Lock-free data structures. Inside RCU

In this article, I will continue to familiarize the community with the technicians who provide writing of lock-free containers, advertise (along the way, I hope, not too obtrusively) my library libcds .
It will be a question of one more technique of safe release of memory for lock-free containers - RCU. This technique differs significantly from the previously considered a la Hazard Pointer algorithms.
Read - Copy Update (RCU) is a synchronization technique designed for “almost read-only,” that is, rarely modifiable, data structures. Typical examples of such a structure are map and set — in which most of the operations are search, that is, reading data. It is believed that for a typical map, more than 90% of the called operations are key searches, so it is important that the search operation be the fastest; In principle, search synchronization is not needed - in the absence of writers, readers can work in parallel. RCU provides the least overhead just for read operations.
')
Where did the name Read - Copy Update come from? Initially the idea was very simple: there is some rarely changeable data structure. If we need to change it, then we make a copy of it and make a change - add or delete data - in the copy. At the same time, parallel readers work with the original, unchanged structure. At some safe moment in time when there are no readers, we can replace the data structure with a modified copy. As a result, all subsequent readers will see the changes made by the writer.
The creator and active popularizer of RCU technology is Paul McKenney. He heads a whole school of "RCU lovers", from which many well-known scientists in the field of lock-free and unconventional synchronization schemes have emerged, and he is also "the main RCU" in the Linux kernel (Linux-kernel RCU maintainer) and the author of several works on RCU .
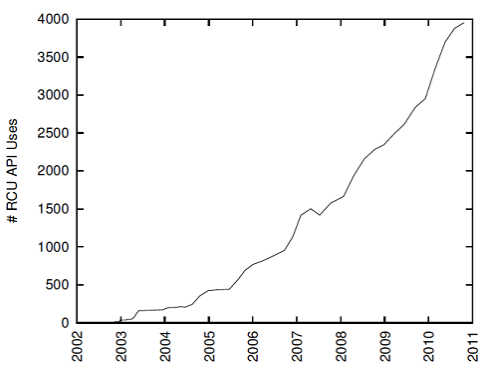
RCU was introduced into the Linux kernel in 2002, and since then it has grown more and more into kernel code, see the figure to the right. For a long time, it was positioned as a synchronization technique for the core of the operating system. Since the kernel has full control over all threads, both user and system, it is quite simple in the kernel to determine that a safe point in time for replacing data with a modified copy. But we are interested in the application of RCU, is it possible? Before answering this question, let's take a closer look at the RCU theory and terminology used in it.
General description RCU
The above description of the RCU idea is very simplistic. As we know, having atomic operations, we can not make a copy of the data, but change the data structure “on the fly” in parallel with its reading. Then the “reader” becomes a stream that performs any operation, except for removing an element from the data structure. A writer is a stream that removes something from a structure. Deletion should be done at the time when no one “stepped” on the data to be deleted, otherwise we will get a bunch of difficult-to-find problems - from ABA-problems to memory corruption. The RCU solves all these problems, and in a way that is different from the Hazard Pointers scheme discussed earlier.
RCU readers run in the read-side critical section. When entering such a critical section, the reader calls the function
rcu_read_lock() , on exit - rcu_read_unlock() . These are very lightweight functions, with virtually no effect on performance; in the Linux kernel, they weigh nothing at all (zero-overhead).If the flow is not in the critical reading section, then the flow is said to be at rest (quiescent state, quiescent-state). Any period of time in which each stream was at least once in a quiescent-state is called a grace period . Each critical reading section that began before the grace period must end before the grace period ends. Each grace period is guaranteed to be finite, since any critical reading section is finite (it is understood that the number of threads is finite, as well as that we are good programmers and avoid endless loops, as well as the collapse of the thread).
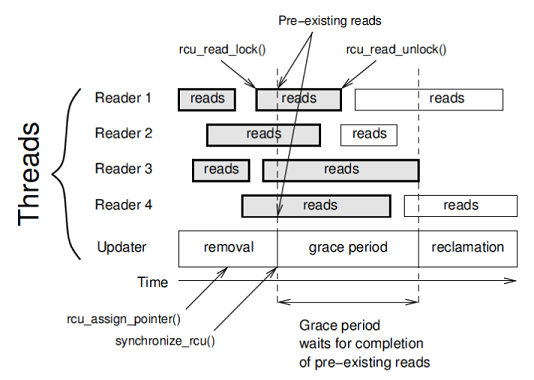
A stream writer deleting an element from a data structure excludes the element from the structure and then waits for the end of the grace period. The end of the grace-period means that no reader has access to the element to be deleted (see the figure, the “reads” rectangles on it are critical read sections). Therefore, a stream writer can safely physically remove an item.
The deletion is performed in two stages: the first stage, “removal”, atomically removes the element from the data structure, but does not produce a physical free of memory. Instead, the writer declares the beginning of the grace-period by calling the special primitive
synchronize_rcu() and waits for it to end. A deleted item can be accessed only by those readers who have declared their critical reading section in parallel with the writer (in the figure such sections are highlighted in gray). By definition, all such readers will finish their work before the end of the grace-period. At the end of the grace-period, that is, when all critical reading sections initiated or active during the grace-period are completed, the second stage of deletion begins - “reclamation” - that is, the physical deletion of memory under the element.As you can see, the RCU synchronization technique is quite simple. The question remains - how to determine the end of the grace-period in the user code? The original RCU is heavily honed to the Linux kernel, where it is much easier to determine, since we have full control over all threads. For the user space-code, the approaches of the original RCU are not applicable.
User-space RCU
The decision was given in 2009 by M.Desnoyers, a representative of the P. McKenney school, in his dissertation , Chapter 6 of which is called: User-Level Implementations of RCU.
M.Desnoyers offers 3 user-space RCU (URCU) solutions:
- Quiescent-State-Based Reclamation RCU is a very easy scheme for readers, but requiring streams outside the critical reading section to periodically declare "I am in a quiescent-state." This solution is not suitable for the general purpose library, which is libcds , so I will not consider it.
- A general-purpose user space RCU (General-Purpose URCU) is an algorithm suitable for a general implementation, which I will describe below.
- User-space RCU on signals (RCU via Signal Handling) is also an interesting algorithm based on signals (suitable for * nix-systems, inapplicable to Windows). Implemented in the libcds library, shows performance slightly worse than general-purpose RCU. I will not consider it in this article; I am interested in referring to M.Desnoyers thesis and to the source codes libcds.
General-Purpose URCU
M.Desnoyers so thoroughly and thoroughly parses the URCU algorithm that I can only follow it, changing only the name of some variables and functions to match the ones adopted in libcds.
In the URCU scheme, two variables are defined:
std::atomic<uint32_t> g_nGlobalCtl(1) ; struct thread_record { std::atomic<uint32_t> nThreadCtl; thread_record * pNext; thread_record(): nThreadCtl(0), pNext(nullptr) {} }; The
thread_record structure contains local data for the thread and links all such objects to the list of RCU streams.The
nThreadCtl 31 bits of nThreadCtl contain the URCU call nesting depth counter (yes, the URCU allows almost unlimited nesting of the critical reading sections), the high bit determines the identifier of the grace-period at the moment the stream enters the critical reading section. In the described scheme, only two identifiers for a grace-period are sufficient.The high-order bit of the
g_nGlobalCtl global variable contains the identifier of the current grace-period, the low-order bits serve to initialize the nThreadCtl per-thread variables and are not changed.The functions
access_lock and access_unlock respectively, are used to enter / exit the critical reading section: static uint32_t const c_nControlBit = 0x80000000; static uint32_t const c_nNestMask = c_nControlBit — 1; void access_lock() { thread_record * pRec = get_thread_record(); assert( pRec != nullptr ); uint32_t tmp = pRec->nThreadCtl.load( std::memory_order_relaxed ); if ( (tmp & c_nNestMask) == 0 ) { pRec->nThreadCtl.store(g_nGlobalCtl.load( std::memory_order_relaxed ), std::memory_order_relaxed ); std::thread_fence( std::memory_order_acquire ); } else pRec->nThreadCtl.fetch_add( 1, std::memory_order_relaxed ); } void access_unlock() { thread_record * pRec = get_thread_record(); assert( pRec != nullptr ); pRec->nThreadCtl.fetch_sub( 1, std::memory_order_release ); } When entering the critical section of the URCU, it is checked whether the call is nested or not. If the call is nested (that is, the counter in the lower 31 bits is not zero), the nesting counter is simply incremented. If the call is not nested, the variable
nThreadCtl current thread is assigned the value of the global variable g_nGlobalCtl ; it is thus marked that the input to the critical section was made in a certain grace-period (the high bit g_nGlobalCtl ), and the one in the low bits g_nGlobalCtl initializes the nesting counter of the current stream. At the first, outermost entrance to the critical section, a acquire-memory barrier is applied. It guarantees that the following code will not be moved (“optimized”) upstream of the barrier by either the processor or the compiler. This ensures the visibility of the current grace-period of the thread to all processors - if this order is disturbed, the URCU algorithm will be scattered. When entering the embedded critical section of the barrier is not required, since the current grace-period (high bit) does not change.When exiting the critical section (
access_unlock ), the nesting counter in the current thread's access_unlock simply decremented. The release semantics of the atomic operation is applied; in fact, the release-barrier is needed here only when exiting the uppermost critical section (when moving from 1 to 0 of the nesting counter); when exiting the nested critical section, there is enough relaxed semantics. The release barrier is required when resetting the counter, because when the nesting counter moves from 1 to 0, the declaration “the stream no longer uses RCU” actually occurs, that is, the exit from the grace period, which is critical for the URCU algorithm, is a violation of the order by the compiler or processor will lead to the inoperability of the algorithm. Recognizing the “0 - not 0” situations in the code will require a conditional transition, which is unlikely to add performance to the access_unlock function, and the basic pattern of using the critical sections of the URCU is without nesting, therefore, the release semantics is always used here.As you can see, the code from the readers is quite lightweight. Atomic read-write and thread-local data are used. Of course, this is not zero-overhead, but still much better than a mutex or CAS.
The flow writer must make sure that the grace period is completed before physically removing an element. The end of the grace period is one of two things:
- The
nThreadCtlbits (nesting counter) of thenThreadCtleach thread are zero, which means that the thread is not in the critical section of the URCU - The
nThreadCtlhigh bitnThreadCtlnot match the highg_nGlobalCtlhigh bit, which means that the reader entered the critical section after the beginning of the grace period
These conditions are verified by the following function:
bool check_grace_period( thread_record * pRec ) { uint32_t const v = pRec->nThreadCtl.load( std::memory_order_relaxed ); return (v & general_purpose_rcu::c_nNestMask) && ((( v ^ g_nGlobalCtl.load( std::memory_order_relaxed )) & ~c_nNestedMask )); } Before physical deletion, the writer calls the
synchronize function, which waits for the end of the current grace-period: std::mutex g_Mutex ; void synchronize() { std::atomic_thread_fence( std::memory_order_acquire ); { cds::lock::scoped_lock<std::mutex> sl( g_Mutex ); flip_and_wait(); flip_and_wait(); } std::atomic_thread_fence( std::memory_order_release ); } Here,
g_Mutex is a global mutex for the URCU algorithm (yes, yes! URCU is still a synchronization technique, so there is nowhere without the mutex). Thus, only one thread writer can go into synchronize . Do not forget that RCU is positioned for “almost read-only” data, so no particular push on this mutex is expected.The writer waits for the grace-period to end by calling the
flip_and_wait function: void flip_and_wait() { g_nGlobalCtl.fetch_xor( c_nControlBit, std::memory_order_seq_cst ); for (thread_record* pRec = g_ThreadList.head(std::memory_order_acquire); pRec!= nullptr; pRec = pRec->m_pNext ) { while ( check_grace_period( pRec )) { sleep( 10 ); // 10 CDS_COMPILER_RW_BARRIER ; } } } This function changes the grace-period identifier, which means the beginning of a new grace-period, with the help of the atomic
fetch_xor and waits (by calling check_grace_period ) until all check_grace_period threads have completed this new grace-period. In pseudocode, waiting occurs at a simple sleep of 10 milliseconds; in the real libcds code, a template parameter is used that defines the back-off strategy.Why
flip_and_wait writer call flip_and_wait twice? For clarification, consider the following sequence of actions with two threads A and B. Suppose that the call to flip_and_wait synchronize only one:access_lockA callsaccess_lock. In the body of this function, it is determined that the call is not nested, the globalg_nGlobalCtlis read, but so far not assigned to the variablenThreadCtlthread (everything is done in parallel, so this situation is quite acceptable)- Thread B calls
synchronize. The firstflip_and_wait, which changes the bit ID of the grace-period ing_nGlobalCtl. The current grace-period identifier becomes 1 - Since there is no one in the critical section of the URCU (remember that thread A has not yet managed to assign the value to its variable
nThreadCtl), thread B completessynchronize nThreadCtlA performs the assignment of its variablenThreadCtl. Recall that the stream read the old grace-period value of 0access_lockA terminatesaccess_lockand continues execution in the critical section.- Thread B calls
synchronizeagain (apparently, it wants to delete something again). Again, the current grace-period isg_nGlobalCtling_nGlobalCtl, so its identifier is now 0.
But flow A in the critical section that started earlier than B changed the grace-period! Violation of the semantics of URCU, which will eventually lead to the entire bouquet - from ABA to memory corruption. Recall:
synchronize is called by the writer before physically removing memory for an itemCalling
flip_and_wait twice, that is, twice waiting for the end of the grace-period, we solve the above problem, the cause of which is the competitive execution of threads.Another solution
You can, of course, solve this problem in a different way, if you use a counter instead of the bit ID of the grace-period. But here a problem arises, which we have already seen in the article about the tagged pointer algorithm, the counter is prone to overflow! For reliability, the counter should be 32-bit, then the overflow is not terrible for us. But such a counter makes it necessary to have a 64-bit atomic type on 32-bit platforms. This type either does not exist or it is rather inefficient. Or we will have to abandon the nesting of critical sections of the URCU, which is also not very convenient.
Therefore, we
Therefore, we
flip_and_wait dwell on a common solution with a bit as the identifier of the grace-period and calling two flip_and_waitImplementing URCU in libcds

The URCU algorithm described above is good for everyone, except that you need to call up a rather heavy
synchronize before each deletion. Is there any way to improve this?Yes, it is possible, with the same method as in the Hazard Pointer algorithm, using delayed deletion. Instead of deleting, we will put elements into some buffer. The
synchronize function will be called only when the buffer is full. Unlike the Hazard Pointer, in the URCU the buffer will be common to all threads (in general, you can make per-thread buffers, nothing interferes with this).Moreover, in order not to slow down the writer, who has a share to clean the buffer when it overflows, the buffer cleaning functionality, that is, the actual deletion, can be assigned to a separate thread.
The libcds library has five implementations of URCU, they all live in the
cds::urcu :general_instantis an implementation that exactly follows the described URCU algorithm: each deletion causes asynchronize, no buffering. If deleting is quite a frequent operation, that is, the structure is not too “almost read-only”, this implementation is rather slow.general_buffered- implementation with a general lock-free buffer of a predefined size. Dmitry Vyukov's queue is used as a lock-free buffer -cds::container::VyukovMPMCCycleQueue. The performance of such an implementation is comparable to the Hazard Pointergeneral_threadedis similar togeneral_buffered, but clearing buffers is done by the selected thread. Such an implementation is slightly inferior togeneral_buffereddue to additional synchronization with the selected stream, but does not slow down the writerssignal_bufferedis an analogue ofgeneral_buffered, but is based on the signal-handled URCU. Not for Windows systemssignal_threadedis the analogue ofgeneral_threadedfor signal-handled URCU. Also not for windows
Such an abundance of implementations of URCU raises the problem of writing container specializations under URCU. The fact is that the implementation of containers for the URCU scheme is significantly different from the implementation for the Hazard Pointer. Therefore, a separate specialization for URCU is required. I would like to have one specialization, not five.
To facilitate the writing of the specialization under the URCU, the wrapper class
cds::urcu::gc was introduced: template <typename RCUimpl> class gc; where
RCUimpl is one of the URCU implementations: general_instant , general_buffered , etc. With such a wrapper, the specialization for the URCU is easy to write and it will be the only one: template < class RCU, typename Key, typename Value, class Traits > class SplitListMap< cds::urcu::gc< RCU >, Key, Value, Traits > ... It should be noted that in libcds, the main function of the URCU algorithm during deletion is not
synchronize , but retire_ptr . This function places the item to be removed in the URCU buffer and at the right time (for example, when the buffer is full) calls synchronize . So an explicit call to synchronize not required, although it is valid. In addition, this solution unifies the interface URCU and Hazard Pointer.All the listed URCU algorithms are implemented in a typical libcds manner: for each there is a global singleton object, which is initialized by calling the wrapper object constructor
cds::urcu::gc<cds::urcu::general_buffered<> > at the beginning of main() after calling cds::Initialize() : #include <cds/init.h> //cds::Initialize cds::Terminate #include <cds/gc/general_buffered.h> // general_buffered URCU int main(int argc, char** argv) { // libcds cds::Initialize() ; { // general_buffered URCU cds::urcu::gc<cds::urcu::general_buffered<> > gbRCU ; // main thread lock-free // main thread // libcds cds::threading::Manager::attachThread() ; // , libcds // ... } // libcds cds::Terminate() ; } As with the Hazard Pointer schema, each thread using URCU containers must be initialized in a special way:
// cds::threading::Manager #include <cds/threading/model.h> int myThreadEntryPoint(void *) { // libcds cds::threading::Manager::attachThread() ; // // lock-free libcds ... // libcds cds::threading::Manager::detachThread() ; return 0; } Using libcds URCU containers is completely transparent: just declare a container object with a URCU gc, and that's it. All the specifics of working with the URCU is hidden inside the URCU container specialization. No external synchronization is required when accessing such a container.
UPD: Oops!
"No external synchronization is required" - this is something I got excited about.
In fact, some methods of some URCU containers require prior entry to the critical reading section. As a rule, these are methods for removing (retrieving) an element of a container. The URCU can provide us with the ability to return a pointer to an item found by key. This possibility is a rare exception in the lock-free world, where the return of the death pointer is usually similar, since an element can be removed at any time by a competing stream. But in order to work safely with the returned pointer to the item, we need to be in the critical reading section. So in this case, you should explicitly call
In the description of each method of the URCU container of the libcds library, it is noted whether this method should be called - in the critical section or not.
In fact, some methods of some URCU containers require prior entry to the critical reading section. As a rule, these are methods for removing (retrieving) an element of a container. The URCU can provide us with the ability to return a pointer to an item found by key. This possibility is a rare exception in the lock-free world, where the return of the death pointer is usually similar, since an element can be removed at any time by a competing stream. But in order to work safely with the returned pointer to the item, we need to be in the critical reading section. So in this case, you should explicitly call
access_lock before calling the container method, and after completing work with the pointer, access_unlock , and the best (exception-safe) technique will be to use scoped-lock in a separate code block.In the description of each method of the URCU container of the libcds library, it is noted whether this method should be called - in the critical section or not.
If you decide to make your own container class based on the Uccu implementation of libcds, you should study the internal structure of the URCU container containers in detail. In principle, there is nothing supernatural: when entering the method, call
gc::access_lock() , upon exit - gc::access_unlock() (here gc is one of the URCU implementations; for security exceptions it is better to use the scoped lock technique instead of calling functions) . The only subtle point is the removal of the element: the deletion method must also be included in the critical section of the reading, but the physical removal of the element by calling gc::retire_ptr must be done outside the critical section, otherwise deadlock is possible: the gc::retire_ptr method may trigger synchronize inside.Libcds defines URCU specializations for all set and map classes. URCU specializations for queue and stack containers are undefined; they are not “almost read-only” containers, so the URCU is not for them.
Source: https://habr.com/ru/post/206984/
All Articles