Google Photon. Data processing at the speed of light *
Photon is a scalable, fault tolerant and geographically distributed system for processing streaming data in real time . The system is Google’s internal product and is used in the Google Advertising System. Research paper [5], describing the basic principles and architecture of Photon, was presented at the ACM SIGMOD scientific conference in 2013.
Paper [5] stated that the peak load on a system can be millions of events per minute with an average end-to-end delay of less than 10 seconds .
* 'The speed of light' in the title is ablatant lie hyperbole.

Photon solves a very specific problem: you need to connect (perform the join operation) two continuous data streams in real time. So in the already mentioned Google Advertising System, one of these streams is a search flow, the other is a flow of clicks through advertisements.
')
Photon is a geographically distributed system and is automatically capable of handling cases of infrastructure degradation , including data center failure. In geo-distributed systems, it is extremely difficult to guarantee message delivery time (primarily due to network delays), so Photon assumes that the streaming data being processed may not be time-ordered.
Used services: Google File System , PaxosDB, TrueTime.
In [5], an explanation of how Photon works is in the following context: the user entered a search query ( query ) at time t1 and passed on an advertisement ( click ) at time t2. In the same context, unless otherwise specified, this article will explain how Photon works.
The principle of joining threads ( join ) is taken from the world of RDBMS: the query stream has a unique identifier query_id (conditionally Primary Key), the click thread has a unique identifier click_id and includes some query_id (conventionally Foreign Key). Merging threads happens by query_id.
The next important point: a situation where one click event is counted twice, or, conversely, is not counted, will lead, respectively, either to lawsuits from advertisers, or to lost profits from Google. Hence, it is imperative to provide at-most-once event processing semantics.
Another requirement is to provide near-exact semantics, i.e. so that most of the events were calculated in near real-time mode. Events that are not counted in real-time should still be counted - exactly-once semantics.
In addition, for Photon instances working in different data centers, you need a synchronized state (or rather only the critical state, since the entire state is too “expensive” to replicate between the DCs). So synchronized critical state chose event_id (in fact, click_id). Critical state is stored in the IdRegistry structure - in-memory key-value storage, built on the basis of PaxosDB .
The latter, PaxosDB, implements the Paxos algorithm to support fault tolerance and data consistency .
Worker nodes interact with the IdRegistry client-server model . Architecturally, the interaction of Worker nodes with IdRegistry is a network interaction with an asynchronous message queue .
So clients - Worker nodes - send to IdRegistry only 1) a search request for event_id (if event_id is found, then it has already been processed) and 2) a request to insert event_id (for the case if in step 1 event_id was not found). On the server side, requests are received by RPC handlers whose purpose is to queue the request. From the queue requests takes a special process Registry Thread (singleton), which will write to PaxosDB and initialize the callback to the client.
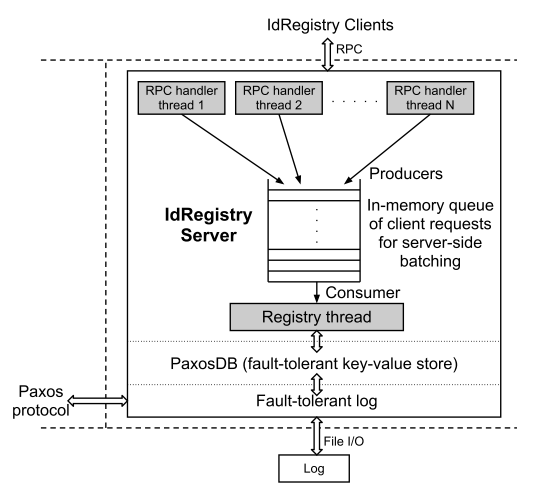
Source of illustration [5, Figure 3]
Since IdRegistry replica occurs between geographic regions, network delays between which can reach 100 ms [5], this automatically limits the throughput of IdRegistry to ten consecutive transactions (event_id commits) per second, while the requirement for IdRegistry was 10K transactions per second . But it is also impossible to abandon geo-distribution and / or synchronous replication of critical state with support for resolving conflicts in a quorum.
Then Google engineers introduced 2 more practices familiar to many of the world of DBMS:
Batch sending of requests has a reverse side: in addition to mixing semantics (Photon processes data in real-time , and some of its parts work in batching mode), the batching script is not suitable for systems with a small number of events — the time taken to collect a full package can take a significant interval of time.
Within one DC, the following components are distinguished:
The algorithm for adding an entry is shown below:
Source of illustration [5, Figure 5]
The interaction between the DC:

Source of illustration [5, Figure 6]
We omit the algorithm for adding an entry to Joined Click Logs, noting that in systems with frequent network interaction, using retry-policies and asynchronous calls is an extremely effective way to increase the reliability and scalability of the system, respectively, without complicating the overall algorithm of operation.
The same techniques - retry-policy and asynchronous call - and took advantage of the creators of Photon.
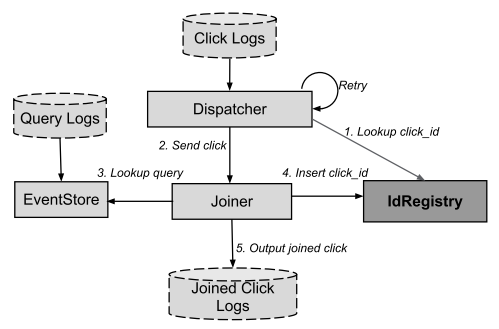
Dispatcher - the process responsible for reading click logs - clicks. These logs are stored in GFS and grow over time continuously.
In order to effectively read them, Dispatcher periodically scans the directory with logs and identifies new files and / or modified ones, saves the state of each file in the local GFS cell. This state contains a list of files and a shift from the beginning of the file for data that has already been processed. Thus, when a file is changed, the latter is read not from the beginning, but from the point at which the processing ended in the past reading.
New data are processed in parallel by several processes, each of which shares its state, which allows different processes to work without conflicts on different parts of the same file .
Joiner is an implementation of a stateless RPC server accepting requests from a Dispatcher. Accepting a request from Dispatcher, Joiner extracts click_id and query_id from it. Then by query_id tries to get information from the EventStore.
If successful, the EventStore returns a search query matching the click to be processed.
Next, the Joiner removes duplicates (using IdRegistry) and generates an output log containing the joined (joined) values - Joined Click Logs.
If Dispatcher used retry-logic to handle failures, then Google engineers added another trick to Joiner. Reception works in cases where the Joiner sent a request to the IdRegistry; the latter has successfully registered click_id, but due to network problems, or due to a timeout, Joiner did not receive an answer about the success from IdRegistry.
For this, every “commit click_id” request that a Joiner sends to IdRegistry is associated with a special token. The token is stored in IdRegistry. If the answer from IdRegistry was not received, the Joiner repeats the request with the same token as in the previous request, and IdRegistry easily "understands" that the incoming request was already processed.
An EventStore is a service that accepts query_id as input and returns the corresponding query (information about a search query).
Photon for EventStore has 2 implementations:
Since Photon works in near real-time mode, we can guarantee with confidence that the probability of finding a query in the CacheEventStore (provided that the query gets into it with a minimum delay) will be very high, and the CacheEventStore itself can store events for relatively small time interval.
The researching paper [5] provides statistics that only 10% of requests "pass by" the in-memory cache and, accordingly, are processed by the LogsEventStore.
At the time of publication [5], i.e. in 2013, IdRegistry replicas were deployed in 5 data centers in 3 geographic regions (east, west coast, and Mid-West North America), with network delays between regions exceeding 100 ms . Other Photon components are Dispatchers, Joiners, etc. - deployed in 2 geographic regions on the west and east coast of the United States.
In each of the DCs, the number of IdRegistry-shards exceeds a hundred, and the number of instances of the Dispatcher and Joiner processes exceeds thousands.
Photon processes billions of joined-events per day, including during peak periods millions of events per minute . The volume of clicks-logs processed in 24 hours exceeds terabytes, and the volume of daily query-logs is estimated in dozens of terabytes.
90% of all events are processed (join in one stream) in the first 7 seconds after they appear.
Source of illustration [5, Figure 7]. More graphs with statistics (slides 24-30).
In the section “Basic Principles” I already mentioned that Photon is a system with exactly-once (at-least-once and at-most-once) support and near-exact semantics, i.e. guarantees that any event recorded in the logs will be processed once and only once, and with a high probability in the mode close to real time.
PaxosDB implements at-most-once semantics , while retry-policies Dispatcher provide at-least-once semantics .
To handle near-real-time mode (near-exact semantics), Photon architecture incorporates the following principles:
In the conclusion of research paper [5], Google engineers shared good practices and their plans for the future.
The principles are not new, but for completeness and completeness of the article, I will list them:
The plans of the creators of Photontake over the world reduce end-to-end delays due to the fact that servers that generate threads clicks and queries will directly send RPC requests to Joiners (now Dispatcher is “waiting” for these events). It is also planned to “teach” Photon to merge several data streams (in the current implementation, Photon can merge only 2 streams).
We wish the Photon creators good luck in the implementation of their plans! And we are waiting for new research paper!
[5] Rajagopal Ananthanarayanan, Venkatesh Basker, Sumit Das, Ashish Gupta, Haifeng Jiang, Tianhao Qiu, et al. Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams , 2013.
** A complete list of sources used to prepare the cycle.
This is the final article in a series of articles on the Google platform .

Happy New Year, everyone! Good luck and perseverance!
Dmitry Petukhov
MCP,PhD Student , IT Zombies,
caffeinated man instead of red blood cells.
Paper [5] stated that the peak load on a system can be millions of events per minute with an average end-to-end delay of less than 10 seconds .
* 'The speed of light' in the title is a
Photon solves a very specific problem: you need to connect (perform the join operation) two continuous data streams in real time. So in the already mentioned Google Advertising System, one of these streams is a search flow, the other is a flow of clicks through advertisements.
')
Photon is a geographically distributed system and is automatically capable of handling cases of infrastructure degradation , including data center failure. In geo-distributed systems, it is extremely difficult to guarantee message delivery time (primarily due to network delays), so Photon assumes that the streaming data being processed may not be time-ordered.
Used services: Google File System , PaxosDB, TrueTime.
Basic principles
In [5], an explanation of how Photon works is in the following context: the user entered a search query ( query ) at time t1 and passed on an advertisement ( click ) at time t2. In the same context, unless otherwise specified, this article will explain how Photon works.
The principle of joining threads ( join ) is taken from the world of RDBMS: the query stream has a unique identifier query_id (conditionally Primary Key), the click thread has a unique identifier click_id and includes some query_id (conventionally Foreign Key). Merging threads happens by query_id.
The next important point: a situation where one click event is counted twice, or, conversely, is not counted, will lead, respectively, either to lawsuits from advertisers, or to lost profits from Google. Hence, it is imperative to provide at-most-once event processing semantics.
Another requirement is to provide near-exact semantics, i.e. so that most of the events were calculated in near real-time mode. Events that are not counted in real-time should still be counted - exactly-once semantics.
In addition, for Photon instances working in different data centers, you need a synchronized state (or rather only the critical state, since the entire state is too “expensive” to replicate between the DCs). So synchronized critical state chose event_id (in fact, click_id). Critical state is stored in the IdRegistry structure - in-memory key-value storage, built on the basis of PaxosDB .
The latter, PaxosDB, implements the Paxos algorithm to support fault tolerance and data consistency .
Customer interaction
Worker nodes interact with the IdRegistry client-server model . Architecturally, the interaction of Worker nodes with IdRegistry is a network interaction with an asynchronous message queue .
So clients - Worker nodes - send to IdRegistry only 1) a search request for event_id (if event_id is found, then it has already been processed) and 2) a request to insert event_id (for the case if in step 1 event_id was not found). On the server side, requests are received by RPC handlers whose purpose is to queue the request. From the queue requests takes a special process Registry Thread (singleton), which will write to PaxosDB and initialize the callback to the client.
Source of illustration [5, Figure 3]
Scalability
Since IdRegistry replica occurs between geographic regions, network delays between which can reach 100 ms [5], this automatically limits the throughput of IdRegistry to ten consecutive transactions (event_id commits) per second, while the requirement for IdRegistry was 10K transactions per second . But it is also impossible to abandon geo-distribution and / or synchronous replication of critical state with support for resolving conflicts in a quorum.
Then Google engineers introduced 2 more practices familiar to many of the world of DBMS:
- batching requests ( batching ) - “useful” information on event_id takes less than 100 bytes; requests are sent in batches to the IdRegistry Client. There, they enter in-memory into the queue, which is disassembled by the Registry Thread process, which is responsible for resolving conflicts related to the fact that there can be more than one item with the same event_id in the queue.
- timestamp-based sharding (+ dynamic resharding ) - all event_id are divided by ranges; transactions for each of the ranges are sent to a specific IdRegistry.
Batch sending of requests has a reverse side: in addition to mixing semantics (Photon processes data in real-time , and some of its parts work in batching mode), the batching script is not suitable for systems with a small number of events — the time taken to collect a full package can take a significant interval of time.
Components
Within one DC, the following components are distinguished:
- EventStore - provides effective search queries (search query stream in the search engine);
- Dispatcher - reading ad clicks stream (clicks) and feed (feed) read by Joiner;
- Joiner is a stateless RPC server that accepts requests from Dispatcher, processes them and joins the queries and clicks streams.
The algorithm for adding an entry is shown below:
Source of illustration [5, Figure 5]
The interaction between the DC:
Source of illustration [5, Figure 6]
We omit the algorithm for adding an entry to Joined Click Logs, noting that in systems with frequent network interaction, using retry-policies and asynchronous calls is an extremely effective way to increase the reliability and scalability of the system, respectively, without complicating the overall algorithm of operation.
The same techniques - retry-policy and asynchronous call - and took advantage of the creators of Photon.
Repeat Query Logic
As previously mentioned, the situation when click_id is received for processing, and the associated query_id is not - not an exception. All due to the fact that it is not necessary that the stream of search queries will be processed by that moment, the code will begin to process the stream of clicks on contextual advertising.
To reliably provide at-least-once processing semantics for all click_id, logic was introduced, which uses the repetition logic for the case described above. To avoid system throttling by itself, the time between failed queries increases exponentially backoff algorithm. After a number of unsuccessful requests or after a certain time, click is marked as "unjoinable".
To reliably provide at-least-once processing semantics for all click_id, logic was introduced, which uses the repetition logic for the case described above. To avoid system throttling by itself, the time between failed queries increases exponentially backoff algorithm. After a number of unsuccessful requests or after a certain time, click is marked as "unjoinable".
Dispatcher
Dispatcher - the process responsible for reading click logs - clicks. These logs are stored in GFS and grow over time continuously.
In order to effectively read them, Dispatcher periodically scans the directory with logs and identifies new files and / or modified ones, saves the state of each file in the local GFS cell. This state contains a list of files and a shift from the beginning of the file for data that has already been processed. Thus, when a file is changed, the latter is read not from the beginning, but from the point at which the processing ended in the past reading.
New data are processed in parallel by several processes, each of which shares its state, which allows different processes to work without conflicts on different parts of the same file .
Joiner
Joiner is an implementation of a stateless RPC server accepting requests from a Dispatcher. Accepting a request from Dispatcher, Joiner extracts click_id and query_id from it. Then by query_id tries to get information from the EventStore.
If successful, the EventStore returns a search query matching the click to be processed.
Next, the Joiner removes duplicates (using IdRegistry) and generates an output log containing the joined (joined) values - Joined Click Logs.
If Dispatcher used retry-logic to handle failures, then Google engineers added another trick to Joiner. Reception works in cases where the Joiner sent a request to the IdRegistry; the latter has successfully registered click_id, but due to network problems, or due to a timeout, Joiner did not receive an answer about the success from IdRegistry.
For this, every “commit click_id” request that a Joiner sends to IdRegistry is associated with a special token. The token is stored in IdRegistry. If the answer from IdRegistry was not received, the Joiner repeats the request with the same token as in the previous request, and IdRegistry easily "understands" that the incoming request was already processed.
Generation of unique tokens / Event_Id
Another interesting technique that should be noted is a way to generate unique event_id.
Clearly, guaranteed uniqueness for event_id is an extremely important requirement for Photon to work. At the same time, the algorithm for generating a unique value within several DCs can take an extremely significant time and amount of CPU resources.
Google engineers have found an elegant solution: event_id can be uniquely identified using the IP of the server (ServerIP), the process Id (ProcessId) and the timestamp (Timestamp) of the node on which this event was generated.
As in the case of Spanner , the TrueTime API is used to minimize inconsistency of timestamps on different nodes.
Clearly, guaranteed uniqueness for event_id is an extremely important requirement for Photon to work. At the same time, the algorithm for generating a unique value within several DCs can take an extremely significant time and amount of CPU resources.
Google engineers have found an elegant solution: event_id can be uniquely identified using the IP of the server (ServerIP), the process Id (ProcessId) and the timestamp (Timestamp) of the node on which this event was generated.
As in the case of Spanner , the TrueTime API is used to minimize inconsistency of timestamps on different nodes.
Eventstore
An EventStore is a service that accepts query_id as input and returns the corresponding query (information about a search query).
Photon for EventStore has 2 implementations:
- CacheEventStore - distributed [sharding by hash (query_id)] in-memory storage to which full information on the query is stored. Thus, the response to the request does not require reading from the disk.
- LogsEventStore is the key-value store, where key is query_id, and value is the name of the log file that stores information on the corresponding query, and the offset (byte offset) in this file.
Since Photon works in near real-time mode, we can guarantee with confidence that the probability of finding a query in the CacheEventStore (provided that the query gets into it with a minimum delay) will be very high, and the CacheEventStore itself can store events for relatively small time interval.
The researching paper [5] provides statistics that only 10% of requests "pass by" the in-memory cache and, accordingly, are processed by the LogsEventStore.
results
Configuration
At the time of publication [5], i.e. in 2013, IdRegistry replicas were deployed in 5 data centers in 3 geographic regions (east, west coast, and Mid-West North America), with network delays between regions exceeding 100 ms . Other Photon components are Dispatchers, Joiners, etc. - deployed in 2 geographic regions on the west and east coast of the United States.
In each of the DCs, the number of IdRegistry-shards exceeds a hundred, and the number of instances of the Dispatcher and Joiner processes exceeds thousands.
Performance
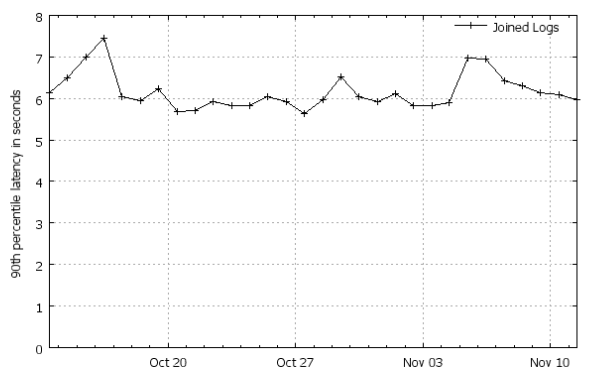
Photon processes billions of joined-events per day, including during peak periods millions of events per minute . The volume of clicks-logs processed in 24 hours exceeds terabytes, and the volume of daily query-logs is estimated in dozens of terabytes.
90% of all events are processed (join in one stream) in the first 7 seconds after they appear.
Source of illustration [5, Figure 7]. More graphs with statistics (slides 24-30).
Simple principles of complex systems
In the section “Basic Principles” I already mentioned that Photon is a system with exactly-once (at-least-once and at-most-once) support and near-exact semantics, i.e. guarantees that any event recorded in the logs will be processed once and only once, and with a high probability in the mode close to real time.
PaxosDB implements at-most-once semantics , while retry-policies Dispatcher provide at-least-once semantics .
To handle near-real-time mode (near-exact semantics), Photon architecture incorporates the following principles:
- Scalability:
- Required sharding for non-relational repositories;
- All worker sites are stateless.
- Required sharding for non-relational repositories;
- Latency:
- RPC communication wherever possible;
- Transfer of data to RAM wherever possible.
- RPC communication wherever possible;
In custody
In the conclusion of research paper [5], Google engineers shared good practices and their plans for the future.
The principles are not new, but for completeness and completeness of the article, I will list them:
- Use RPC communication instead of writing to disk . Requests that go beyond the physical boundaries of the node must be executed asynchronously, and the client must always expect that it will not receive a response on timeout or due to network problems.
- Minimize the critical state of the system, as it, in general, has to be replicated synchronously. Ideally, the system’s critical critical state should include only system metadata.
- Sharding is a friend of scalability :) But Google engineers improved this idea by making time-based sharding.
The plans of the creators of Photon
We wish the Photon creators good luck in the implementation of their plans! And we are waiting for new research paper!
List of sources**
[5] Rajagopal Ananthanarayanan, Venkatesh Basker, Sumit Das, Ashish Gupta, Haifeng Jiang, Tianhao Qiu, et al. Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams , 2013.
** A complete list of sources used to prepare the cycle.
Post change history
Chanset 01 [ 12/27/2013 ].
Changed the illustration of the article. Thanks for the new illustration TheRaven
Changed the illustration of the article. Thanks for the new illustration TheRaven
Offtopic
This is the final article in a series of articles on the Google platform .
Happy New Year, everyone! Good luck and perseverance!
Dmitry Petukhov
MCP,
caffeinated man instead of red blood cells.
Source: https://habr.com/ru/post/207348/
All Articles