Search for cropped duplicate images using perceptual hashes
This article will discuss how a small task of finding duplicates by fragment or crop of a picture was solved.

')
I have one place where users sometimes add, in their opinion, beautiful pictures.
Which are then moderated by the users themselves.
And there are cases when one and the same picture is added several times. What was usually solved with postmoderation.
But the time came when it became difficult every time to check whether a similar or the same picture was already loaded.
And there was an idea that it was time to look at the automatic search for duplicates.
Initially, the gaze fell on SURF descriptors, which gave very good results.
But due to the complexity of checking for coincidences with the collection of pictures, I decided not to hurry and look at other solutions.
Intuitively, I would like to highlight some signs of the image, like SIFT / SURF descriptors, but with the ability to quickly check for a match.
After some effort, I ran into the idea of perceptual hashes .
They seemed simple enough to create and search the database.
In short, a perceptual hash is a convolution of some signs that describe a picture.
The main advantage of such hashes is that they are easy to compare with other hashes using Hamming distance .
Ideally, the hash distance of two images is zero. Then it means that these pictures are (most likely) identical.
Especially bribed that this distance could be considered using a not very complex SQL query:
It remains to figure out how to get such hashes.
In a subsequent article , descriptions were given of three ways to isolate this type of hash.
In addition to the simplest algorithm for checking for the average value, which was called aHash (Average Hash) and the most relevant variant implemented in the open source project pHash (Perceptual Hash), another description was given - dHash (Difference Hash), proposed by David Oftedal , namely, the comparison is not with the average pixel value, but with the previous one.
After some tests, it turned out that
aHash is inoperative and gives a huge number of false positives,
dHash works much better, but still a lot of unsatisfactory mistakes,
pHash showed itself best with the most current results, but is more sensitive to image modifications.
In general, pHash is able to verify the identity of the image, even if a small copyright label was applied to it. Insensitive to color, contrast, brightness, size and even weak geometric changes.
With all these advantages, there is a completely legitimate restriction: the hash describes the whole picture and is more intended to search for a complete duplicate.
In other words, such hashes are irrelevant when searching for duplicate pictures with crop, modifications with scale, size of the sides of the pictures, or directly partial or serious interference with the content of the picture.
After a brief analysis of the situation, I came to the conclusion that users are unlikely to add pictures with content modifications.
For example, to draw a flower, a huge wet tag, or to change a photo somehow differently.
But adding pictures with Crop is quite real. For example, cut an important part, change the aspect ratio, increase something, and so on.
Therefore, besides checking for complete or partial coincidence, it was necessary to check for a crop, at least a small one.
One hash for one image is expediently unable to solve a similar problem.
But, due to the ease of implementation of such hashes, I wanted to think a little about how to get around this limitation and find the cropping of the image with their help.
Since one hash is no good, you should get a list of hashes. Where each hash describes only its part of the image.
But how do we know where and how to cut the picture?
This is where getting local features using SURF came in handy.
In other words, it was necessary to somehow cut the images by the points found.
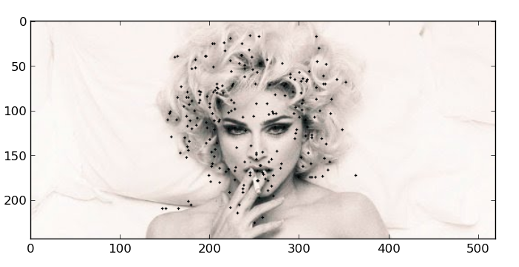
Figure 1. Found points from the requested image

Figure 2. Found points from the saved image
Since we need to cut the picture in such a way that similar areas coincide (at least a little), k-means clustering of key points (features) has been tried.
It seemed that if the picture did not change much in content and the local signs found remained almost unchanged, then probably the centroids after clustering these local points should also be approximately the same.
This is the main idea of this approach.

Figure 3. The dot shows the center of a single cluster.

Figure 4. Points describe the centers of the three clusters. If you look closely, the upper centroid almost coincides with the center from Fig. 3.
In order to find such centroids that will roughly converge, it was necessary to perform clustering, for example, 20 times, changing the number of clusters.
And it was possible to cut at the extreme points of each cluster.
With a limit of 20 clusters, 21 * 20/2 = 210 centroids are obtained. And just hashes for one image 210 + full image hash = 211 hashes.
But we discard the slices less than 32 pixels and as a result we get, for example, 191 hashes.
This approach showed better results than just comparing hashes of full images, but it still turned out to be unsatisfactory due to obvious misses. It seems to be visually cutting coincide, but checking their hashes fails.
Here the idea has already crept up to throw this venture and dig in another direction.
But, finally, I decided to check what role the fixed format of the sides or coordinates plays. And it turned out that this made it possible to increase the number of matches.
I picked it up with a spear method so that the coordinate of the cut out image was a multiple of eight.

Figure 5. Cut out matching images using clustering
Next, it was necessary to test the performance of such a model in practice.
Quickly everything was transferred to the mogilnichok with pictures and the entire base was indexed.
It turned out 1,235 pictures and 194,710 hashes in the database.
And it turned out that BIT_COUNT (hash1 ^ hash2) is a rather expensive operation and requires additional attention.
And it takes more time to execute 200 requests than to fulfill one large request with all 200 hashes at once.
On my weak server, such a large request is executed for at least 2 seconds.
A total of 200 * 194,710 = 38,942,000 operations for calculating the Hamming distance are required to search for one image.
Therefore, I decided to check what the difference would be if I wrote my own implementation of calculating the distance in MySQL.
The difference was insignificant and, moreover, not in favor of user functions.
For the sake of interest, I tried to implement a search on a collection of hashes in C ++.
Where the idea is impossible is simple: get the entire list of hashes from the database and walk through them, calculating the distance manually.
And this idea works out twice as fast as through a SQL query.
Further, due to the large number of hashes, it was necessary to formulate the rules for determining duplicates.
For example, if one of two hundred hashs matched, consider the image a duplicate? Probably not.
Also, there were cases when more than 20% of the hashes coincided, but the picture is definitely not a duplicate.
And there are 10% of matches, but is a duplicate.
So the number of only hashes found to the total number is not a guarantee of verification.
To filter out obviously incorrect matches, we used the SURF calculation of the descriptors of the images found and counting the number of matches with the requested one.
That allowed to show current results, but requires additional processing time. Most likely there are more optimal options.
Such an approach made it possible to find pictures that were reasonably well within reasonable limits in a satisfactory time.
Although it is far from optimal and leaves a lot of room for maneuvers or optimizations (for example, it is reasonable to check the hashes after clustering and discard duplicates, which will reduce the number of hashes by two, and maybe even more times).
But, I hope, interesting for simple curiosity, albeit non-academic.
habrahabr.ru/post/120562 - Description of hashes, translation
ru.wikipedia.org/wiki/Hamming distance - Hamming distance
en.wikipedia.org/wiki/SURF - SURF key points
ru.wikipedia.org/wiki/K-means - Clustering
phash.org - pHash project
www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html - Comparing Hash Types
01101001.net/differencehash.php - Difference Hash
github.com/valbok/img.chk/blob/master/bin/example.py - My version of the implementation of the selection of hashes from the image
github.com/valbok/leie/blob/master/classes/image/leieImage.php - Another version of my hash, but in PHP
')
Foreword
I have one place where users sometimes add, in their opinion, beautiful pictures.
Which are then moderated by the users themselves.
And there are cases when one and the same picture is added several times. What was usually solved with postmoderation.
But the time came when it became difficult every time to check whether a similar or the same picture was already loaded.
And there was an idea that it was time to look at the automatic search for duplicates.
Investigation
Initially, the gaze fell on SURF descriptors, which gave very good results.
But due to the complexity of checking for coincidences with the collection of pictures, I decided not to hurry and look at other solutions.
Intuitively, I would like to highlight some signs of the image, like SIFT / SURF descriptors, but with the ability to quickly check for a match.
After some effort, I ran into the idea of perceptual hashes .
They seemed simple enough to create and search the database.
In short, a perceptual hash is a convolution of some signs that describe a picture.
The main advantage of such hashes is that they are easy to compare with other hashes using Hamming distance .
Ideally, the hash distance of two images is zero. Then it means that these pictures are (most likely) identical.
Especially bribed that this distance could be considered using a not very complex SQL query:
SELECT * FROM image_hash WHERE BIT_COUNT( 0x2f1f76767e5e7f33 ^ hash ) <= 10It remains to figure out how to get such hashes.
In a subsequent article , descriptions were given of three ways to isolate this type of hash.
In addition to the simplest algorithm for checking for the average value, which was called aHash (Average Hash) and the most relevant variant implemented in the open source project pHash (Perceptual Hash), another description was given - dHash (Difference Hash), proposed by David Oftedal , namely, the comparison is not with the average pixel value, but with the previous one.
After some tests, it turned out that
aHash is inoperative and gives a huge number of false positives,
dHash works much better, but still a lot of unsatisfactory mistakes,
pHash showed itself best with the most current results, but is more sensitive to image modifications.
In general, pHash is able to verify the identity of the image, even if a small copyright label was applied to it. Insensitive to color, contrast, brightness, size and even weak geometric changes.
With all these advantages, there is a completely legitimate restriction: the hash describes the whole picture and is more intended to search for a complete duplicate.
In other words, such hashes are irrelevant when searching for duplicate pictures with crop, modifications with scale, size of the sides of the pictures, or directly partial or serious interference with the content of the picture.
Attempt to solve
After a brief analysis of the situation, I came to the conclusion that users are unlikely to add pictures with content modifications.
For example, to draw a flower, a huge wet tag, or to change a photo somehow differently.
But adding pictures with Crop is quite real. For example, cut an important part, change the aspect ratio, increase something, and so on.
Therefore, besides checking for complete or partial coincidence, it was necessary to check for a crop, at least a small one.
One hash for one image is expediently unable to solve a similar problem.
But, due to the ease of implementation of such hashes, I wanted to think a little about how to get around this limitation and find the cropping of the image with their help.
Since one hash is no good, you should get a list of hashes. Where each hash describes only its part of the image.
But how do we know where and how to cut the picture?
This is where getting local features using SURF came in handy.
In other words, it was necessary to somehow cut the images by the points found.
Figure 1. Found points from the requested image
Figure 2. Found points from the saved image
Since we need to cut the picture in such a way that similar areas coincide (at least a little), k-means clustering of key points (features) has been tried.
It seemed that if the picture did not change much in content and the local signs found remained almost unchanged, then probably the centroids after clustering these local points should also be approximately the same.
This is the main idea of this approach.
Figure 3. The dot shows the center of a single cluster.
Figure 4. Points describe the centers of the three clusters. If you look closely, the upper centroid almost coincides with the center from Fig. 3.
In order to find such centroids that will roughly converge, it was necessary to perform clustering, for example, 20 times, changing the number of clusters.
And it was possible to cut at the extreme points of each cluster.
With a limit of 20 clusters, 21 * 20/2 = 210 centroids are obtained. And just hashes for one image 210 + full image hash = 211 hashes.
But we discard the slices less than 32 pixels and as a result we get, for example, 191 hashes.
This approach showed better results than just comparing hashes of full images, but it still turned out to be unsatisfactory due to obvious misses. It seems to be visually cutting coincide, but checking their hashes fails.
Here the idea has already crept up to throw this venture and dig in another direction.
But, finally, I decided to check what role the fixed format of the sides or coordinates plays. And it turned out that this made it possible to increase the number of matches.
I picked it up with a spear method so that the coordinate of the cut out image was a multiple of eight.
Figure 5. Cut out matching images using clustering
Prototype
Next, it was necessary to test the performance of such a model in practice.
Quickly everything was transferred to the mogilnichok with pictures and the entire base was indexed.
It turned out 1,235 pictures and 194,710 hashes in the database.
And it turned out that BIT_COUNT (hash1 ^ hash2) is a rather expensive operation and requires additional attention.
And it takes more time to execute 200 requests than to fulfill one large request with all 200 hashes at once.
On my weak server, such a large request is executed for at least 2 seconds.
A total of 200 * 194,710 = 38,942,000 operations for calculating the Hamming distance are required to search for one image.
Therefore, I decided to check what the difference would be if I wrote my own implementation of calculating the distance in MySQL.
The difference was insignificant and, moreover, not in favor of user functions.
For the sake of interest, I tried to implement a search on a collection of hashes in C ++.
Where the idea is impossible is simple: get the entire list of hashes from the database and walk through them, calculating the distance manually.
An example of calculating the Hamming distance in C ++
typedef unsigned long long longlong; inline longlong hamming_distance( longlong hash1, longlong hash2 ) { longlong x = hash1 ^ hash2; const longlong m1 = 0x5555555555555555ULL; const longlong m2 = 0x3333333333333333ULL; const longlong h01 = 0x0101010101010101ULL; const longlong m4 = 0x0f0f0f0f0f0f0f0fULL; x -= (x >> 1) & m1; x = (x & m2) + ((x >> 2) & m2); x = (x + (x >> 4)) & m4; return (x * h01)>>56; } And this idea works out twice as fast as through a SQL query.
Further, due to the large number of hashes, it was necessary to formulate the rules for determining duplicates.
For example, if one of two hundred hashs matched, consider the image a duplicate? Probably not.
Also, there were cases when more than 20% of the hashes coincided, but the picture is definitely not a duplicate.
And there are 10% of matches, but is a duplicate.
So the number of only hashes found to the total number is not a guarantee of verification.
To filter out obviously incorrect matches, we used the SURF calculation of the descriptors of the images found and counting the number of matches with the requested one.
That allowed to show current results, but requires additional processing time. Most likely there are more optimal options.
Epilogue
Such an approach made it possible to find pictures that were reasonably well within reasonable limits in a satisfactory time.
Although it is far from optimal and leaves a lot of room for maneuvers or optimizations (for example, it is reasonable to check the hashes after clustering and discard duplicates, which will reduce the number of hashes by two, and maybe even more times).
But, I hope, interesting for simple curiosity, albeit non-academic.
Links
habrahabr.ru/post/120562 - Description of hashes, translation
ru.wikipedia.org/wiki/Hamming distance - Hamming distance
en.wikipedia.org/wiki/SURF - SURF key points
ru.wikipedia.org/wiki/K-means - Clustering
phash.org - pHash project
www.hackerfactor.com/blog/index.php?/archives/529-Kind-of-Like-That.html - Comparing Hash Types
01101001.net/differencehash.php - Difference Hash
github.com/valbok/img.chk/blob/master/bin/example.py - My version of the implementation of the selection of hashes from the image
github.com/valbok/leie/blob/master/classes/image/leieImage.php - Another version of my hash, but in PHP
Source: https://habr.com/ru/post/205398/
All Articles