New version of HP Vertica: Crane number 7

In December 2013, a new, seventh version of HP Vertica was released. In the continuation of the tradition of large construction of “not small data”, the version was named “Crane” (the sixth version was called “Bulldozer”). In this article I will describe what has changed in the new version.
Work with unstructured data - Flex Zone
The most important step up the big data ladder in the new version of HP Vertica is the emergence of support for direct work with unstructured data in CSV and JSON formats. The sixth version supported loading data from CSV files and querying them as to external global tables. If the file data had a previously unknown, floating structure, then the only way to load and work with such data in Vertica was to pre-process them in external applications, such as ETL tools.
Now Vertica is able to work with unstructured data as easily as with structured data. It looks like this:
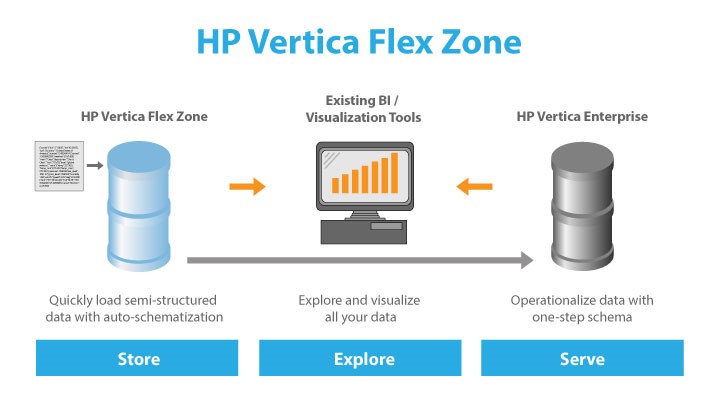
')
The HP Vertica Flex Zone is a special area for storing and processing unstructured data. In the Vertica database, you can create flex tables, load data from files with CSV and JSON formats into them, and query them by connecting these data in queries with Vertica relational tables. The loaded data in flex tables is stored on the nodes of the server cluster in a special format, but according to the same principles as the relational data of the database. Compression, mirroring and data segmentation are also supported for them (distribution between the nodes of the cluster). With this storage, the unstructured data, when processed, takes full advantage of the Vertica MPP architecture, works in a fault-tolerant scalable architecture, and participates in backups.
A great advantage of Flex Zone is that it is not an external solution integrated with Vertica (like HDFS / Hadoop connectors), but a native native support for unstructured data. This gives flexibility and lack of dependence on errors and changing versions of an external product. It also guarantees the speed of work with hybrid processing in queries using structured and unstructured data tables.
Where is the flex zone useful? A simple example: you need to load files with a dynamic (floating) structure. Moreover, it is not known in advance which data will be further demanded in the analysis, and which will not. Variants of solutions to this problem on the sixth version of Vertica would be:
- Create a table in the database with all possible fields that may be present in the files. Track the appearance of new columns in files and add them to the table. For JSON formats, write and maintain an additional data loader, which parses the format and writes data to the table. The solution is productive, but expensive to develop and maintain.
- Create a task in Hadoop to parse and write the processed files to CSV format, and store the result of processing in HDFS. Connect from HDFS the received files as external tables to Vertica, specifying the required fields for processing. As new fields appear, recreate the connection of external tables with a modified structure. The solution is fast in development, but expensive to maintain and not productive.
For the seventh version of Vertica, this task of processing, storing and working with files will be reduced to just two SQL statements:
- Define a flex table (create table)
- Load data into flex table (copy)
Vertica allows for flex tables to describe immediately materialized columns (create / alter table). Such columns are filled with values immediately when they are loaded and are stored as standard columns of the Vertica tables in the column structure. The remaining columns can be accessed dynamically through the created view, which can be rebuilt using specialized functions. Such an approach allows materializing the relevant and key fields in the queries, obtaining other data from the stored unstructured data during the processing of the request. Such a hybrid approach allows you to retain high query performance even for unstructured data.
In summary, I would like to summarize: The Flex Zone allows you to easily and securely store unstructured data, extracting information on demand from it. This saves on the complexity of the development and maintenance of the solution to work with such data and provides excellent opportunities in the field of analysis of various data.
Since the Flex zone runs on Vertica cluster servers, it is stored and processed in the same place, it is licensed in the same way as structured data, that is, by the amount of source data. Here I would like to notice one big drawback with such licensing: unlike structured data, flex tables load the entire volume of these files for storage in the database, which means everything that is loaded will be licensed. If only half of the fields from an unstructured file are used, the storage of such data is expensive in terms of licenses. For such cases, it is nevertheless more convenient to use HDFS unstructured files as storage and process them in Hadoop, delivering the processing results to Vertica. However, the licensing scheme is too vaguely described in the documentation, I will clarify its provisions and further write off on this issue.
Working with HDFS files with HCatalog
In the sixth version of Vertica was the ability to download flat files from HDFS. It was also possible to include such files for analysis in queries as external tables. The main disadvantage here is the requirement to accurately describe the structure of the file being loaded from HDFS. In the new version of Vertica, support for working with flat HDFS files has been extended to support metadata for the description of flat tables through a connector to the HCatalog interface, which serves to store the description of the structure of flat files (metadata) for Apache Hive. It looks like this:

When loading data from HDFS files or querying them as connected external tables, Vertica receives metadata for the files from the HCatalog server. The server then loads the file data itself from the HDFS cluster and processes it. The processing capabilities of Hadoop / Hive are not used. The Vertica documentation says that due to efficient server solutions in the field of data analysis, it is more profitable to collect data and further process it on the Vertica side than on the Hadoop side. An additional advantage of this approach is the cost of development and maintenance. By the way, in the same documentation it is added that in the case of massive and heavy data processing it is recommended to do this on Hadoop, here Vertica will be less effective. So we can say that Vertica in a certain sense not only integrates with Hadoop, but also tries to replace it in the field of analytical data processing, providing both its own algorithms for processing unstructured data and its data storage in the Flex zone.
Large cluster management
Any MPP always has an hour X sooner or later: the number of cluster servers reaches a critical level when the costs of message transfer and network coordination begin to be the bottleneck of the system. Apparently, the HP Vertica server has grown to companies in which hundreds and thousands of servers are not a miracle, but a working moment. Therefore, in the seventh version, the possibilities of network interaction of the cluster servers were significantly expanded. Now, in addition to the usual broadcast mode of Vertica, you can enable the “Large Cluster Arrangement” mode, which allows you to optimize Vertica for clusters with a large number of servers. Vertica documentation recommends using it both with a number of 120 servers in a cluster, and with a smaller number of servers if there is a high-loaded network activity between them. The principle of a large cluster mode is that its nodes are combined into groups in which coordinators of network interaction are appointed. Within each group, nodes communicate with each other, and between groups, the coordinators of groups are responsible for networking.
There is another MPP problem that is critical for large clusters: this is the fault tolerance of a group of servers (racks). As you know, Vertica mirrors the data between neighboring nodes. Prior to the seventh version, this happened automatically and it was not possible to specify the order of mirroring. This jeopardized the work of the cluster as a whole if it had multiple server racks and one of the racks was turned off. It turned out that the neighboring nodes disappeared from the cluster and he was forced to stop his work. In the seventh version, this problem was solved with the help of “Fault Groups”. Now for the database it is possible to paint server groups by racks and paint on them working cluster nodes:
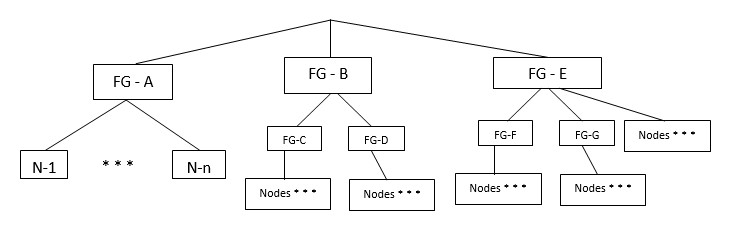
When data is segmented, the Vertica server will ensure that the mirror of these servers will be stored in different fault tolerant groups. Thus, shutting down one server group (rack) will not cause the cluster to stop, as the other group will have a mirror that they can connect to in order for the cluster to work.
JDBC API Key-Value
Initially, HP Vertica was designed as an analytical data server that allows you to quickly perform analysis on large amounts of data. Gradually, the server capabilities grew and now Vertica can already be called a full-fledged BigData server, which allows processing both structured and unstructured data. Any BigData server must, in particular, be able to not only quickly analyze data, but also look for values by key, that is, support fast access to data, acting as a Key-Value server. The Vertica team seriously decided to cover all the BigData requirements in their product and implemented this feature through an extension for Vertica JDBC drivers. Initially, searching for information by key in Vertica looked like a normal SELECT query in the database with a filter in WHERE by a key, as a result of which the query was distributed among the servers of the cluster, where everything started, until one of the cluster nodes found the desired result and returned it to the calling client session . It looks like this:

Now, using the Key-Value interface, you can query the data as follows:
VGet get = conn.prepareGet("public", "users"); get.addPredicate("id", 5); ResultSet rs = get.execute(); When executing this code, the JDBC interface will immediately determine which cluster server the required entry is on and receive it:

Work with Key-Value is achieved due to certain rules of records segmentation and the presence of a PK / UK key in the processed table. Without these rules on the table being processed, this method will not work.
Summarizing, we can say that the Key-Value interface allows you to organize a highly efficient way to quickly find and retrieve data on a given key for multiple sessions, without unnecessary loads on the cluster servers by processor time, disk and network activity. I think this will be primarily appreciated by companies related to the web, for which the speed of information retrieval by key is always important.
Client Drivers
Vertica's JDBC driver has added support for the JDBC 4 standard. This is primarily useful for solutions that use JNDI. It also expanded support for obtaining database metadata through drivers and improved the work of the connection pool.
Support for “connection failover” and “connection load balancing” has been introduced for all drivers. You can specify a list of hosts by which you can connect in turn, if the previous one in the list was not available. You can also specify the connection balancing option for the connection. Then, when connecting to the first available host in the list, the connected server can redirect the client’s connection to another, less loaded, available host. These features virtually eliminate the need to use a third-party load balancer, performing its functions.
For user authentication, the Kerberos version 5 protocol is also available in client drivers.
The drivers optimized batch inserts (batch inserts). According to the vendor, now the insertion speed is much higher and less resources are required on the client side.
Performance and fault tolerance
Optimized cluster operation in case of server failure. This is achieved due to the uniform redistribution of computational loads between other nodes of the cluster. Previously, the neighbor that had its mirror had to work for the failed node, which led to a general decrease in cluster performance due to the expectations of the working nodes, while the one working for two nodes would work out the calculations for both itself and the fallen neighbor.
To speed up the processing of calculating the number of unique field values in tables with a large number of records, functions of approximate counting the number with an error are added. This allows you to significantly speed up the execution of requests, if the error is allowed.
The optimizer now supports a new partial grouping algorithm using the hybrid GROUPBY PIPELINED and GROUPBY HASH algorithms. This allows you to more efficiently perform data aggregation queries using part of the sorted columns, which reduces the memory and swap consumption on the disk for hashing.
The operation of the MERGE operator is accelerated for tables that have PK / UK keys, by which data is combined, and the set of columns and values for insertion and changes is the same. If these conditions are not met, then the tables are joined according to the algorithm of previous versions without optimization.
The work of the data loader COPY has been improved, where now the parsing and downloading file is more efficiently parsed by splitting it into several parts and parallel processing between the node's cores.
SDK extension
In previous versions of Vertica, it was possible in C to extend the functionality of the server by writing your own scalar (simple) functions, data transformation functions (olap) and functions for processing the loaded data with the COPY and CREATE EXTERNAL TABLE operators. Now it is also available on the Java platform. Especially for this Java SDK is included in the new version of HP Vertica.
Other extensions
Significantly expanded the functionality of the web console (Management Console). More and more, this tool is turning from a system operation monitoring tool into a full-fledged cluster administration tool. Now the console supports viewing plans and profiles for executing queries and launching the designer to optimize and create new projections. Even support for console skins has been added, although I don’t understand why this is needed.
Significantly improved Database Designer itself. Reworked algorithms for determining the best candidates for segmentation and packing of columns. The ability to analyze the correlation of columns (close connection between them) is added, that is, data profiling is actually used in the analysis. Added functions that allow programmatically create a design area for the specified tables and queries, analyze them and add new projections or modify existing ones, with a more optimal structure. This allows you to automate the work of tuning the execution of data queries. For example, you can independently develop and schedule the collection of heavy queries at a specified time, analyze them and get recommendations for optimizing data structures, applying them automatically to the database or saving them as a script for manual execution later. Additionally, the concept of query groups is introduced, which allows the designer to identify typical queries and optimize for the weight of the frequency of their use. For example, it allows not to build extra projections on heavy nightly requests, if they are performed once a day.
Improved server installation system. Vertica now checks for more OS settings on its own and tries to correct them. In case of impossibility, recommendations for manual configuration are issued during the installation.
The functionality of the SQL language, functions, service tables, configuration parameters, etc. was also expanded. All this can be read in more detail in the HP Vertica documentation.
Summarizing the article
HP Vertica has really grown from a low power bulldozer to a high strong crane. Construction BigData is in full swing. The scope of changes, taking into account the fact that packs for the sixth version continued to come out with functionality, is really impressive.
Author Konstantinov Alexey
Data Warehouse Architect
EasyData Company
Please refer to the author when using article information.
Source: https://habr.com/ru/post/206278/
All Articles