A simple interpreter from scratch in Python (translation) # 1

The thing that attracted me to study computer science was the compiler. I thought it was all magic, how can they even read my badly written code and compile it. When I completed the compiler course, I began to find this process very simple and straightforward.
Content
Simple interpreter from scratch in Python # 1
Simple interpreter from scratch in Python # 2
Simple interpreter from scratch in Python # 3
Simple interpreter from scratch in Python # 4
Simple interpreter from scratch in Python # 2
Simple interpreter from scratch in Python # 3
Simple interpreter from scratch in Python # 4
In this series of articles, I will try to capture some of this simplicity by writing a simple interpreter for the usual imperative language IMP (IMperative Language). The interpreter will be written in Python, because it is a simple and widely known language. Also, the python code is similar to pseudocode, and even if you do not know it [python], you will be able to understand the code. Parsing will be performed using a simple set of combinators written from scratch (I will tell you more in the next section). No additional libraries will be used except sys (for I / O), re (regular expressions in the lexer) and unittest (to test the performance of our crafts).
The essence of the IMP language
First of all, let's discuss why we will write an interpreter. IMP is an unrealistically simple language with the following constructs:
')
Assignments (all variables are global and only accept integer):
x := 1 Conditions:
if x = 1 then y := 2 else y := 3 end While loop:
while x < 10 do x := x + 1 end Compound operators (separated ; ):
x := 1; y := 2 This is just a toy language. But you can extend it to a utility level like Python or Lua. I just wanted to keep it as simple as I can.
And here is an example of a program that calculates factorial:
n := 5; p := 1; while n > 0 do p := p * n; n := n - 1 end The IMP language cannot read input data (input), i.e. At the beginning of the program you need to create all the necessary variables and assign values to them. Also, the language can not display anything: the interpreter will display the result at the end.
Interpreter structure
The interpreter core is nothing more than an intermediate representation (intermediate representation, IR). It will represent our IMP programs in memory. Since IMP is as simple as 3 rubles, IR will directly correspond to the syntax of the language; we will create a class for each syntax unit. Of course, in a more complex language, you would also like to use a semantic representation, which is much easier to analyze or execute.
Only three stages of interpretation:
- Parse source code symbols into tokens.
- Collect all tokens in an abstract syntax tree (abstract syntax tree, AST). AST is our IR.
- Execute AST and display the result at the end.
The process of dividing characters into tokens is called lexing, and the lexer does this. Tokens are short, digestible lines containing the most basic parts of a program, such as numbers, identifiers, keywords, and operators. Lexer will skip the spaces and comments, as they are ignored by the interpreter.
The process of assembling tokens in AST is called parsing. The parser extracts the structure of our program into a form that we can execute.
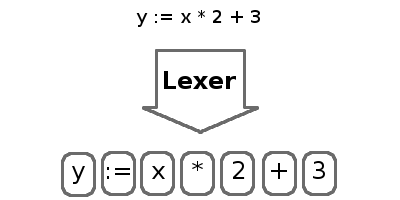
This article will focus exclusively on the lexer. First we will write the general lex library and then the lexer for IMP. The following parts will focus on the parser and artist.
Lexer
In truth, lexical operations are very simple and are based on regular expressions. If you are not familiar with them, you can read the official documentation .
The input to the lexer will be a simple stream of characters. For simplicity, we will read the input in memory. But the output data will be a list of tokens. Each token includes a value and a label (tag, to identify the type of token). The parser will use this to build a tree (AST).
So, let's make the most common lexer, which will take a list of regexps and parse the code into tags. For each expression, it will check whether the input matches the current position. If a match is found, the corresponding text is extracted into the token, along with the regular expression tag. If the regular expression does not fit anywhere, the text is discarded. This allows us to get rid of things like comments and spaces. If nothing matched at all, then we report an error and the script becomes a hero. This process is repeated until we analyze the whole code flow.
Here is the code from the lexer library:
import sys import re def lex(characters, token_exprs): pos = 0 tokens = [] while pos < len(characters): match = None for token_expr in token_exprs: pattern, tag = token_expr regex = re.compile(pattern) match = regex.match(characters, pos) if match: text = match.group(0) if tag: token = (text, tag) tokens.append(token) break if not match: sys.stderr.write('Illegal character: %s\n' % characters[pos]) sys.exit(1) else: pos = match.end(0) return tokens Note that the order of transmission to regular expressions is significant. The lex function will iterate through all the expressions and accept only the first match found. This means that when using this function, first of all we should pass specific expressions (corresponding to operators and keywords), and then ordinary expressions (identifiers and numbers).
Lexer IMP
Given the code above, creating a lexer for our language becomes very simple. First, let's define a series of tags for tokens. A language needs only 3 tags. RESERVED for reserved words or operators, INT for numbers, ID for identifiers.
import lexer RESERVED = 'RESERVED' INT = 'INT' ID = 'ID' Now we define the expressions for the tokens that will be used in the lexer. The first two expressions correspond to spaces and comments. Since they have no tags, the lexer will skip them.
token_exprs = [ (r'[ \n\t]+', None), (r'#[^\n]*', None), After that all our operators and reserved words follow.
(r'\:=', RESERVED), (r'\(', RESERVED), (r'\)', RESERVED), (r';', RESERVED), (r'\+', RESERVED), (r'-', RESERVED), (r'\*', RESERVED), (r'/', RESERVED), (r'<=', RESERVED), (r'<', RESERVED), (r'>=', RESERVED), (r'>', RESERVED), (r'=', RESERVED), (r'!=', RESERVED), (r'and', RESERVED), (r'or', RESERVED), (r'not', RESERVED), (r'if', RESERVED), (r'then', RESERVED), (r'else', RESERVED), (r'while', RESERVED), (r'do', RESERVED), (r'end', RESERVED), Finally, we need expressions for numbers and identifiers. Please note that the regular expressions for identifiers will correspond to all the reserved words above, so it is very important that these two lines come last.
(r'[0-9]+', INT), (r'[A-Za-z][A-Za-z0-9_]*', ID), ] When our regexps are defined, we can create a wrapper over the lex function :
def imp_lex(characters): return lexer.lex(characters, token_exprs) If you have read these words, you will most likely be interested in how our miracle works. Here is the code for the test:
import sys from imp_lexer import * if __name__ == '__main__': filename = sys.argv[1] file = open(filename) characters = file.read() file.close() tokens = imp_lex(characters) for token in tokens: print token $ python imp.py hello.imp Download full source code: imp-interpreter.tar.gz
The author of the original article is Jay Conrod .
UPD: Thanks to the zeLark user for fixing the bug related to the pattern definition order.
Source: https://habr.com/ru/post/206320/
All Articles