Machine learning and data analysis. Lecture for the Small ShAD Yandex
More and more, we are faced with the need to identify the internal patterns of large amounts of data. For example, to recognize spam, you must be able to find patterns in the content of e-mails, and to predict the value of shares - patterns in financial data. Unfortunately, it is often impossible to identify them manually, and then machine learning methods come to the rescue. They allow you to build algorithms that help to find new, not yet described patterns. We will talk about machine learning, where it should be used and what difficulties may arise. The principles of operation of several popular methods of machine learning will be discussed on real examples.
The lecture is intended for high school students - students of the Small SCHA, but adults can use it to get an idea of the basics of machine learning.

')
The basic idea of machine learning is that, having a learning program and data examples with patterns, we can build some pattern of patterns and find patterns in the new data.
For example, let's solve a simple problem. We have points of two colors scattered on the plane: red and blue. The coordinates and color of each of them are known to us. It is necessary to determine the color of the new point. Each point is the object being studied, and the coordinates and color are its parameters. For example, objects are people, coordinates are the height and length of a person’s hair, and color is a person’s gender.
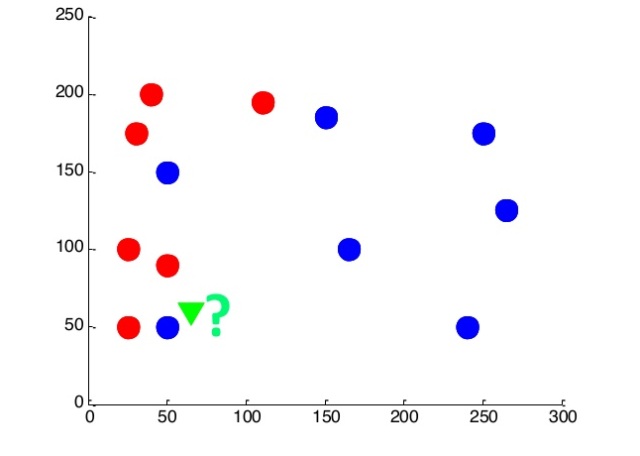
Let's try to solve it by the nearest neighbor method. Let the new object belong to the same class as its nearest neighbor. We make a forecast for each point on our plane: if the nearest point is blue, then the new object that appeared at this point is blue. And vice versa.

Thus, we have two areas: in one, the probability of red dots is great, and in the other, blue ones.
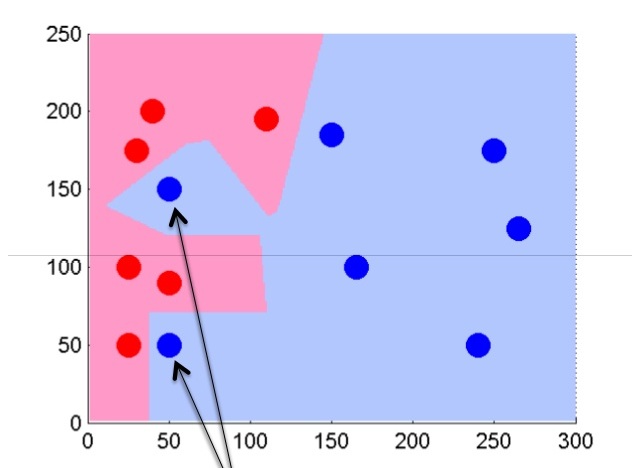
Next, we will try to slightly change the algorithm, and focus on several (k) nearest neighbors. Let k be five.
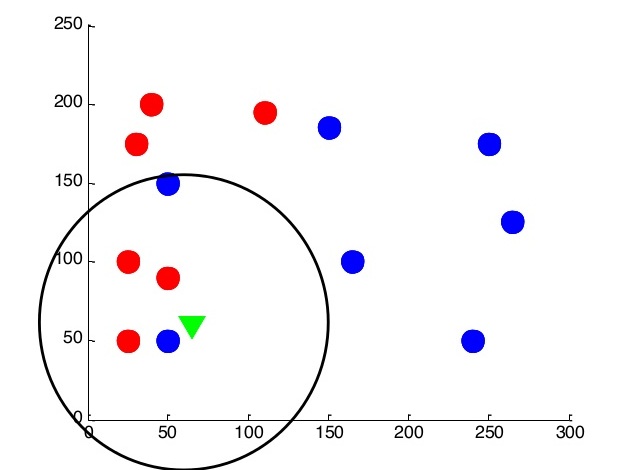
In this case, we will be able to cut off potentially noise objects and get a more even border separation of classes.
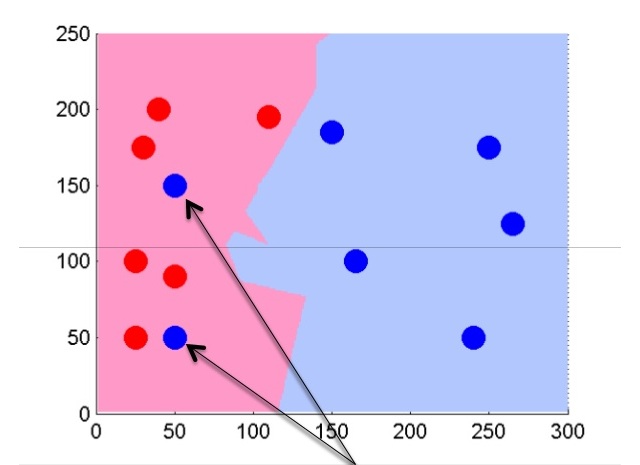
This is how the separation on a larger number of objects obtained by normal distribution will look like.
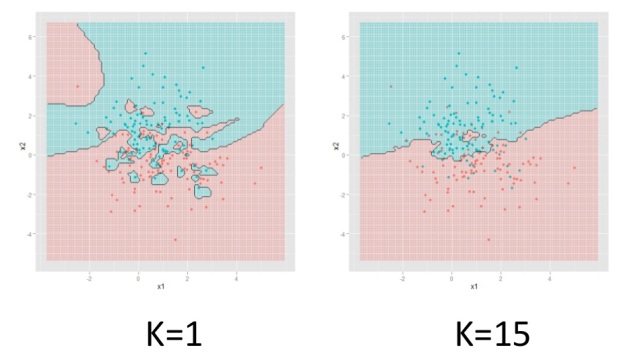
Imagine again that we have a plane on which the red and blue dots are located in a certain way.

You can draw a line between them in different ways. The result will depend on how the algorithm is adjusted to the data.
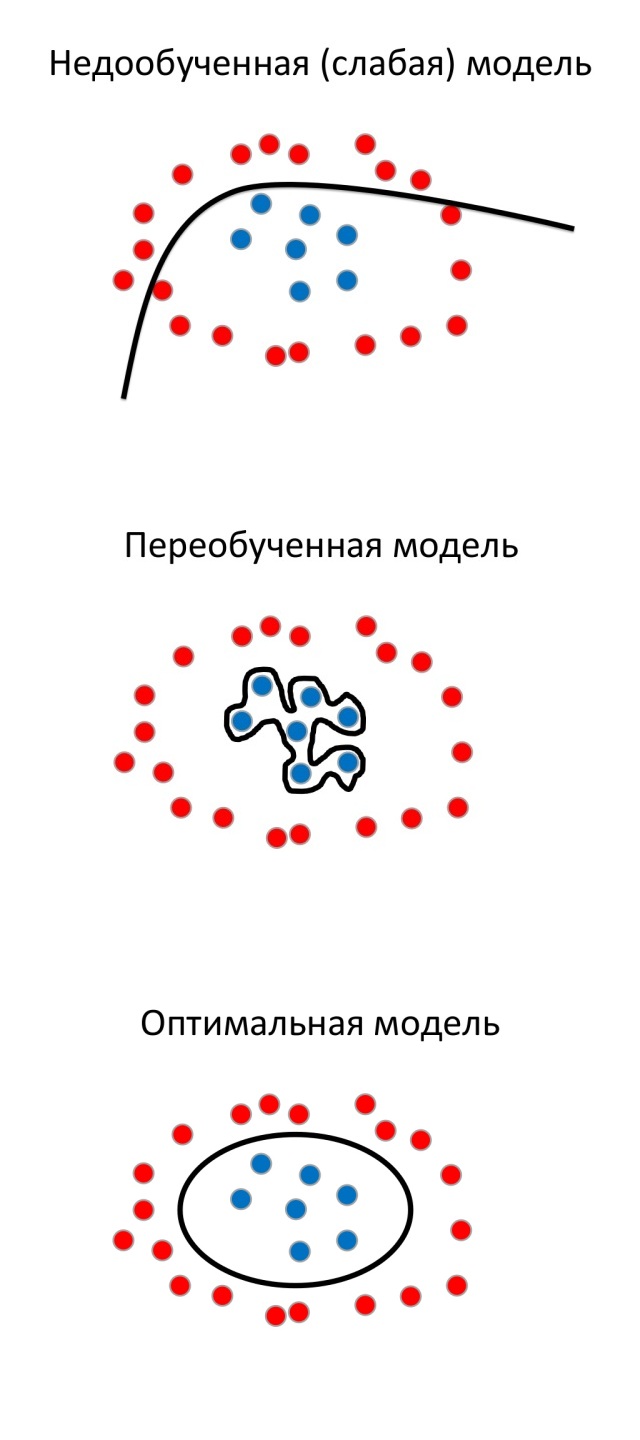
As a rule, the tendency of the model to retrain is related to the number of its parameters. For example, a model with a small number of parameters is unlikely to be able to retrain.
In the general case, in problems of machine learning, points are considered in multidimensional space, and not on a plane. Each coordinate is a sign. Therefore, the training set can be represented as follows:
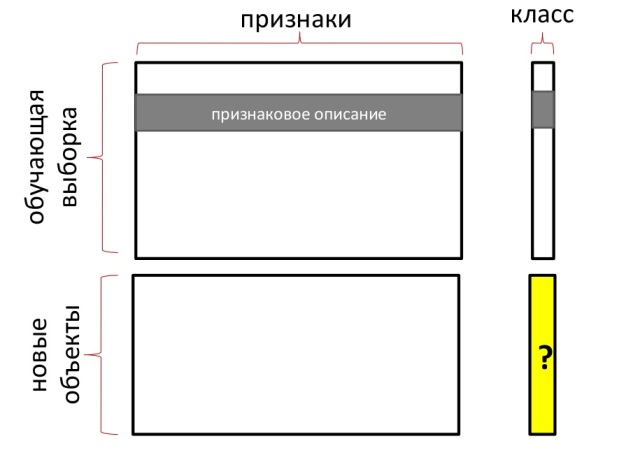
But which algorithm to choose, and how to evaluate the quality of its work? For this, the marked training sample is divided into two parts. In the first part, learning takes place directly, and the second part is used as a control. On it, we will check how many errors the algorithm produced.
An approximate cycle of solving a machine learning problem is as follows:
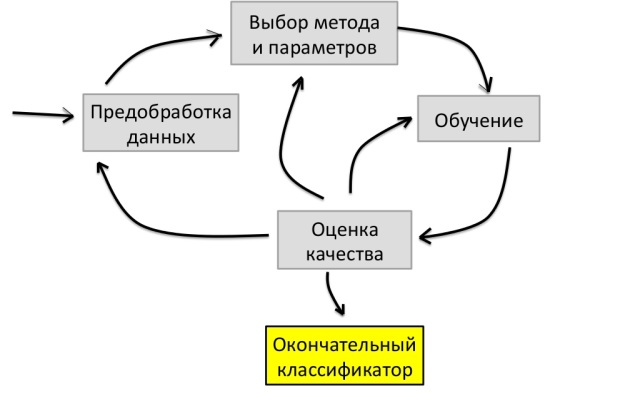
First, we perform preliminary data processing, then we select the classification method and parameters, conduct training and evaluate quality. If the quality triples us, the task is considered completed. Otherwise, we return to the selection of the method and parameters.
More detailed information, examples of real problems for machine learning, as well as a story about hyperplanes, neural networks . In deep learning, Viola-Jones , Decisive Trees and Boosting are available in videotape lecture.
The lecture is intended for high school students - students of the Small SCHA, but adults can use it to get an idea of the basics of machine learning.
')
The basic idea of machine learning is that, having a learning program and data examples with patterns, we can build some pattern of patterns and find patterns in the new data.
Neighbor Neighbor Method
For example, let's solve a simple problem. We have points of two colors scattered on the plane: red and blue. The coordinates and color of each of them are known to us. It is necessary to determine the color of the new point. Each point is the object being studied, and the coordinates and color are its parameters. For example, objects are people, coordinates are the height and length of a person’s hair, and color is a person’s gender.
Let's try to solve it by the nearest neighbor method. Let the new object belong to the same class as its nearest neighbor. We make a forecast for each point on our plane: if the nearest point is blue, then the new object that appeared at this point is blue. And vice versa.
Thus, we have two areas: in one, the probability of red dots is great, and in the other, blue ones.
Next, we will try to slightly change the algorithm, and focus on several (k) nearest neighbors. Let k be five.
In this case, we will be able to cut off potentially noise objects and get a more even border separation of classes.
This is how the separation on a larger number of objects obtained by normal distribution will look like.
Algorithm quality and parameters
Imagine again that we have a plane on which the red and blue dots are located in a certain way.
You can draw a line between them in different ways. The result will depend on how the algorithm is adjusted to the data.
As a rule, the tendency of the model to retrain is related to the number of its parameters. For example, a model with a small number of parameters is unlikely to be able to retrain.
In the general case, in problems of machine learning, points are considered in multidimensional space, and not on a plane. Each coordinate is a sign. Therefore, the training set can be represented as follows:
But which algorithm to choose, and how to evaluate the quality of its work? For this, the marked training sample is divided into two parts. In the first part, learning takes place directly, and the second part is used as a control. On it, we will check how many errors the algorithm produced.
Problem solving cycle
An approximate cycle of solving a machine learning problem is as follows:
First, we perform preliminary data processing, then we select the classification method and parameters, conduct training and evaluate quality. If the quality triples us, the task is considered completed. Otherwise, we return to the selection of the method and parameters.
More detailed information, examples of real problems for machine learning, as well as a story about hyperplanes, neural networks . In deep learning, Viola-Jones , Decisive Trees and Boosting are available in videotape lecture.
Source: https://habr.com/ru/post/206058/
All Articles