Have you met with a forest analysis of a SQL query population of an industrial application (for example, for optimization)?
I want to ask this question Habrovchanam.
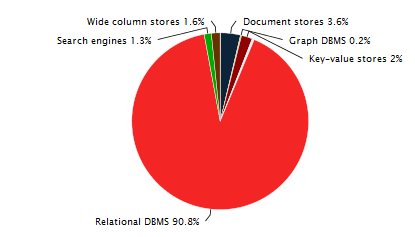
Modern information systems are built on different types of DBMS and yet relational DBMS remain the most common and used . Interesting statistics on this topic HERE and HERE .
When developing and modifying systems, the level of formalization of knowledge of analysts and developers remains small (automating the creation of smart queries or taking into account a number of clear rules) and most often the resulting SQL queries are written “normally”, “like I used”, “that's what we write in our company” and optimization questions remain at the stage of fulfilling queries in the DBMS and the subsequent stages of optimization (in the worst case, they are waiting for everything to slow down).
')
The amount of manual code remains large even in spite of the presence of a large number of handy tools to avoid their manual writing (including ORM). And it is not always possible to use such tools, especially when it comes to very complex analytical queries, including complex data analysis. And such tools as ORM are used in less recent projects and only for trivial requests.
In any case, the need to optimize queries and, possibly, the database structure is constant on an industrial basis. Even with the "ideal" design, this can not be avoided because the environment is changing and the customer himself does not always know what will happen tomorrow (how will the laws, the market, customers change, what new ideas will appear, etc.).

When optimizing in a DBMS, a number of the same problems arise as when optimizing the code for a normal programming language - searching and tracking the same code, replacing it in all places with a new, optimized, etc ... And it would be nice if all the SQL queries were in the same place and it would be possible to go through a simple search and replace))) But it has so happened historically that most technologies do not distinguish the layer of queries into separate structures / objects / files / etc. At best, the queries are really allocated in separate files.
The option to receive all queries can be, for example, SQL logger (almost all DBMS are either built-in or can be screwed). But in this case, it is necessary to choose the period of receiving all requests, for example, a year, which takes a long time (for a typical enterprise, all the basic operations that can be ... almost :) take place, and the problem of determining the parameters will remain open ...
Here, on Habré, and on the Internet in Russian. and eng. languages have a lot of information on query optimization and a separate database structure, but there are really few materials on the analysis of all queries for subsequent optimization. And the fact that there are more recommendations of analytical, automated tools for this, I have not found ...
Tell me, habrovchane, did you meet with a comprehensive analysis of the entire population of SQL application queries?
In my opinion there are three main reasons for a comprehensive analysis of the structure of SQL queries :
1. code optimization : highlighting duplicate code, replacing duplicate code when optimizing it, issuing various automatic prompts to improve the code structure.
2. code refactoring (optimization in this case is not a mandatory effect).
3. scientific interest , for example, the analysis of the forests of SQL industrial systems for further research, for example, the imitation modeling of the SQL query forest for the analysis of new algorithms for optimizing the work of the DBMS.
In my opinion, the availability of such an analysis tool would significantly simplify the work of many programmers and some scientists working on optimization algorithms in a DBMS.
Modern information systems are built on different types of DBMS and yet relational DBMS remain the most common and used . Interesting statistics on this topic HERE and HERE .
When developing and modifying systems, the level of formalization of knowledge of analysts and developers remains small (automating the creation of smart queries or taking into account a number of clear rules) and most often the resulting SQL queries are written “normally”, “like I used”, “that's what we write in our company” and optimization questions remain at the stage of fulfilling queries in the DBMS and the subsequent stages of optimization (in the worst case, they are waiting for everything to slow down).
')
The amount of manual code remains large even in spite of the presence of a large number of handy tools to avoid their manual writing (including ORM). And it is not always possible to use such tools, especially when it comes to very complex analytical queries, including complex data analysis. And such tools as ORM are used in less recent projects and only for trivial requests.
In any case, the need to optimize queries and, possibly, the database structure is constant on an industrial basis. Even with the "ideal" design, this can not be avoided because the environment is changing and the customer himself does not always know what will happen tomorrow (how will the laws, the market, customers change, what new ideas will appear, etc.).
When optimizing in a DBMS, a number of the same problems arise as when optimizing the code for a normal programming language - searching and tracking the same code, replacing it in all places with a new, optimized, etc ... And it would be nice if all the SQL queries were in the same place and it would be possible to go through a simple search and replace))) But it has so happened historically that most technologies do not distinguish the layer of queries into separate structures / objects / files / etc. At best, the queries are really allocated in separate files.
The option to receive all queries can be, for example, SQL logger (almost all DBMS are either built-in or can be screwed). But in this case, it is necessary to choose the period of receiving all requests, for example, a year, which takes a long time (for a typical enterprise, all the basic operations that can be ... almost :) take place, and the problem of determining the parameters will remain open ...
Here, on Habré, and on the Internet in Russian. and eng. languages have a lot of information on query optimization and a separate database structure, but there are really few materials on the analysis of all queries for subsequent optimization. And the fact that there are more recommendations of analytical, automated tools for this, I have not found ...
Tell me, habrovchane, did you meet with a comprehensive analysis of the entire population of SQL application queries?
In my opinion there are three main reasons for a comprehensive analysis of the structure of SQL queries :
1. code optimization : highlighting duplicate code, replacing duplicate code when optimizing it, issuing various automatic prompts to improve the code structure.
2. code refactoring (optimization in this case is not a mandatory effect).
3. scientific interest , for example, the analysis of the forests of SQL industrial systems for further research, for example, the imitation modeling of the SQL query forest for the analysis of new algorithms for optimizing the work of the DBMS.
In my opinion, the availability of such an analysis tool would significantly simplify the work of many programmers and some scientists working on optimization algorithms in a DBMS.
Source: https://habr.com/ru/post/205538/
All Articles