recognition methods, within 10-15 minutes, can create in his head a certain basic picture of the world, relevant to the subject, and understand in which direction to dig. Many of the methods described here are applicable to radar and audio processing.
I will start with a couple of principles that we always begin to tell a potential customer, or a person who wants to start practicing Optical Recognition:
- When solving a problem, always go from the simplest. It is much easier to hang an orange label on a person than to follow a person, highlighting him in cascades. It is much easier to take a camera with a higher resolution than to develop a superresolving algorithm.
- A rigorous formulation of the problem in optical recognition methods is orders of magnitude more important than in system programming problems: one extra word in the TOR can add 50% of the work.
- There are no universal solutions for recognition tasks. You can not make an algorithm that will simply "recognize any inscription." A sign on the street and a sheet of text are fundamentally different objects. Probably, you can make a general algorithm ( here is a good example from Google), but this will require the great work of a large team and consist of dozens of different subroutines.
- OpenCV is a bible in which there are many methods, and with the help of which 50% of almost any task can be solved, but OpenCV is only a small part of what can be done in reality. In one study, the conclusions were written: "The problem is not solved by OpenCV methods, therefore, it is unsolvable." Try to avoid this, not be lazy and soberly assess the current task from scratch every time, without using OpenCV templates.
It is very difficult to give some kind of universal advice, or tell you how to create some kind of structure around which you can build a solution to arbitrary computer vision tasks. The purpose of this article is to structure what can be used. I will try to break the existing methods into three groups. The first group is the pre-filtering and image preparation. The second group is the logical processing of filtering results. The third group is decision-making algorithms based on logical processing. The boundaries between the groups are very conditional. To solve a problem, it is not always necessary to apply methods from all groups, it is enough two, and sometimes even one.
The list of methods given here is not complete. I propose in the comments to add critical methods that I have not written and to assign 2-3 to each of the accompanying words.
Part 1. Filtering
In this group I put methods that allow you to highlight areas of interest in images, without analyzing them. Most of these methods apply a single transformation to all points in the image. At the filtering level, image analysis is not performed, but the points that pass filtering can be considered as areas with special characteristics.
')
Threshold binarization, histogram area selection
The simplest transformation is the binarization of the image on the threshold. For RGB images and grayscale images, the threshold is the color value. There are ideal problems in which such a transformation is sufficient. Suppose you need to automatically highlight items on a white sheet of paper:
The choice of the threshold by which binarization occurs largely determines the process of binarization itself. In this case, the image was binarized according to the average color. Usually, binarization is performed using an algorithm that adaptively selects a threshold. Such an algorithm can be the choice of expectation or mode . And you can choose the largest peak of the histogram.
Binarization can give very interesting results when working with histograms, including in a situation if we consider the image not in RGB, but in HSV . For example, segment the colors of interest. On this principle, it is possible to build both a tag detector and a human skin detector.
Classical filtering: Fourier, LPF, HPF
Classical filtering techniques from radar and signal processing can be successfully applied in a variety of Pattern Recognition tasks. The traditional method in radar, which is almost not used in images in its pure form, is the Fourier transform (more specifically, FFT ). One of the few exceptions in which the one-dimensional Fourier transform is used is image compression . For image analysis, one-dimensional transformation is usually not enough, you need to use a much more resource - intensive two - dimensional transformation .
Few people actually count it, usually, where it is much faster and easier to use a convolution of the region of interest with a ready-made filter tuned to high (HPF) or low (LPF) frequencies. This method, of course, does not allow for spectrum analysis, but in a particular video processing task, it is usually not the analysis that is needed, but the result.
The most simple examples of filters that implement the underscore of low frequencies ( Gaussian filter ) and high frequencies ( Filter Gabor ).
For each point of the image, a window is selected and multiplied with a filter of the same size. The result of such a convolution is a new point value. When implementing a low-pass filter and high-pass filter, images of this type are obtained:
Wavelets
But what if we use for the convolution of a signal with some arbitrary characteristic function? Then it will be called " Wavelet Transformation ". This definition of wavelets is not correct, but it has traditionally been established that in many teams the wavelet analysis is the search for an arbitrary pattern in an image using a convolution with a model of this pattern. There is a set of classical functions used in wavelet analysis. These include the Haar wavelet , Morlah wavelet, Mexican hat wavelet , etc. The Haar primitives, about which there were several of my past articles ( 1 , 2 ), refer to such functions for two-dimensional space.
Above are 4 examples of classic wavelets. 3-dimensional Haar wavelet, 2-dimensional Meyer wavelet, Mexican Hat wavelet, Dobeshi wavelet. A good example of the use of extended interpretation of wavelets is the problem of finding the glare in the eye, for which the wavelet is the glare itself:
Classic wavelets are usually used to compress images , or to classify them (described below).
Correlation
After such a free interpretation of wavelets, on my part, it is worth mentioning the correlation proper, which underlies them. When filtering images it is an indispensable tool. A classic application is the correlation of a video stream for finding shifts or optical flows. The simplest shear detector is also in some sense a difference correlator. Where the images do not correlate - there was movement.
Filtering features
An interesting class of filters is filtering functions. These are purely mathematical filters that allow you to detect a simple mathematical function in an image (direct, parabola, circle). An accumulating image is built, in which for each point of the original image a multitude of functions are generated that generate it. The most classical transformation is the Hough transformation for straight lines. In this transformation, for each point (x; y), the set of points (a; b) of the line y = ax + b, for which equality holds, is drawn. Beautiful pictures turn out:
(the first plus to the one who first finds the catch in the picture and that definition and explains it, the second plus to the one who first says what is shown here)
Hough Transformation allows you to find any parameterizable functions. For example a circle . There is a modified transformation that allows you to search for any shapes . This transformation is terribly fond of mathematics. But when processing images, it unfortunately does not always work. Very slow speed, very high sensitivity to binarization quality. Even in ideal situations, I preferred to use other methods.
An analogue of the Hough transform for straight lines is the Radon transform . It is calculated through the FFT, which gives a performance gain in a situation where there are a lot of points. In addition, it is possible to apply it to a non-binarized image.
Contour filtering
A separate class of filters - filtering boundaries and contours . Outlines are very useful when we want to move from working with an image to working with objects in this image. When an object is rather complicated, but well distinguished, then often the only way to work with it is to select its contours. There are a number of algorithms that solve the problem of filtering circuits:
The most commonly used is Kenny, who works well and has an implementation in OpenCV (Sobel is also there, but he is less interested in contours).
Other filters
Above are filters whose modifications help solve 80-90% of problems. But besides them there are more rare filters used in local problems. There are dozens of such filters, I will not give them all. Interesting are iterative filters (for example, the active model of appearance ), as well as a ridgelet and a transformation curvelet , which are a fusion of classical wavelet filtering and analysis in the radon transform field. The beamlet transform works beautifully on the border of the wavelet transform and logical analysis, allowing you to select the contours:
But these transformations are very specific and sharpened for rare tasks.
Part 2. Logical processing of filtering results
Filtering gives a set of data suitable for processing. But it is often impossible to simply take and use this data without processing it. In this section there will be several classical methods that allow you to move from an image to the properties of objects, or to the objects themselves.
Morphology
The transition from filtering to logic, in my opinion, are the methods of mathematical morphology ( 1 , 2 , 3 ). In fact, these are the simplest operations for building and eroding binary images. These methods allow you to remove noise from a binary image by increasing or decreasing existing elements. On the basis of mathematical morphology, there are contouring algorithms, but usually some kind of hybrid or combination algorithms are used.
Contour analysis
In the section on filtering algorithms for obtaining boundaries have already been mentioned. The resulting bounds are simply converted into contours. For the Kany algorithm, this happens automatically; for the other algorithms, additional binarization is required. You can get a contour for a binary algorithm, for example, a bug algorithm.
The contour is a unique feature of the object. Often this allows you to identify the object on the contour. There is a powerful mathematical tool to do this. The device is called contour analysis ( 1 , 2 ).
To be honest, I never once managed to apply contour analysis in real-world problems. Too perfect conditions are required. That border is not there, the noise is too much. But, if you need to recognize something in ideal conditions, then contour analysis is a great option. It works very fast, beautiful math and understandable logic.
Special points
Special points are unique characteristics of an object that allow you to map an object to itself or to similar classes of objects. There are several dozen ways to select such points. Some methods highlight specific points in adjacent frames, some through a long period of time and when lighting changes, some allow you to find special points that remain so even when the object turns. Let's start with the methods that allow you to find special points that are not so stable, but they are quickly calculated, and then we go in increasing complexity:
First grade. Singular points that are stable for seconds. Such points are used to lead the object between adjacent frames of video, or to reduce the image from neighboring cameras. These points include local maxima of the image, angles in the image (the best of the detectors, perhaps, Haris detector), points at which the dispersion maximums are reached, certain gradients, etc.
Second class. Special points that are stable when changing lighting and small movements of the object. Such points serve primarily for learning and the subsequent classification of object types. For example, a pedestrian classifier or a face classifier is a product of a system built on such points. Some of the previously mentioned wavelets may be the basis for such points. For example, Haar primitives, search for glare, search for other specific functions. These points are points found by the histogram method of directional gradients ( HOG ).
Third class. Stable points. I know only about two methods that give complete stability and about their modifications. This is SURF and SIFT . They allow you to find particular points even when you rotate the image. The calculation of such points is longer compared to other methods, but for a rather limited time. Unfortunately, these methods are patented. Although, in Russia, patent the algorithms nizya, so use for the domestic market.
Part 3. Training
This part of the story will be devoted to methods that do not work directly with the image, but which allow you to make decisions. These are mainly different methods of machine learning and decision making. Recently Yandyks laid out a course on this topic on Habr, there is a very good selection. Here it is in the text version. For serious study topics strongly recommend to see them. Here I will try to identify several basic methods used specifically in pattern recognition.
In 80% of situations, the essence of learning in the recognition problem is as follows:
There is a test sample on which there are several classes of objects. Let it be the presence / absence of a person in the photo. For each image there is a set of features that were highlighted by some feature, be it Haar, HOG, SURF, or any wavelet. The learning algorithm should construct such a model, according to which it will be able to analyze a new image and decide which of the objects is in the image.
How it's done? Each of the test images is a point in the feature space. Its coordinates are the weight of each of the features in the image. Let our signs be: "Presence of eyes", "Presence of nose", "Presence of two hands", "Presence of ears", itd ... All these signs we will highlight with our existing detectors, who are trained in body parts, similar to human For a person in such a space, the point [1; 1; 1; 1; ..] will be correct. For the monkey, the point [1; 0; 1; 0 ...] for the horse [1; 0; 0; 0 ...]. The qualifier is trained in a sample of examples. But not all the photographs stood out hands, others did not have eyes, and on the third, the monkey had a human nose because of a classifier error. A trained person classifier automatically splits the feature space so as to say: if the first sign is in the range 0.5 <x <1, the second is 0.7 <y <1, etc., then this is a person.
Essentially, the purpose of the classifier is to draw in the feature space the regions characteristic for the objects of classification. This is how a consistent approximation to the answer for one of the classifiers (AdaBoost) in two-dimensional space will look like:
There are so many classifiers. Each of them works better in some of its task. The task of selecting a classifier for a specific task is in many ways an art. Here are a few beautiful pictures on the subject.
Simple case, one dimensional separation
Let us analyze by example the simplest case of classification, when the space of a sign is one-dimensional, and we need to separate 2 classes. The situation is more common than can be introduced: for example, when you need to distinguish between two signals, or to compare the pattern with the sample. Suppose we have a training set. This results in an image where the X axis is the measure of similarity, and the Y axis is the number of events with such a measure. When the desired object looks like itself, the left Gaussian is obtained.When not like - right. A value of X = 0.4 divides the samples so that the wrong decision minimizes the likelihood of making any wrong decision. The search for such a separator is the task of classification.
A little remark. Not always the optimal criterion that minimizes the error will be. The next graph is the graph of the real iris recognition system. For such a system, the criterion is chosen such as to minimize the probability of a false pass of an unauthorized person to the object. This probability is called the “first kind error”, “false alarm probability”, “false alarm”. In the English literature "False Access Rate".
What to do if there are more than two measurements?
There are many algorithms. Even a lot. If you want to know in detail about each of them, read the course of Vorontsov, the link to which is given above, and watch the lectures of Yandyks. To say which algorithm is better for which task is often impossible in advance. Here I will try to identify the main ones, which in 90% will help a beginner with the first task and the implementation of which in your programming language you will reliably find on the Internet.
k-means ( 1 , 2 , 3 ) is one of the simplest learning algorithms. Of course, it is mainly for clustering, but it is also possible to train through it. It works in a situation where groups of objects have a well-spaced center of mass and do not have a large intersection.
AdaBoost ( 1 ,2 , 3 ) AdaBusta is one of the most common classifiers. For example, the Haar cascade is built exactly on it. Usually used when binary classification is needed, but nothing prevents to train for more classes.
SVM ( 1 , 2 , 3 , 4 ) One of the most powerful classifiers, having many implementations. In principle, on the learning tasks that I encountered, he worked in the same way as Adabust. It is considered fast enough, but its learning is more complicated than that of Adabusta and the choice of the correct core is required.
There are also neural networks and regression. But in order to briefly classify them and show how they differ, we need an article much more than this.
________________________________________________
I hope I managed to make a cursory review of the methods used without immersion in math and description. Maybe it will help someone. Although, of course, the article is incomplete and there is not a word about working with stereo images, nor about the MNC with the Kalman filter, nor about the adaptive Bayesian approach.
If you like the article, I will try to make the second part with a selection of examples of how the existing ImageRecognition problems are solved.
And finally
What to read?
1) Once I really liked the book “Digital Image Processing” by B. Yana, which was written simply and clearly, but at the same time almost all the mathematics was given. Good for getting familiar with existing methods.
2) The classic of the genre is R Gonzalez, R. Woods "Digital Image Processing". For some reason she gave me more difficult than the first. Much less mathematics, but more methods and pictures.
3) “Processing and analysis of images in computer vision problems” - written on the basis of a course taught at one of the departments of PhysTech. A lot of methods and their detailed description. But in my opinion there are two big drawbacks in the book: the book is strongly focused on the software package that is attached to it, in the book too often the description of a simple method turns into a mathematical jungle from which it is difficult to take a block diagram of the method. But the authors have made a convenient site, where almost all the content is presented - wiki.technicalvision.ru
4) For some reason, it seems to me that a good book that structures and links the picture of the world that occurs during the occupation of Image Recognition and Machine Learning is “On the Intelligence” of Jeff Hawkins. There are no direct methods, but there are many thoughts to think about where direct image processing methods come from. When you read it, you understand that you have already seen the methods of the human brain, but in video processing tasks.
Source: https://habr.com/ru/post/208090/
All Articles