Why do we all need SAT and all these P-NPs (part one)
SAT is already so good that it leads the mind in order
Lomonosov ( original )
Introduction
On Habré already many articles devoted to the problem of P vs. NP and the problem of the feasibility of logical formulas (SATisfiability problem). However, most of them do not answer some of the most important questions. Why is this problem really important to us? What happens if they decide it? Where does all this apply? And why is it necessary to have at least a general idea of what it is about?
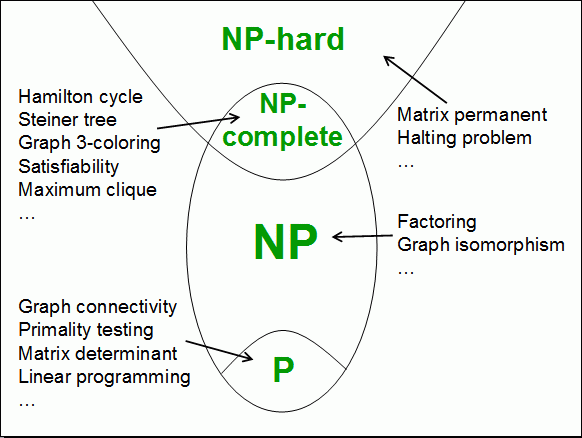
If we analyze in detail the most notable works on Habré on this topic [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ], then we note that on the one hand, people with knowledge of computational complexity will not be able to learn anything fundamentally new these articles. On the other hand, these articles are still not publicly available. The illustration from the title clearly demonstrates the problem: to those who were not clear, nothing was clear from it, and those who had already heard about it did not need it.
')
This article has two goals: the first is to give a general idea of the problem and answer the question of why we should be aware of this task (the first part), the second is to provide material for “growth” that will be of interest to people interested in topics, as well as It may be useful to study the topic in the future (second part).
Article structure
For ease of reading and navigation provide a brief overview of the contents of the article.
- Generally available material
- Why is SAT important to all of us? Applications / Interesting NP tasks and SAT
- The history of SAT and NP-completeness
- "Intuitive Definition" SAT, NP and P
- What happens if ... P! = NP, P = NP
- 2-SAT polynomial: algorithm and intuition
- A challenge to think about
- Specialized material (see in the following series)
- Formal definition. Asymmetry of the solvability problem for NP and CoNP
- 2 + p-SAT polynomial?
- The dependence of the complexity of the number of variables
- I decided to P vs. NP, what should I do? Where should i write?
- Inexpressibility theorems: why the article by Romanov [ 3 ] expects reject
- About modern SAT solvers
- What to read?
- A challenge to think about
Disclaimer
This work is a general educational material and is intended solely for familiarization with SAT issues. Computational complexity and SAT are not the main directions of my research, but lie in the adjacent scientific field, so in case of doubt, always refer to the specified source.
Generally available material
Why is SAT important to all of us? Applications
In order to answer this question it is necessary first of all to understand which mathematical problems affect our everyday actual life without our knowledge and how these tasks are related to the SAT.
We give a list of tasks that occur around us and say how they relate to the SAT.
- First of all, we mention the RSA cryptographic algorithm , which is used to ensure the security of banking transactions, as well as to create a secure connection. The RSA algorithm can be “hacked” using SAT.
- Many recommender systems (for example, as part of Netflix) use a Boolean decomposition algorithm to recommend content. The optimal decomposition of such matrices can be found using SAT.
- The task of optimal distribution of tasks among processors can be solved with the help of SAT. A large number of planning tasks are reduced to SAT, for example, open shop scheduling , where tasks (jobs) must go through certain stages (performed by certain workers) and it is necessary to minimize the total processing time of all tasks.
- NASA verifies its software specifications and its hardware models using model checking methods directly related to the SAT.
- The popular k-means clustering method (k-means method) can be solved with the help of SAT.
- Most of the interesting tasks associated with graphs (for example, in social networks, a graph is a friendship between users) is the search for the largest community, where everyone is friendly with each other, the search for the longest path and many other tasks on the graphs can be solved using the SAT. The task of the life of the Moscow region (and not only): to make a schedule of garbage trucks in such a way that they traveled all the garbage collection points once in a minimum time. A large number of tasks in logistics is reduced to the task of SAT.
- Even the knapsack problem can be solved with the help of the SAT. The task is to have a backpack of a fixed size, to collect in it items of the greatest value (knowing the size of all items in advance).
- Many video games can be solved with the help of SAT (and even Mario !) Also puzzle Sudoku and, attention, Minesweeper can be solved with the help of SAT!
- The tasks of serializing transaction history in databases can be solved using SAT.
Visualization of tasks solved with the help of SAT (due to Bart Selman, taken from here )

What does it mean “can be solved” and what does NP have to do with it
Simply put, if we have an effective solution to the SAT problem, then we can effectively solve all the above tasks. What exactly is meant by efficiency depends on a specific task, but here we will assume that the work time is acceptable for the user (we can devote a couple of days to calculations for making the school schedule for the semester, and for the clustering method, we would like to get the result in interactive mode ). And for many of the above problems, the reverse is also true; if we can solve them effectively, then we can solve SAT effectively (this is called NP-completeness - this definition is informal, but enough for a common understanding).
All these tasks lie in the NP class - later we will describe the class in more detail, but now we should note that if the effective solution of the SAT problem is known, then we can effectively solve any problem in the NP class. In other words, SAT is a class representative task; it is “most difficult” in its class and allows solving all other tasks in the NP.
The history of SAT and NP-completeness
NP-completeness
The theory of computational complexity , in which languages and functions are allocated to different classes according to the amount of time and memory necessary for their calculations, was born from the theory of computability (ie, the works of the 30s of Gödel, Church and Turing) when Hartmanis, Sternc, Lewis (1965 ) offered one of the first similar classifications of functions (original works: here and here ).
The concept of NP-completeness developed in the 1960s-1970s independently in the USSR and the USA (Edmonds, Levin, Yablonsky et al.). In 1971, Stephen Cook formulated the P vs. hypothesis. Np. The theorem that SAT is a “universal problem” for the class NP and allows solving any problem in this class (NP-completeness) was independently proved by Leonid Levin (1973) and Stephen Cook, and is called the Levin-Cook theorem . In 1982, Cook will receive a Turing Award for this job.
In 1972, Karp publishes Reducibility among combinatorial problems , a list showing that the SAT is far from the only interesting problem in the NP and a huge number of problems lies in the NP and is equivalent to the SAT. In 1985 Karp will receive a Turing Award for this job.
In 1974, Fagin will show that NP is closely related to classical logic, namely, that NP is equivalent to existential logical structures of second order ( Fagin's theorem ).
In 1975, Baker, Jill, Solovey received the first fundamental meta-result on the unsolvability of the P vs. task. NP using regularized methods i. this is the first result showing that a whole class of methods cannot answer the question of equality P vs. NP (more on this is written here ).
In 1979, Gary and Johnson will write Computing Machines and Unresolved Problems , one of the most comprehensive sources of information on NP-completeness and a detailed catalog of problems. Despite the fact that some theoretical results are currently considered obsolete, this is one of the most fundamental works in the field of computational complexity.
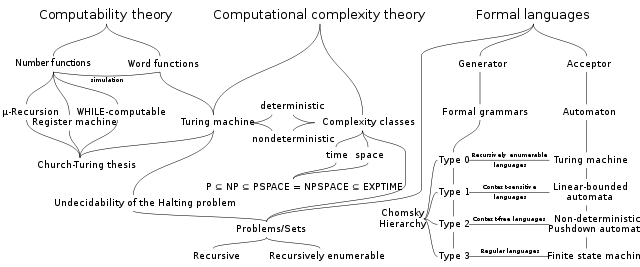
Visualization of the relationship between formal languages, theories of computational complexity and the theory of computation ( hence ):
A very brief history of SAT-solvers
In the 1960s, Davis and Putman began to apply classically deductive (to put it simply, methods to prove theorems) methods to solve the SAT ( original work ).
In 1962, Davis, Putnam, Logeman, Loveland proposed the DPLL algorithm based on search with the return and distribution of deterministic calculations (unit-propagation). To put it simply, the algorithm assumed the value of some variable to be equal to truth and calculated all the deterministic consequences of such a solution and repeated until it found a solution. This algorithm has served as the basis for many SAT solvers for decades.
In 1992, Selman, Levesque and Mitchell proposed a local search method in a GSAT article. GSAT - means Greedy SAT, local as it decides on the value of variables based on local information only. The algorithm began with an arbitrary assignment of variable values and changed the value of a variable if it gave the greatest increase in the executed sentences. Subsequently, local search methods in a wide variety of variations were integrated into most SAT solvers — in 1999 Hegler Hus led an extensive study of local stochastic search and its applications in his PhD thesis (the work is available here ).
In 1996, Marques-Silva and Sakalah suggested an algorithm called Conflict-Driven-Clause-Learning ( CDCL ), like DPLL, he decides on the value of variables and performs deterministic calculations, on the other hand he keeps in memory the implication graph and remembers some combinations that do not lead to a solution and can effectively avoid “useless” solutions and effectively cut off the solution space containing the conflict previously established.
From 2001, Locality Based Search SAT-solvers began to emerge, effectively selecting subspaces for a full search based on local information, such as BerkMin (Berkley-Minsk) and many others.
"Intuitive Definition" SAT, NP and P
SAT
We begin by defining what propositional logic is : it is a set of variables {x, y, z, ...} and a set of connectors {and, or, - (not), →}. Each variable can be either "false" or "true." Connectors are defined standardly:
- x and y is true if and only if (for brevity we write iff - if and only if) x is true and y is true, the classic "AND"
- x or y is true iff at least one of the variables x \ y is true, the classic "OR"
- -x true iff x false, classic negation
- x → y is false iff x is true, and y is false - let's look at an example:
“If it was raining, the grass is wet”
A statement is false if and only if the rain was (x true) and the grass is still dry (y is false).
Formula F is a syntactically correct set of variables and connectors, i.e., →, and, or connect variables or other formulas, (not) stands before a variable or formula. Example, F = (x → (y or z)) and (z → -x).
It is said that the formula F is satisfiable (SAT), iff its variables can be assigned the values "true" \ "false" (we call this function I from the English I nterpretation), so that F is true. For brevity, we write I (F) = "true."
Any propositional formula F can be reduced to the form CNF (conjunctive normal form), i.e. be represented as
F '= c 1 and c 2 and ... c n
where c i is (x or y or z), and x, y, z are variables or their negations.
Example F = (x or -y or -z) and (-x or -y or h) and (z or h).
More information about this conversion is written here (in order for each sentence to contain no more than three variables, you will need to introduce additional variables, but these are only technical details).
In this form, when the formula has the form described above, the task is called 3-SAT, emphasizing the fact that each sentence c i contains no more than three variables or their negations.
The formulation of the 3-SAT task is as follows:
Given: 3-CNF Propositional Formula F
Find:: function I , assigning the value "true" \ "false" to all variables, such that I (F) = "true"
class P
P is also PTIME — problems solvable in polynomial time, this means that the number of steps of the algorithm in a given class grows no more than some polynomial from the input data. More about various algorithms and complexity analysis in PTIME has already been written on Habré [ 9 , 10 , 11 , 12 , 13 ].
For illustration, here’s a simple example: bubble sorting algorithm ( pseudocode from wiki)
procedure bubbleSort( A : list of sortable items ) n = length(A) repeat swapped = false for i = 1 to n-1 inclusive do if A[i-1] > A[i] then swap(A[i-1], A[i]) swapped = true end if end for n = n - 1 until not swapped end procedure The input parameter is an array of numbers to sort. We are interested in the growth of time depending on the growth of the array length, i.e. time dependence of TIME on n. Note that each iteration of the repeat loop performs no more than 3 * n steps and sets at least one array element to the right place. This means that the repeat loop is executed no more than n times. This means that the number of operations (it’s TIME) grows as a certain square of the array length (and the linear term in “n = length (A)”), i.e.
TIME (n) = a * n 2 + b * n + C
In other words, the running time of the algorithm is limited by a certain polynomial in n, in this case we say that the running time of the algorithm does not grow faster than the square of the number of elements and write it using the Big-O entry
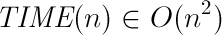
NP class
NP stands for nondeterministic polynomial time. Very often it is mistakenly called non-polynomial time, a joke was born on this occasion:
To divide algorithms into polynomial and non-polynomial, it is about how to divide the universe into bananas and non-bananas.
In this article, we are not interested in the formal definition of NP (this will be in the specialized material), but we consider the intuitive representation of the class NP. The very nature and internal mechanisms of NP follow the so-called guess-and-check method. Those. the solution search space is exponential (large enough to eliminate the possibility of iteration), and checking the solution is a simple task. You can consider NP as a class of problems in which you need to find a solution (“guess” - guess part) among a large number of options, and then verify its correctness (check part).
From the point of view of the SAT, the solution space is all possible sets of variable values, if we have k different variables in the formula, then we have 2 k possible “interpretations” of the formula, i.e. search space I exponentially. However, if we "guessed" I , then we can verify the truth of the formula in polynomial time.
What happens if P! = NP
Nothing will happen, only someone will get a million dollars .
What happens if P = NP
There are two news: good and bad.
Good ones. We will very quickly solve a bunch of optimization tasks, tasks for graphs, make schedules, assemble puzzles, check various properties of databases, and also effectively test the performance of NASA specifications.
The bad. All modern cryptography collapses, and with it, the banking system hits. People will start writing bots for Mario.
2-SAT in P.
Consider an interesting variation of the SAT, in which each clause is limited to two variables. Hereinafter, the author greatly simplifies everything to facilitate the perception of the material.
Given : F - formula of the form c 1 and c 2 and c 3 ... and c n ,
where c i has the form (x or y) and x, y are variables or their negations, i.e. x is some variable v or -v.
Find : function I , assigning the value "true" \ "false" to all variables, such that I (F) = "true"
Statement : I exist a polynomial algorithm P, such that if the function I exists, then P (F) = I , and otherwise, P (F) = {}.
(*) function I is not unique if it exists and P returns some function I (in books on the theory of algorithms and complexity, everything will be the same written in formal language, but these details are irrelevant for perceiving the general idea of why 2-SAT is polynomial )
Sketch of evidence:
To begin with, we transform the original formula using the following equality:
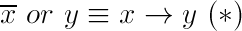
You can check it with a truth table. The intuition behind this rule is as follows:
“If it was raining, the grass is wet” (x → y, x - it was raining, y - grass is wet)
This means that if the grass is dry (not wet: y is false), then there was definitely no rain (x is false).
If the grass is wet, then either the rain was (x true, in a sense, x "explains" why y is true), or there was no rain (x false), on an intuitive level, we mean that there is another reason due to which y true (z - the neighbor watered the lawn and therefore the grass is wet).
We transform F using (*) to the form c ' 1 and c' 2 ... and c ' n where c' i has the form (x → y), x, y are variables or their negations. As a result, F is a graph of implications. An example of a similar graph below:
c 1 = If it was raining, the grass is wet.
c 2 = If a neighbor is watering the lawn, the grass is wet.
c 3 = If the grass is wet, weeds grow well.
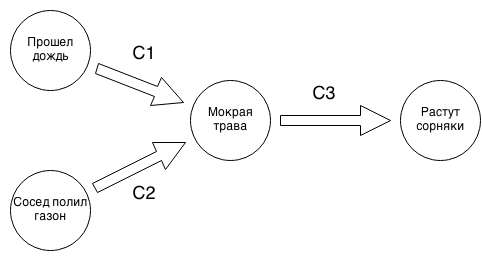
We see that if in the graph of implications coming out of some vertex v (for example, there was rain), it is impossible to reach the vertex -v (there was no rain), then the system of implications is consistent. Intuition is as follows: if we make some assumption, for example, that there was rain, we immediately conclude that the grass is wet and weeds grow (it remains only to choose whether the lawn was watered by the neighbor) and we do not get a contradiction, then we have part of function I , in particular deciding that it was raining, we got the values for “wet grass” and “weeds grow well”, we are left to decide on the meaning “neighbor watered the lawn”.
How many such decisions need to be made? No more than n is the number of sentences. How many operations do you need to make when making one decision? For each solution, we need to bypass the edges of the graph no more than once, that is, perform no more than n operations per solution. This means that no more than n 2 operations need to be performed to find I. ■
The task "to think"
This task may require additional study and literature search.
Trivial SAT Solution
ConditionEach propositional formula F = c 1 and c 2 and c 3 and c n can be brought to the disjunctive normal form (DNF), that is, to the form F '= c' 1 or c ' 2 ... or c' k , where c ' i has the form (x and y and z), x, y, z are variables or their negations. For example, by consistently applying the rules of De Morgan (reference) and disclosing parentheses.
For F ', there is a trivial algorithm for searching for function I. It is necessary that at least one of c' i is true. Let's write a simple pseudocode solving problem:
#Input: F — propositional formula in disjunctive normal form (DNF) #Output: {SAT, UNSAT} for each c in F do if c is SAT: return SAT return UNSAT For each sentence (clause) c i, the search algorithm I is also trivial, if the sentence c i does not contain some variable v and its negation simultaneously, then c i is feasible (SAT).
Total : we get the trivial algorithm for checking the formula for feasibility
Find : where is the error?
Links and sources
The picture in the introduction is taken from
Computational Complexity and Anthropic Principle Scott Aaronson
Slides
Why SAT Scales: Phase Transition Phenomena & Back Doors to Complexity Courses of Bart Selman Cornell University.
Slides based on the article:
2 + P-SAT: Relation of typical phase transition (Monasson, Remi; Zecchina, Riccardo; Kirkpatrick, Scott; Selman, Bart; and Troyansky, Lidror.)
Other articles can be found here.
More information about the history of NP can be found here:
The Question of Michael Sipser
P versus NP by Elvira Mayordomo
More about SAT-solver'ah:
SAT Solvers: A Condensed History
Understanding Modern SAT Solvers - by Armin Biere, perhaps the most famous developer of SAT Solvers in the world. Donald Knut, who is now writing “The Art of Computer Programming: Volume 4B, Pre-fascicle 6A Satisfiability,” says he is consulting with him on many issues.
Towards SAT Solvers
Material from Habra:
[1] Why I do not believe in simple algorithms for NP-complete problems
[2] A little more about P and NP
[3] An open letter to scientists and the reference implementation of the Romanov algorithm for the NP-complete 3-SP problem.
[4] Published evidence of P ≠ NP?
[5] P = NP? The most important unsolved problem of theoretical computer science.
[6] Theoretical computer science at the Academic University
[7] Top-10 results in the field of algorithms for 2012
[8] It has been proven that Super Mario is an NP-complete challenge.
[9] Introduction to the analysis of the complexity of algorithms (part 1)
[10] Introduction to the analysis of the complexity of algorithms (part 2)
[11] Introduction to the analysis of the complexity of algorithms (part 3)
[12] Introduction to the analysis of the complexity of algorithms (part 4)
[13] Know the complexity of algorithms.
Source: https://habr.com/ru/post/207112/
All Articles