How Data Mining Company Lives: Tasks and Research
Hi, Habr!
Finally got around. It's time to tell what our company DM Labs is doing in the field of data analysis, in addition to educational activities (we already wrote about it 1 ).
Over the past year, we began to work closely with the fortiss Robotics Institute at the Technical University of Munich (TUM) (jointly teach robots not to kill people), launched a prototype anti-fraud system, participated in international conferences on machine learning, and, most importantly, were able to form a strong team of analysts .
')
Now DM Labs combines three areas: a research laboratory, the development of ready-made commercial solutions and training. In today's post we will tell about them in more detail, summarize the past year and share our goals for the future.
By launching the educational direction, we wanted to create a program for the exchange of knowledge between young professionals and experts and, as already mentioned, to help form the Data Science community in Russia.
During this year we managed to release the first stream of students and are now running a program for the second set.
The curriculum has changed a lot, but we realized that the three elements that underlie our teaching philosophy will not change:
In addition to continuing the curriculum, in 2014 we will conduct even more different educational initiatives:
After the launch of the training direction, the project activity and the new direction of data mining Projects became a logical continuation, because with the help of machine learning you can solve many interesting problems in various areas:
Now our team is working on various commercial projects, including the task of analyzing the traffic of financial transactions, the detection of anomalies based on the log files of web services, the prediction of the return of users, etc.
At TechCrunch Moscow, we outlined how we can help a company become data-driven.
About specific case studies and our product, antifraud system, we will write in the following articles.
Design work is good, but the soul of a data scientist always asks for more: I want the models to be more accurate, and the algorithms to work faster, and the area of their application grows. Thus, the third direction was created - Data Mining R & D.
Now we are working on various tasks related to Gradient Boosting Machines [ 1 , 2 , 3 ]. These algorithms are actively used by companies such as Yahoo !, Yandex in their Matrixnet, Microsoft, and others . If we explain “on fingers”, then the main idea of the algorithm is to build a set of decision trees so that with each new tree the total output of the algorithm becomes more and more accurate. For example, as in this picture:
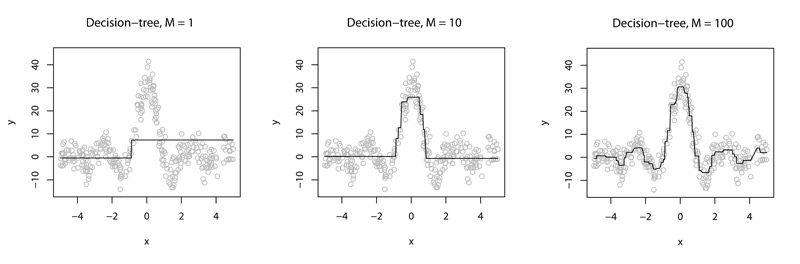
It seems simple, but there is a lot of room for creativity: how to make it so that in order to achieve the same accuracy fewer trees are required (how to reduce their number)? What will happen if you do a “deep” ensemble? Or an ensemble of semi- ”deep” gizmos? "
The second important area of work is Data Fusion methods. The idea is to use data from different areas: text, video, audio, graphs, sensors, as well as their various combinations as part of solving one task. If we run the same GBM algorithm head-on for all data, the distributions will be too different, and the number of signs would be unreasonably large. In general, a description of the reasons why this will not work is a topic worthy of a separate article.
An example that we faced in this area was the task of determining financial risks. For this task, quantitative information about quotes from the stock exchange is usually used - looking at the volatility of company stock prices, one can quite accurately predict the risks for the next year. However, if we also take into account the information from the annual accounting reports of companies, this accuracy can be improved.
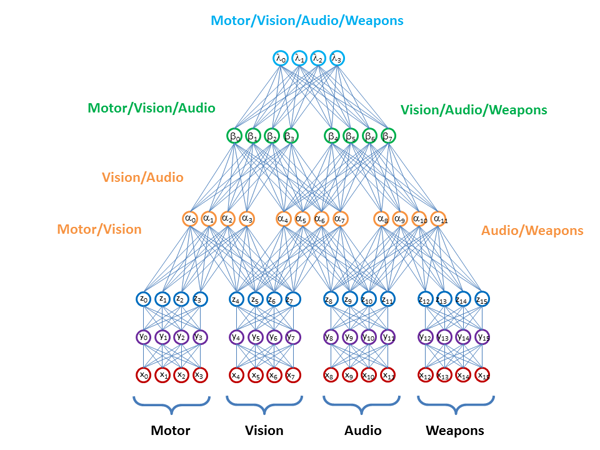
The main question is how to do it most effectively in order to use all the information contained in the data? How to sew models built on different data spaces? Stitch only models or some intermediate layers with representation, similar to how it is proposed to do in D-Wave:
Our research does not end there. For example, we are very concerned about the questions:
It was a year rich in events, new good people and interesting challenges. We hope that 2014 will bring a lot of great ideas and even more power to bring them to life and write about each article on Habr. Yes, we already want to tell so much now that we decided to conduct a small survey
Over the past year, we began to work closely with the fortiss Robotics Institute at the Technical University of Munich (TUM) (jointly teach robots not to kill people), launched a prototype anti-fraud system, participated in international conferences on machine learning, and, most importantly, were able to form a strong team of analysts .
')
Now DM Labs combines three areas: a research laboratory, the development of ready-made commercial solutions and training. In today's post we will tell about them in more detail, summarize the past year and share our goals for the future.
Training
By launching the educational direction, we wanted to create a program for the exchange of knowledge between young professionals and experts and, as already mentioned, to help form the Data Science community in Russia.
During this year we managed to release the first stream of students and are now running a program for the second set.
| 2013 | 2013/2014 | |
|---|---|---|
| Students | 18 | 25 |
| Experts | nineteen | 30+ |
Program  | Data Mining in Industry | Data Mining in Industry + individual courses on R, Machine Learning, Big Data |
| Lectures | 60 hours | Data Mining in Industry: 70+ hours, Courses: 80+ hours |
| Companies | IBM, EMC, Siemens, fortiss, etc. | all the same + Delloite, Accenture, Odnoklassniki, etc. |
The curriculum has changed a lot, but we realized that the three elements that underlie our teaching philosophy will not change:
- Communication with experts.
- Practice. Students take part in kaggle competitions, solve problems that are set for them by experts from different fields ( 1 , 2 and 3 ).
- Proactive. We are trying to interest students in sharing their knowledge with each other and themselves organizing internal seminars on various topics, including those related not only to data analysis.
In addition to continuing the curriculum, in 2014 we will conduct even more different educational initiatives:
- Data Mining Sauna - for Christmas holidays, we invited students and experts to a private contact zoo near St. Petersburg to share ideas with each other and discuss research (we will write more about this event soon).
- Now we are preparing a hackathon to analyze social networks in St. Petersburg.
- In the coming year, we would also very much like to organize a conference on Data Mining.
Projects
After the launch of the training direction, the project activity and the new direction of data mining Projects became a logical continuation, because with the help of machine learning you can solve many interesting problems in various areas:
Now our team is working on various commercial projects, including the task of analyzing the traffic of financial transactions, the detection of anomalies based on the log files of web services, the prediction of the return of users, etc.
At TechCrunch Moscow, we outlined how we can help a company become data-driven.
About specific case studies and our product, antifraud system, we will write in the following articles.
Research
Design work is good, but the soul of a data scientist always asks for more: I want the models to be more accurate, and the algorithms to work faster, and the area of their application grows. Thus, the third direction was created - Data Mining R & D.
Now we are working on various tasks related to Gradient Boosting Machines [ 1 , 2 , 3 ]. These algorithms are actively used by companies such as Yahoo !, Yandex in their Matrixnet, Microsoft, and others . If we explain “on fingers”, then the main idea of the algorithm is to build a set of decision trees so that with each new tree the total output of the algorithm becomes more and more accurate. For example, as in this picture:
It seems simple, but there is a lot of room for creativity: how to make it so that in order to achieve the same accuracy fewer trees are required (how to reduce their number)? What will happen if you do a “deep” ensemble? Or an ensemble of semi- ”deep” gizmos? "
The second important area of work is Data Fusion methods. The idea is to use data from different areas: text, video, audio, graphs, sensors, as well as their various combinations as part of solving one task. If we run the same GBM algorithm head-on for all data, the distributions will be too different, and the number of signs would be unreasonably large. In general, a description of the reasons why this will not work is a topic worthy of a separate article.
An example that we faced in this area was the task of determining financial risks. For this task, quantitative information about quotes from the stock exchange is usually used - looking at the volatility of company stock prices, one can quite accurately predict the risks for the next year. However, if we also take into account the information from the annual accounting reports of companies, this accuracy can be improved.
The main question is how to do it most effectively in order to use all the information contained in the data? How to sew models built on different data spaces? Stitch only models or some intermediate layers with representation, similar to how it is proposed to do in D-Wave:
Our research does not end there. For example, we are very concerned about the questions:
- How to select significant signs when there are a lot of them: tens and hundreds of thousands?
- How to look for anomalies in large dimensions?
- How to run the GBM algorithm on a billion points? And on trillion? This is rather a common question for those gradient methods where SGD and minibatch are not applied (a similar story with ICA )
Finally
It was a year rich in events, new good people and interesting challenges. We hope that 2014 will bring a lot of great ideas and even more power to bring them to life and write about each article on Habr. Yes, we already want to tell so much now that we decided to conduct a small survey
Source: https://habr.com/ru/post/207538/
All Articles