How to optimize Unicorn processes in a Ruby on Rails application

If you are a rails developer, then you have probably heard about Unicorn , an http server that can simultaneously handle many requests.
To ensure concurrency, Unicorn uses multiple process creation. Since The created (forked) processes are copies of each other, which means that a rails application must be thread-safe.
It's great because it's hard for us to be sure that our code is thread-safe. If we cannot be sure of this, then neither parallel web servers, such as Puma , nor even alternative implementations of Ruby implementing parallelism, such as JRuby and Rubinius , are out of the question.
')
Therefore, Unicorn provides concurrency to our rails applications even if they are not thread-safe. However, this requires a certain fee. Rails applications running on Unicorn require much more memory. Without paying any attention to the memory consumption of your application, you may eventually find out that your cloud server is overloaded.
In this article, we will look at several ways to use Unicorn parallelism, while controlling the amount of memory consumed.
Use Ruby 2.0!
If you are using Ruby 1.9, you should seriously consider switching to 2.0. To understand why, we need a little bit to figure out how to create processes.
Creating Processes and Copy-on-Write
When a child process is created, it is exactly a copy of its parent process. However, it is not necessary to immediately copy the physical memory. Being exact copies of each other, both child and parent processes can use the same physical memory. When the write process occurs, only then do we copy the child process to physical memory.
How does all this relate to Ruby 1.9 / 2.0 and Unicorn?
I remind you that Unicorn uses forks. In theory, the operating system can use Copy-on-Write. Unfortunately Ruby 1.9 makes this impossible. To be more precise, the implementation of garbage collection in Ruby 1.9 makes this impossible. In a simplified version, it looks like this - when the garbage collector in 1.9 is triggered, it is written, which makes Copy-on-Write useless.
Without going into details, suffice it to say that Ruby 2.0's garbage collector eliminates this, and we can use Copy-on-Write.
Unicorn configuration setup
Here are a few settings that we can set in config / unicorn.rb to squeeze the maximum performance out of Unicorn.
worker_processes
Sets the number of executables. It is important to know how much memory one process takes. This is necessary so that you can run the required number of workers without fear of overloading the RAM of your VPS.
timeout
Must be given a small number: usually between 15 and 30 seconds is appropriate. A relatively small value is set so that time-consuming requests do not delay the processing of other requests.
preload_app
Must be set to true - this reduces the startup time of the worker. Thanks to the Cope-on-Write application is loaded before the rest of the vorkers. However, there is an important nuance. We need to make sure that all sockets (including database connections) are properly closed and reopened. We do this using before_fork and after_fork.
Example:
before_fork do |server, worker| # Disconnect since the database connection will not carry over if defined? ActiveRecord::Base ActiveRecord::Base.connection.disconnect! end if defined?(Resque) Resque.redis.quit Rails.logger.info('Disconnected from Redis') end end after_fork do |server, worker| # Start up the database connection again in the worker if defined?(ActiveRecord::Base) ActiveRecord::Base.establish_connection end if defined?(Resque) Resque.redis = ENV['REDIS_URI'] Rails.logger.info('Connected to Redis') end end In this example, we make sure that the connections are closed and reopened when creating workers. In addition to database connections, we need to make sure that other connections requiring socket handling are handled the same way. The above is the configuration for Resque .
Limit memory consumption by Unicorn workers
Obviously, around not only rainbows but unicorns. (here was the author's pun 'rainbows and unicorns' - approx. translator). If there are memory leaks in your Rails application, Unicorn will make it all the worse.
Each of the created processes takes up memory, since is a copy of the rails application. Therefore, although having more workers means that our application can handle more incoming requests, we are limited by the physical amount of RAM in our system.
Memory leaks in a rails application are very simple. But even if we succeed in “plugging” all memory leaks, we still have to deal with a slightly imperfect garbage collector (I mean the implementation in MRI).
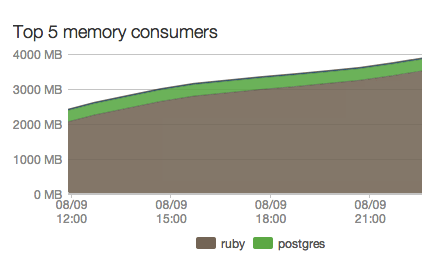
The image above shows a rails application with memory leaks launched by Unicorn.
Over time, memory consumption will continue to grow. The use of many workers will only accelerate the speed of memory consumption, until the moment when there is no free memory left. The application will crash, resulting in many unhappy users and customers.
It is important to note that this is not Unicorn’s fault. However, this is a problem that you will encounter sooner or later.
Meet the Unicorn Worker Killer
One of the easiest solutions I've come across is the unicorn-worker-killer gem.
Quote from README :
The unicorn-worker-killer gem allows you to automatically restart Unicorn workers based on:
1) the maximum number of requests and
2) the size of the memory occupied by the process (RSS), not processing the request.
This will greatly increase the stability of the site, allowing you to avoid unexpected memory shortages in the application nodes.
Please note that I assume that you already have Unicorn installed and running.
Step 1:
Add a unicorn-worker-killer to your gemfile lower than unicorn.
group :production do gem 'unicorn' gem 'unicorn-worker-killer' end Step 2:
Run bundle install.
Step 3:
Next comes the fun part. Open the file config.ru.
# --- Start of unicorn worker killer code --- if ENV['RAILS_ENV'] == 'production' require 'unicorn/worker_killer' max_request_min = 500 max_request_max = 600 # Max requests per worker use Unicorn::WorkerKiller::MaxRequests, max_request_min, max_request_max oom_min = (240) * (1024**2) oom_max = (260) * (1024**2) # Max memory size (RSS) per worker use Unicorn::WorkerKiller::Oom, oom_min, oom_max end # --- End of unicorn worker killer code --- require ::File.expand_path('../config/environment', __FILE__) run YourApp::Application At the beginning we check that we are in a production environment. If so, we execute the rest of the code.
unicorn-worker-killer kills workers based on two conditions: the maximum number of requests and the maximum memory consumed.
- maximum number of requests. In this example, the worker is killed if he processed from 500 to 600 requests. Note that spacing is used. This minimizes situations where more than one worker stops simultaneously.
- maximum consumed memory. Here the worker is killed if he takes from 240 to 260 MB of memory. The interval is needed here for the same reason as above.
Each application has its own memory requirements. You should have an overall assessment of the memory consumption of your application during normal operation. This way you can better estimate the minimum and maximum amount of memory that your workers should occupy.
If you have configured everything correctly during the deployment of your application, you will notice much less volatile memory behavior:
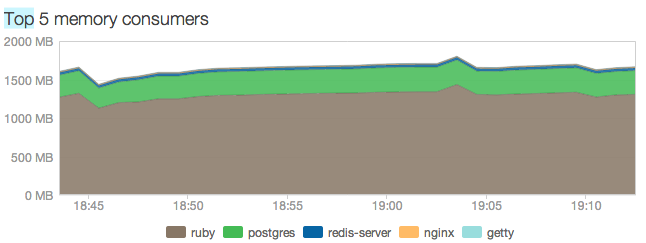
Pay attention to the excesses in the schedule - this heme does its job!
Conclusion
Unicorn provides your rails application with a painless way to achieve concurrency, regardless of whether it is thread safe or not. However, this is achieved along with an increase in memory consumption. Memory balancing is very important for the stability and performance of your application.
We looked at 3 ways to tune your Unicorn workers for maximum performance:
- Using Ruby 2.0 gives us an improved garbage collector that allows us to take advantage of copy-on-write.
- Configure various configuration options in config / unicorn.rb.
- Using unicorn-worker-killer to solve the problem of stopping workers when they get too bloated.
Resources
- A great explanation of how the garbage collector and copy-on-write work in Ruby 2.0 work.
- Complete list of Unicorn configuration options.
Source: https://habr.com/ru/post/206840/
All Articles